Downloaded 423 times





































![NoSQL Taxonomy
by Steve Yen [PG]
key‐value‐cache: memcached, repcached, coherence [?], infinispan, eXtreme scale, jboss
cache, velocity, terracota [???]
key‐value‐store: keyspace [w/Paxos], flare, schema‐free, RAMCloud [, Mnesia (Erlang),
Chordless]
eventually‐consistent key‐value‐store: dynamo, Voldemort, Dynomite, SubRecord,
MotionDb, Dovetaildb
ordered‐key‐value‐store: tokyo tyrant[, BerkleyDB], lightcloud, NMDB, luxio, memcachedb,
actord
data‐structures server: redis
tuple‐store: gigaspaces [?], coord, apache river
object database: ZopeDB, db4o, Shoal
document store: CouchDB [evC, MVCC], MongoDB [evC], Jackrabbit, XML Databases,
ThruDB, CloudKit, Perservere, Riak Basho [evC], Scalaris [Erlang, w/Paxos]
wide columnar store: BigTable, Hadoop HBase [w/ Zookeeper], [Amazon Dynamo-evC, ]
Cassandra [evC], Hypertable, KAI, OpenNeptune, Qbase, KDI
[graph database: Neo4J, Sones, etc.]
44
From Steve Yen’s slideware (slide 54) he used for his “No SQL is a Horseless Carriage” talk at NoSQL Oakland 2009:
http://dl.dropbox.com/u/2075876/nosql-steve-yen.pdf
I do not completely understand or agree with Steve’s criteria but it sure is a possible starting point on building a
database/storage taxonomy.
The stuff in square brackets is mine. “evC” means Eventually Consistent and “?” just means I have doubts / don’t
understand some specific classification.](https://image.slidesharecdn.com/codebits2009-paulogaspar7-dataconsistency-notes-091221221034-phpapp01/85/Distributed-Programming-and-Data-Consistency-w-Notes-44-320.jpg)


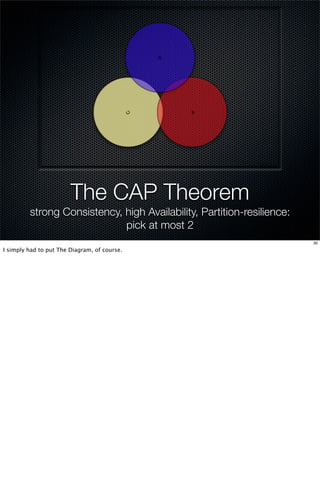
This document discusses distributed programming and data consistency. It defines consistency as how systems and observers perceive the state of a system over time. Consistency has a time aspect, where expected and unexpected sequences of states can occur. Distributed systems like caching introduce inconsistencies when data is replicated across servers. The CAP theorem states that a distributed system cannot simultaneously provide consistency, availability, and partition tolerance. Eventual consistency prioritizes availability over strong consistency.















































