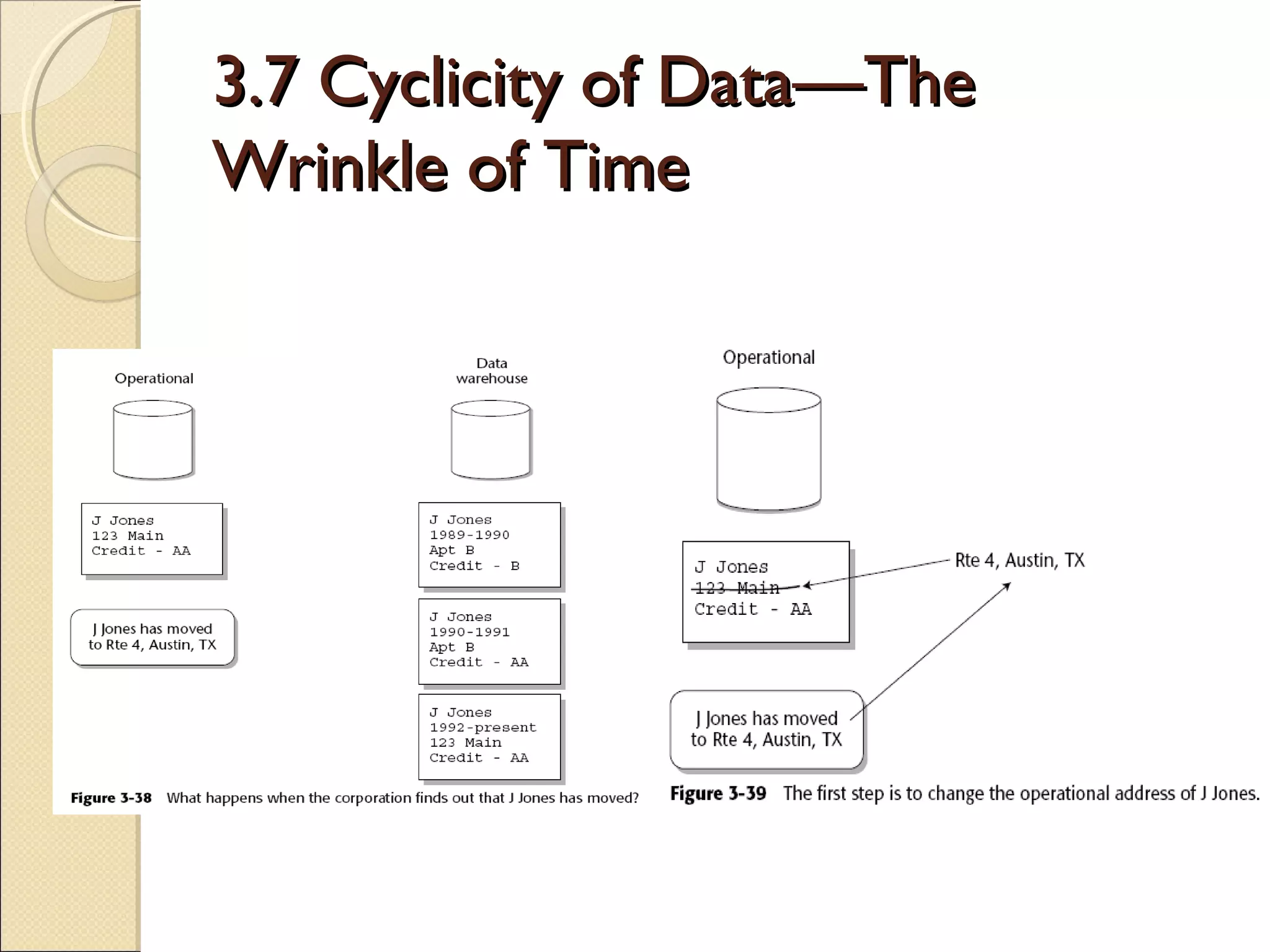
The chapter discusses the design process for building a data warehouse, including designing the interface from operational systems and designing the data warehouse itself. It covers topics like beginning with operational data, data and process models, data warehouse data models at different levels, normalization and denormalization, and managing complexity in transformations and integrations between operational and warehouse systems. The goal is to extract, transform, and load relevant data from operational sources into the data warehouse in a way that supports analysis and decision-making.