Recommended
PDF
PDF
その文字列検索、std::string::findだけで大丈夫ですか?【Sapporo.cpp 第8回勉強会(2014.12.27)】
PPTX
PDF
PDF
PDF
自然言語処理はじめました - Ngramを数え上げまくる
PDF
IT業界における伝統芸能の継承 #hachiojipm
PPTX
PDF
PDF
言語処理するのに Python でいいの? #PyDataTokyo
PDF
PPTX
深層学習を用いた言語モデルによる俳句生成に関する研究
PDF
PDF
PPTX
さくっとはじめるテキストマイニング(R言語) スタートアップ編
PDF
PDF
大規模日本語ブログコーパスにおける言語モデルの構築と評価
PDF
PDF
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
PDF
PDF
PDF
Segmenting Sponteneous Japanese using MDL principle
PDF
PDF
PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl...
PDF
構文情報に基づく機械翻訳のための能動学習手法と人手翻訳による評価
PDF
[第2版]Python機械学習プログラミング 第8章
PDF
PDF
"Programming Hive" Reading #1
More Related Content
PDF
PDF
その文字列検索、std::string::findだけで大丈夫ですか?【Sapporo.cpp 第8回勉強会(2014.12.27)】
PPTX
PDF
PDF
PDF
自然言語処理はじめました - Ngramを数え上げまくる
PDF
IT業界における伝統芸能の継承 #hachiojipm
PPTX
Similar to Pythonで自然言語処理
PDF
PDF
言語処理するのに Python でいいの? #PyDataTokyo
PDF
PPTX
深層学習を用いた言語モデルによる俳句生成に関する研究
PDF
PDF
PPTX
さくっとはじめるテキストマイニング(R言語) スタートアップ編
PDF
PDF
大規模日本語ブログコーパスにおける言語モデルの構築と評価
PDF
PDF
PDF
第三回さくさくテキストマイニング勉強会 入門セッション
PDF
PDF
PDF
Segmenting Sponteneous Japanese using MDL principle
PDF
PDF
PDF
CluBERT: A Cluster-Based Approach for Learning Sense Distributions in Multipl...
PDF
構文情報に基づく機械翻訳のための能動学習手法と人手翻訳による評価
PDF
[第2版]Python機械学習プログラミング 第8章
More from moai kids
PDF
PDF
"Programming Hive" Reading #1
PDF
Casual Compression on MongoDB
PDF
PDF
掲示板時間軸コーパスを用いたワードトレンド解析(公開版)
PDF
PDF
n-gramコーパスを用いた類義語自動獲得手法について
PDF
Programming Hive Reading #4
PDF
Programming Hive Reading #3
PDF
PDF
PDF
PDF
PDF
Hadoop Conference Japan 2011 Fallに行ってきました
KEY
PDF
HandlerSocket plugin Client for Javaとそれを用いたベンチマーク
PDF
KEY
PDF
PDF
Recently uploaded
PDF
第25回FA設備技術勉強会_自宅で勉強するROS・フィジカルAIアイテム.pdf
PDF
基礎から学ぶ PostgreSQL の性能監視 (PostgreSQL Conference Japan 2025 発表資料)
PDF
安価な ロジック・アナライザを アナライズ(?),Analyze report of some cheap logic analyzers
PPTX
PDF
visionOS TC「新しいマイホームで過ごすApple Vision Proとの新生活」
PDF
PCCC25(設立25年記念PCクラスタシンポジウム):東京大学情報基盤センター テーマ1/2/3「Society5.0の実現を目指す『計算・データ・学習...
Pythonで自然言語処理 1. 2. 3. 4. 5. 作成したデモアプリ
• mecab.py
• 自然文をMeCabを用いてわかち書き
• kytea.py
• 自然文をKyTeaを用いてわかち書き
• markov.py
• Markov過程に基づいて文章を自動生成
• freq.py
• n-gramモデルに基づいて頻度の数え上げ
• map.py / reduce.py
• freq.pyをHadoop上で動くように展開
• (bmc_sample.py)
• 2-gramコーパスから分布類似度を算出する
• Baiduコーパスダウンロード広場で配布されているもの
http://www.baidu.jp/corpus/
5
6. 7. MeCab実行例
$mecab
桑野さんがまた醜態をさらす
桑野
名詞,固有名詞,人名,姓,*,*,桑野,クワノ,クワノ
さん
名詞,接尾,人名,*,*,*,さん,サン,サン
が
助詞,格助詞,一般,*,*,*,が,ガ,ガ
また
接続詞,*,*,*,*,*,また,マタ,マタ
醜態
名詞,一般,*,*,*,*,醜態,シュウタイ,シュータイ
を
助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
さらす
動詞,自立,*,*,五段・サ行,基本形,さらす,サラス,サラス
EOS
7
8. Python参考コード
[mecab.py]
import sys
import MeCab
import nltk
if __name__ == "__main__":
file = sys.argv[1]
#read file
raw = open(file).read() #ファイルからテキストを全行読み込み
#split word
m = MeCab.Tagger("-Ochasen") #MeCab初期化
node = m.parseToNode(raw) #形態素解析実施
node = node.next
while node:
print node.surface, node.feature #解析結果の語と品詞を標準出力
node = node.next
8
9. 10. KyTea実行例
$$ python kytea.py ~/kytea/chinese.raw ~/kytea/model/lcmc-0.1.1-1.mod | less
----- origin -----
初音未来是CRYPTON FUTURE MEDIA以Yamaha的VOCALOID 2语音合成引擎为基础 发贩售的虚
拟女性歌手软件。2007年8月31日发售,原只可用于Microsoft Windows,2008年3月19日随
CrossOver Mac 6.1发表而可用于Mac OS X。
----- morphology -----
初/chu1_
音/yin1_
未来/wei4_lai2_
是/shi4_
CRYPTON/C_R_Y_P_T_O_N_
FUTURE/F_U_T_U_R_E_
MEDIA/M_E_D_I_A_
以/yi3_
Yamaha/Y_a_m_a_h_a_
的/de5_
10
11. Python参考コード
[kytea.py]
import sys
import commands
if __name__ == "__main__":
file = sys.argv[1]
model = sys.argv[2]
#read file
raw = open(file).read()
print "----- origin -----"
print raw #元データの表示
print "----- morphology -----" #split word
c = 'kytea -model ' + model + ' < ' + file
result = commands.getstatusoutput(c) #kyteaのコマンドを実行
for r in result[1].split(): #わかち書き結果の表示
print r
11
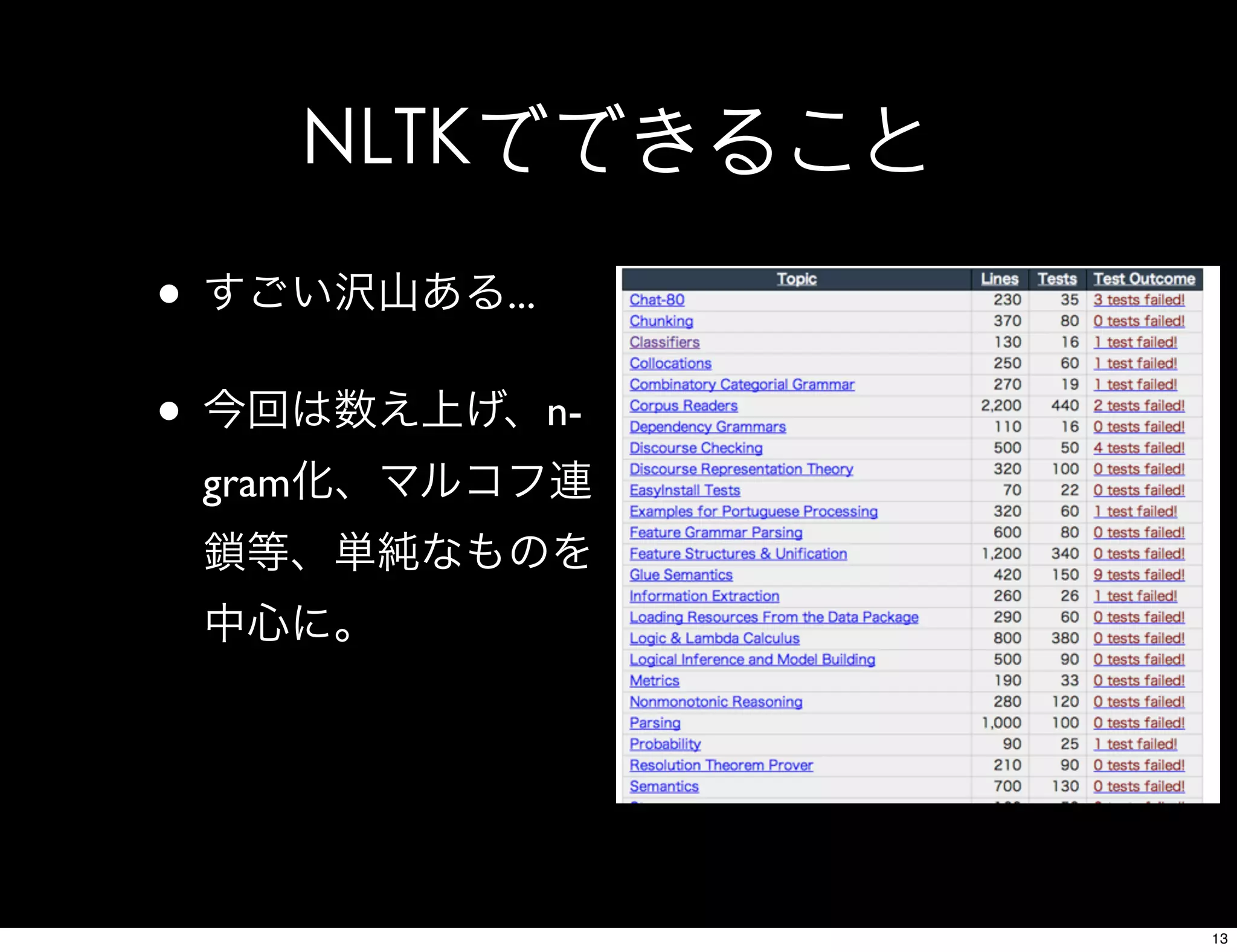
12. 13. 14. 15. 16. 17. 18. NLTK実行例(数え上げ)
[freq.py]
#ワードをn-gramモデルに基づいて解析+出現頻度の数え上げ
def ngrams(words, ngram, limit):
ngrams = nltk.ngrams(words, ngram) #ワード群をn-gram化
fd = nltk.FreqDist(ngrams) #数え上げ
result = {}
for f in fd: #FreqDist構造を普通のdictionaryに変換(非クール)
r = ""
for n in range(0, ngram):
if n > 0:
r += " "
r += f[n]
result[r] = fd[f]
c = 0 #出現頻度多い順にソートして標準出力
for k,v in sorted(result.items(), key=lambda x:x[1], reverse=True):
c += 1
if limit > 0:
if c > limit:
break
print k + "t" + str(result[k])
18
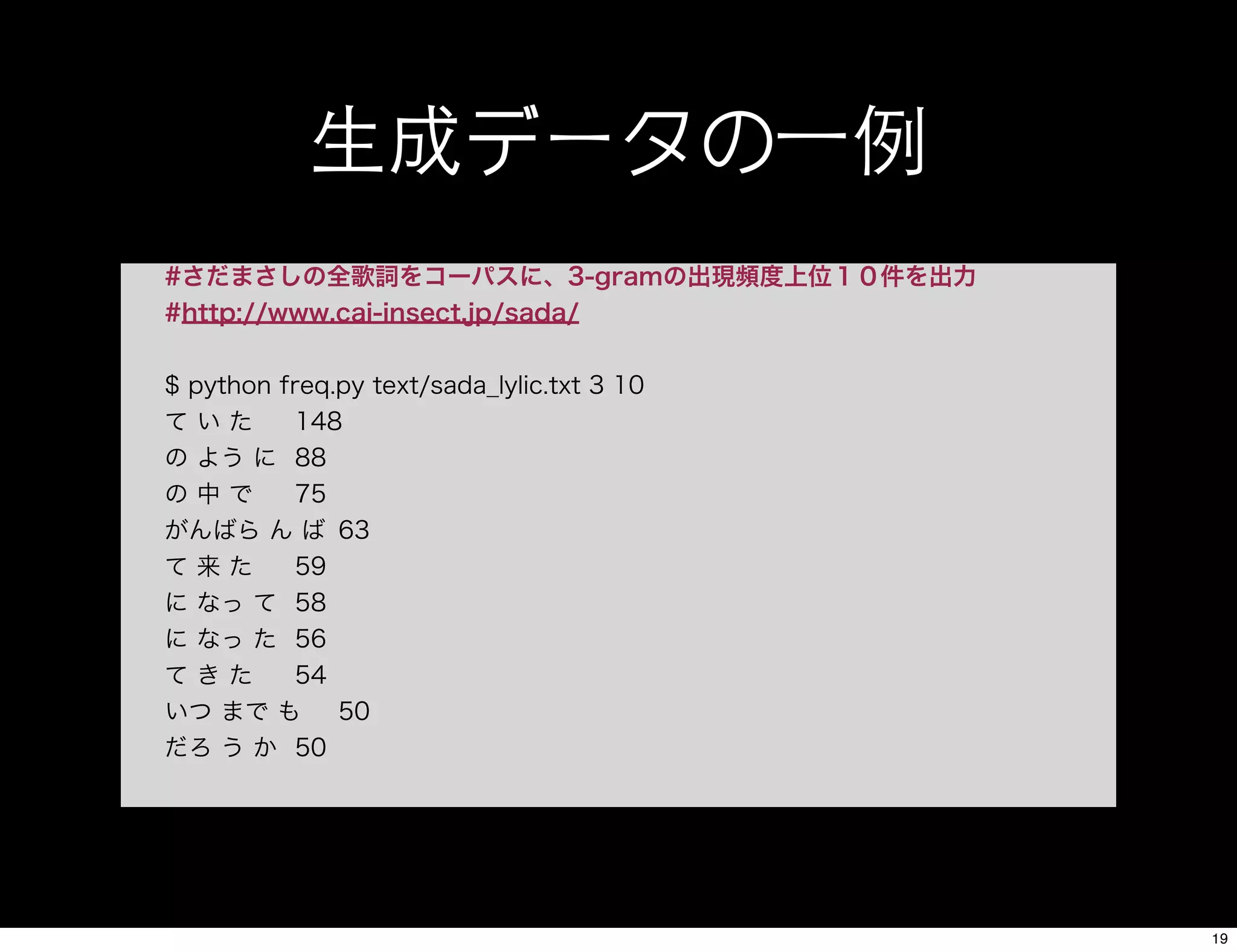
19. 20. 21. 分布類似度の算出
[bmc_sample.py]
#2-gramのコーパス(freq.pyの解析結果のようなもの)を用いて
#ある単語と分布類似度が高いワード上位10件を抽出
#Baiduのサイトから落としてきたプログラムなのでソースの中身の解説は割愛。
$ python bmc_sample.py text/2gram.txt 愛
生命
0.107754
(L:ない L:この R:について L:短い L:始め L:たとえば L:強い L:あゝ R:あり L:小さな)
夢
0.089521
(L:ない L:いつか L:大きな L:この R:という L:から R:だけ L:速く L:ゆく L:なつかしい)
恋
0.083796
(L:この L:ない R:ちゃ L:短い R:あり L:あの R:なんて L:もう L:いつか R:なら)
君
0.079821
(L:ない R:だけ L:いつか R:という L:返す L:咲く L:そして L:から L:ゆく L:陽射し)
心
0.077502
(L:この R:だけ L:ない L:強い L:あゝ L:続ける R:について L:から L:大きな L:咲く)
海
0.076430
(L:この L:いつか L:大きな L:ない L:から L:あの L:けれど L:てる)
町
0.071117
(L:この L:ない L:大きな L:あの L:小さな R:だっ R:それ L:てる)
人
0.070258
(L:ない R:だけ L:いつか R:という L:この L:植える L:ゆく L:違う R:として R:それぞれ)
まま
0.064601
(L:この L:ない L:あの R:だっ R:この)
あなた
0.060459
(L:ない R:だけ L:いつか L:から L:通る L:速く L:ゆく L:本当は L:たとえば L:違う)
21
22. 23. 24. Hadoop Streaming
コマンド例
$hadoop jar ${HADOOP_HOME}/contrib/streaming/hadoop-0.20.x-streaming.jar
-mapper "python map.py"
-reducer "python reduce.py"
-input /python/input/
-output /python/output
-mapper:Mapタスク
-reducer:Reduceタスク
-input:解析対象のデータフォルダ/ファイル
-output:解析結果の出力フォルダ
※他にもJobConfに設定できる内容はだいたいオプションにある。
http://hadoop.apache.org/common/docs/r0.20.2/streaming.html#Streaming+Options+and+Usage
24
25. Map参考コード
[map.py]
if __name__ == "__main__":
for line in sys.stdin: #標準入力から1行づつ読み込み
line = line.strip()
words = parse(line)
fd = nltk.FreqDist(words)
for f in fd:
print f + “¥t” fd[f] #標準出力にKey/Valueのペアを出力
25
26. Reduce参考コード
[reduce.py]
if __name__ == "__main__":
word2count = {}
for line in sys.stdin: #標準入力からKey/Valueを取得
line = line.strip()
word, count = line.split('t', 1)
try:
count = int(count)
word2count[word] = word2count.get(word, 0) + count
exceptValueError:
pass
sorted_word2count = sorted(word2count.items(), key=itemgetter(0))
for word, count in sorted_word2count:
print '%st%s'% (word, count) #標準出力にKey/Valueのペアを出力
26
27.






![[lib]MeCab(めかぶ)
• 日本語の自然文を形態素解析するライブラリ
http://mecab.sourceforge.net/
• たぶん世界で一番有名で一番使われている
• Macのspotlightでも使われているとか
• C言語で実装されているが、各種言語へのバイ
ンディングも存在する(Python/Perl/Ruby/Java)
6](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-6-2048.jpg)

![Python参考コード
[mecab.py]
import sys
import MeCab
import nltk
if __name__ == "__main__":
file = sys.argv[1]
#read file
raw = open(file).read() #ファイルからテキストを全行読み込み
#split word
m = MeCab.Tagger("-Ochasen") #MeCab初期化
node = m.parseToNode(raw) #形態素解析実施
node = node.next
while node:
print node.surface, node.feature #解析結果の語と品詞を標準出力
node = node.next
8](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-8-2048.jpg)
![[lib]KyTea(きゅーてぃー)
• 京都大学のGraham Neubigさんが中心となって
開発された形態素解析ライブラリ
http://www.phontron.com/kytea/
• 教師データを元に単語の分割と発音推定を行
う
• 日本語と中国語のモデルデータも公開されて
いる。今回は中国語を使ってみる。
9](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-9-2048.jpg)

![Python参考コード
[kytea.py]
import sys
import commands
if __name__ == "__main__":
file = sys.argv[1]
model = sys.argv[2]
#read file
raw = open(file).read()
print "----- origin -----"
print raw #元データの表示
print "----- morphology -----" #split word
c = 'kytea -model ' + model + ' < ' + file
result = commands.getstatusoutput(c) #kyteaのコマンドを実行
for r in result[1].split(): #わかち書き結果の表示
print r
11](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-11-2048.jpg)
![[lib] NLTK(えぬえるてぃーけー)
• Python向けに提供されている自然言語処理関
連の処理全般を内包したライブラリ
http://www.nltk.org/
• 本も出ている。これから買うなら日本語訳版
がオススメ
12](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-12-2048.jpg)
![NLTK実行例(Markov連鎖)
[markov.py]
#trigram(3-gram)なワード群を元にMarkov過程に基づいてそれらしい文章を自動生
成
def markovgen(words,length):
text = nltk.Text(words) #ワード群をToken化
gen = text.generate(length) #trigram/Markov過程に基づいてランダムに自動生成
print gen
14](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-14-2048.jpg)


![[参考]Markov過程
• Wikipediaに項があります
http://ja.wikipedia.org/wiki/%E3%83%9E%E3%83%AB%E3%82%B3%E3%83%95%E9%81%8E
%E7%A8%8B
• 確率過程の一つ。それ以上の説明はこの場で
は割愛。
• 卑近な例だと自動文章生成bot、自動要約bot
などでよく用いられる。
例: http://gigazine.net/index.php?/news/comments/20090709_markov_chain/
17](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-17-2048.jpg)
![NLTK実行例(数え上げ)
[freq.py]
#ワードをn-gramモデルに基づいて解析+出現頻度の数え上げ
def ngrams(words, ngram, limit):
ngrams = nltk.ngrams(words, ngram) #ワード群をn-gram化
fd = nltk.FreqDist(ngrams) #数え上げ
result = {}
for f in fd: #FreqDist構造を普通のdictionaryに変換(非クール)
r = ""
for n in range(0, ngram):
if n > 0:
r += " "
r += f[n]
result[r] = fd[f]
c = 0 #出現頻度多い順にソートして標準出力
for k,v in sorted(result.items(), key=lambda x:x[1], reverse=True):
c += 1
if limit > 0:
if c > limit:
break
print k + "t" + str(result[k])
18](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-18-2048.jpg)
![[参考]n-gram言語モデル
• Wikipediaに項があります
(ただし正確な記述とは言いがたい・・)
http://ja.wikipedia.org/wiki/%E5%85%A8%E6%96%87%E6%A4%9C%E7%B4%A2#N-Gram
• 「ある文字列の中で、N個の文字列または単語
の組み合わせが、どの程度出現するか」
を調べるための言語モデル。
• 検索のインデクシング等によく使われる
20](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-20-2048.jpg)
![分布類似度の算出
[bmc_sample.py]
#2-gramのコーパス(freq.pyの解析結果のようなもの)を用いて
#ある単語と分布類似度が高いワード上位10件を抽出
#Baiduのサイトから落としてきたプログラムなのでソースの中身の解説は割愛。
$ python bmc_sample.py text/2gram.txt 愛
生命
0.107754
(L:ない L:この R:について L:短い L:始め L:たとえば L:強い L:あゝ R:あり L:小さな)
夢
0.089521
(L:ない L:いつか L:大きな L:この R:という L:から R:だけ L:速く L:ゆく L:なつかしい)
恋
0.083796
(L:この L:ない R:ちゃ L:短い R:あり L:あの R:なんて L:もう L:いつか R:なら)
君
0.079821
(L:ない R:だけ L:いつか R:という L:返す L:咲く L:そして L:から L:ゆく L:陽射し)
心
0.077502
(L:この R:だけ L:ない L:強い L:あゝ L:続ける R:について L:から L:大きな L:咲く)
海
0.076430
(L:この L:いつか L:大きな L:ない L:から L:あの L:けれど L:てる)
町
0.071117
(L:この L:ない L:大きな L:あの L:小さな R:だっ R:それ L:てる)
人
0.070258
(L:ない R:だけ L:いつか R:という L:この L:植える L:ゆく L:違う R:として R:それぞれ)
まま
0.064601
(L:この L:ない L:あの R:だっ R:この)
あなた
0.060459
(L:ない R:だけ L:いつか L:から L:通る L:速く L:ゆく L:本当は L:たとえば L:違う)
21](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-21-2048.jpg)
![[参考]分布類似度
• 「似た語は似た文脈で出現する」
という仮説に基づいて算出される類似度。
- 上記の場合「さだまさし」と「中島みゆき」は似たよう
な文脈で語られているので似ているとする
さだ_まさし_の_歌_は_暗い_けど_好き
中島_みゆき_の_歌_は_暗い_けど_好き
彼_の_性格_は_暗い_から_嫌い
エグザイル_は_2038_年_に_日本_の_人口_を_抜くから_好き
エグザイル_の_歌_は_嫌い。
松崎_しげる_の_顔_は_暗い。いや_黒い。
22](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-22-2048.jpg)
![[lib]Hadoop(はどぅーぷ)
• 世間では話題になってるらしいアレ
http://hadoop.apache.org/
• 本も出ている。
• Hadoop Streamingを用いることでPythonでも
Map/Reduceロジックが書ける
23](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-23-2048.jpg)

![Map参考コード
[map.py]
if __name__ == "__main__":
for line in sys.stdin: #標準入力から1行づつ読み込み
line = line.strip()
words = parse(line)
fd = nltk.FreqDist(words)
for f in fd:
print f + “¥t” fd[f] #標準出力にKey/Valueのペアを出力
25](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-25-2048.jpg)
![Reduce参考コード
[reduce.py]
if __name__ == "__main__":
word2count = {}
for line in sys.stdin: #標準入力からKey/Valueを取得
line = line.strip()
word, count = line.split('t', 1)
try:
count = int(count)
word2count[word] = word2count.get(word, 0) + count
exceptValueError:
pass
sorted_word2count = sorted(word2count.items(), key=itemgetter(0))
for word, count in sorted_word2count:
print '%st%s'% (word, count) #標準出力にKey/Valueのペアを出力
26](https://image.slidesharecdn.com/20101110python-101107030821-phpapp02/75/Python-26-2048.jpg)




























![[第2版]Python機械学習プログラミング 第8章](https://cdn.slidesharecdn.com/ss_thumbnails/20181015-181029035714-thumbnail.jpg?width=640&height=640&fit=bounds)

























