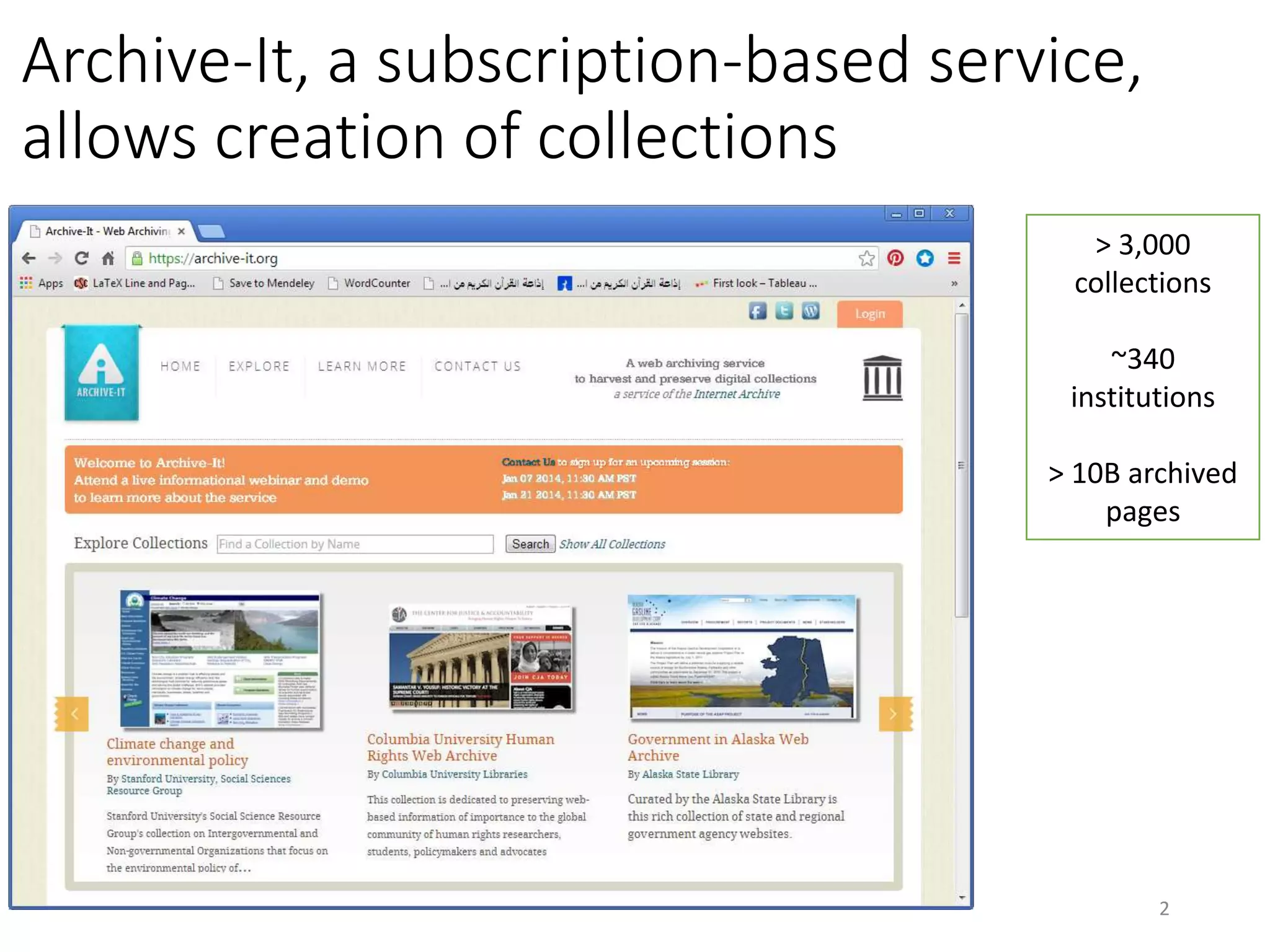
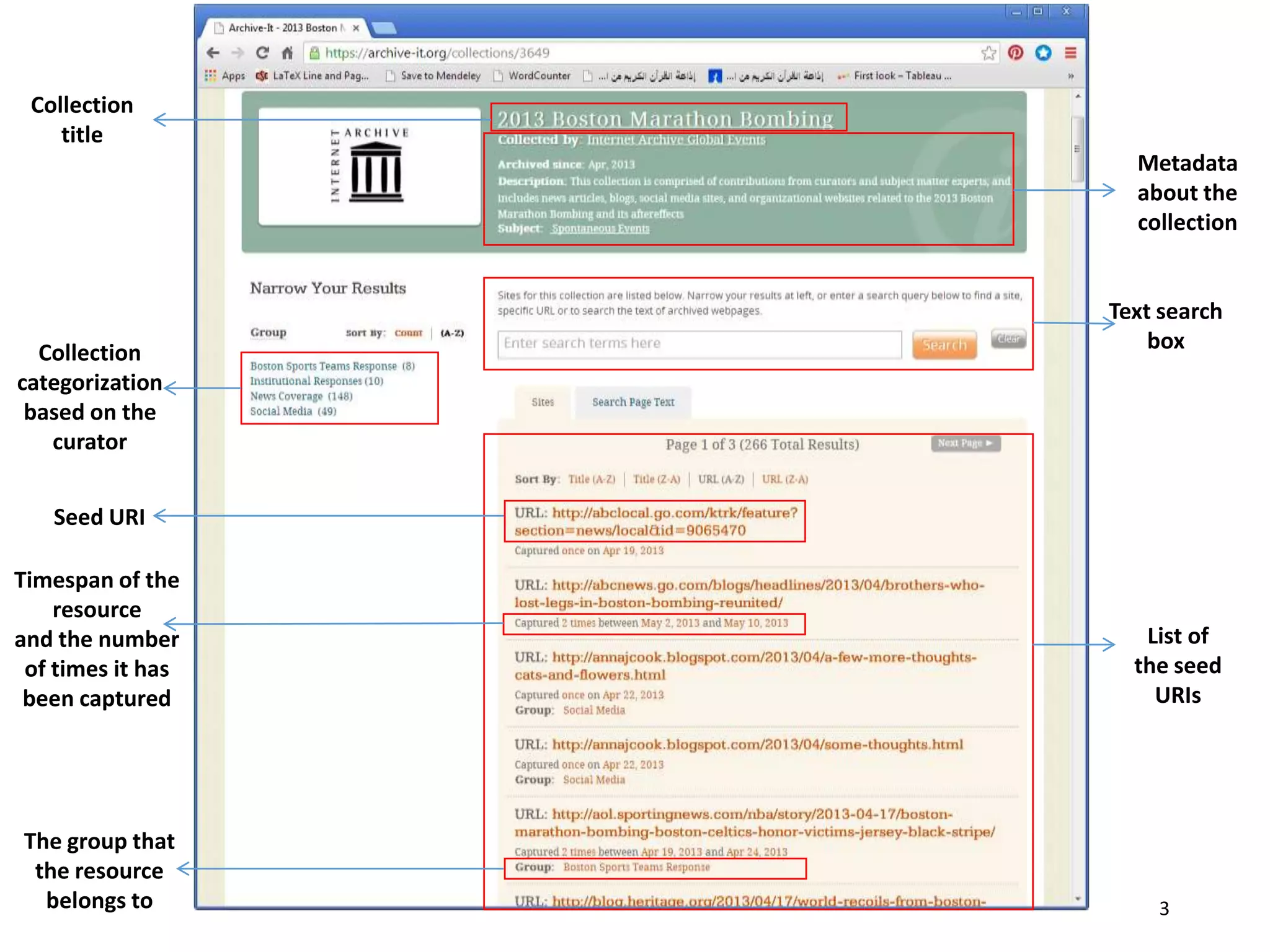
Download to read offline


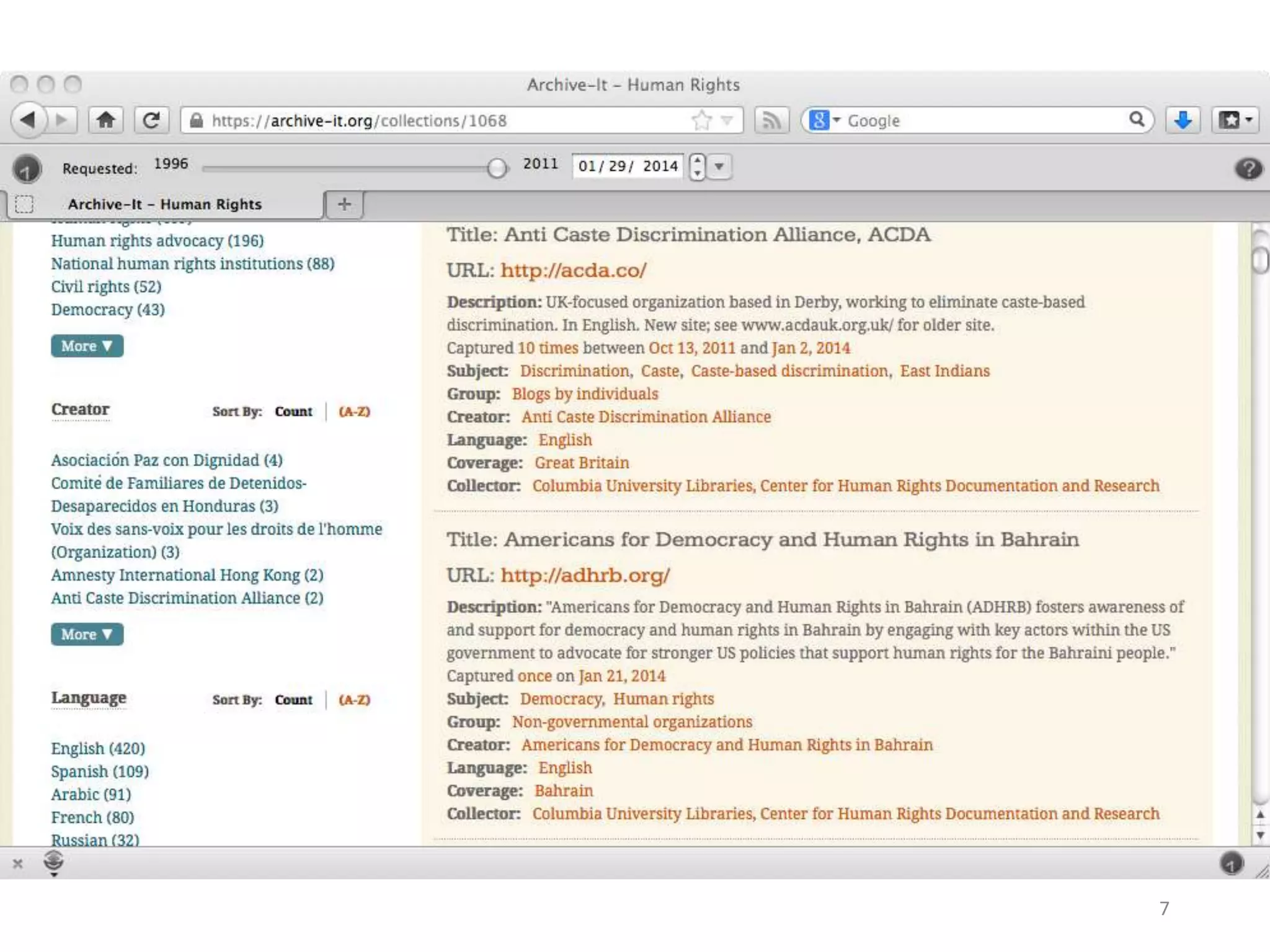
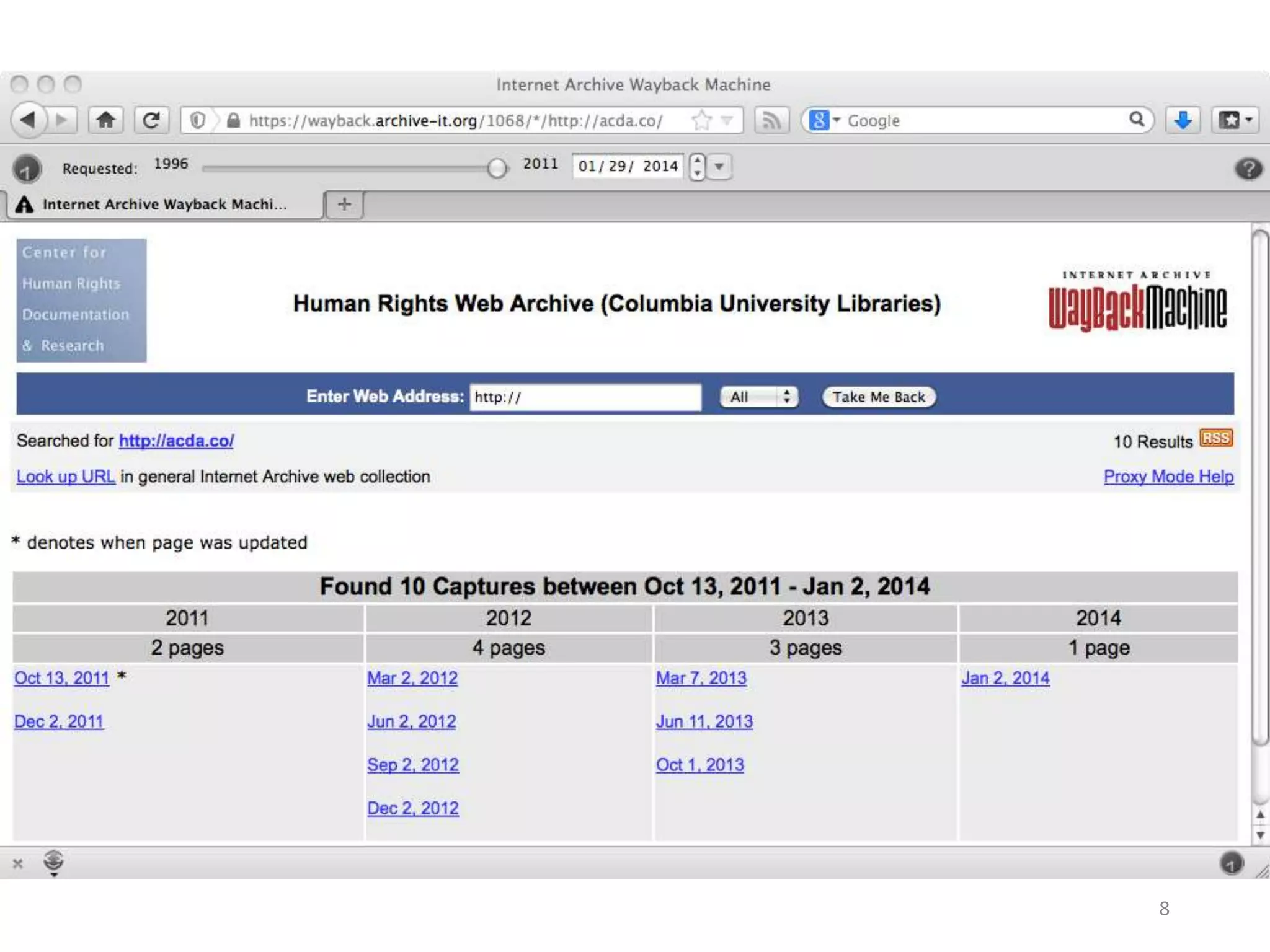








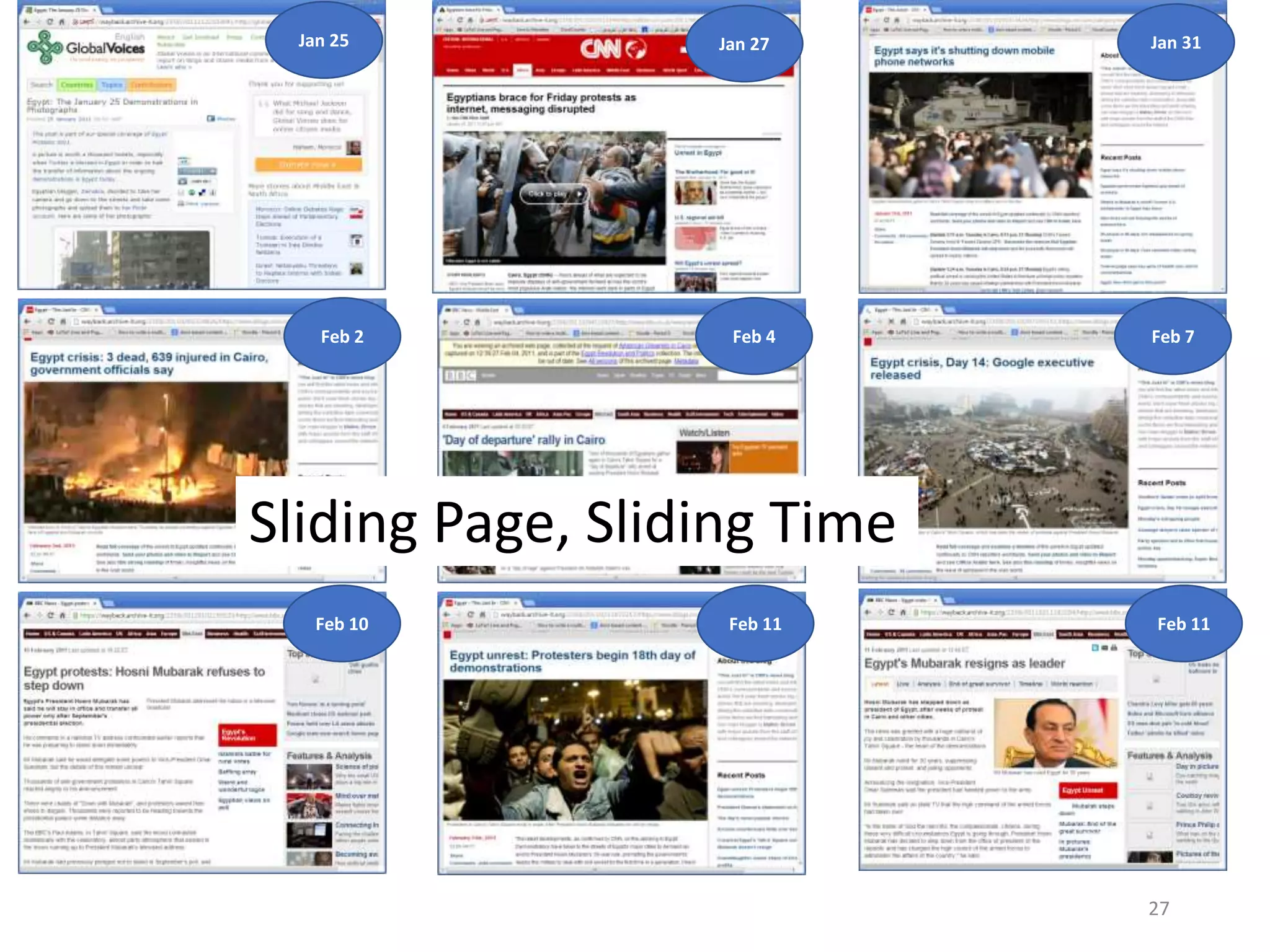



















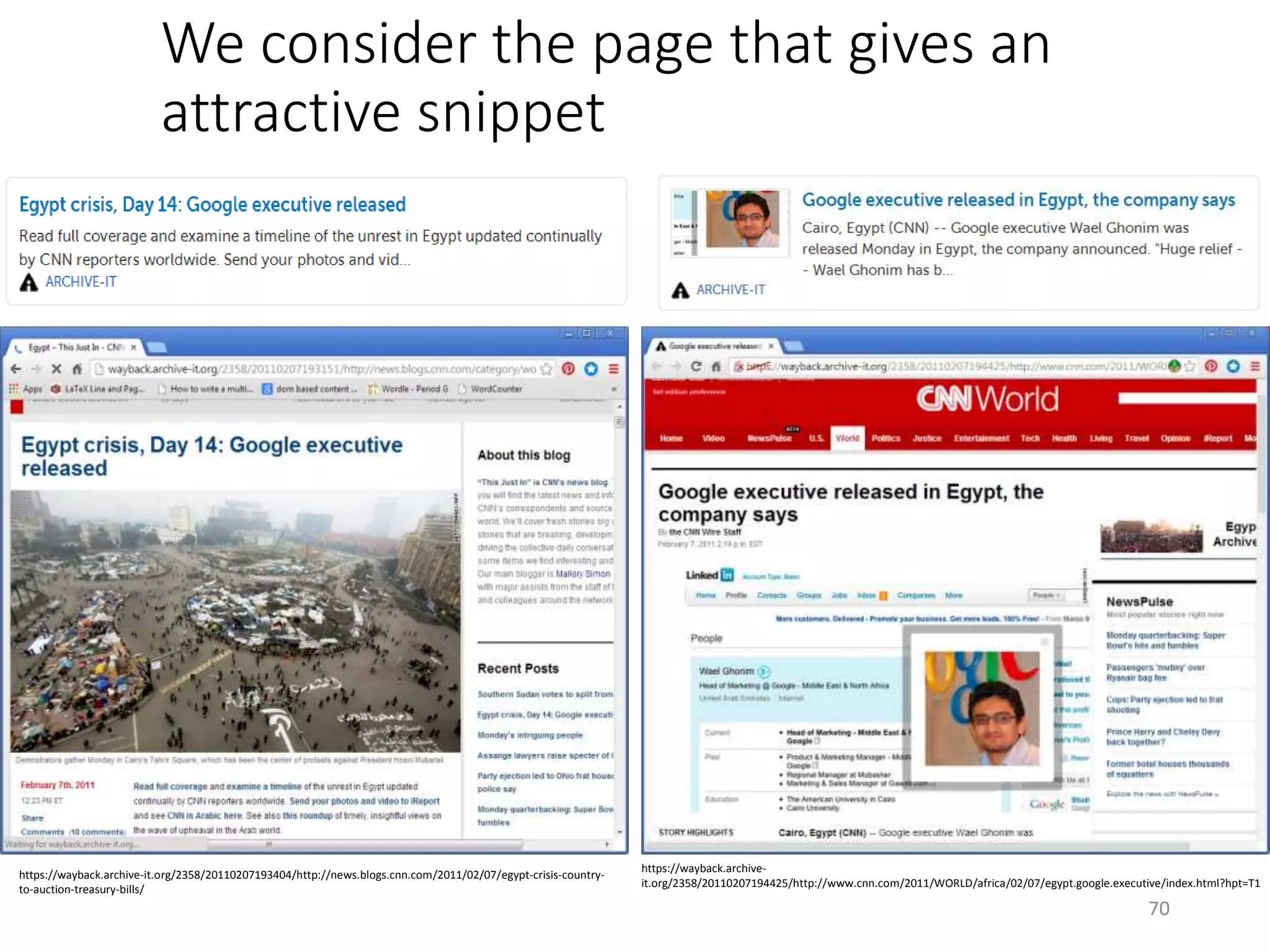



![We extract the metadata of the pages
and order them chronologically
{ "elements":[
{
"permalink":"http://wayback.archive-it.org/694/20070523182134/http://www.usatoday.com/news/nation/2007-04-16-
virginia-tech_N.htm", "type":"link",
"source":{"href":"http://www.usatoday.com",
"name":"www.usatoday.com
@ 23, May 2007"}
},
{
"permalink":"http://wayback.archive-
it.org/694/20070530182159/http://www.time.com/time/specials/2007/vatech_victims", "type":"link",
"source":{"href":"http://www.time.com",
"name":"www.time.com
@ 30, May 2007" }
},
{
"permalink":"http://wayback.archive-it.org/694/20070530182206/http://www.collegiatetimes.com/",
"type":"link", "source":{"href":"http://www.collegiatetimes.com",
"name":"www.collegiatetimes.com
@ 30, May 2007" }
},
{
"permalink":"http://wayback.archive-it.org/694/20070606234248/http://hokies416.wordpress.com/",
"type":"link", "source":{ "href":"http://hokies416.wordpress.com",
"name":"hokies416.wordpress.com
@ 06, Jun 2007" }
},
…
{ "permalink":"http://wayback.archive-it.org/694/20070620234329/http://www.hokiesports.com/april16/",
"type":"link", "source":{"href":"http://www.hokiesports.com",
"name":"www.hokiesports.com
@ 20, Jun 2007" } },
],
"description":"This is an automatically generated story from Archive-It collection.", "title":"April
16 Archive ”
}
76
We override the default
metadata to generate more
attractive snippets](https://image.slidesharecdn.com/2-161017182110/75/Nelson-Michael-Summarizing-Archival-Collections-Using-Storytelling-Techniques-76-2048.jpg)



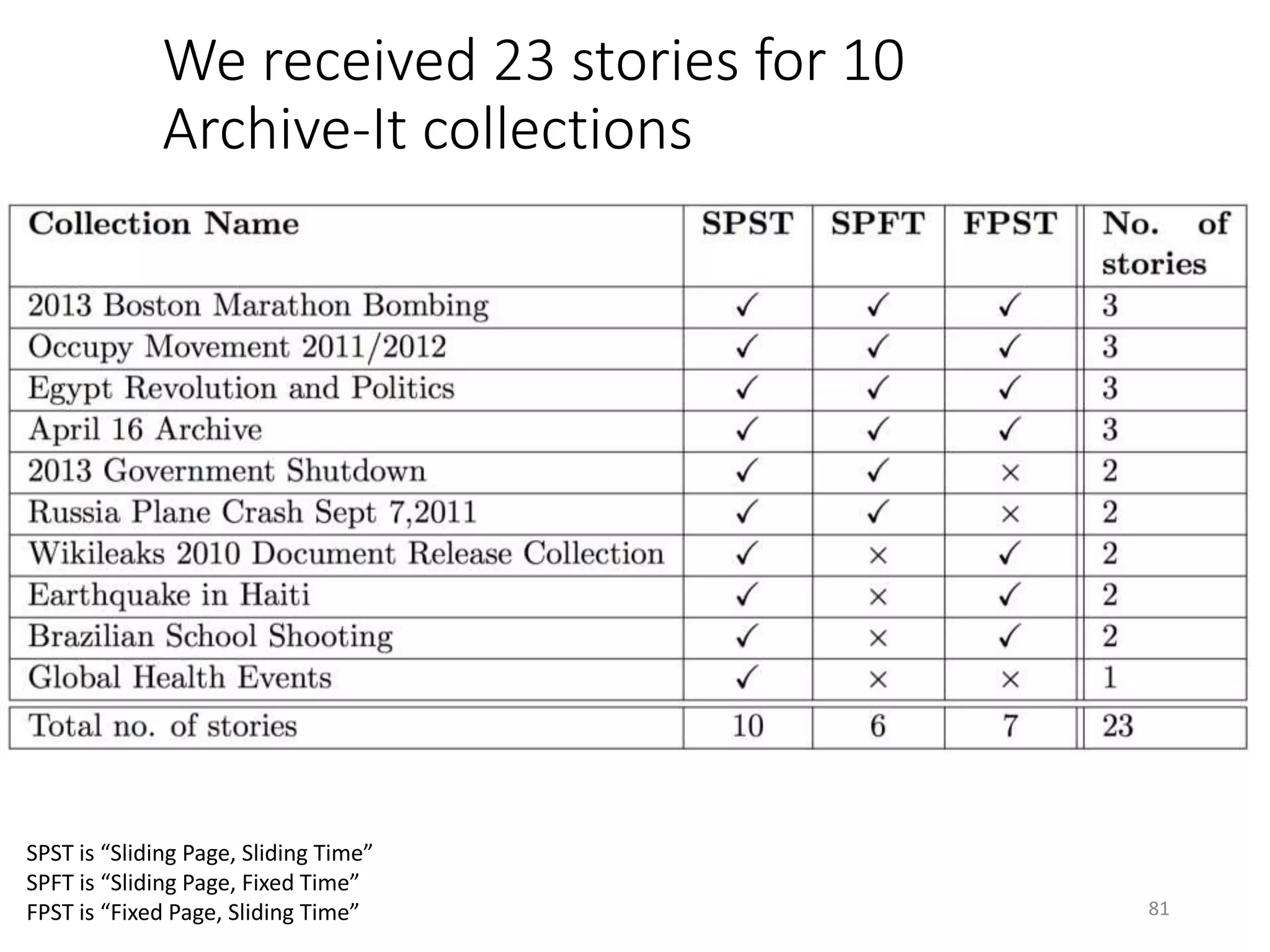
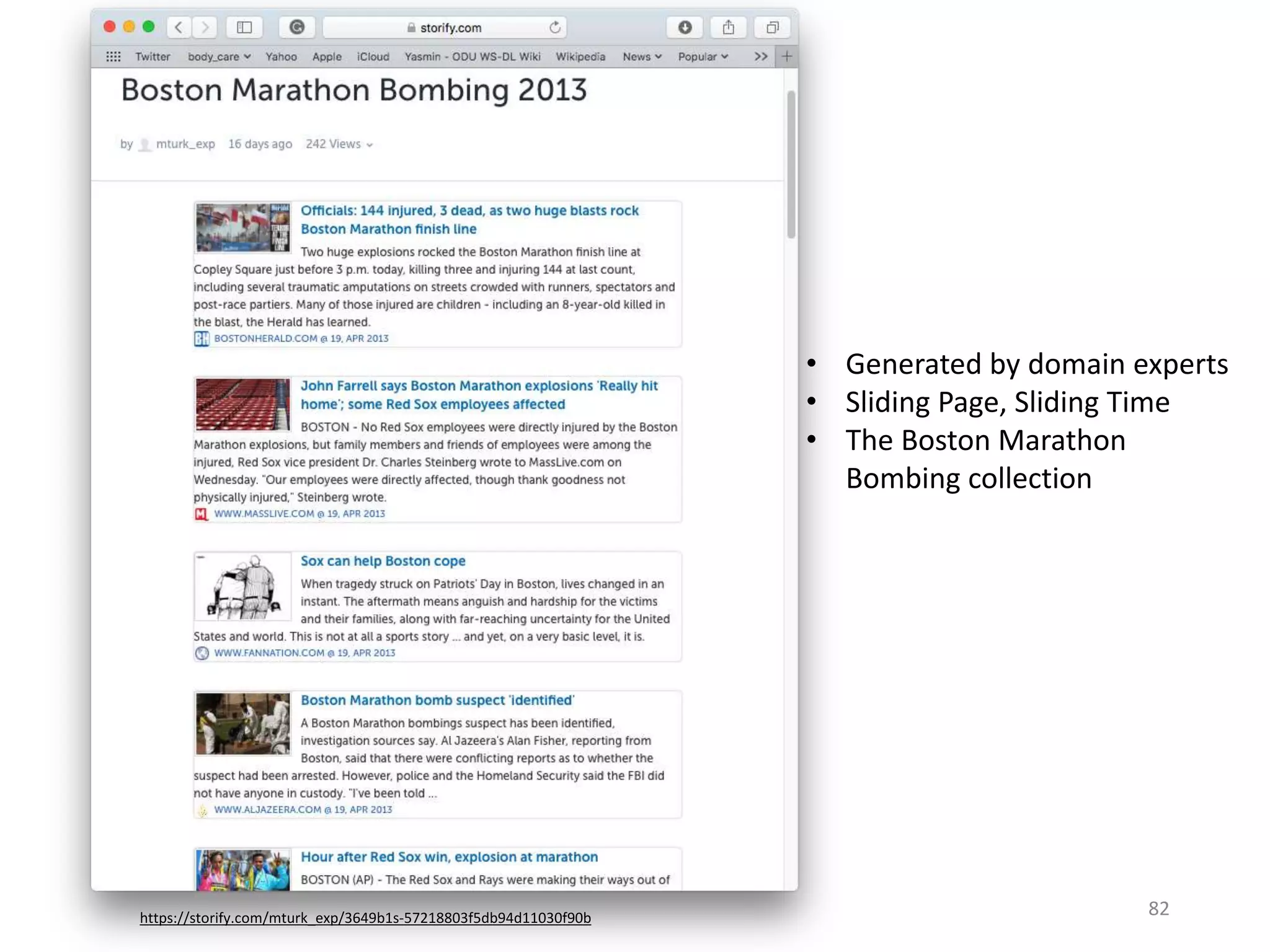

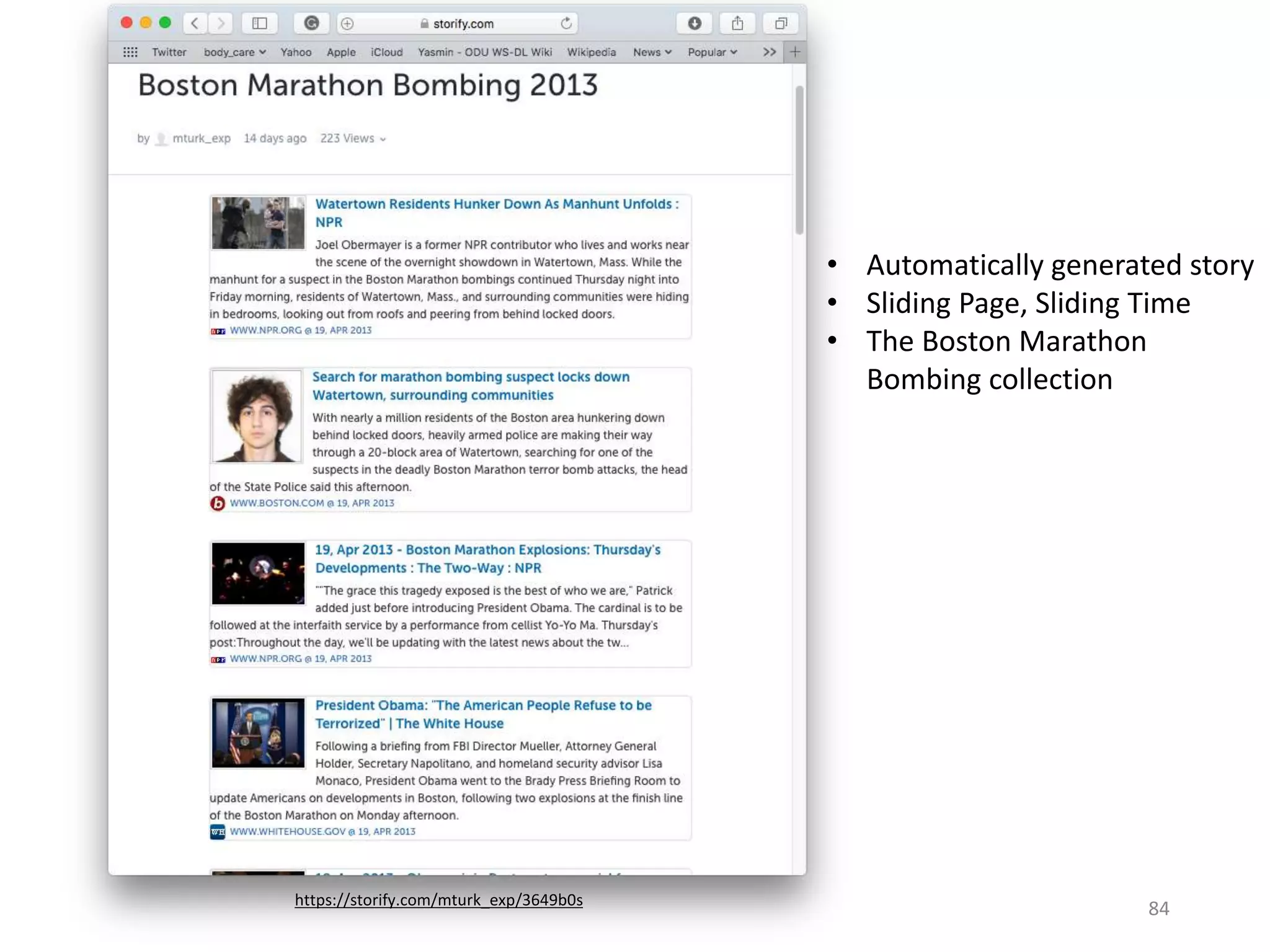

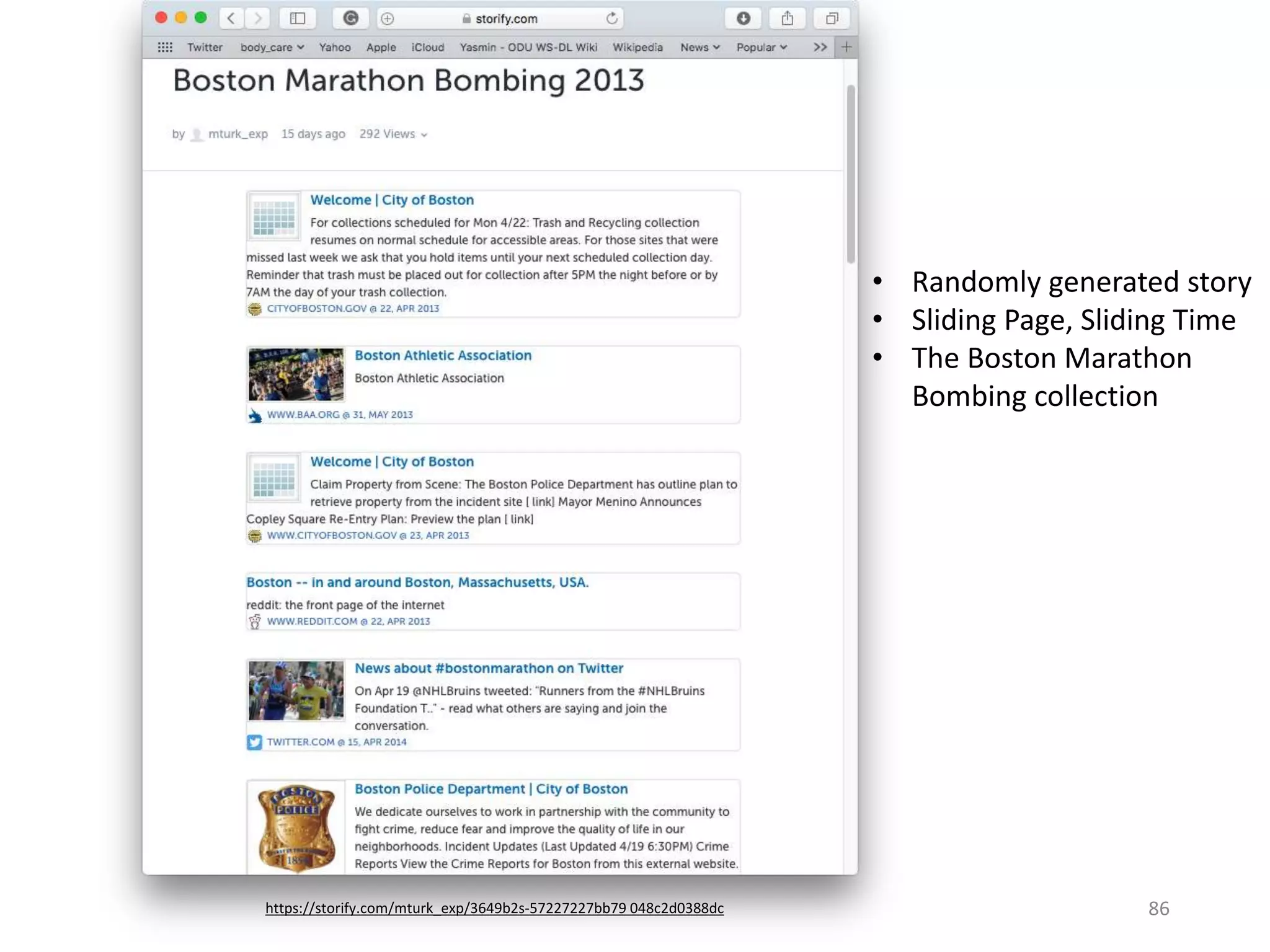

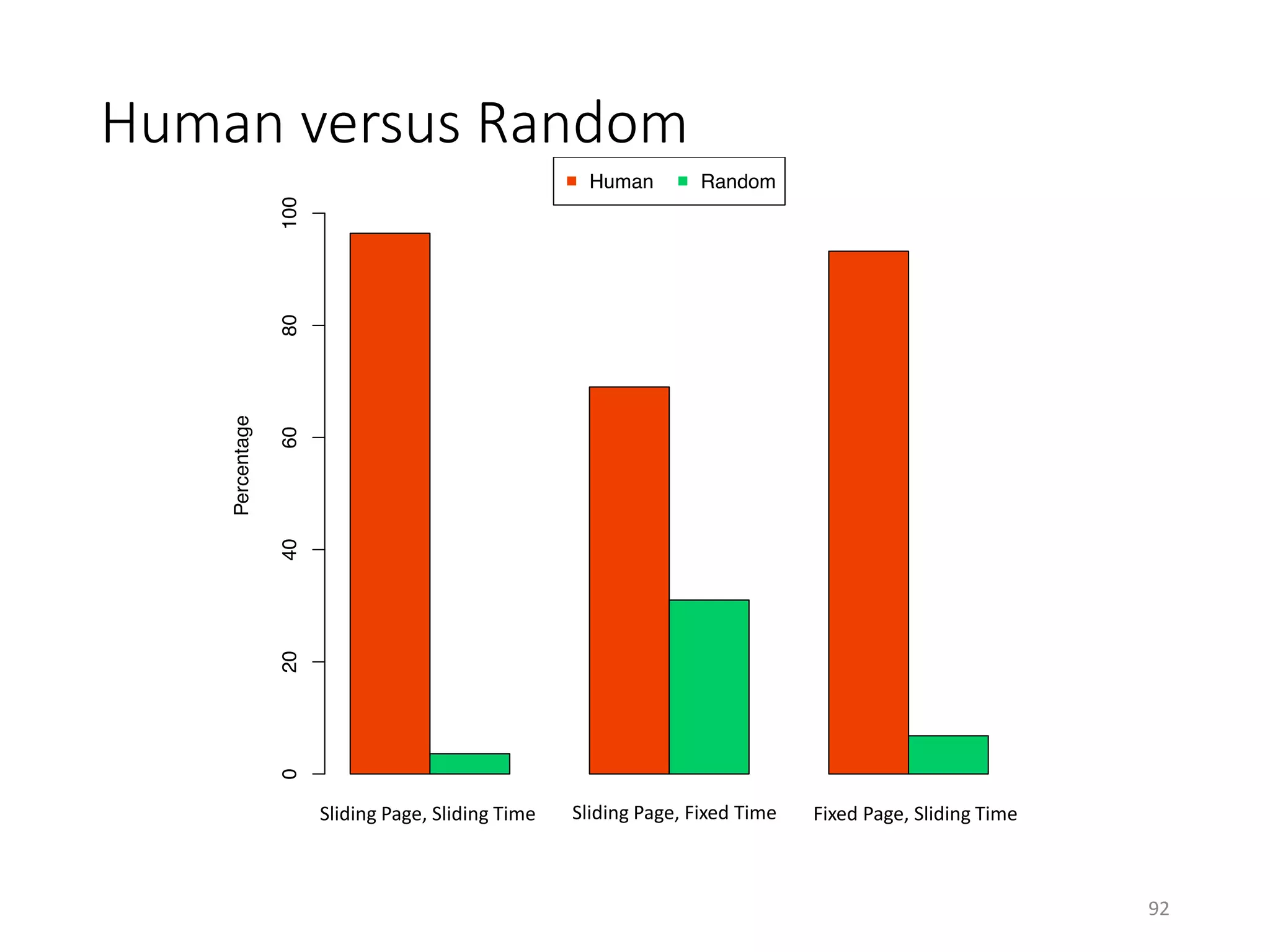
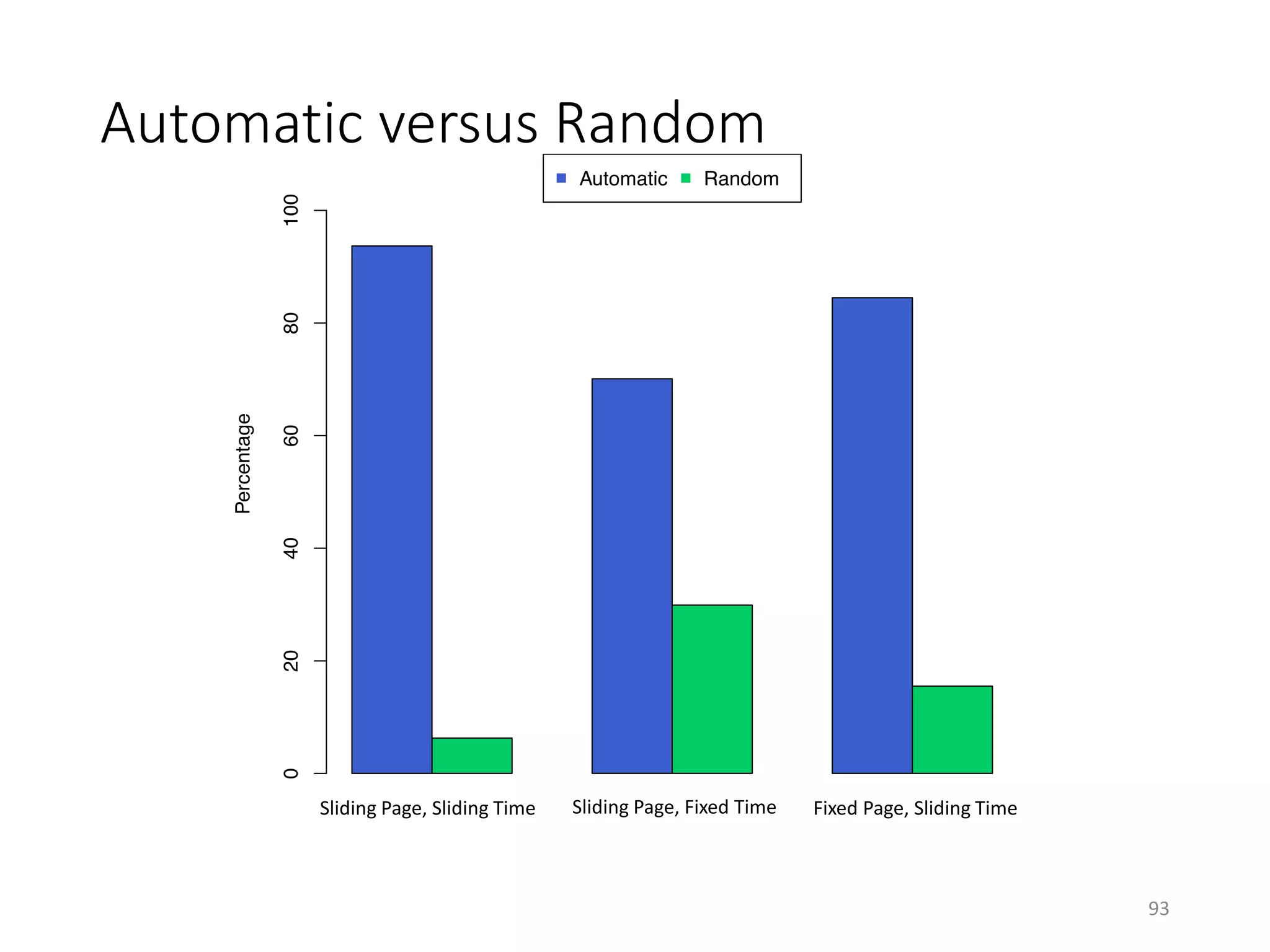

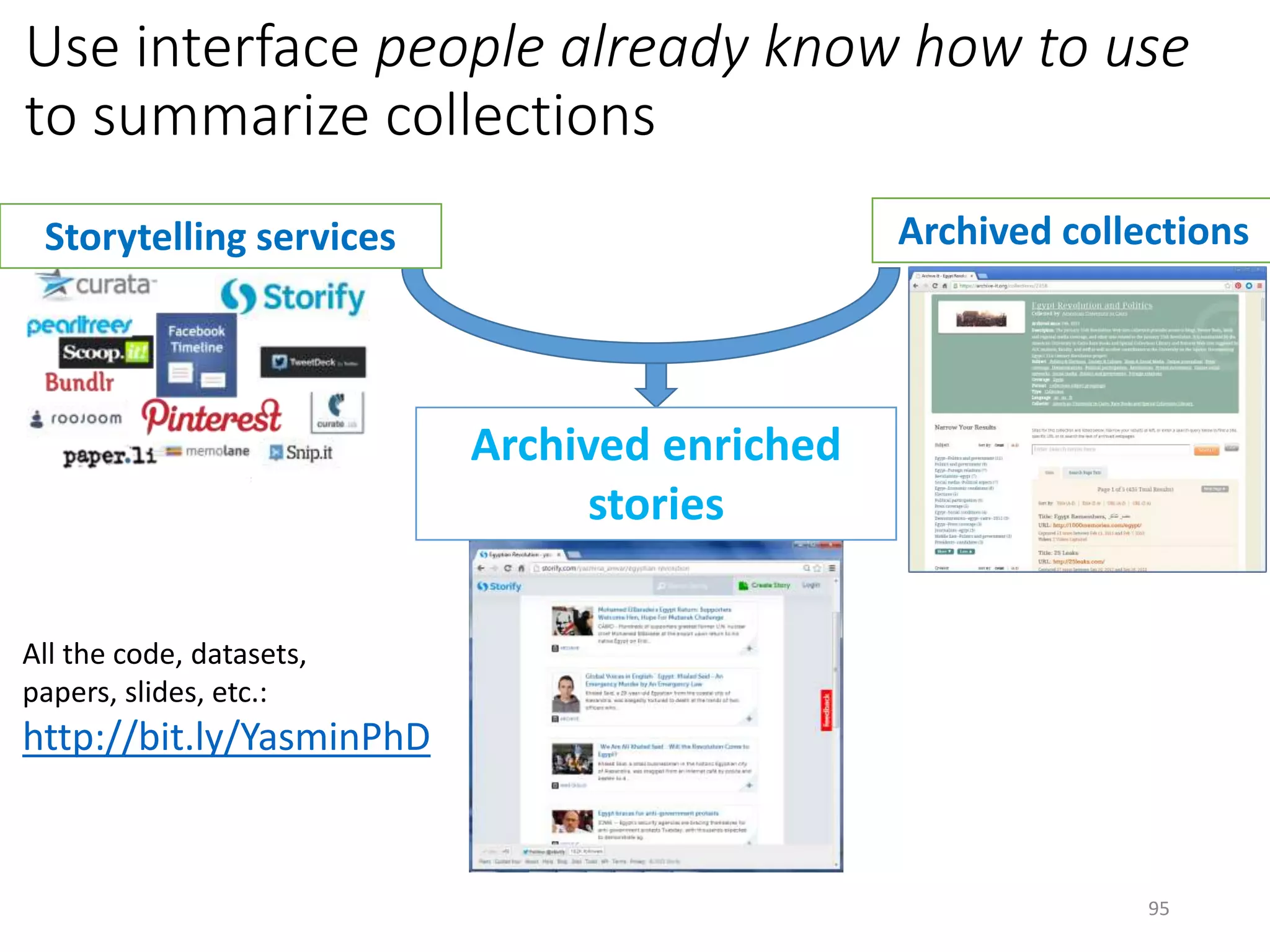

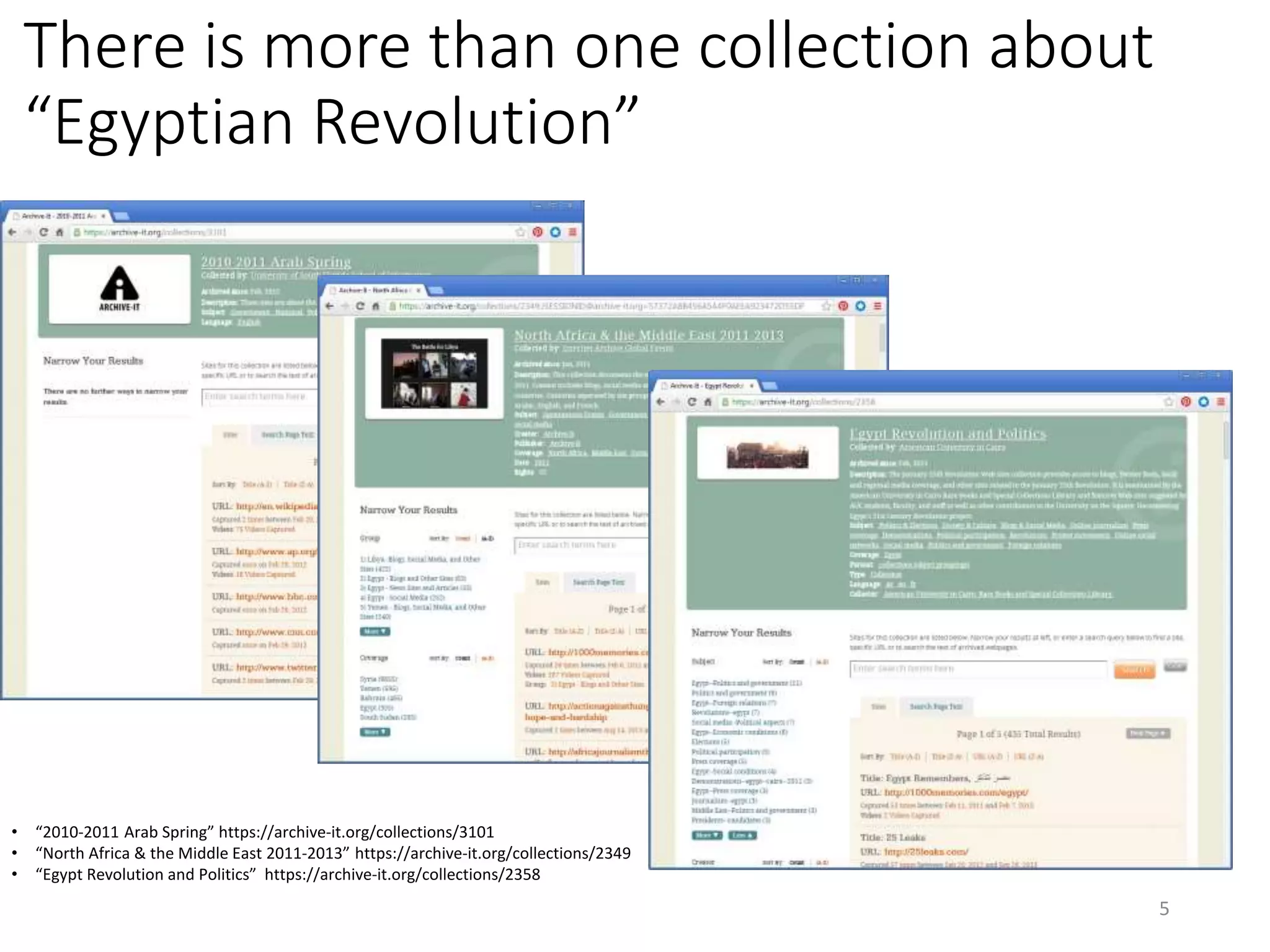
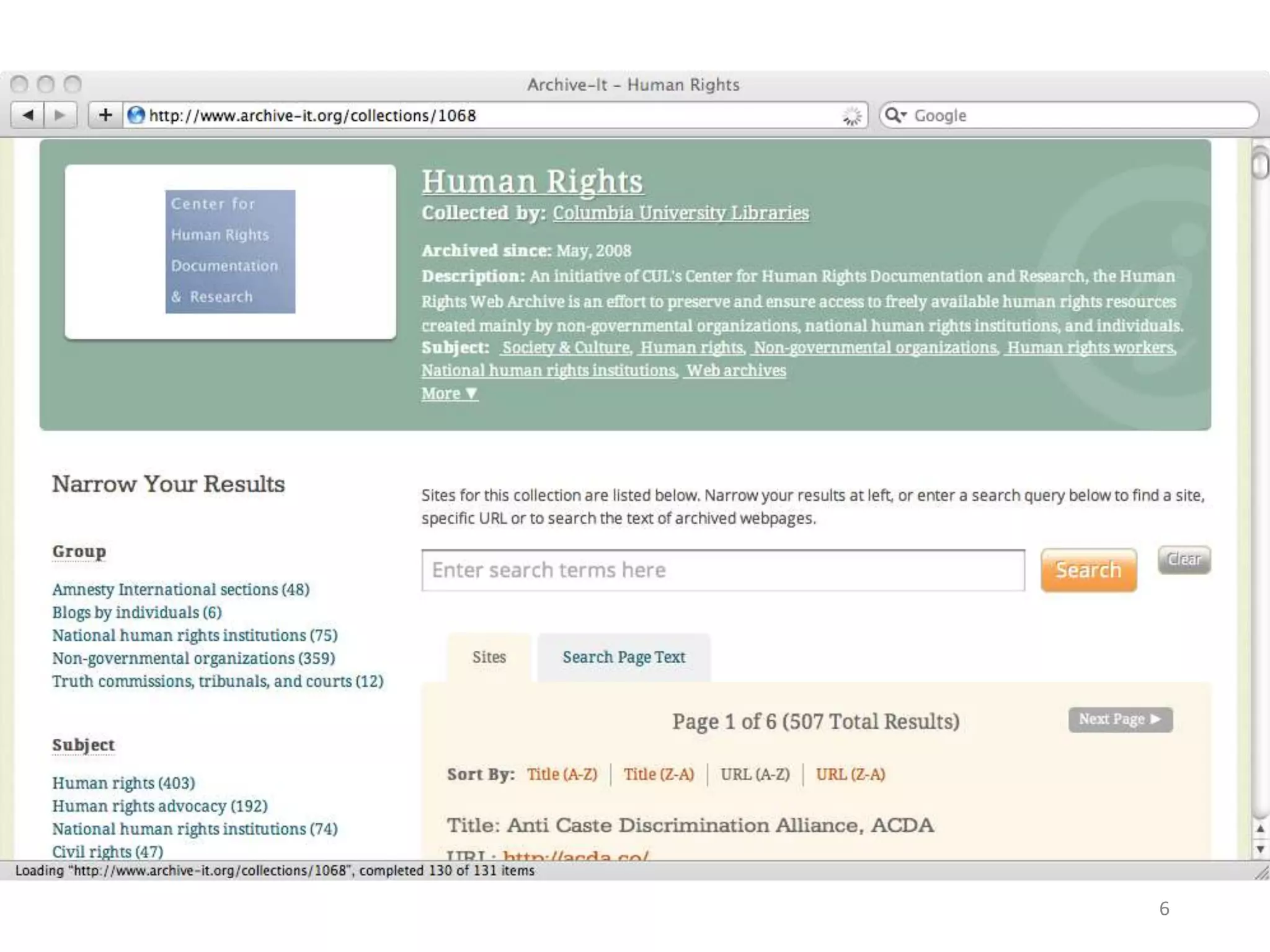
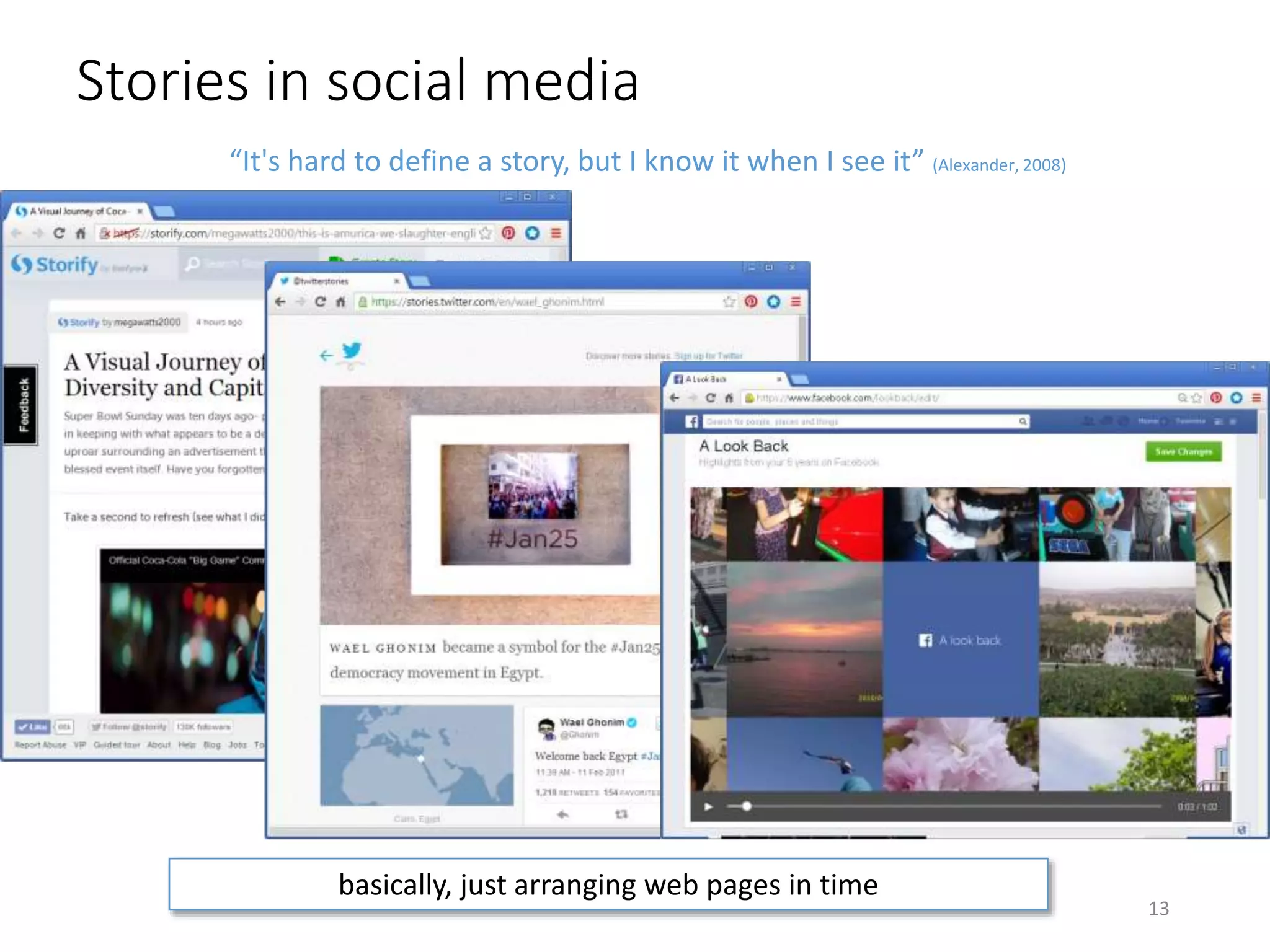
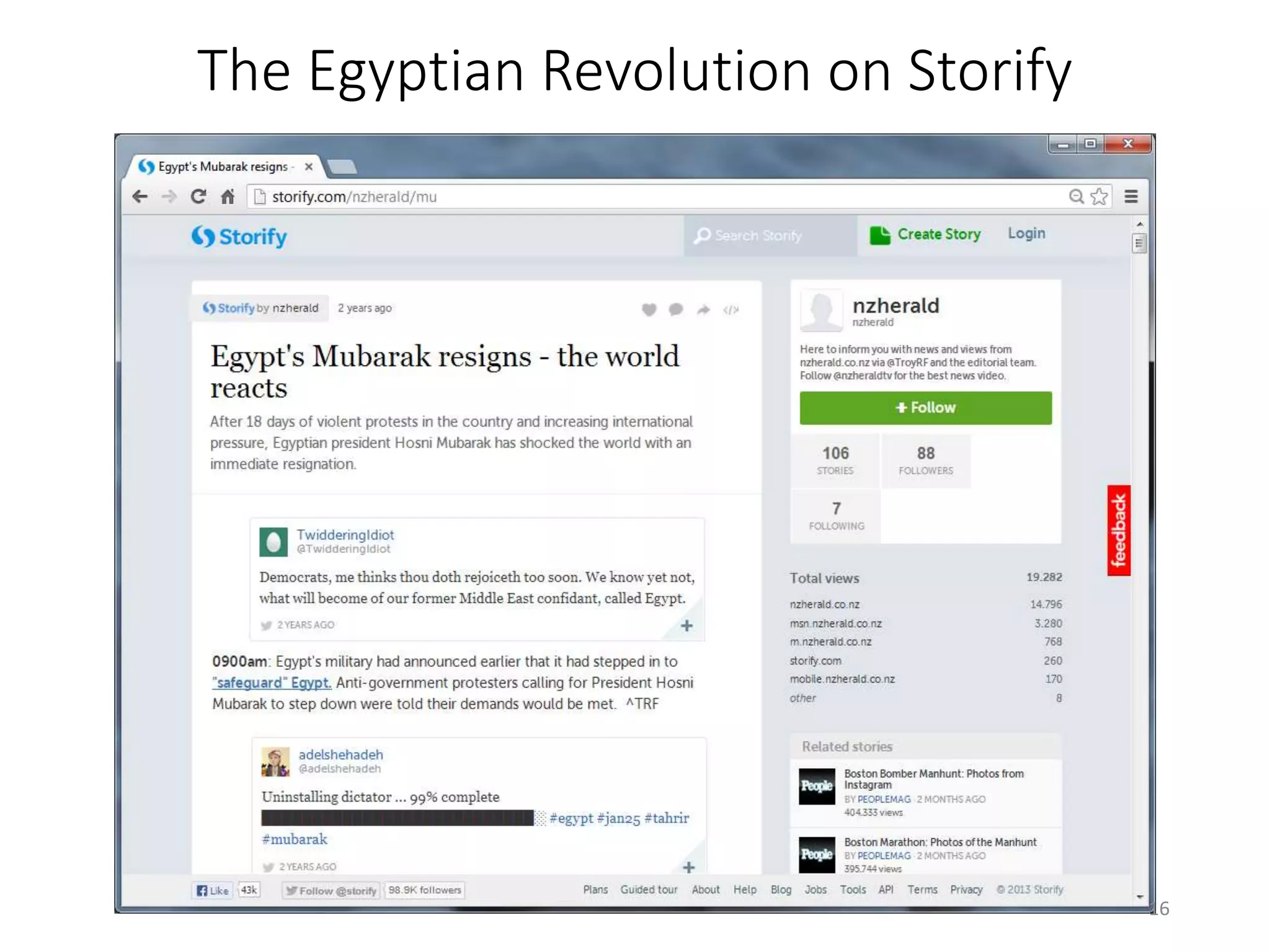
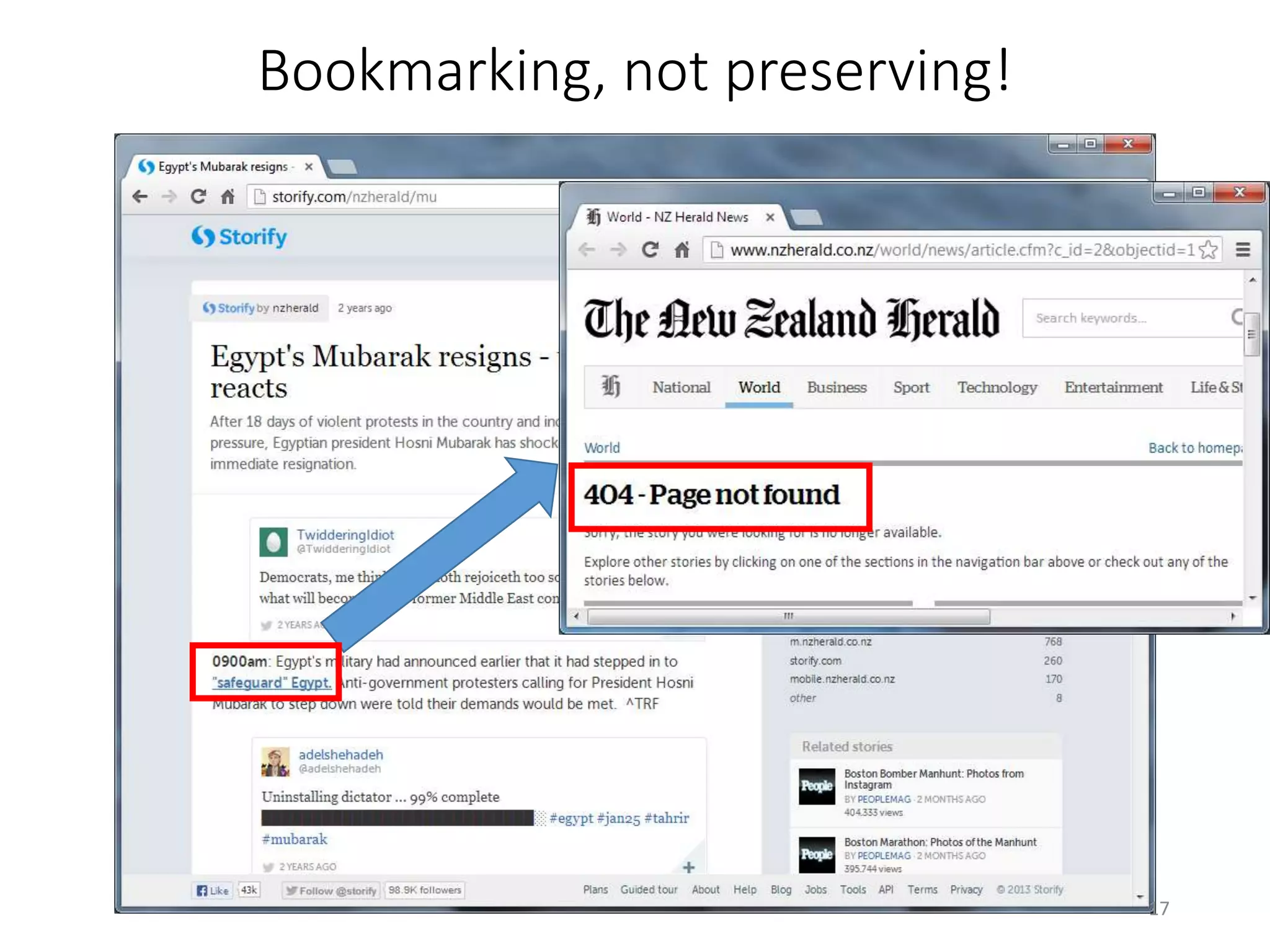
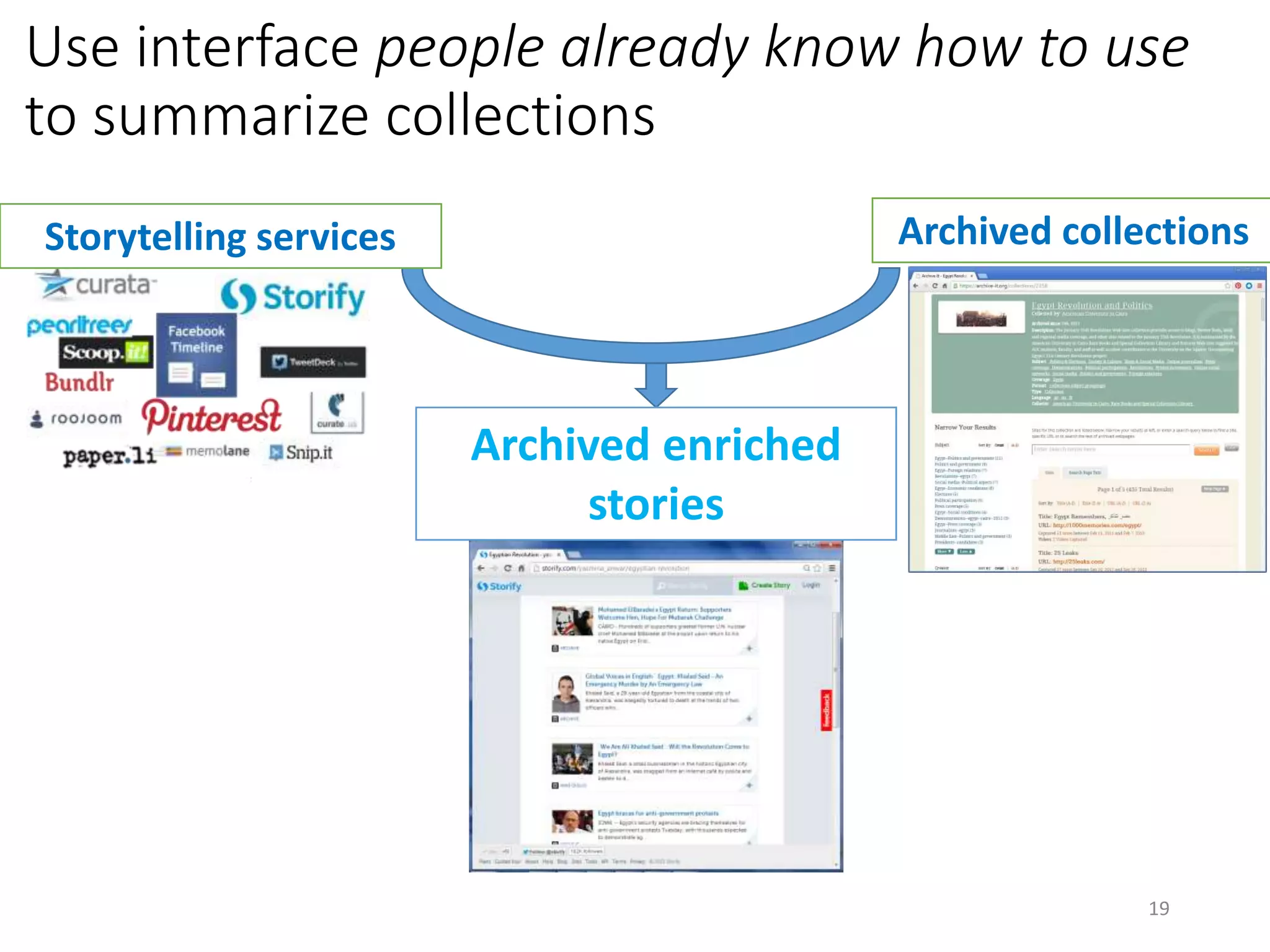
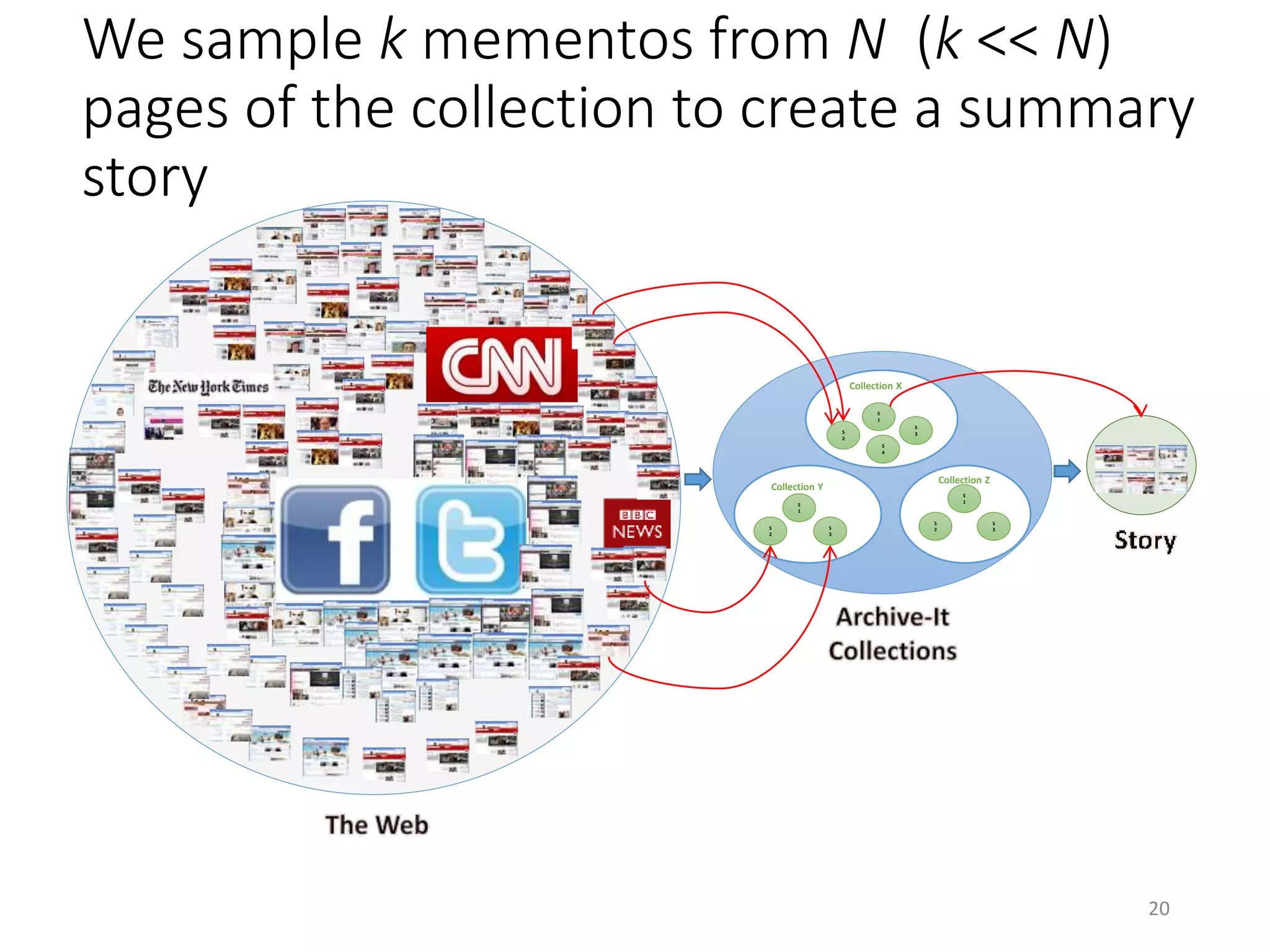
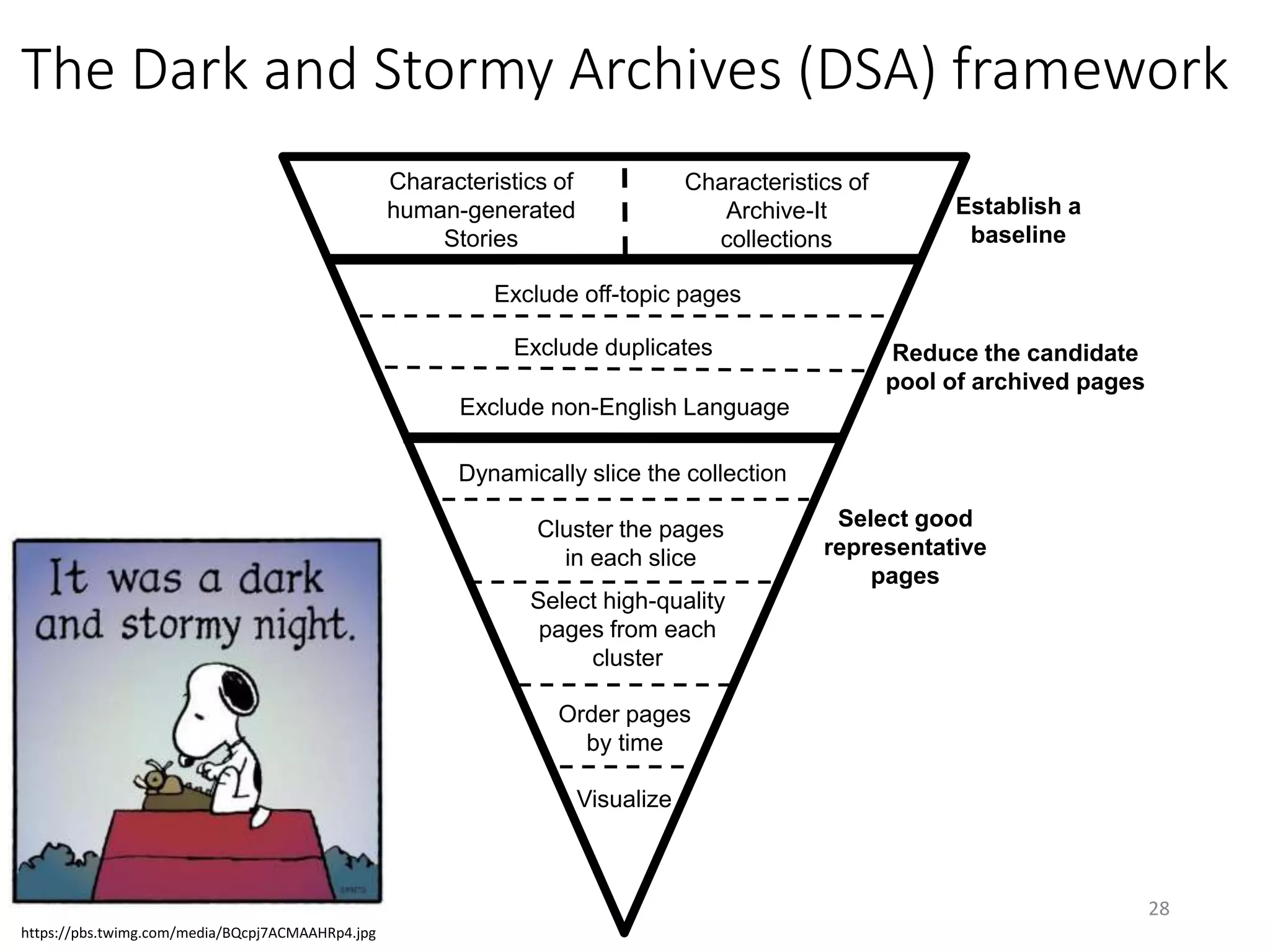
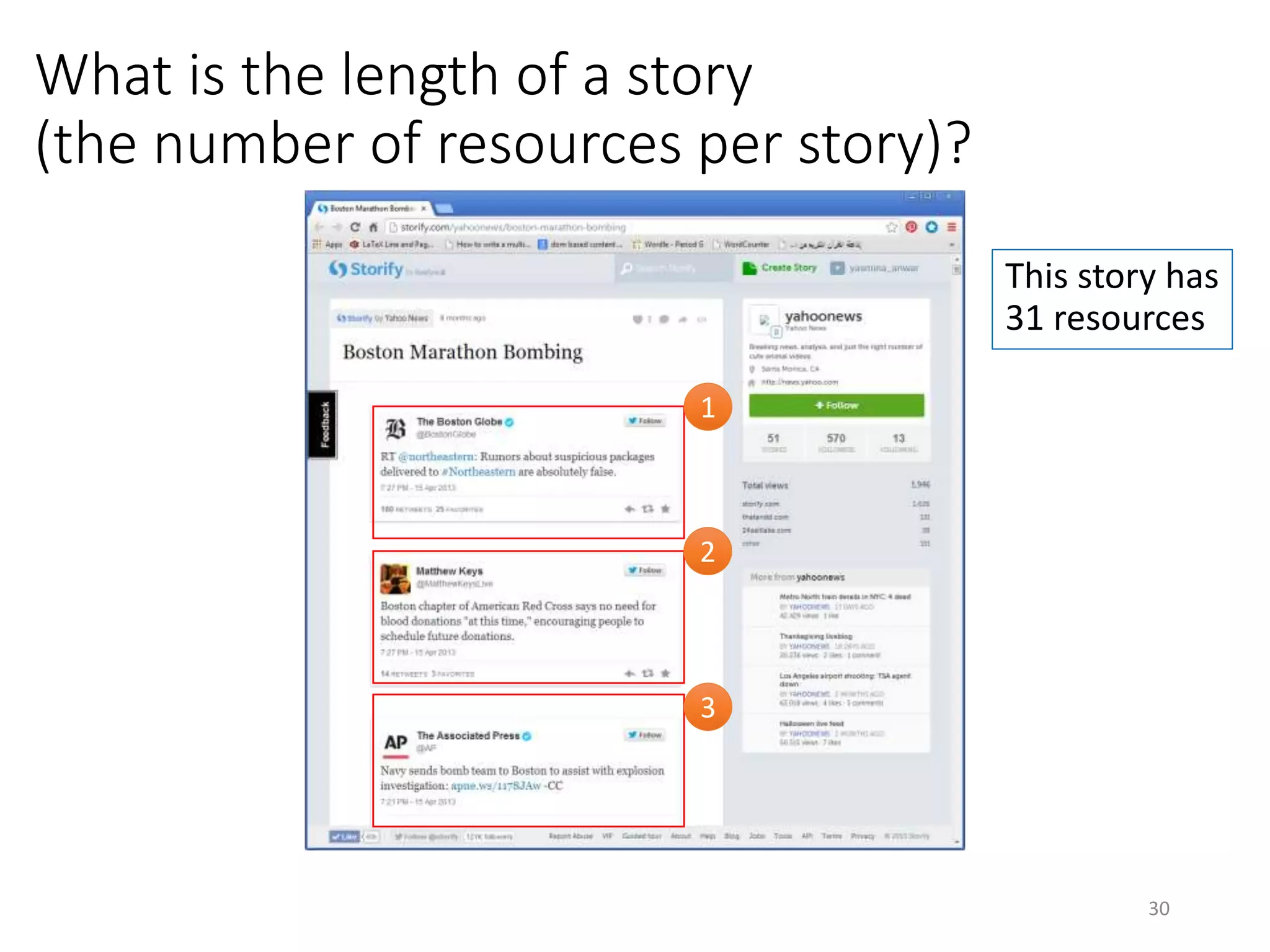
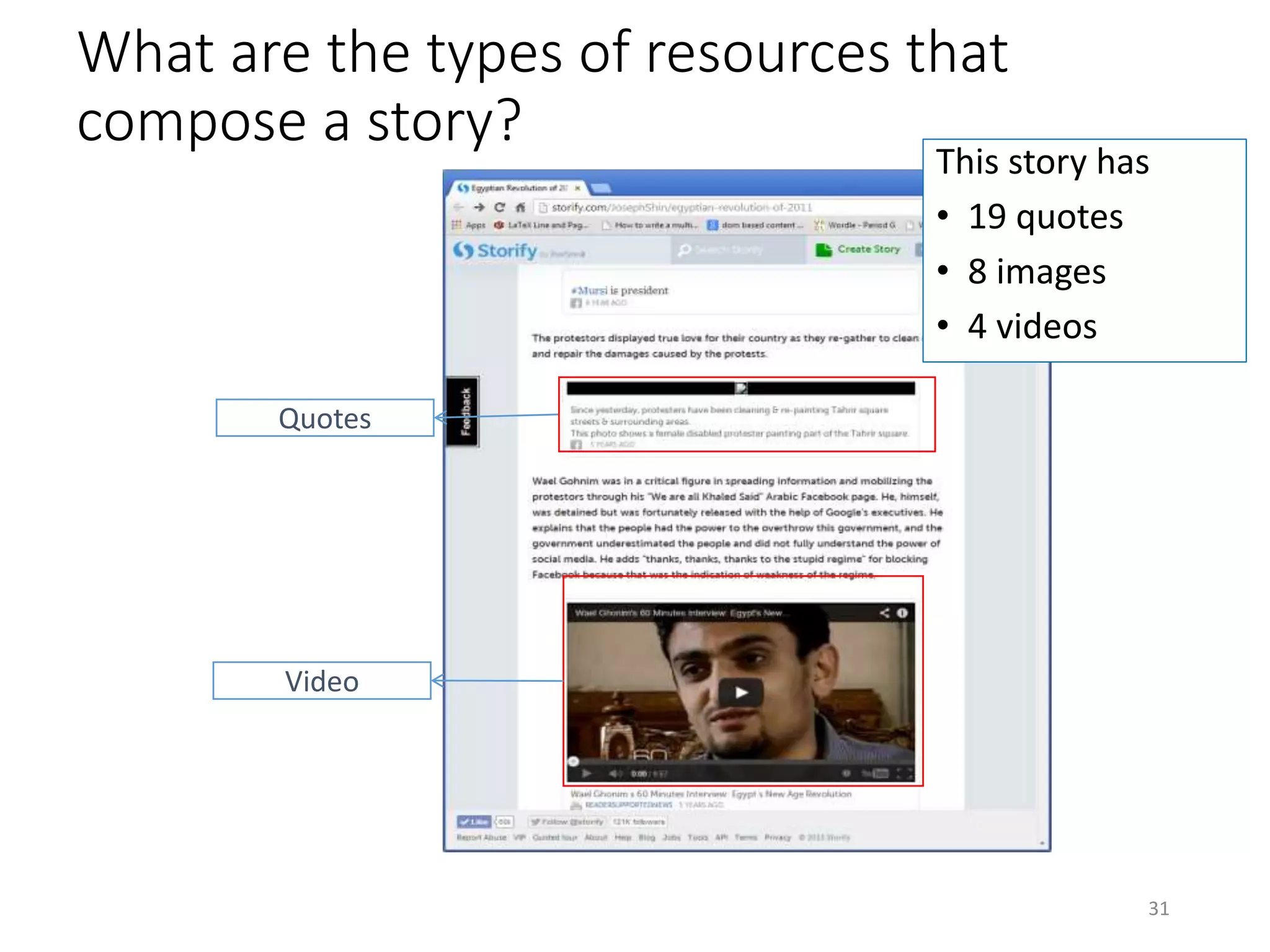
The document discusses techniques for summarizing archival collections using storytelling methods, particularly focusing on the Archive-It service and its collections related to the Egyptian Revolution. It explores the challenges of understanding and differentiating collections and presents a framework for dynamically selecting and visualizing important pages from archived content. The framework aims to enhance user engagement and archive utility by automating the generation of compelling narratives from historical data.



































































