Download to read offline



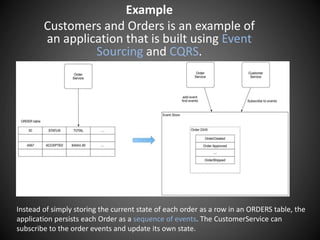
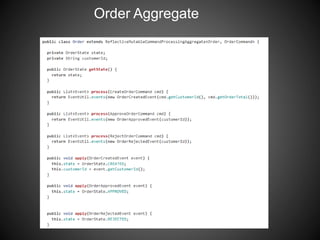




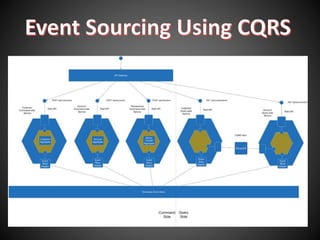








The document discusses the use of event sourcing to reliably publish events during state changes in applications, highlighting its atomicity by persisting state as events. It contrasts the advantages of event sourcing with challenges in object-relational mapping and describes the concept of eventual consistency in distributed systems, including the CAP theorem. Additionally, it introduces the Eventuate framework, which facilitates event-driven programming for microservices, focusing on features like automatic event publishing and support for temporal queries.



























































![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)
![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)




