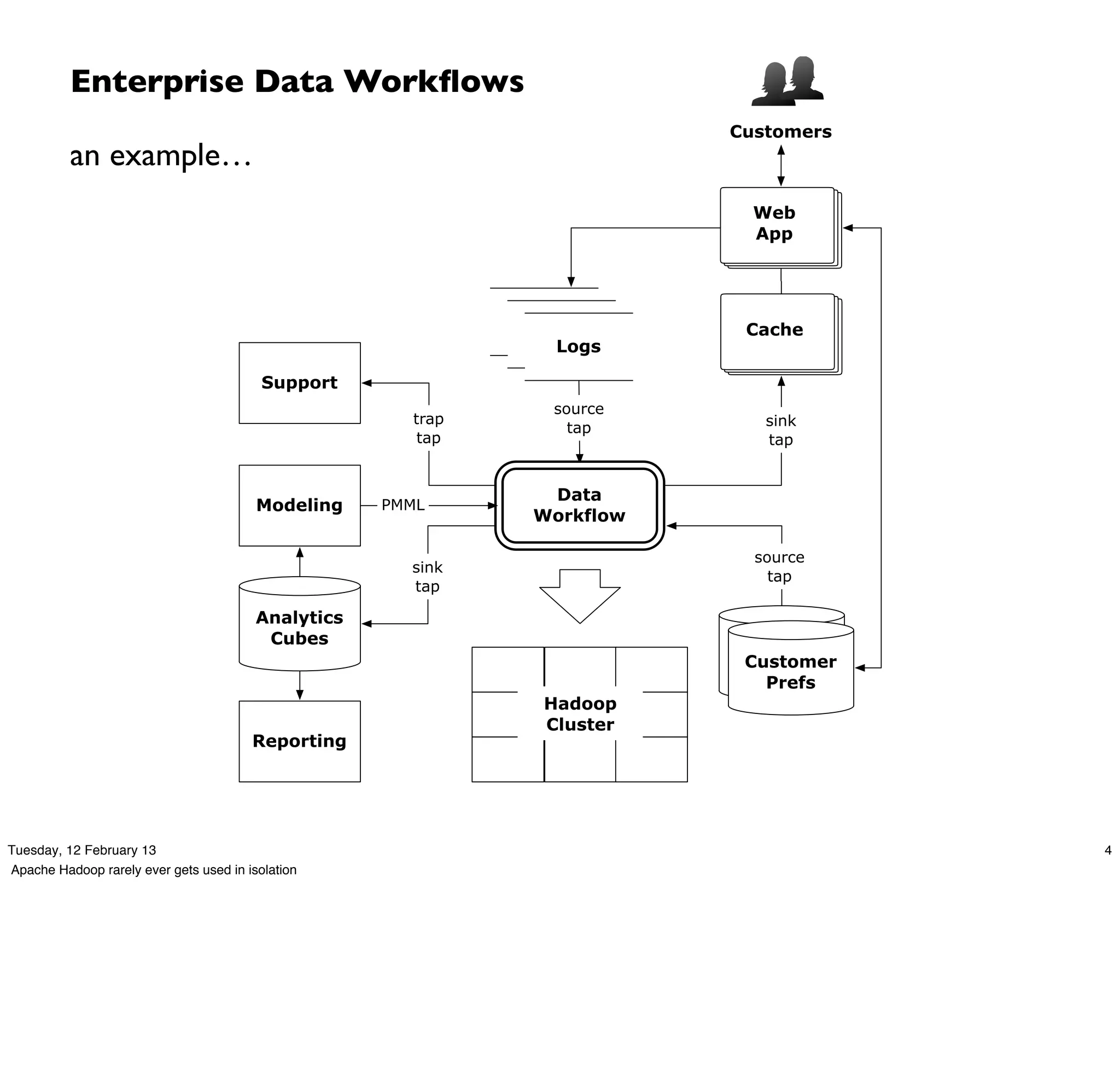
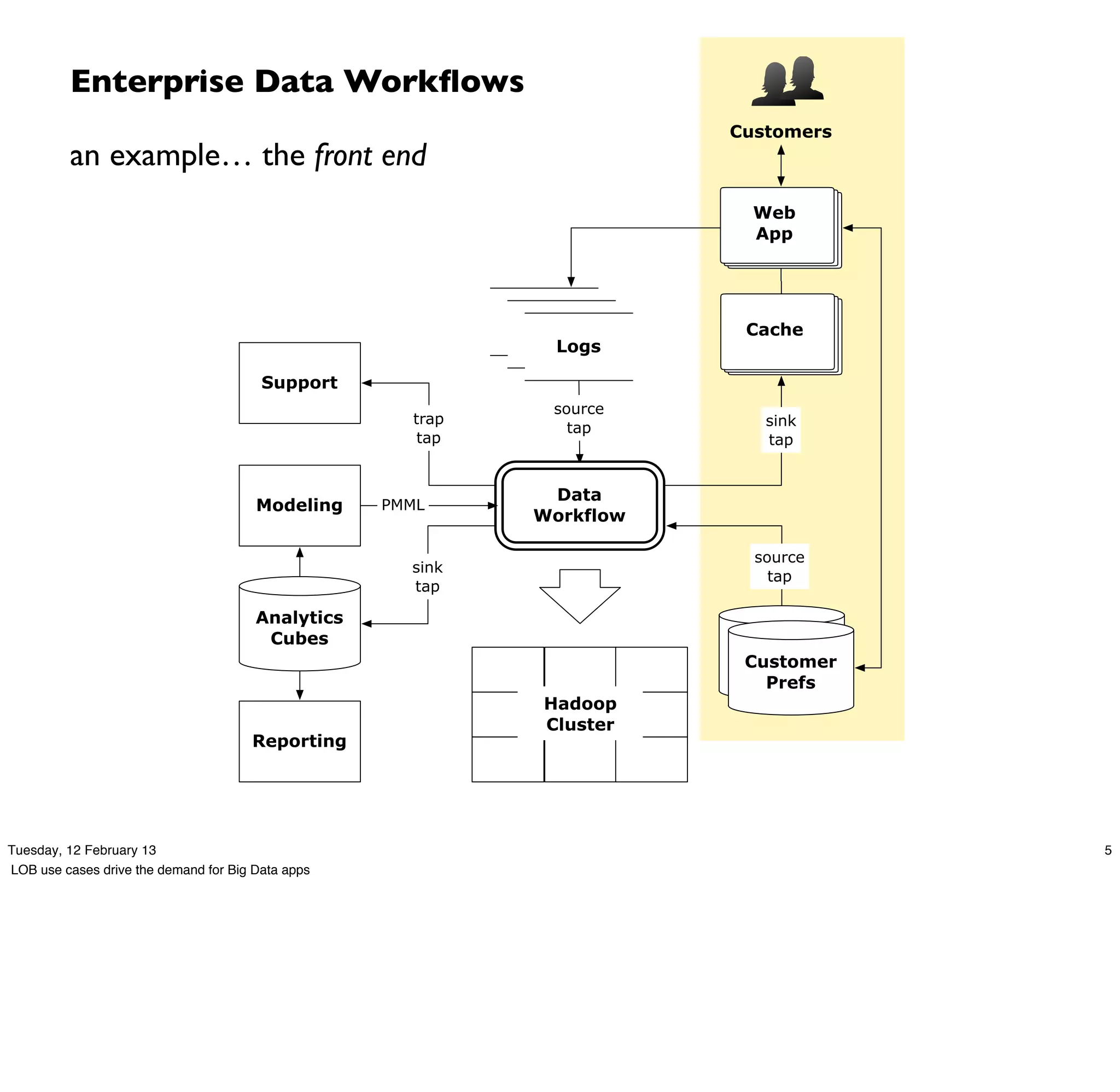
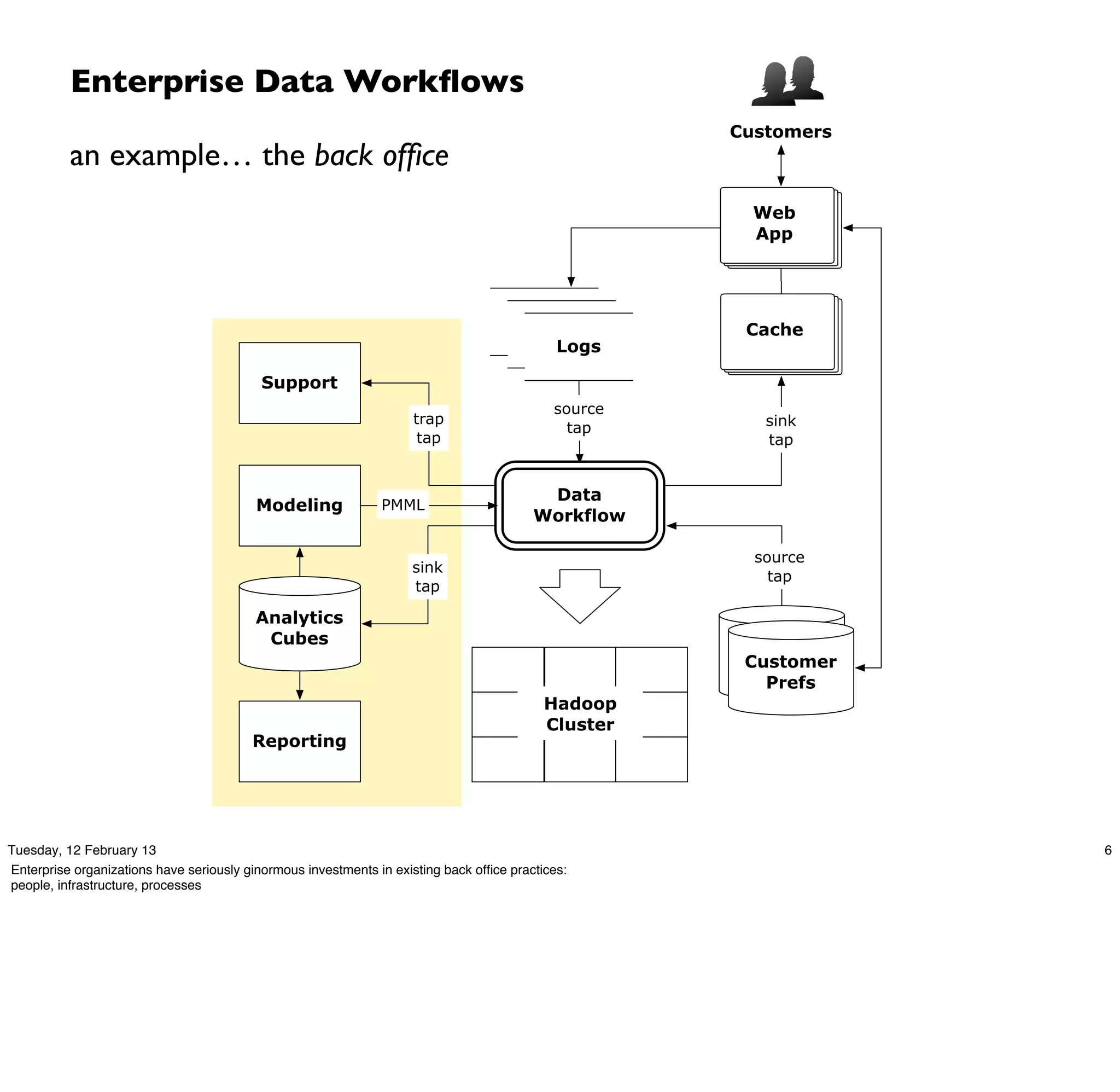
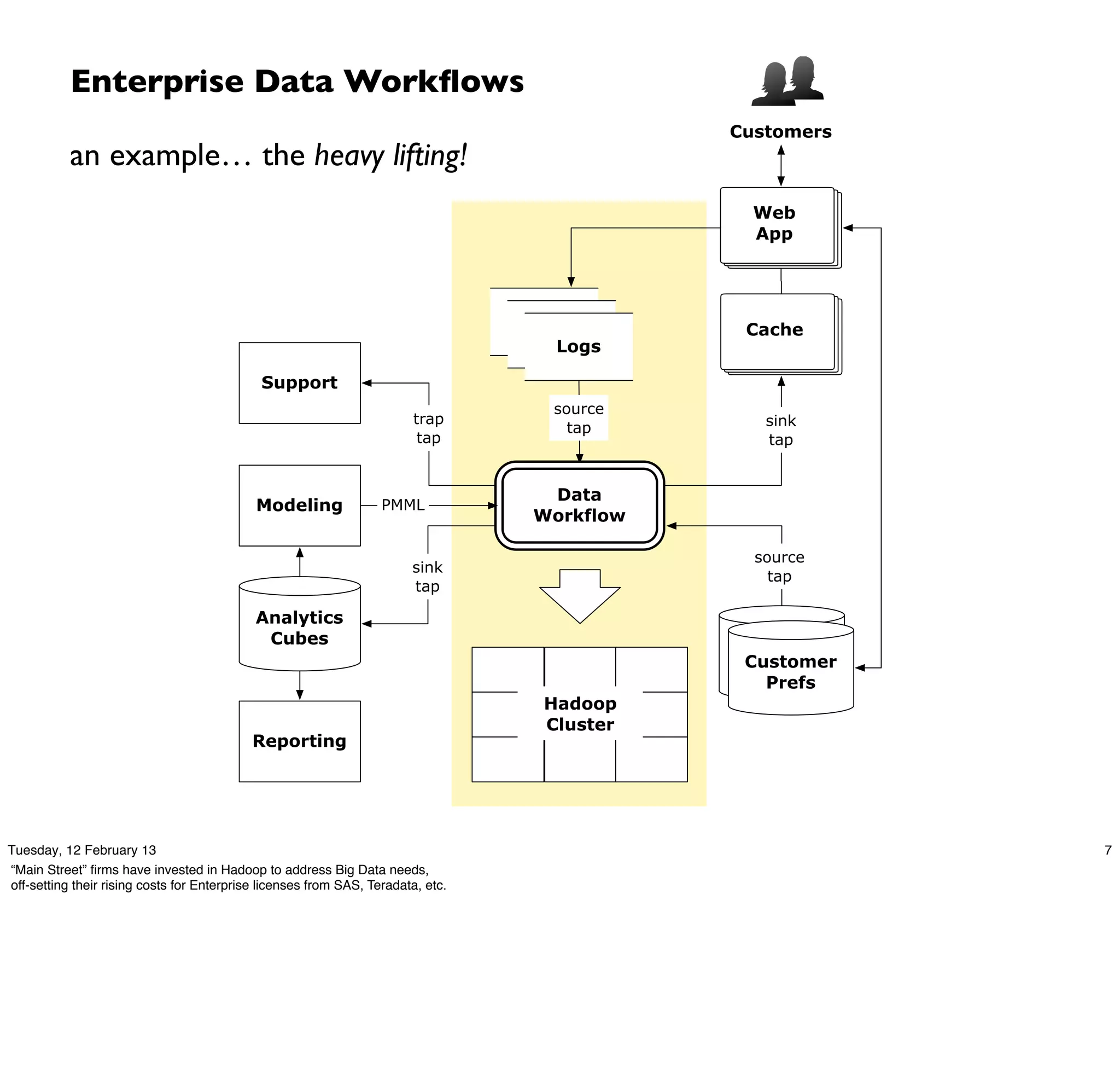
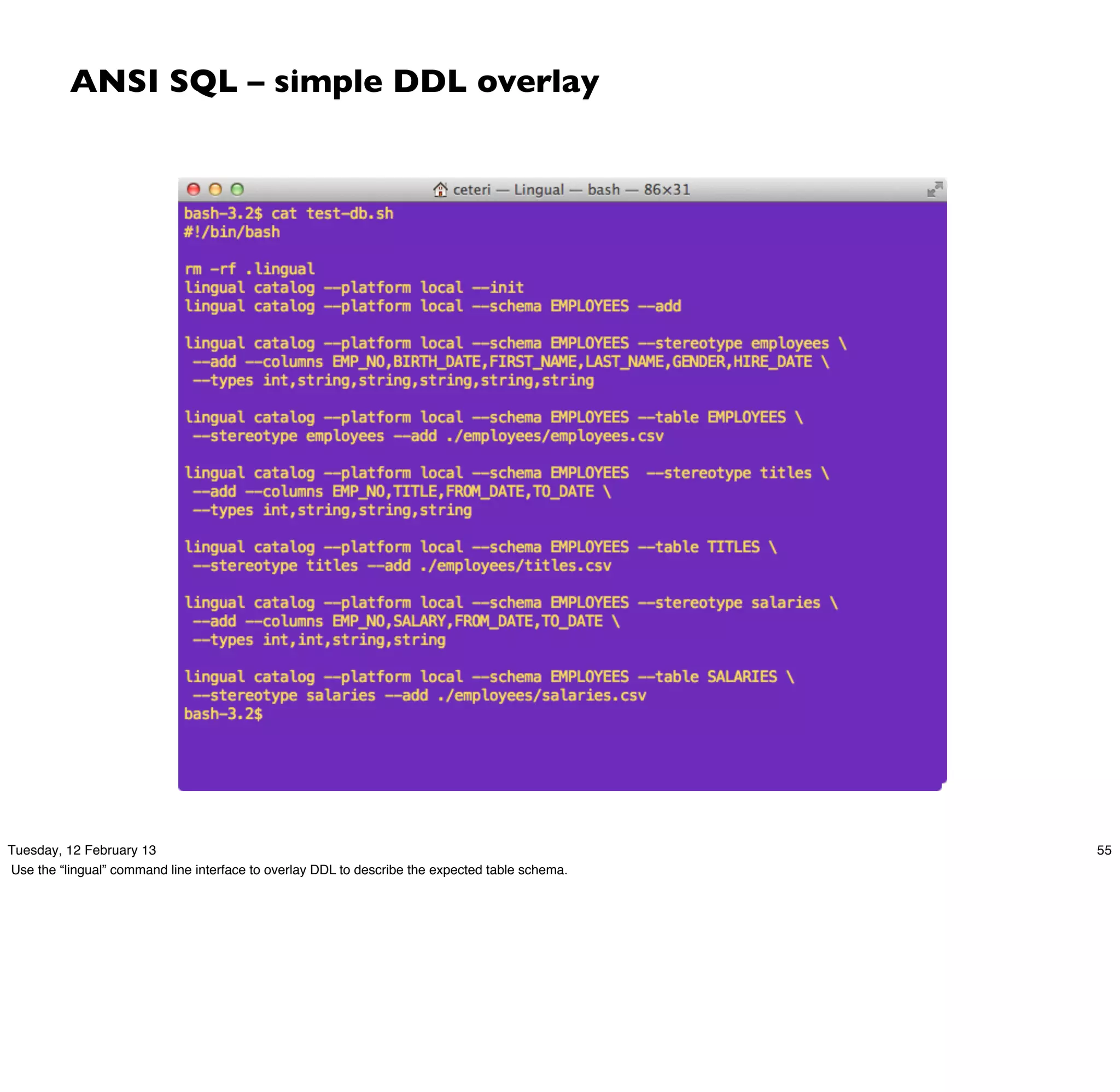
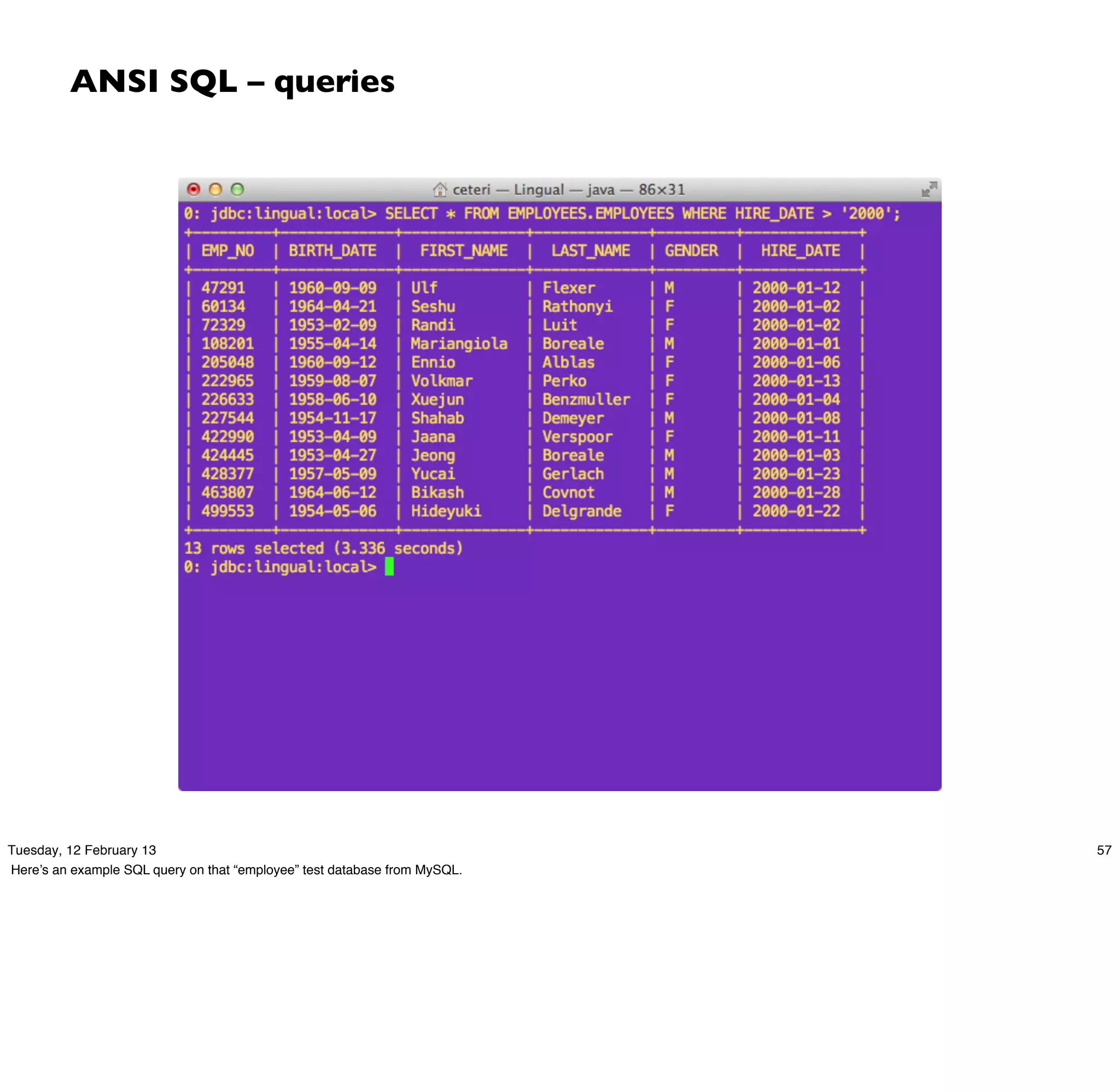
Download as PDF, PPTX













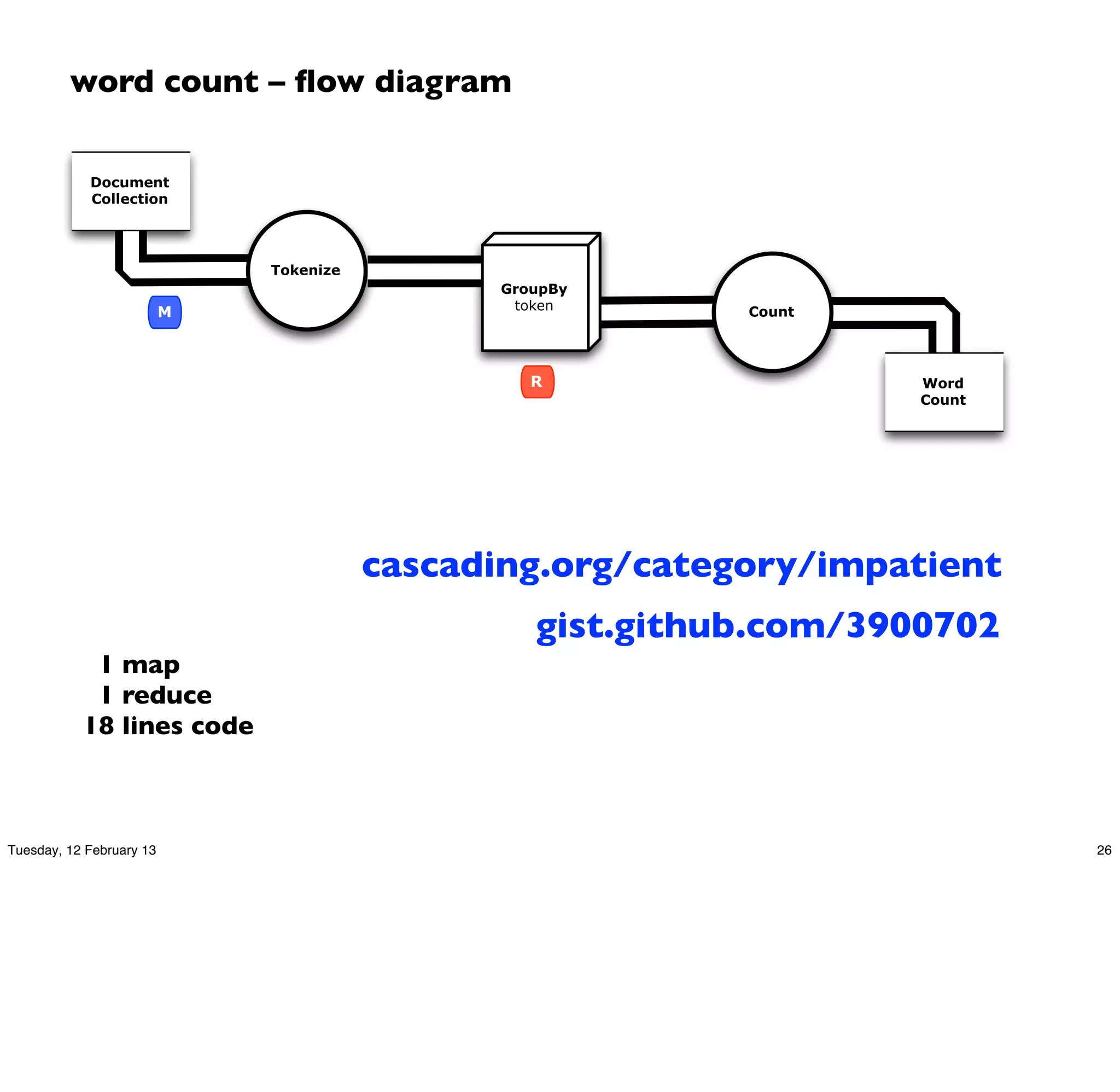
![word count – Cascading app
Document
Collection
Tokenize
GroupBy
M token Count
R Word
Count
String docPath = args[ 0 ];
String wcPath = args[ 1 ];
Properties properties = new Properties();
AppProps.setApplicationJarClass( properties, Main.class );
HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink taps
Tap docTap = new Hfs( new TextDelimited( true, "t" ), docPath );
Tap wcTap = new Hfs( new TextDelimited( true, "t" ), wcPath );
// specify a regex to split "document" text lines into token stream
Fields token = new Fields( "token" );
Fields text = new Fields( "text" );
RegexSplitGenerator splitter =
new RegexSplitGenerator( token, "[ [](),.]" );
// only returns "token"
Pipe docPipe = new Each( "token", text, splitter, Fields.RESULTS );
// determine the word counts
Pipe wcPipe = new Pipe( "wc", docPipe );
wcPipe = new GroupBy( wcPipe, token );
wcPipe = new Every( wcPipe, Fields.ALL, new Count(), Fields.ALL );
// connect the taps, pipes, etc., into a flow
FlowDef flowDef = FlowDef.flowDef().setName( "wc" )
.addSource( docPipe, docTap )
.addTailSink( wcPipe, wcTap );
// write a DOT file and run the flow
Flow wcFlow = flowConnector.connect( flowDef );
wcFlow.writeDOT( "dot/wc.dot" );
wcFlow.complete();
Tuesday, 12 February 13 27](https://image.slidesharecdn.com/chug-130212222343-phpapp02/75/Chicago-Hadoop-Users-Group-Enterprise-Data-Workflows-27-2048.jpg)
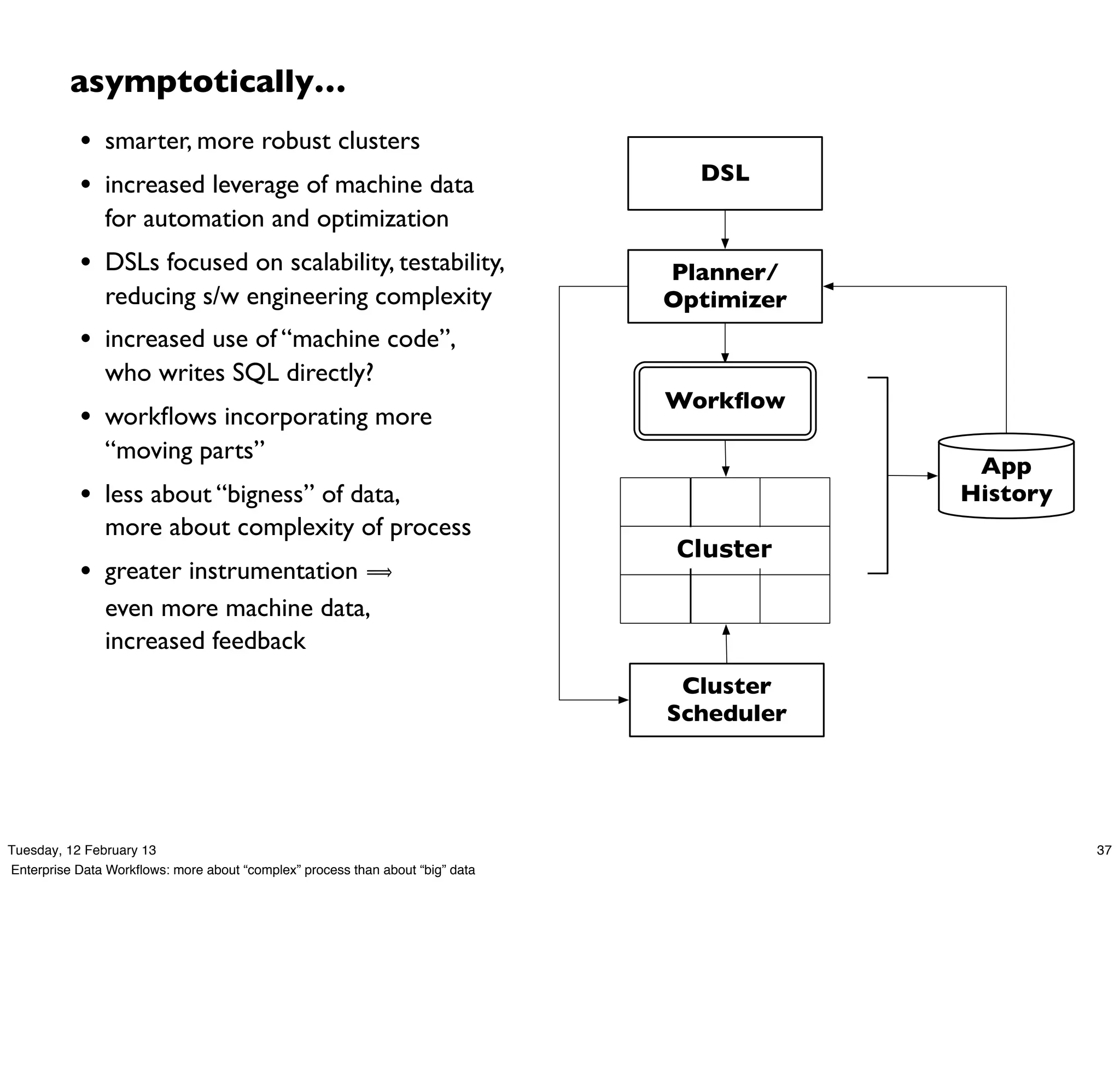
![word count – flow plan
Document
Collection
Tokenize
GroupBy
M token Count
R Word
Count
[head]
Hfs['TextDelimited[['doc_id', 'text']->[ALL]]']['data/rain.txt']']
[{2}:'doc_id', 'text']
[{2}:'doc_id', 'text']
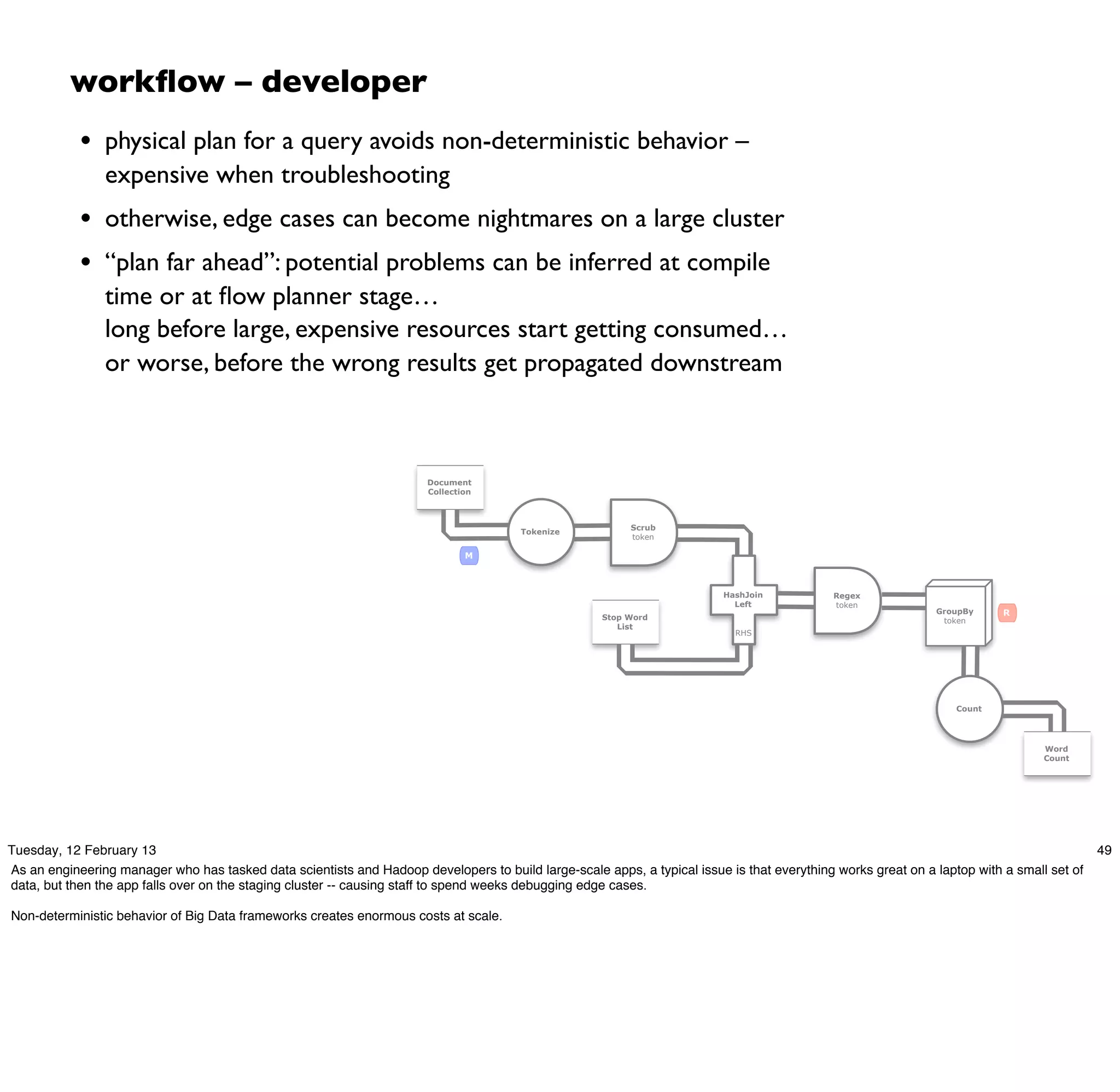
map
Each('token')[RegexSplitGenerator[decl:'token'][args:1]]
[{1}:'token']
[{1}:'token']
GroupBy('wc')[by:['token']]
wc[{1}:'token']
[{1}:'token']
reduce
Every('wc')[Count[decl:'count']]
[{2}:'token', 'count']
[{1}:'token']
Hfs['TextDelimited[[UNKNOWN]->['token', 'count']]']['output/wc']']
[{2}:'token', 'count']
[{2}:'token', 'count']
[tail]
Tuesday, 12 February 13 28](https://image.slidesharecdn.com/chug-130212222343-phpapp02/75/Chicago-Hadoop-Users-Group-Enterprise-Data-Workflows-28-2048.jpg)
![word count – Scalding / Scala
Document
Collection
Tokenize
GroupBy
M token Count
R Word
Count
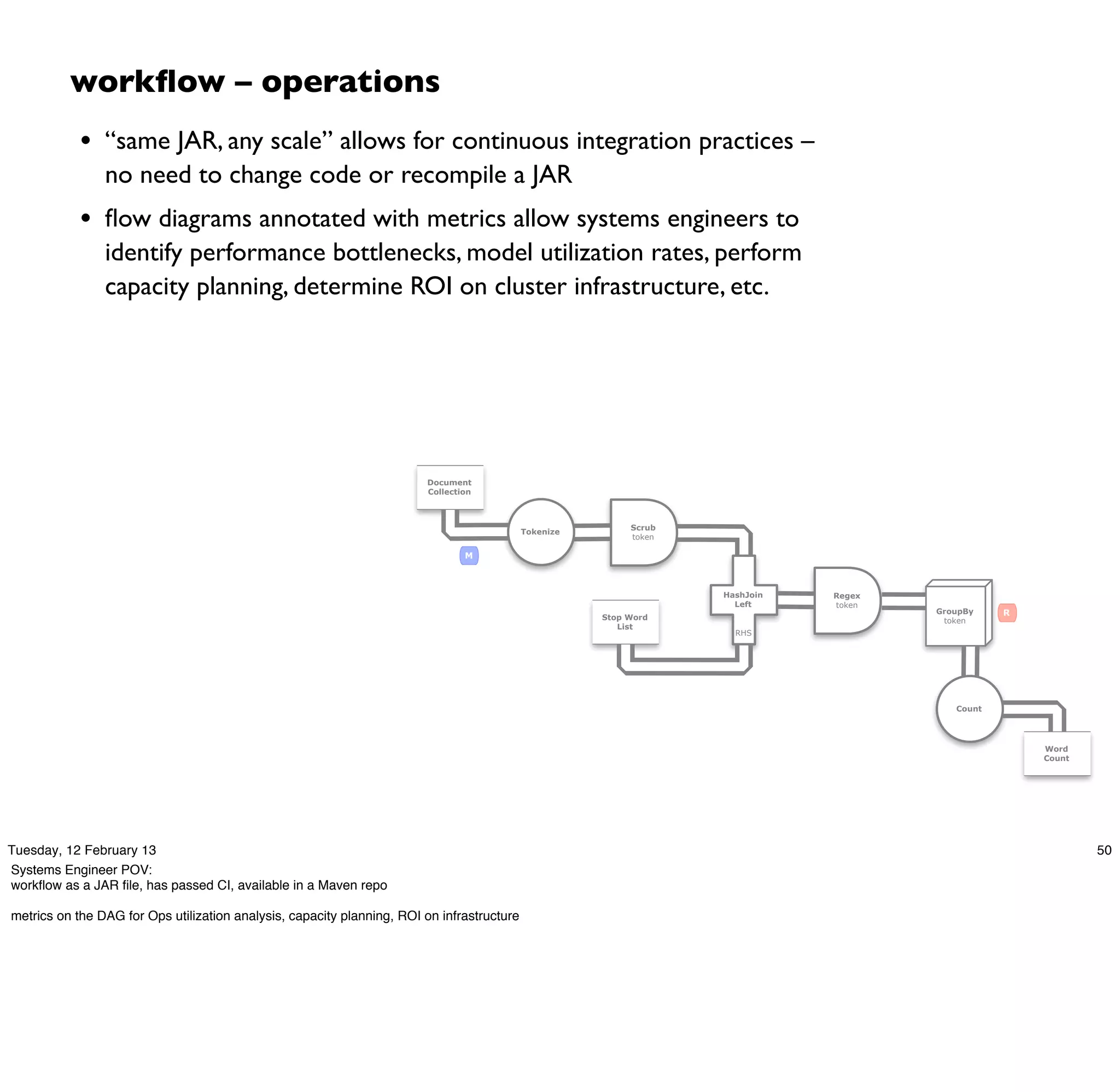
import com.twitter.scalding._
class WordCount(args : Args) extends Job(args) {
Tsv(args("doc"),
('doc_id, 'text),
skipHeader = true)
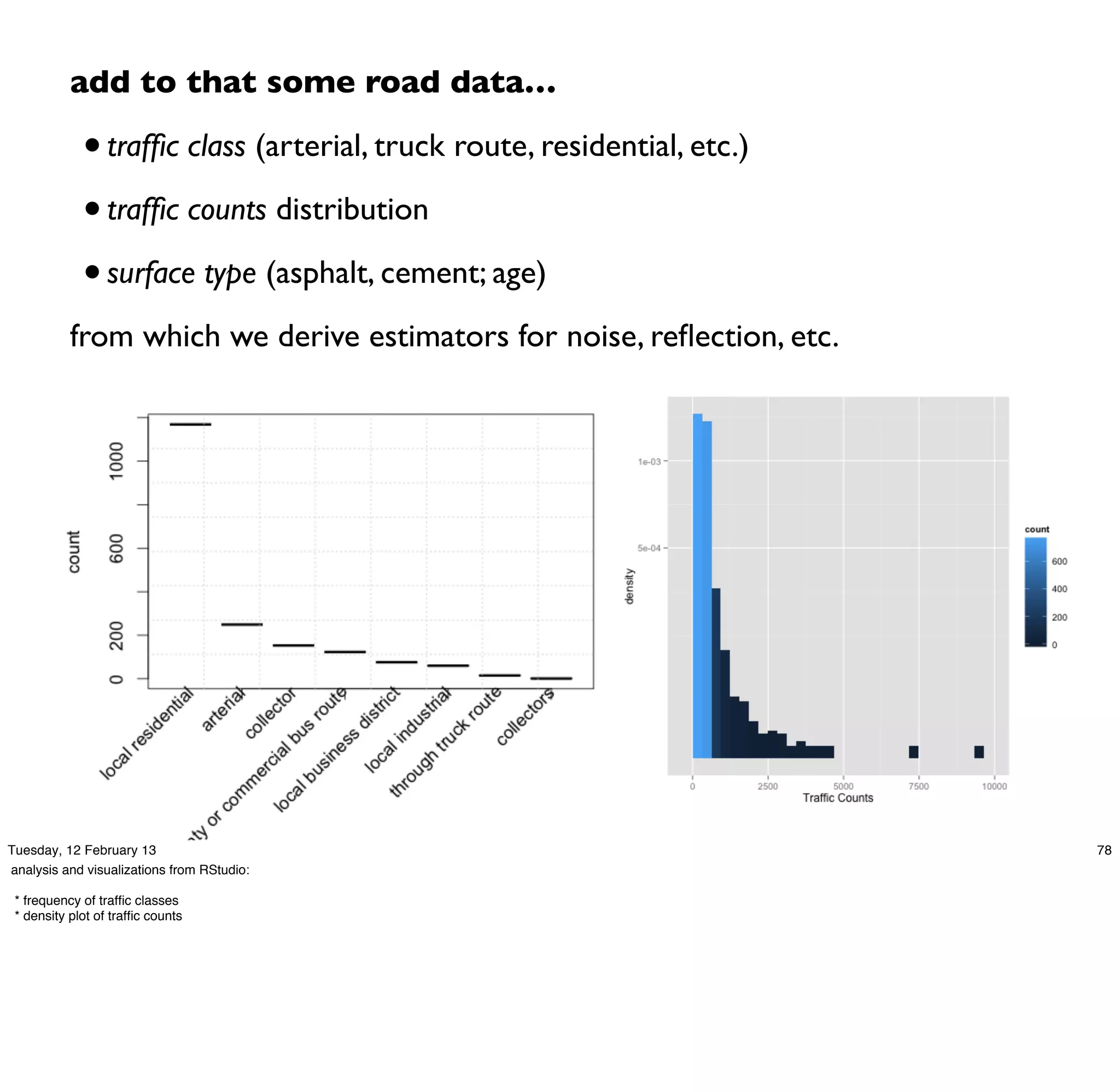
.read
.flatMap('text -> 'token) {
text : String => text.split("[ [](),.]")
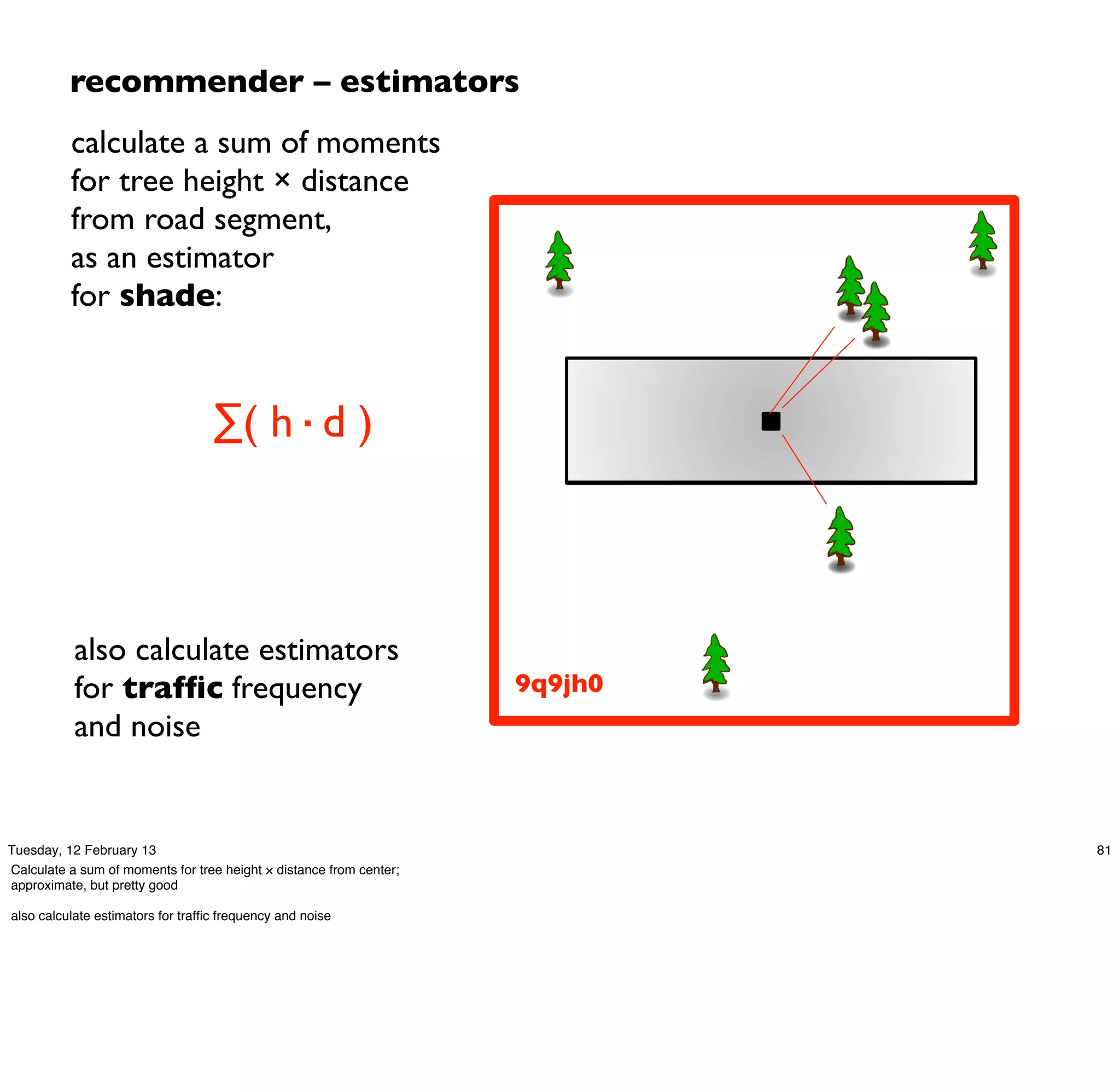
}
.groupBy('token) { _.size('count) }
.write(Tsv(args("wc"), writeHeader = true))
}
Tuesday, 12 February 13 29](https://image.slidesharecdn.com/chug-130212222343-phpapp02/75/Chicago-Hadoop-Users-Group-Enterprise-Data-Workflows-29-2048.jpg)

![word count – Cascalog / Clojure
Document
Collection
Tokenize
GroupBy
M token Count
R Word
Count
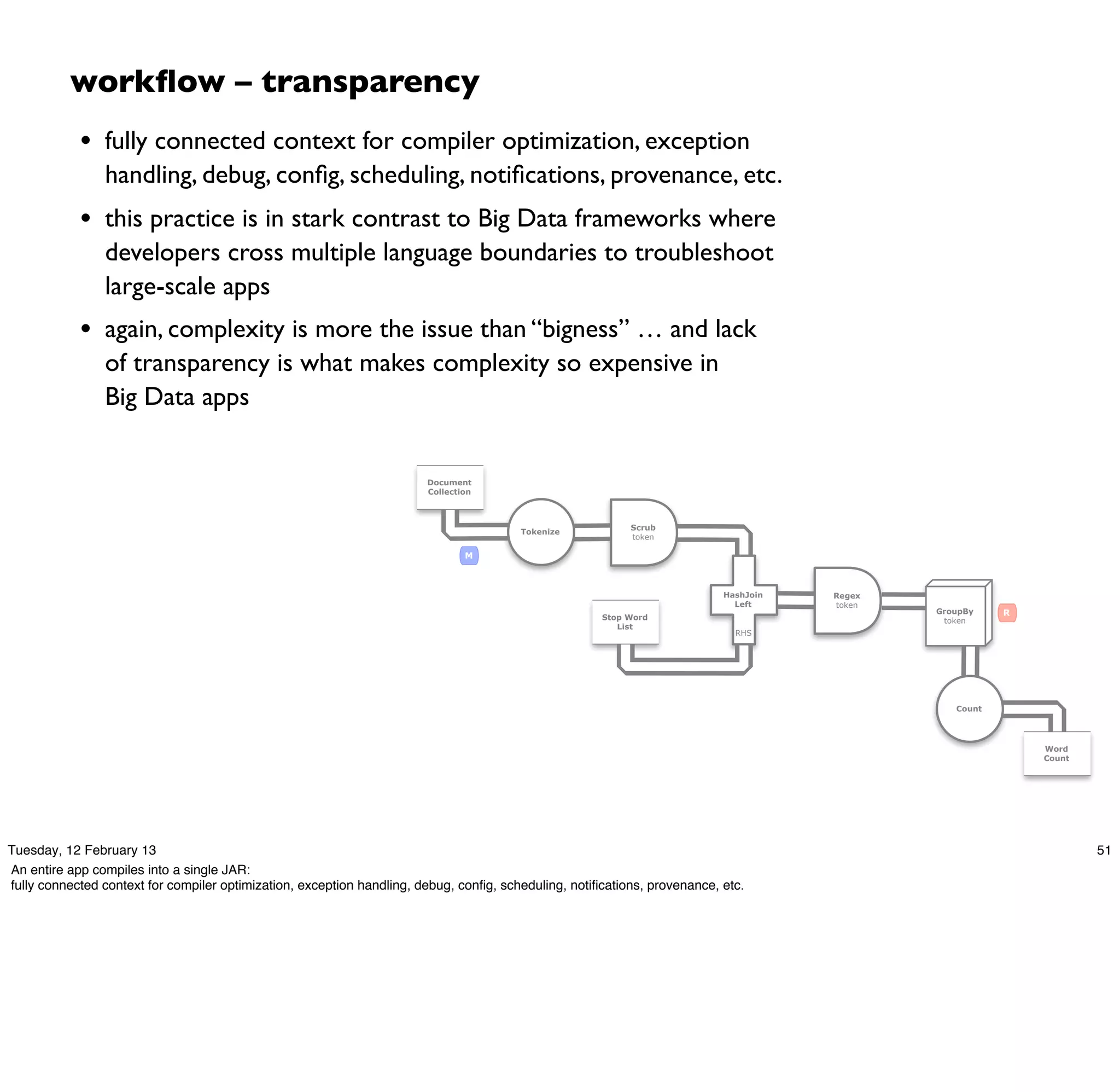
(ns impatient.core
(:use [cascalog.api]
[cascalog.more-taps :only (hfs-delimited)])
(:require [clojure.string :as s]
[cascalog.ops :as c])
(:gen-class))
(defmapcatop split [line]
"reads in a line of string and splits it by regex"
(s/split line #"[[](),.)s]+"))
(defn -main [in out & args]
(?<- (hfs-delimited out)
[?word ?count]
((hfs-delimited in :skip-header? true) _ ?line)
(split ?line :> ?word)
(c/count ?count)))
; Paul Lam
; github.com/Quantisan/Impatient
Tuesday, 12 February 13 31](https://image.slidesharecdn.com/chug-130212222343-phpapp02/75/Chicago-Hadoop-Users-Group-Enterprise-Data-Workflows-31-2048.jpg)












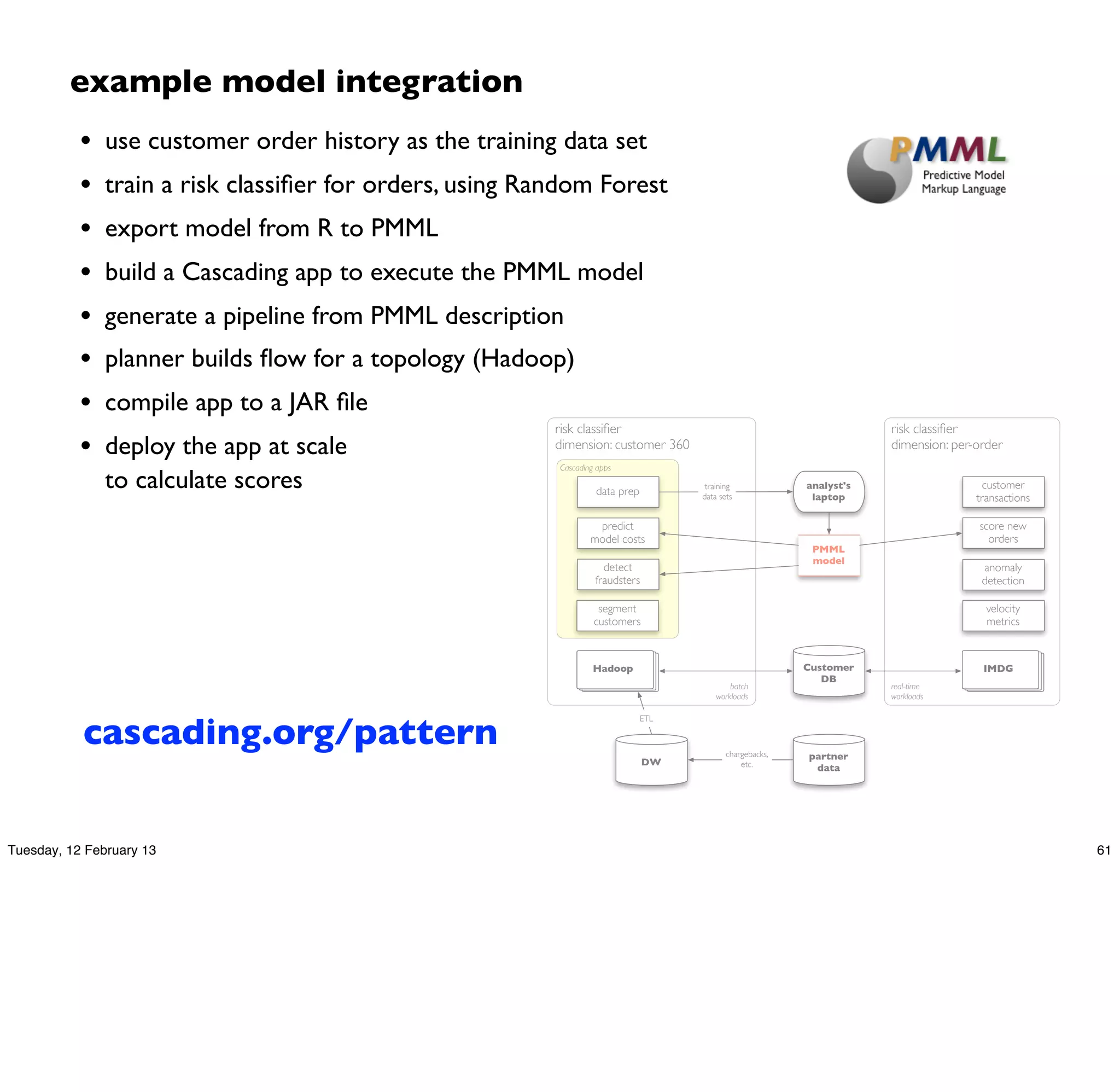
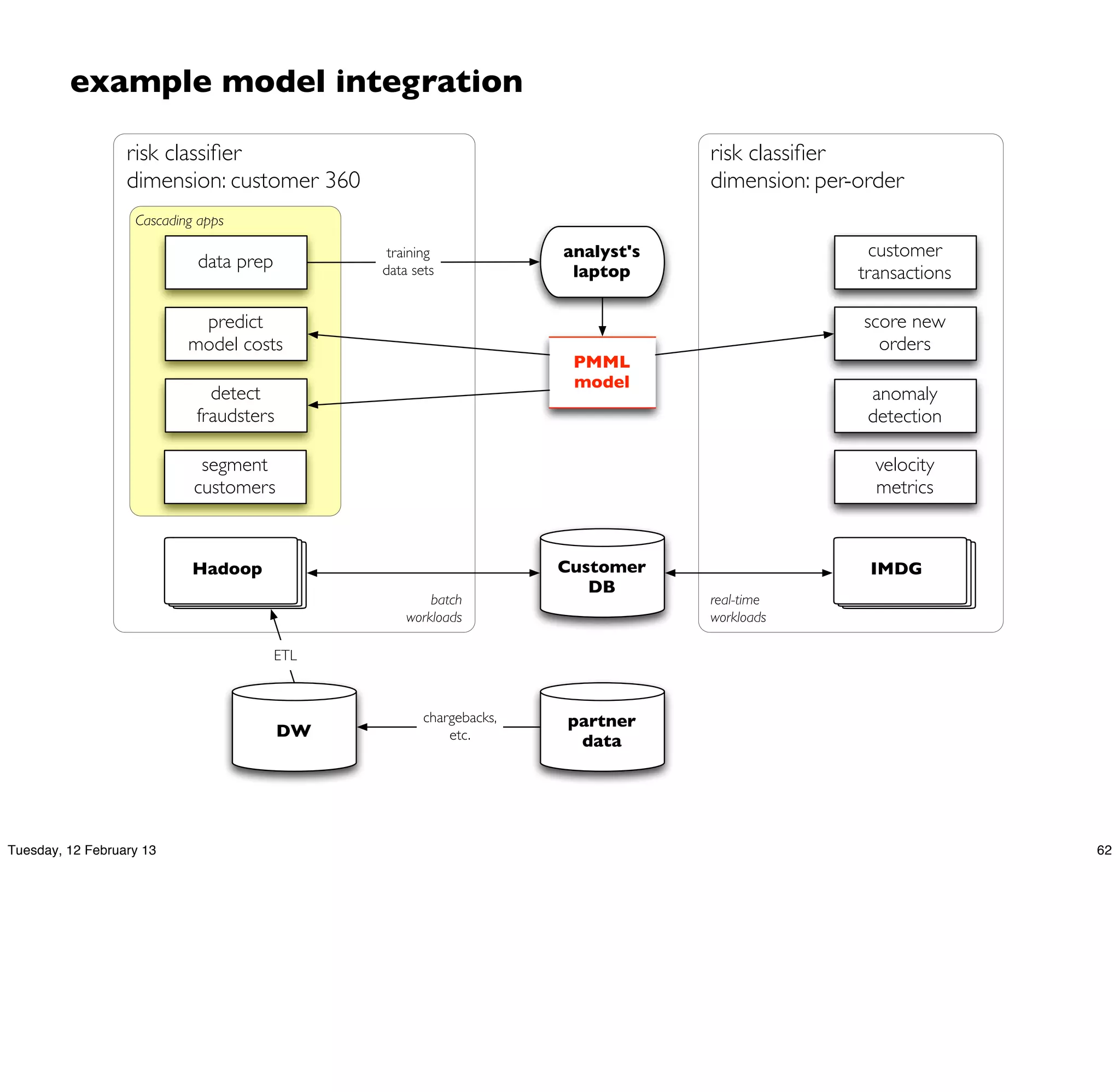
![model creation in R
## train a RandomForest model
f <- as.formula("as.factor(label) ~ .")
fit <- randomForest(f, data_train, ntree=50)
## test the model on the holdout test set
print(fit$importance)
print(fit)
predicted <- predict(fit, data)
data$predicted <- predicted
confuse <- table(pred = predicted, true = data[,1])
print(confuse)
## export predicted labels to TSV
write.table(data, file=paste(dat_folder, "sample.tsv", sep="/"),
quote=FALSE, sep="t", row.names=FALSE)
## export RF model to PMML
saveXML(pmml(fit), file=paste(dat_folder, "sample.rf.xml", sep="/"))
Tuesday, 12 February 13 63](https://image.slidesharecdn.com/chug-130212222343-phpapp02/75/Chicago-Hadoop-Users-Group-Enterprise-Data-Workflows-63-2048.jpg)

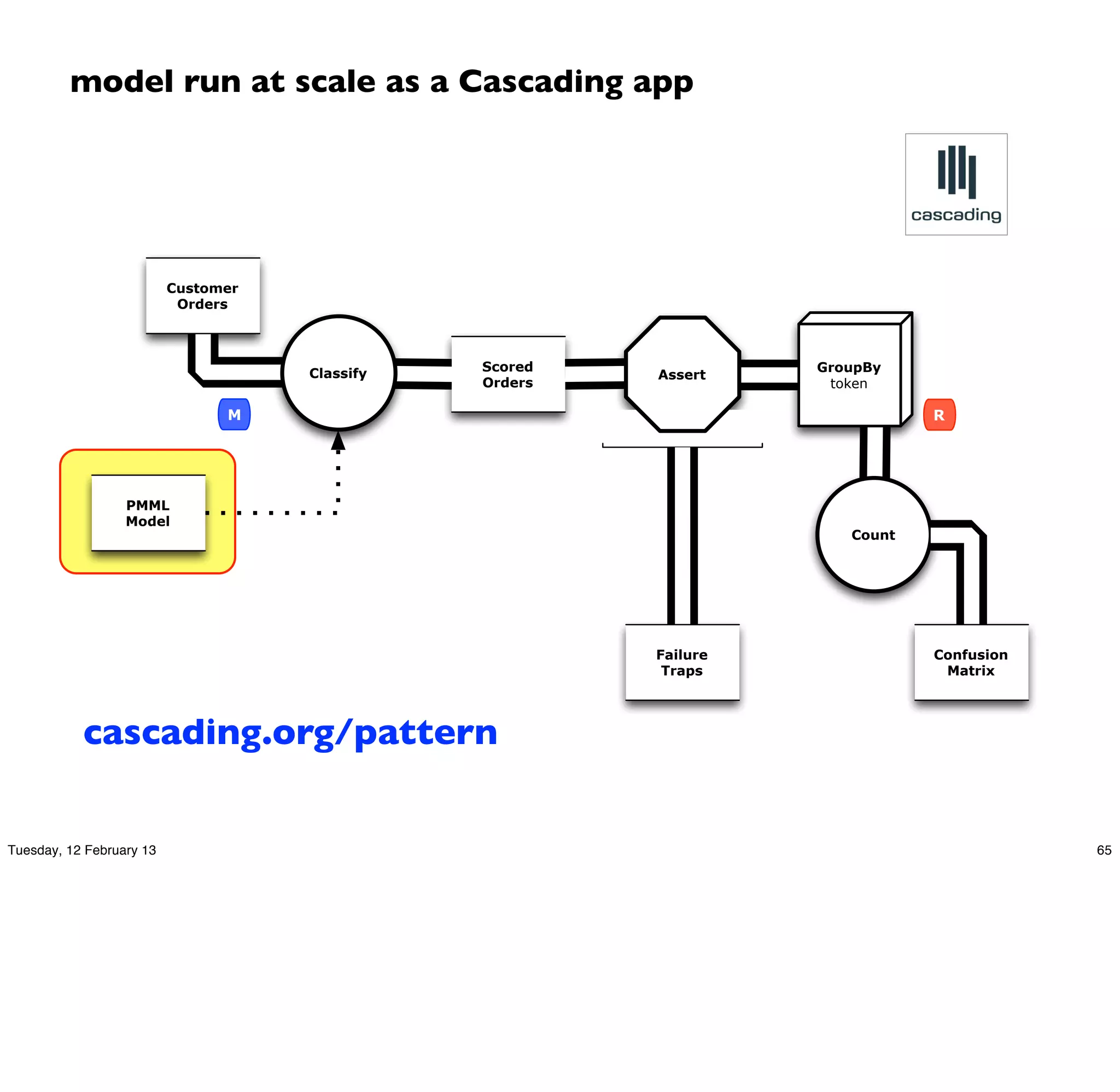
![model run at scale as a Cascading app
public class Main {
public static void main( String[] args ) {
String pmmlPath = args[ 0 ];
String ordersPath = args[ 1 ];
String classifyPath = args[ 2 ];
String trapPath = args[ 3 ];
Properties properties = new Properties();
AppProps.setApplicationJarClass( properties, Main.class );
HadoopFlowConnector flowConnector = new HadoopFlowConnector( properties );
// create source and sink taps
Tap ordersTap = new Hfs( new TextDelimited( true, "t" ), ordersPath );
Tap classifyTap = new Hfs( new TextDelimited( true, "t" ), classifyPath );
Tap trapTap = new Hfs( new TextDelimited( true, "t" ), trapPath );
// define a "Classifier" model from PMML to evaluate the orders
ClassifierFunction classFunc =
new ClassifierFunction( new Fields( "score" ), pmmlPath );
Pipe classifyPipe =
new Each( new Pipe( "classify" ), classFunc.getInputFields(), classFunc, Fields.ALL );
// connect the taps, pipes, etc., into a flow
FlowDef flowDef = FlowDef.flowDef().setName( "classify" )
.addSource( classifyPipe, ordersTap )
.addTrap( classifyPipe, trapTap )
.addSink( classifyPipe, classifyTap );
// write a DOT file and run the flow
Flow classifyFlow = flowConnector.connect( flowDef );
classifyFlow.writeDOT( "dot/classify.dot" );
classifyFlow.complete();
}
}
Tuesday, 12 February 13 66](https://image.slidesharecdn.com/chug-130212222343-phpapp02/75/Chicago-Hadoop-Users-Group-Enterprise-Data-Workflows-66-2048.jpg)



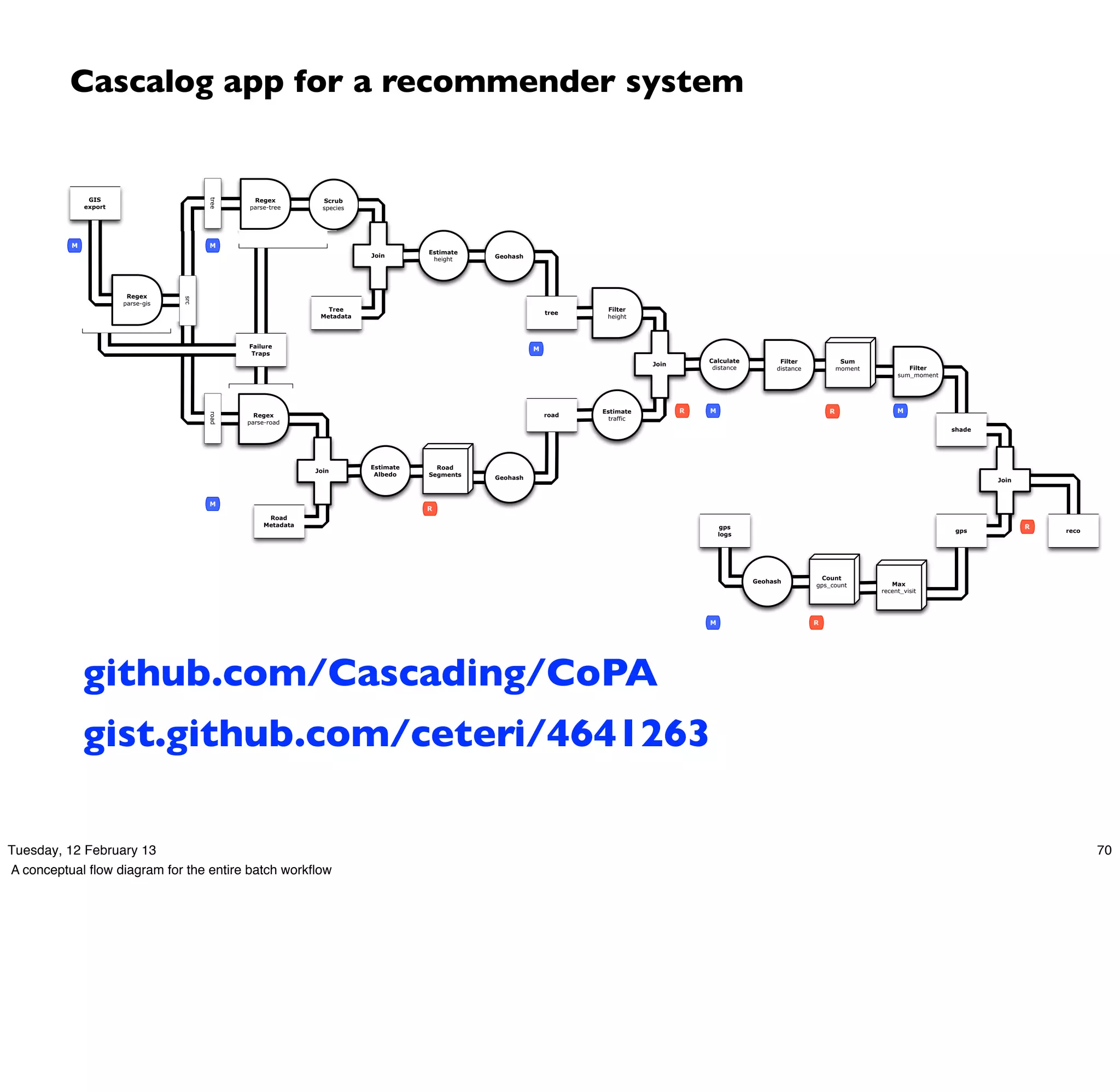




![Cascalog – an example
(defn get-trees [src trap tree_meta]
"subquery to parse/filter the tree data"
(<- [?blurb ?tree_id ?situs ?tree_site
?species ?wikipedia ?calflora ?avg_height
?tree_lat ?tree_lng ?tree_alt ?geohash
]
(src ?blurb ?misc ?geo ?kind)
(re-matches #"^s+Private.*Tree ID.*" ?misc)
(parse-tree
?misc :> _ ?priv ?tree_id ?situs ?tree_site ?raw_species)
((c/comp s/trim s/lower-case) ?raw_species :> ?species)
(tree_meta
?species ?wikipedia ?calflora ?min_height ?max_height)
(avg ?min_height ?max_height :> ?avg_height)
(geo-tree ?geo :> _ ?tree_lat ?tree_lng ?tree_alt)
(read-string ?tree_lat :> ?lat)
(read-string ?tree_lng :> ?lng)
(geohash ?lat ?lng :> ?geohash)
(:trap (hfs-textline trap))
))
Tuesday, 12 February 13 76
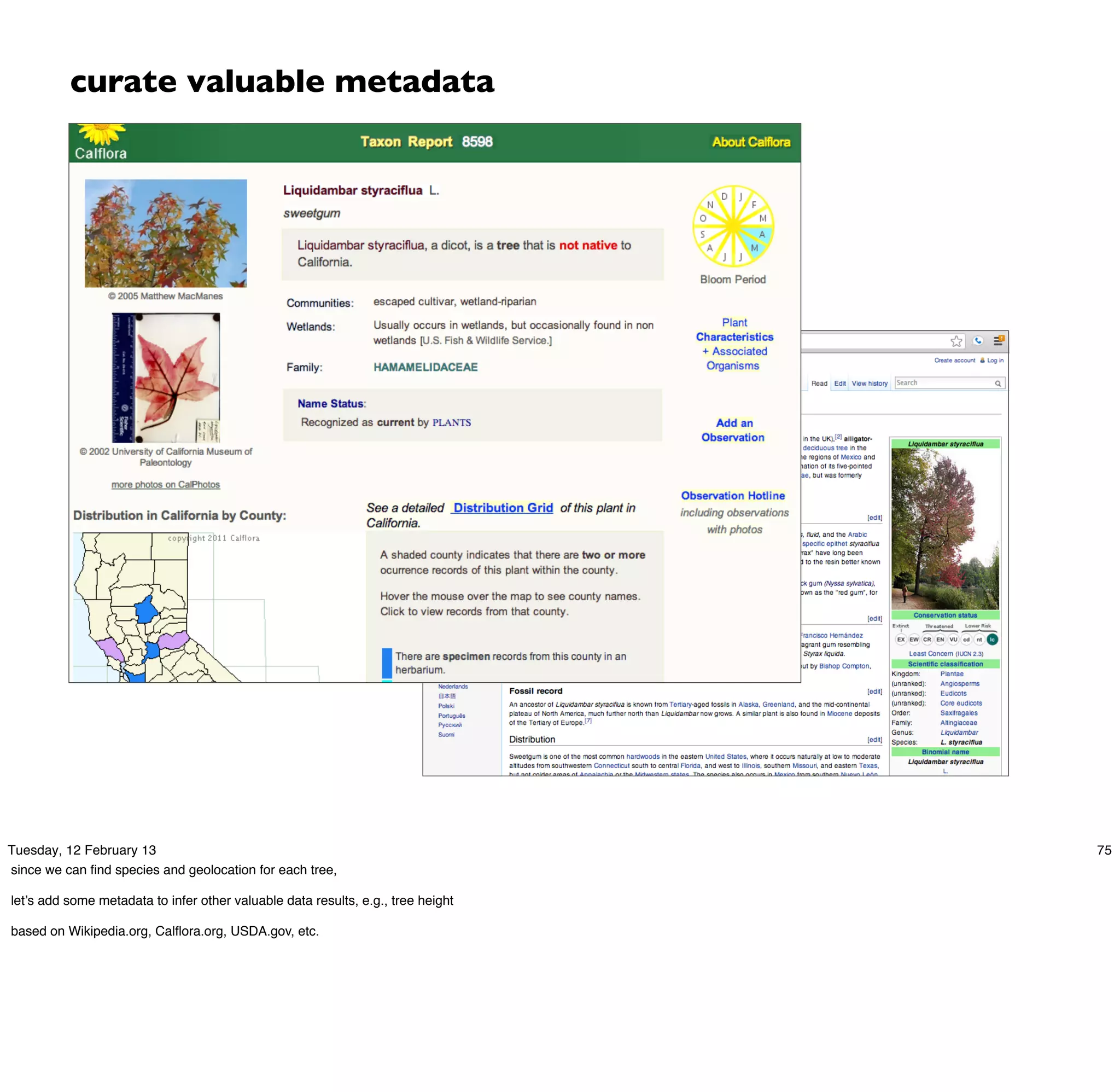
Let's use Cascalog to begin our process of structuring that data
since the GIS export is vaguely in CSV format, here's a simple way to clean up the data
referring back to DJ Patil’s “Data Jujitsu”, that clean up usually accounts for 80% of project costs](https://image.slidesharecdn.com/chug-130212222343-phpapp02/75/Chicago-Hadoop-Users-Group-Enterprise-Data-Workflows-76-2048.jpg)
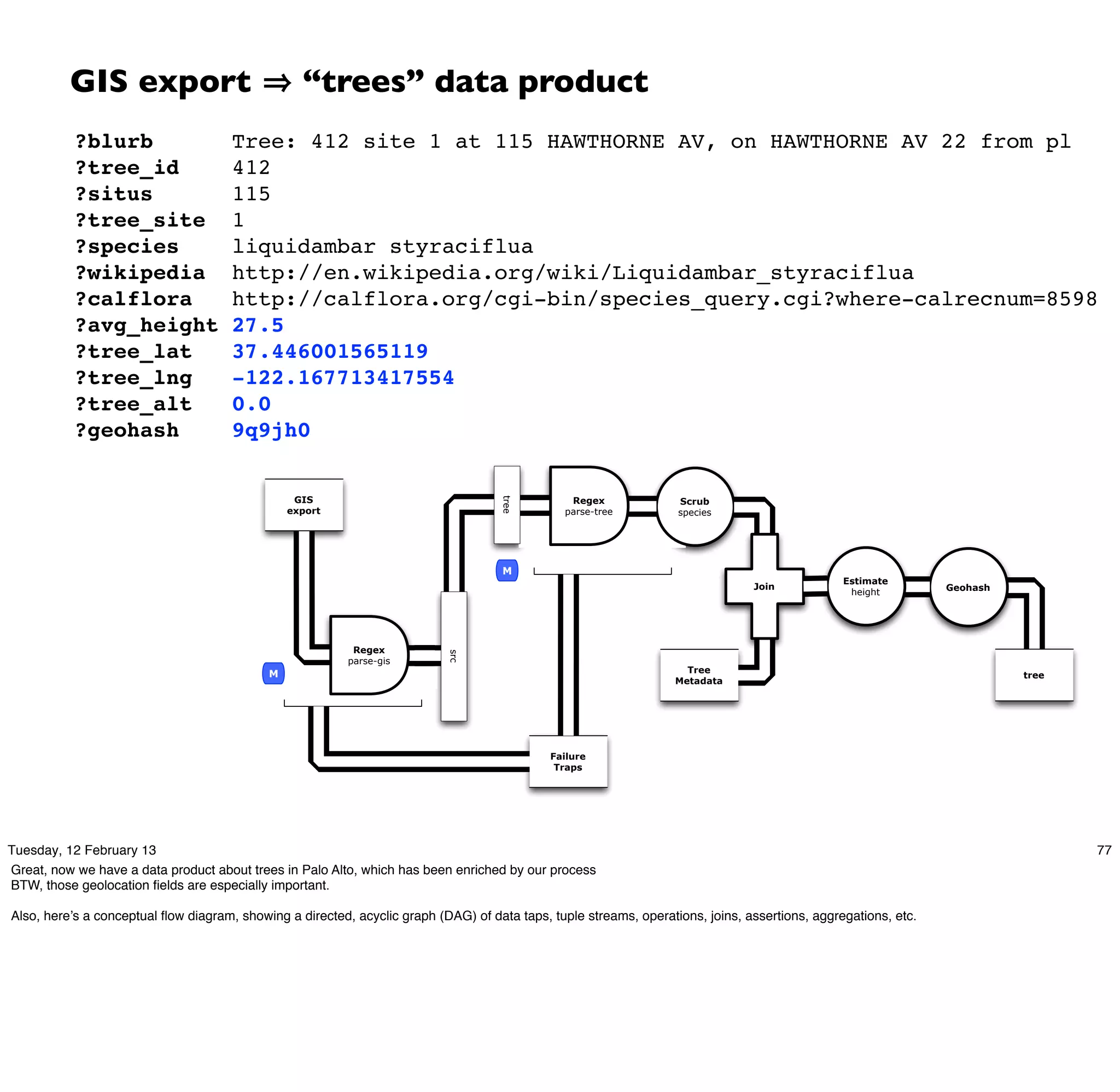









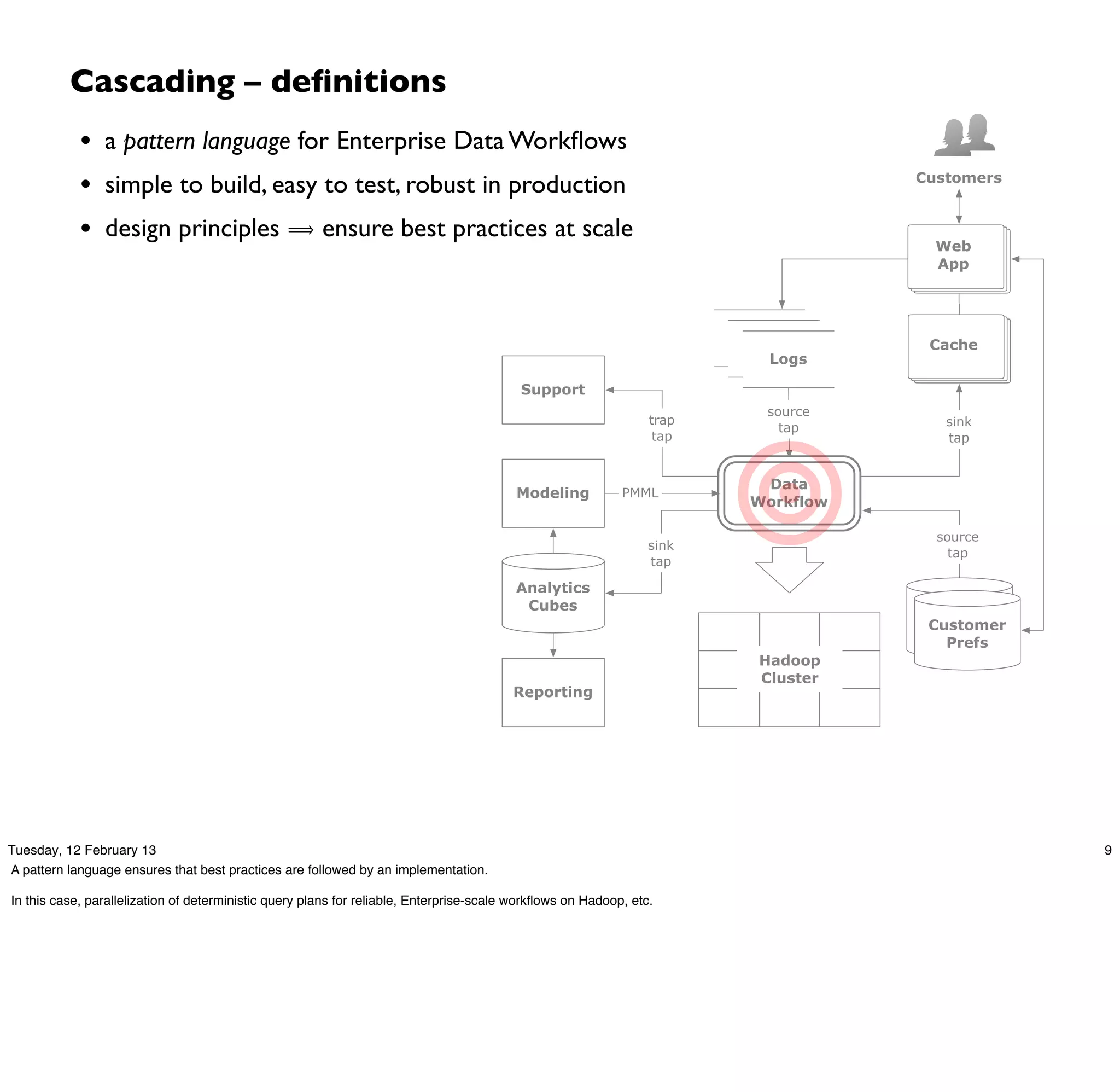
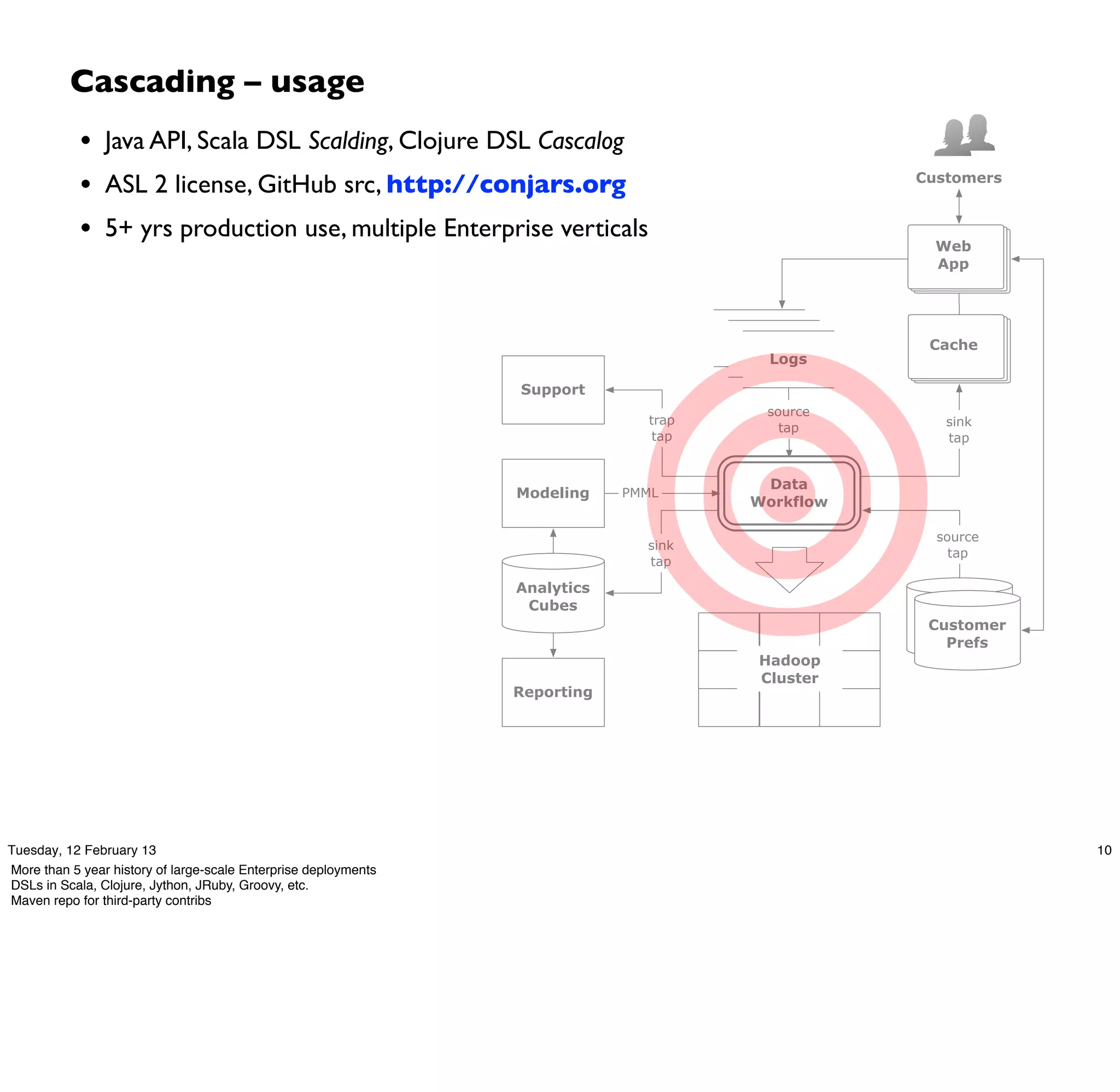
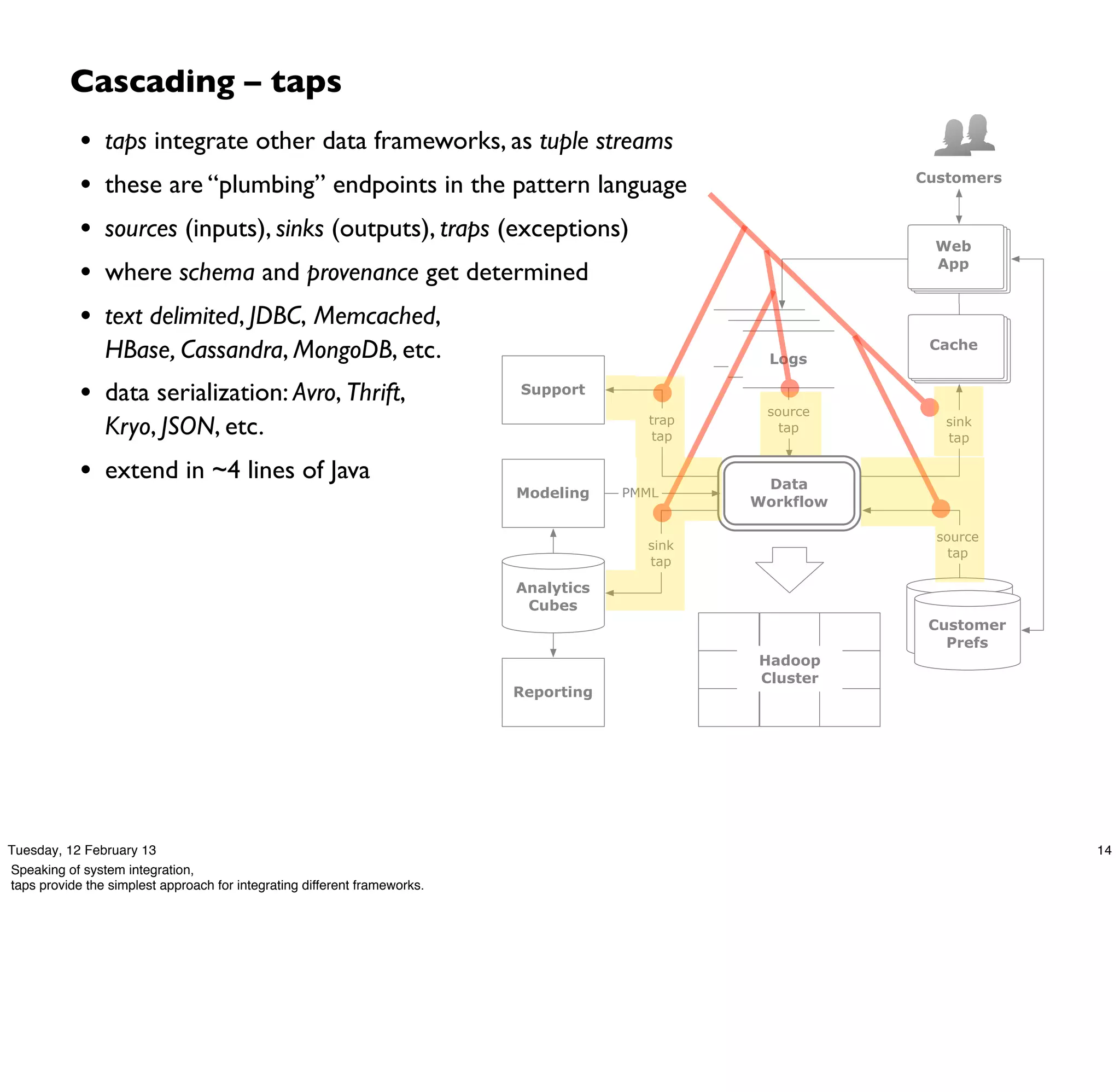
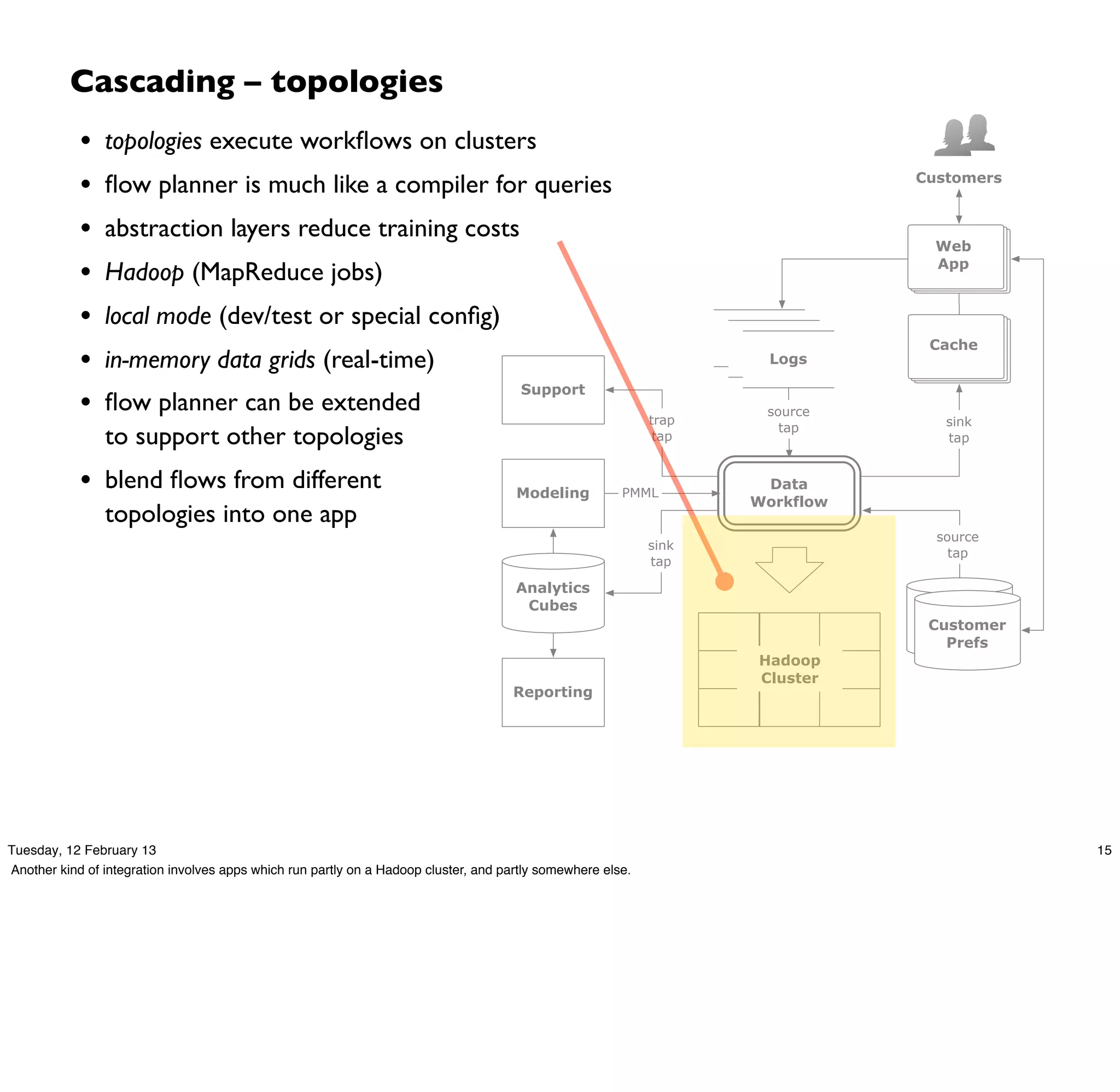
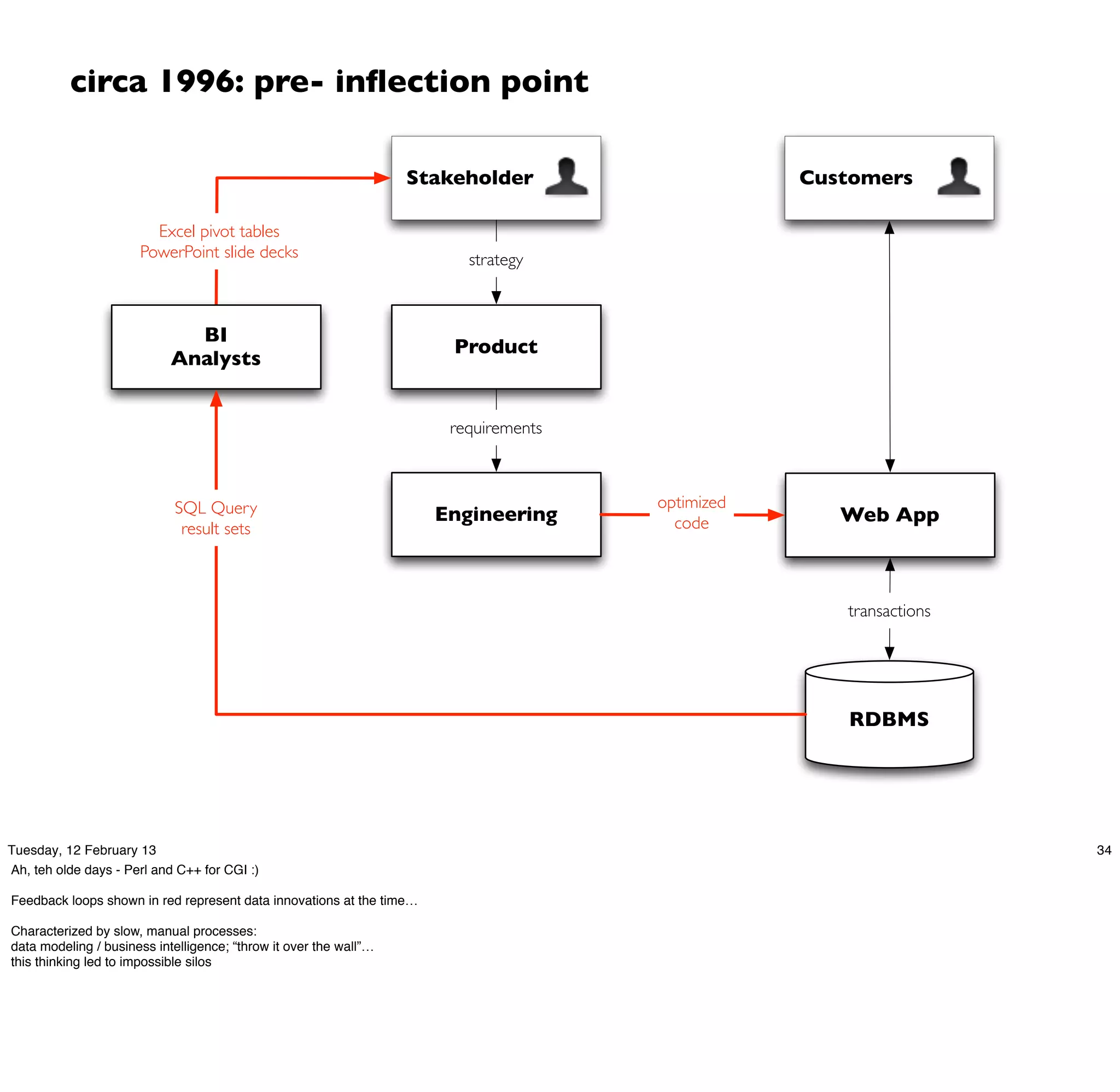
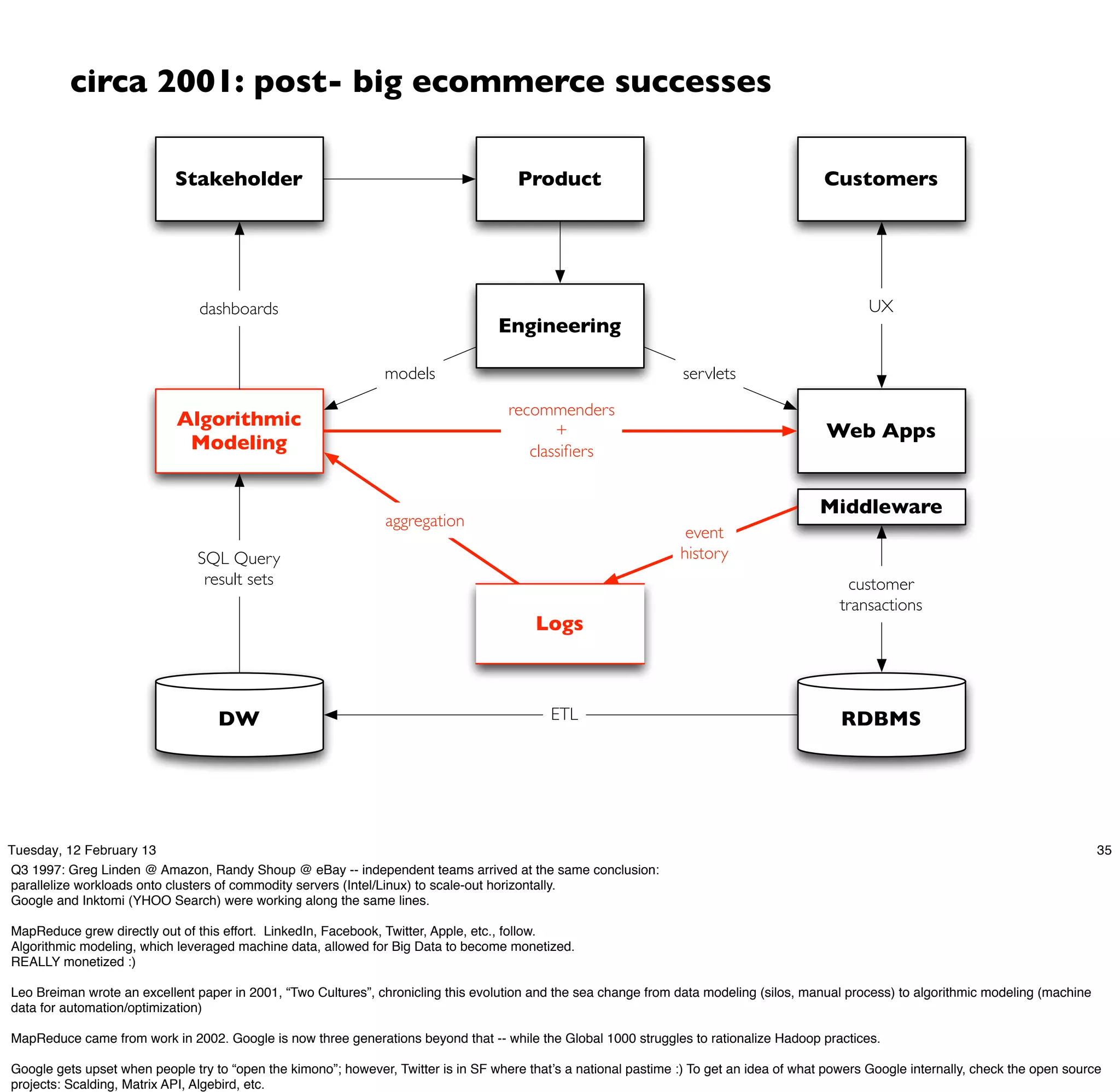
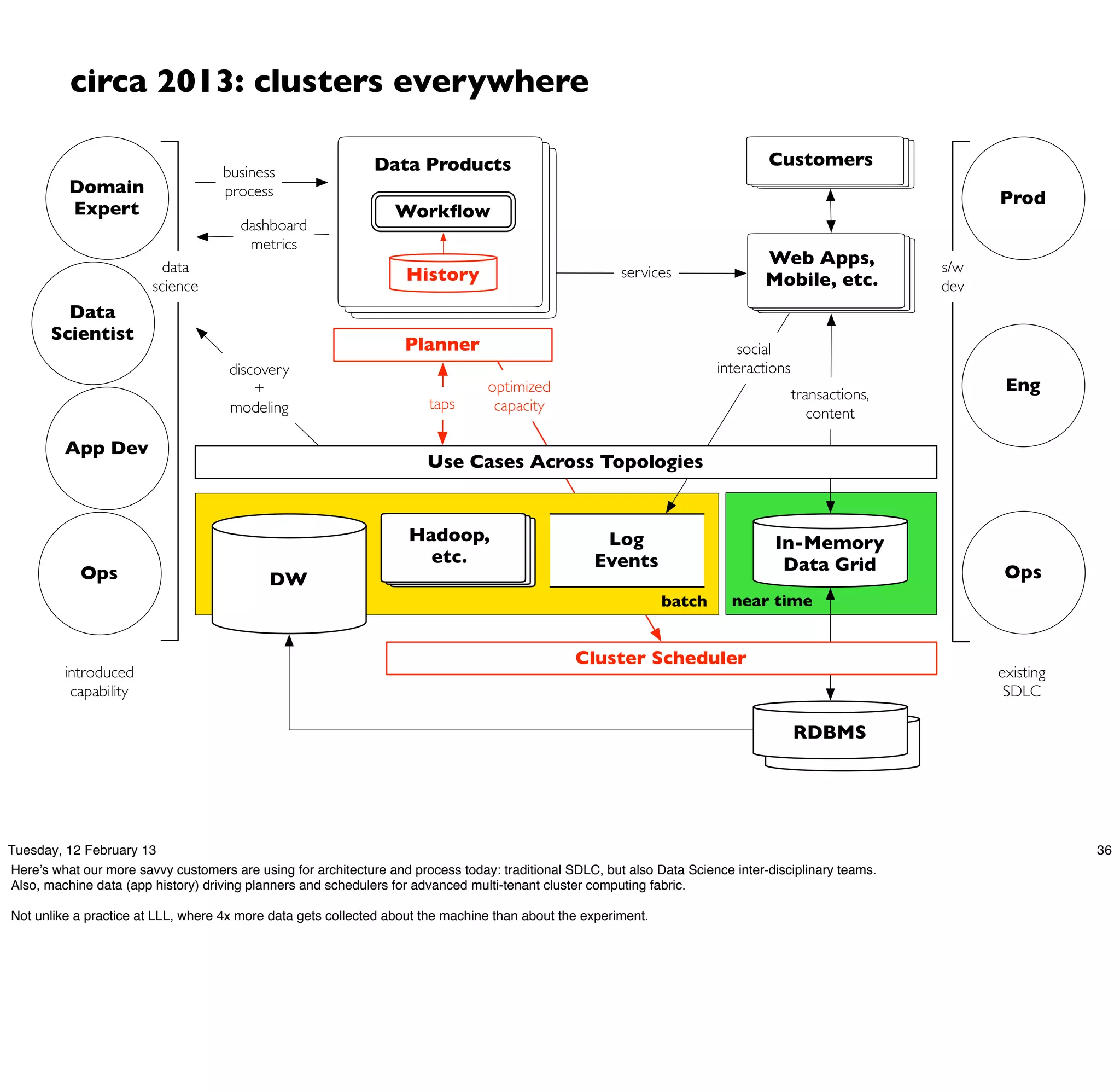
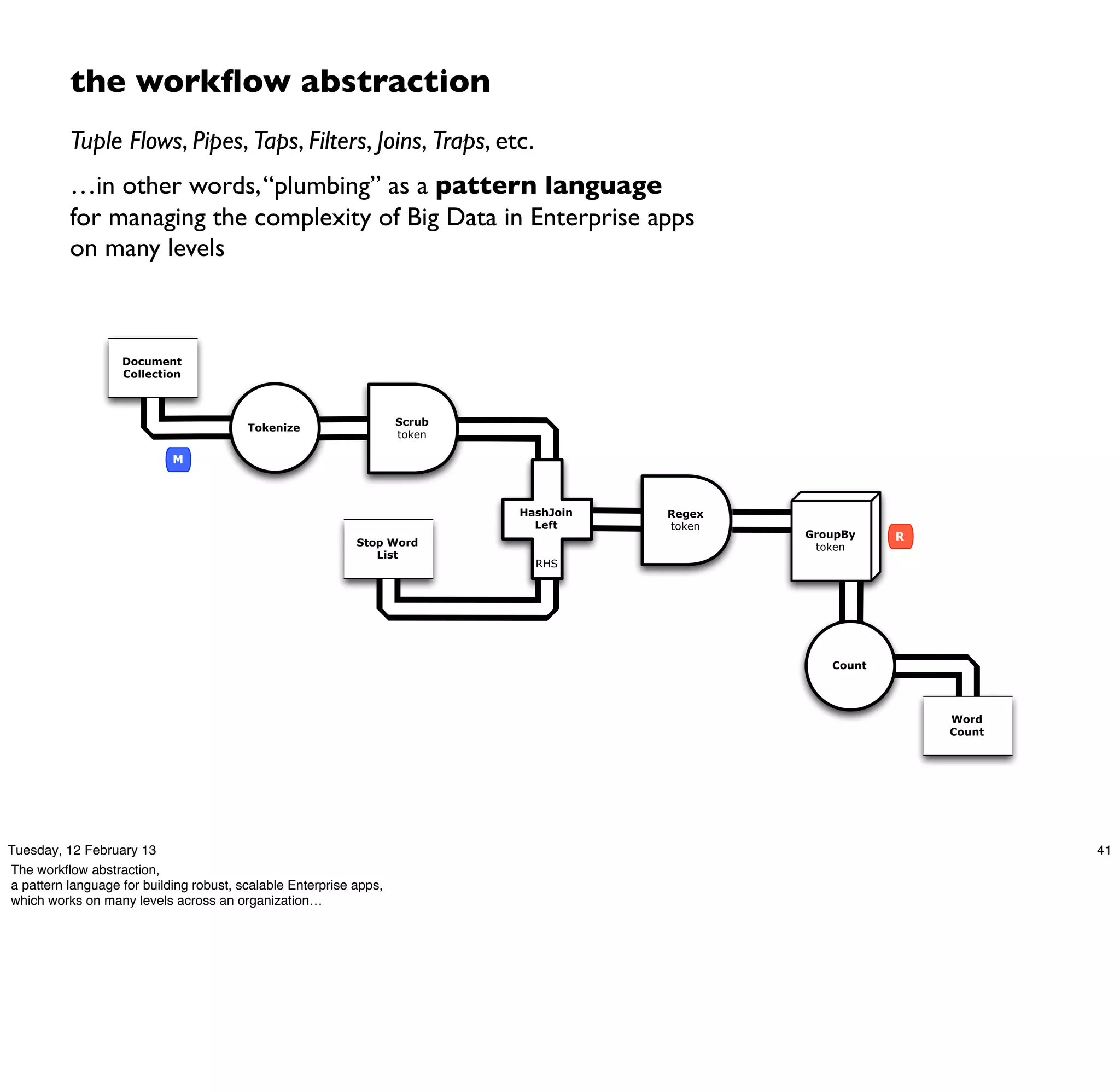
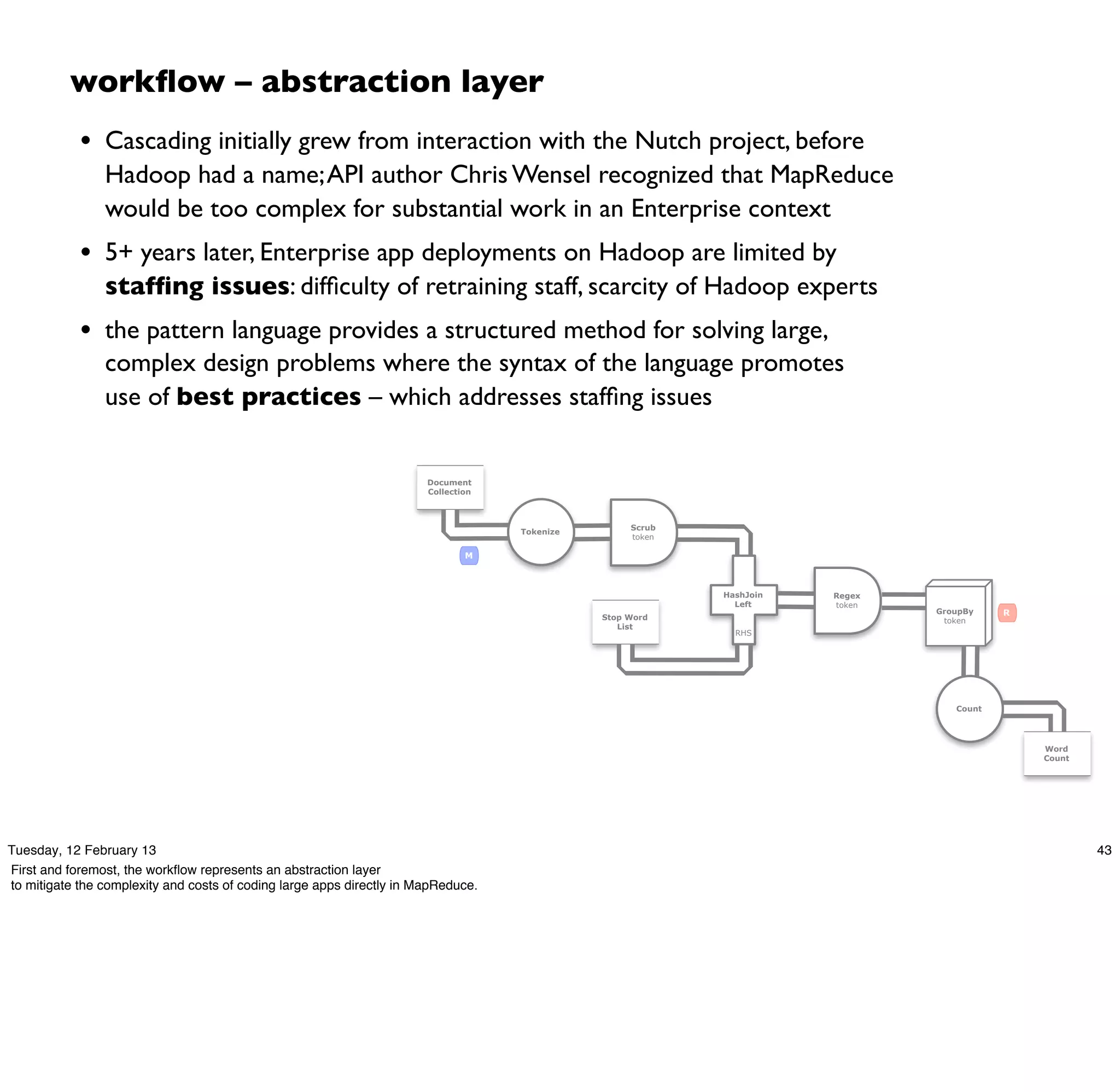
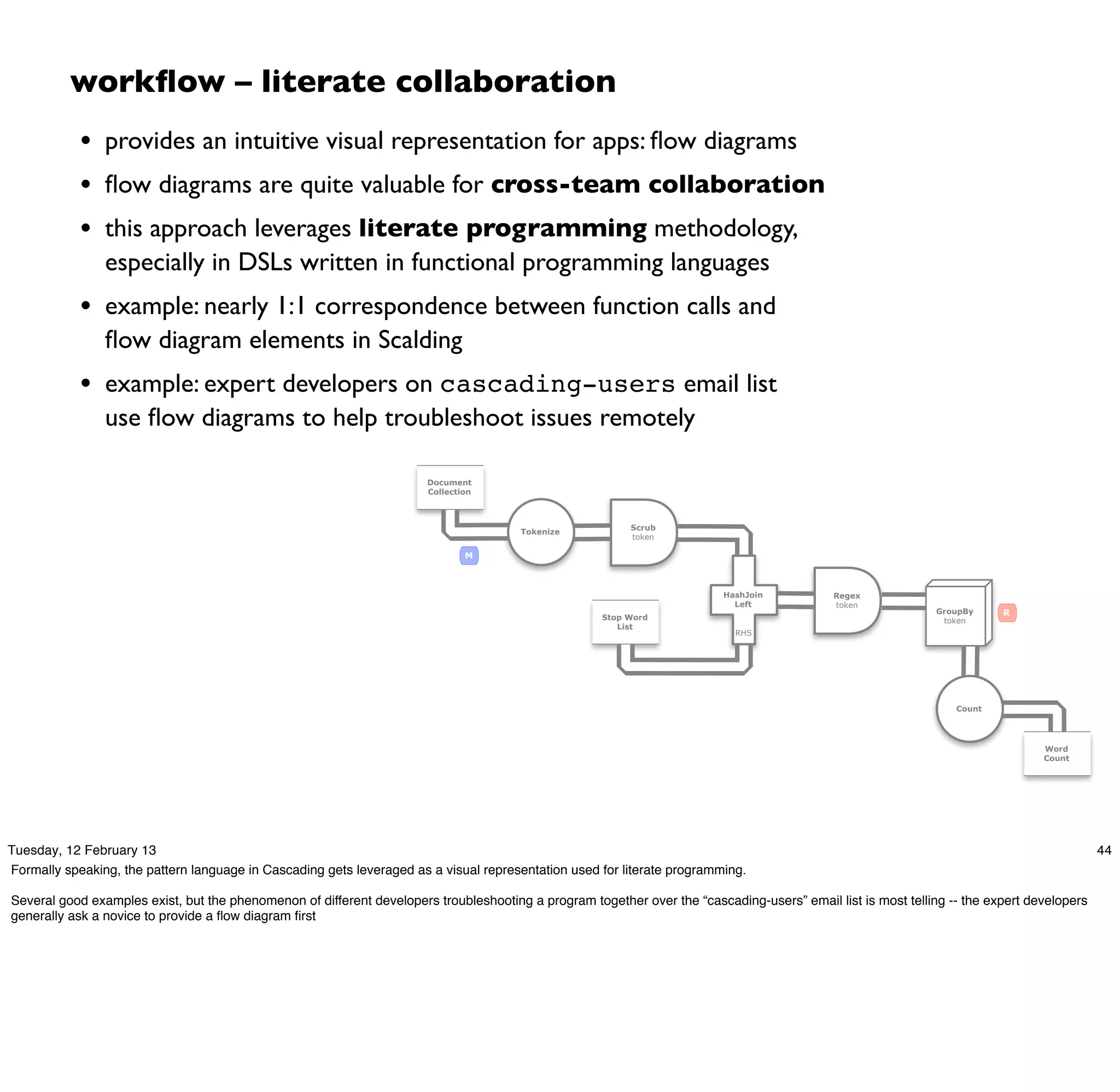
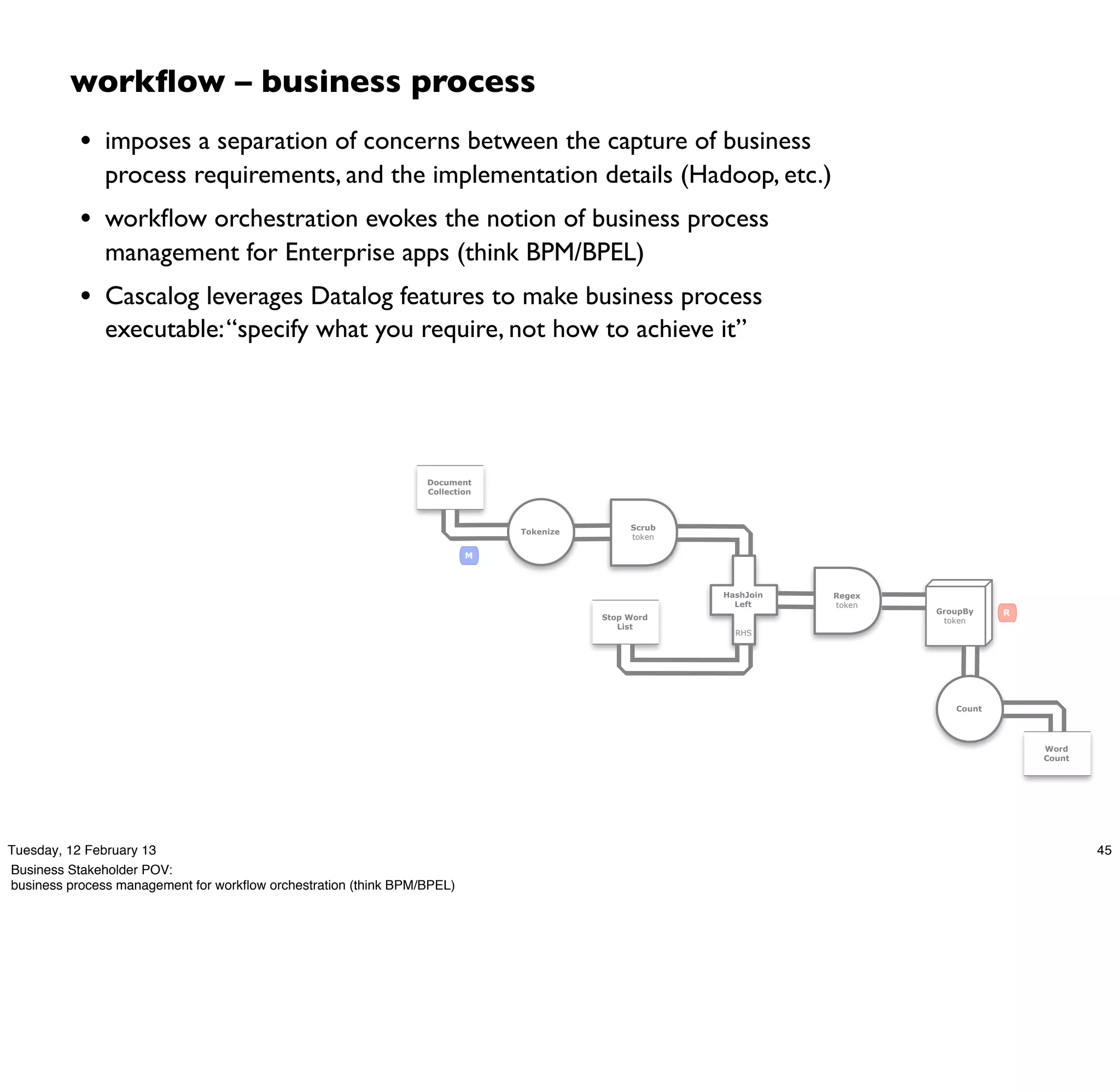
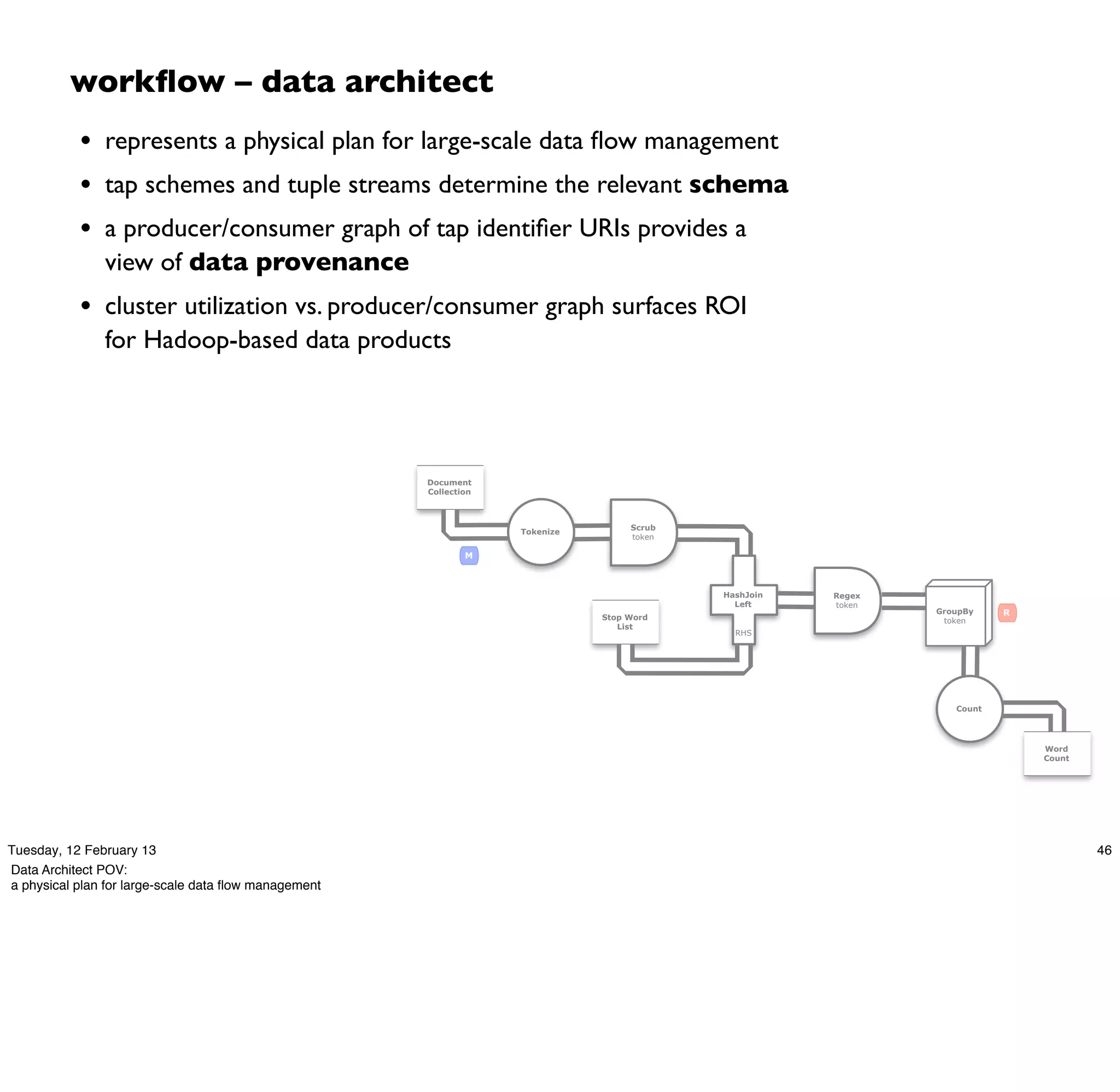
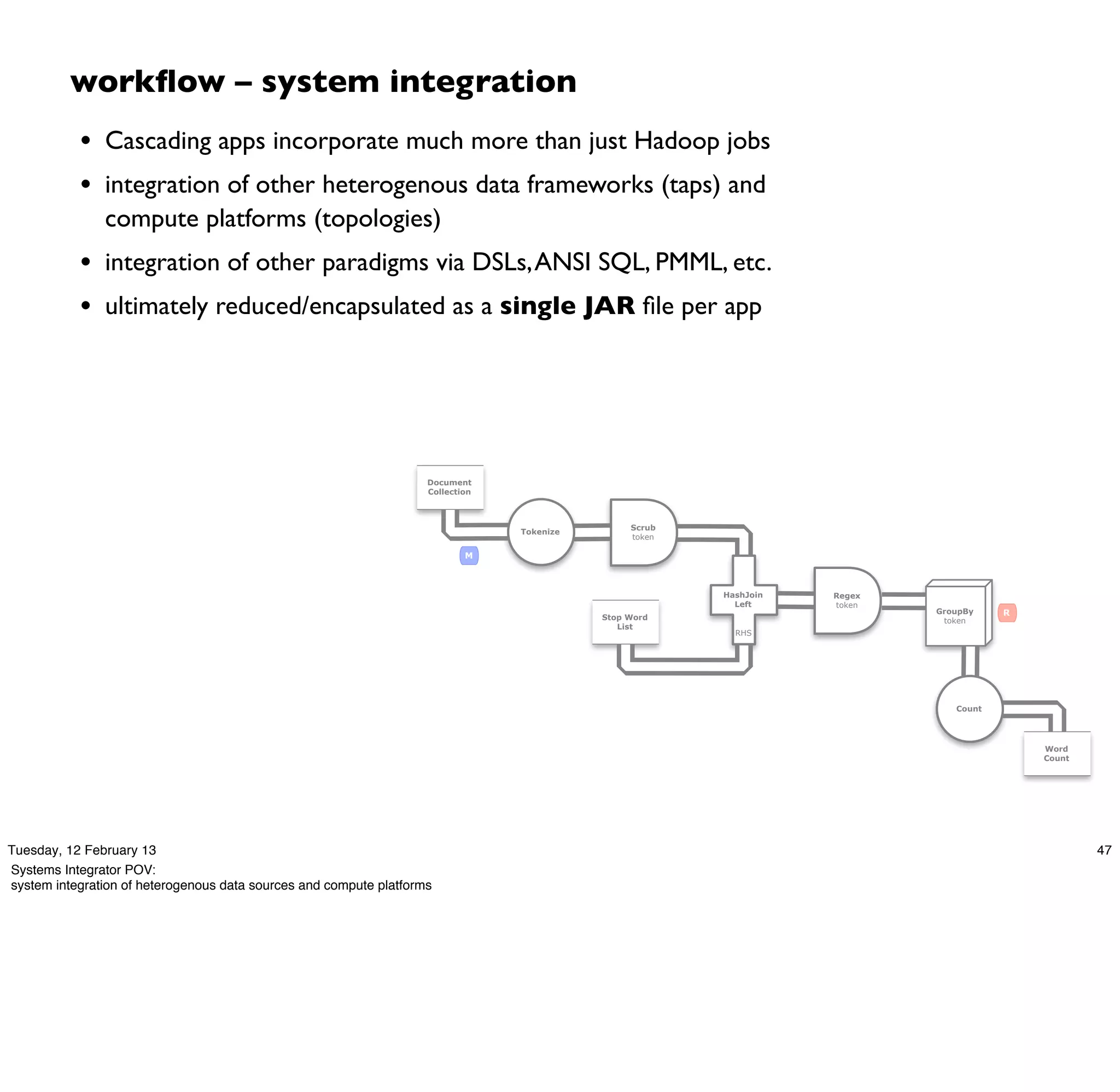
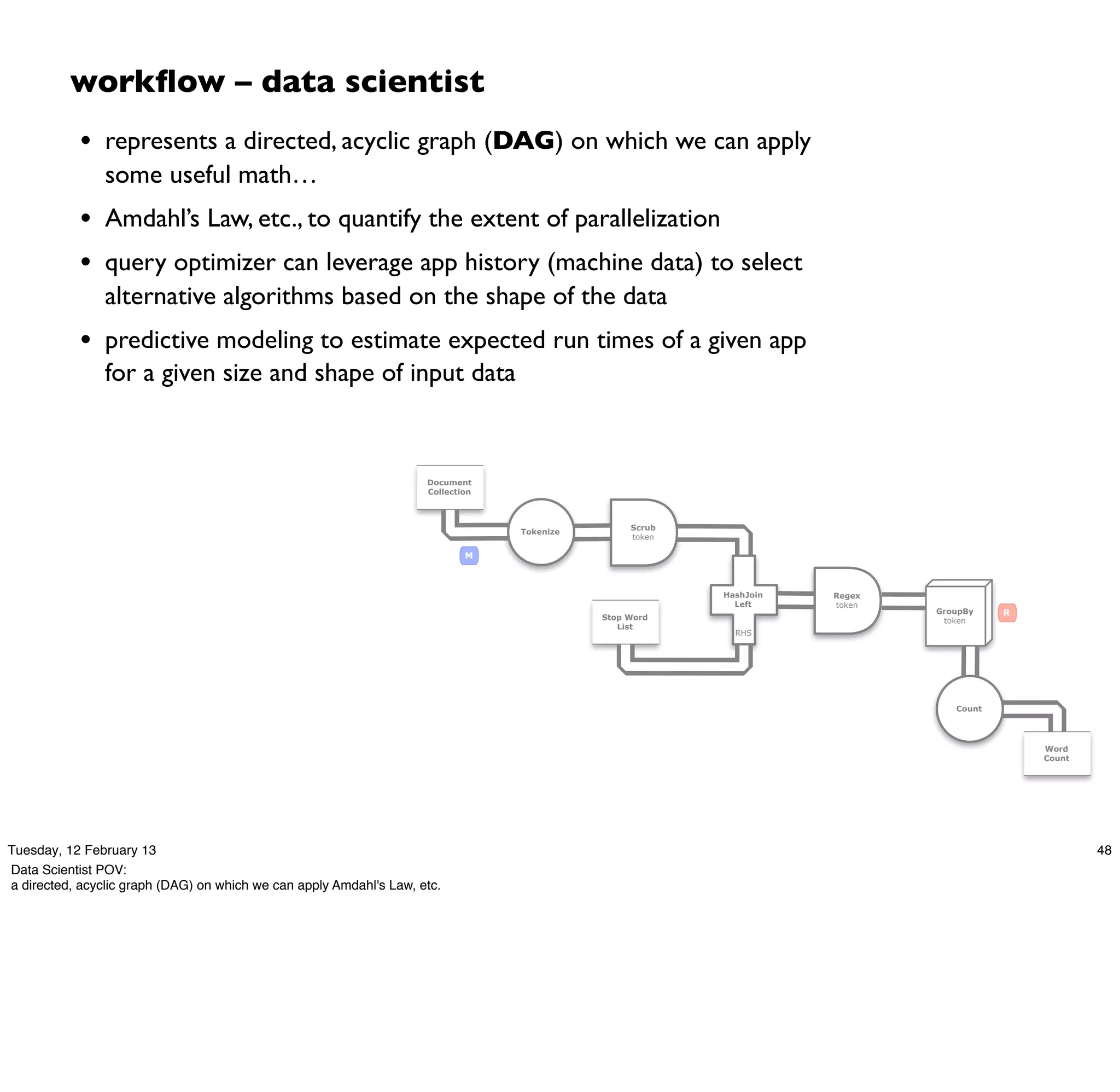
Cascading is an open source framework for building enterprise data workflows. It provides a simple API and domain-specific languages to build robust applications that can operate at scale. Cascading uses a pattern language to ensure best practices and uses taps to integrate different data sources. It supports various topologies including Hadoop, local mode, and in-memory grids.







































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)













