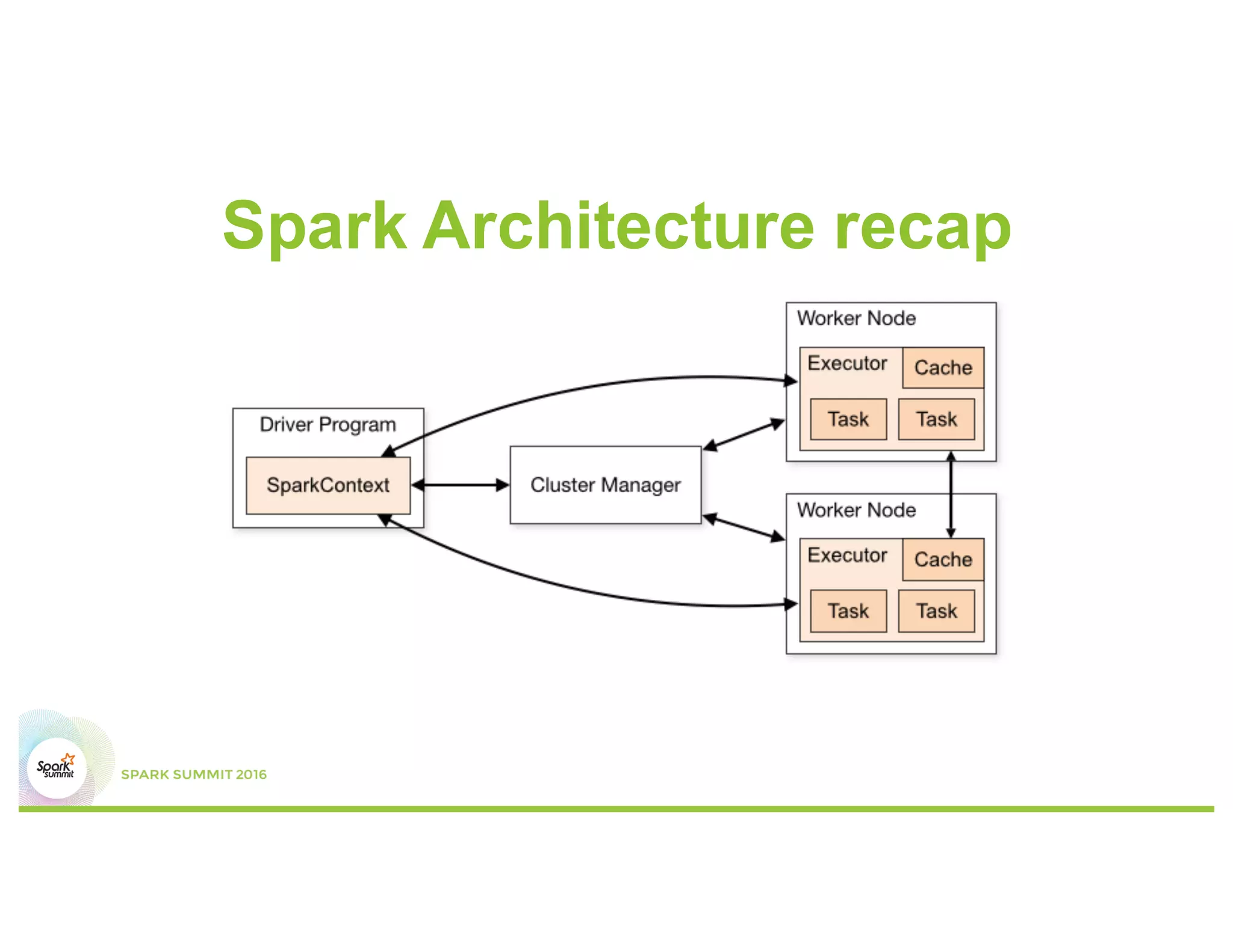
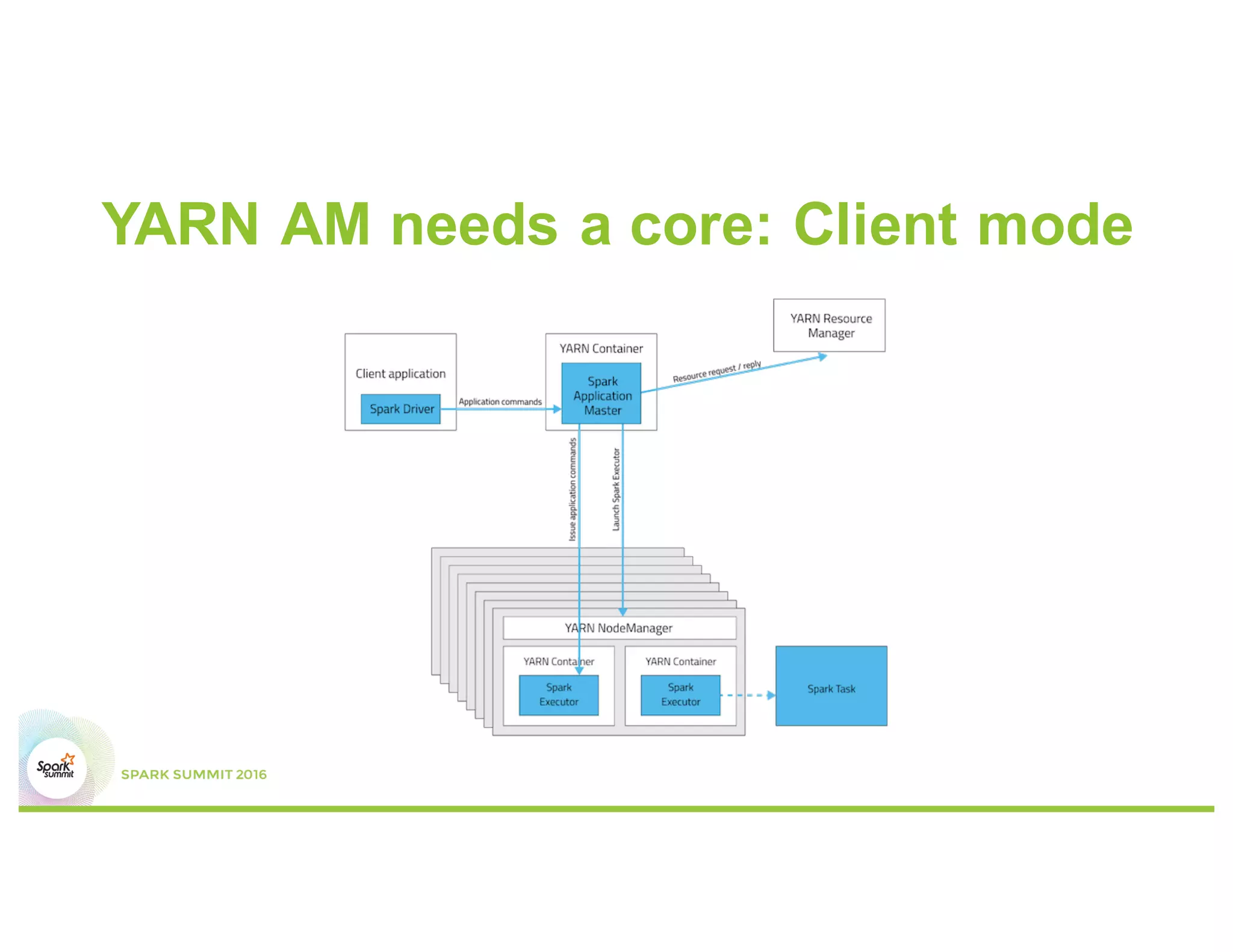
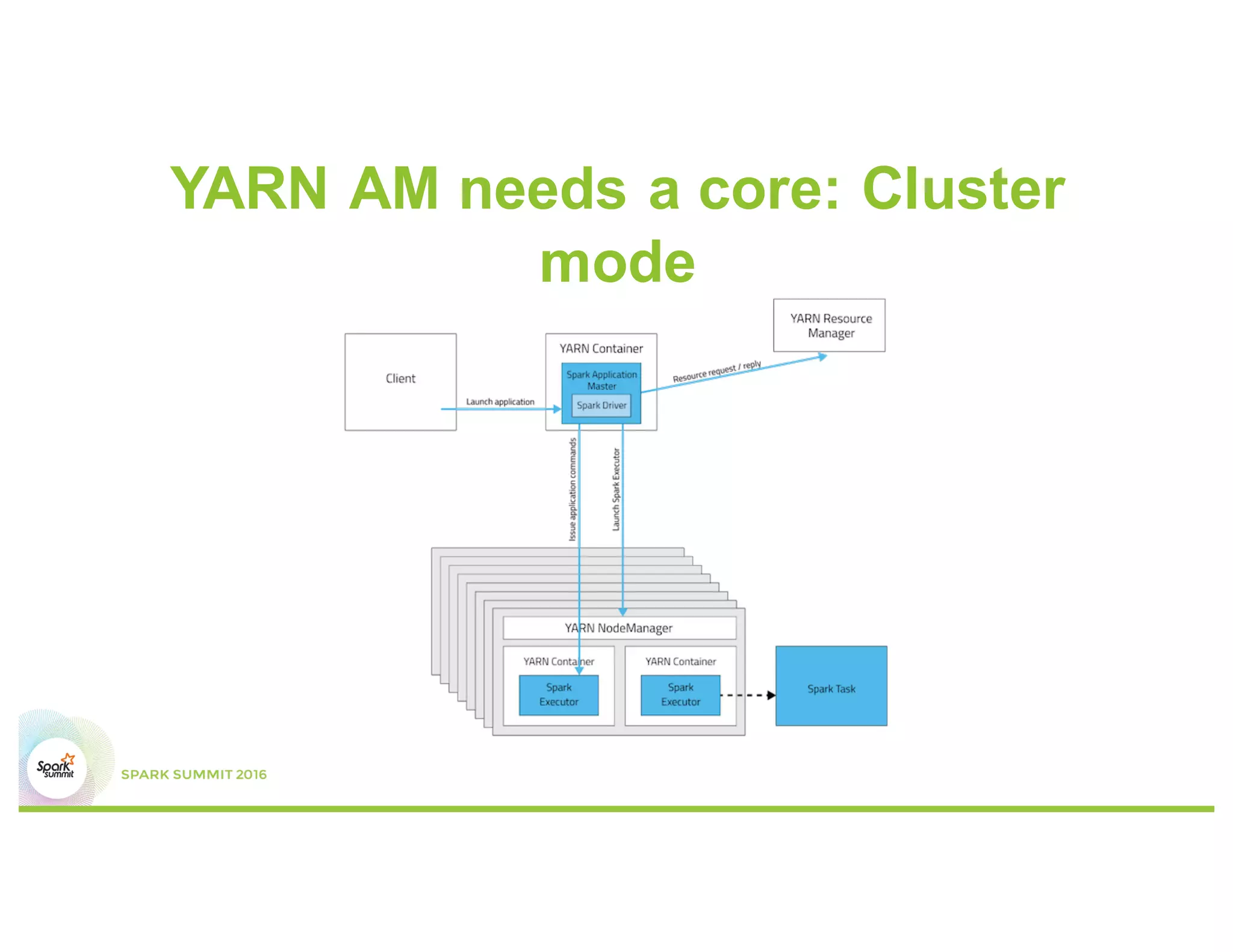
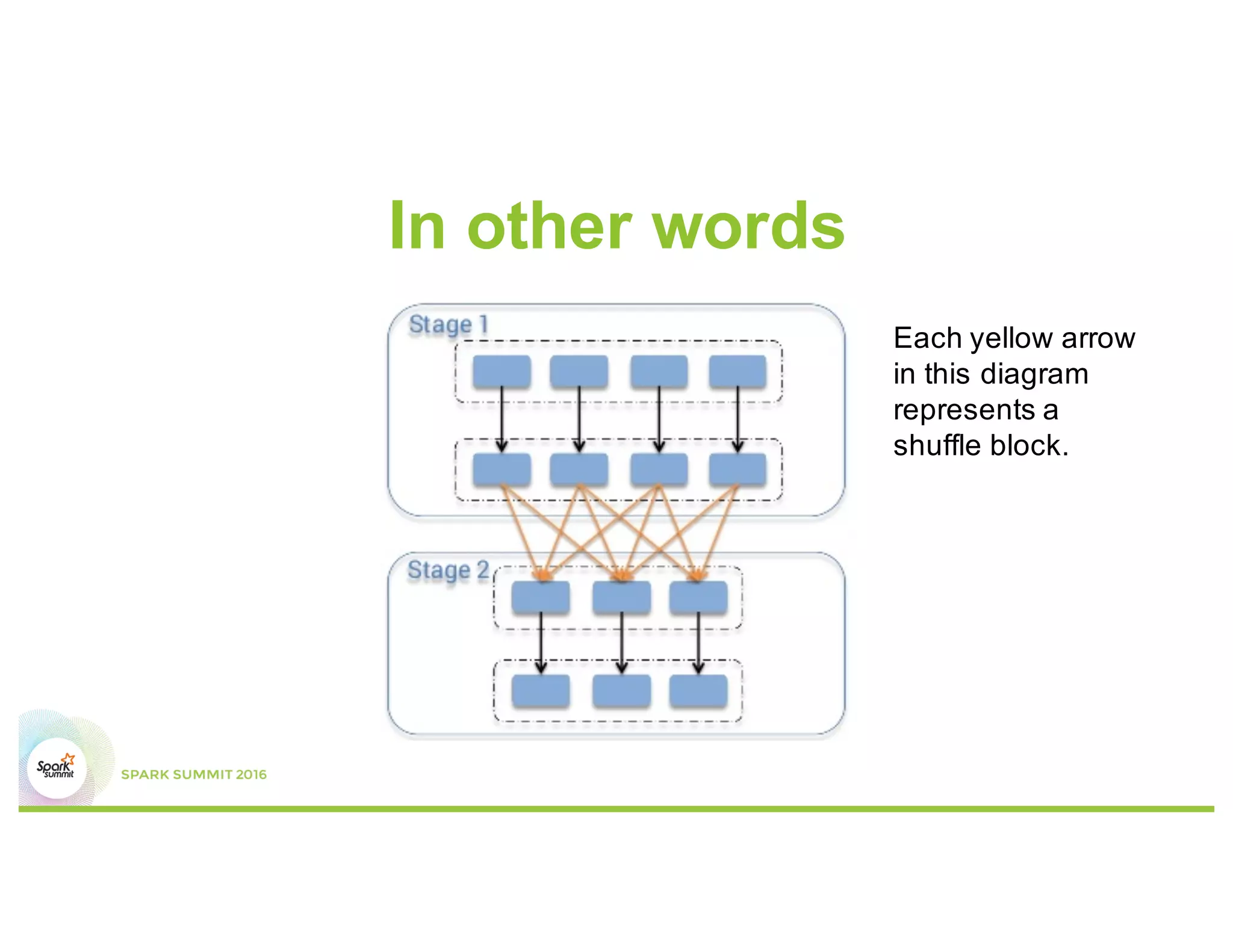
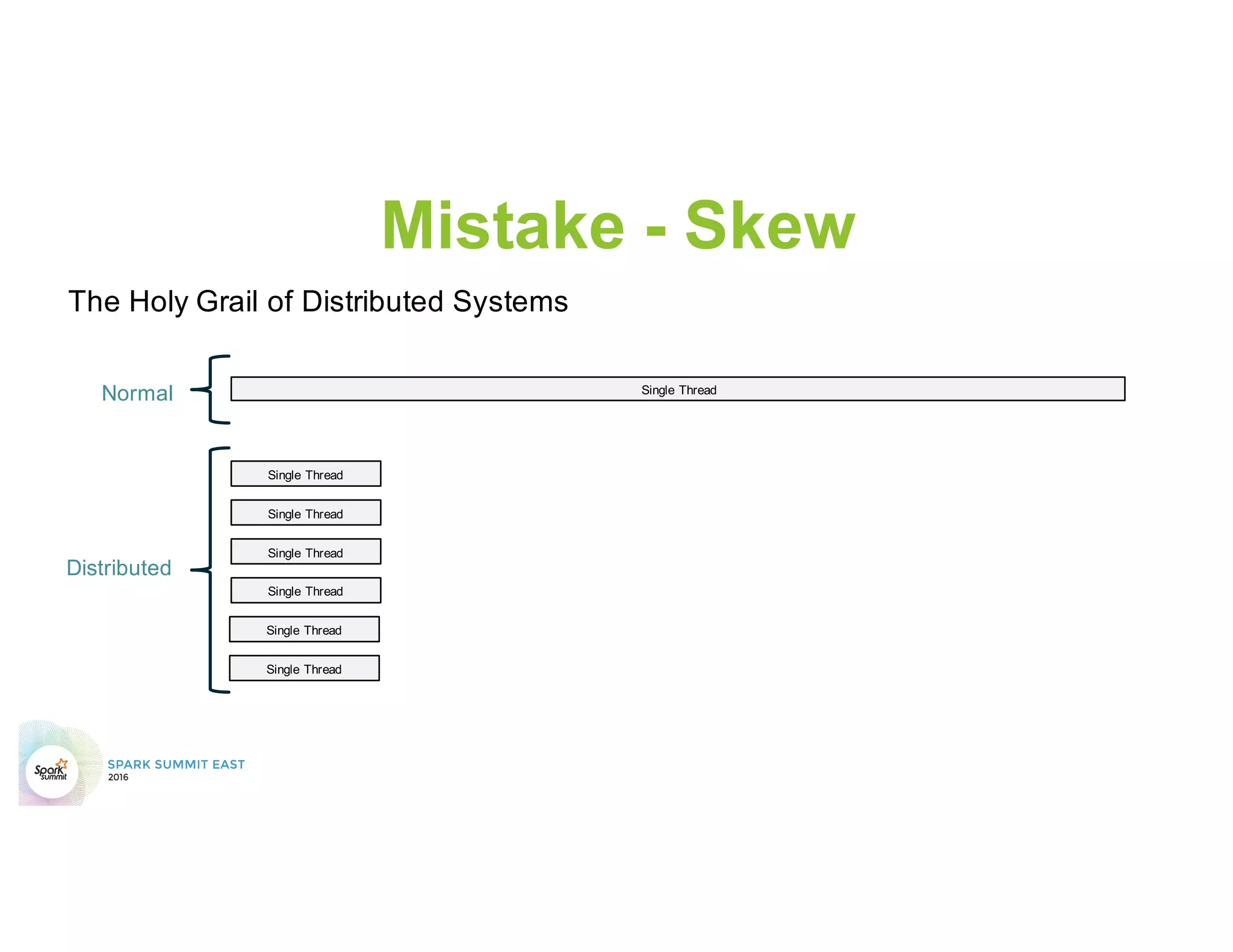
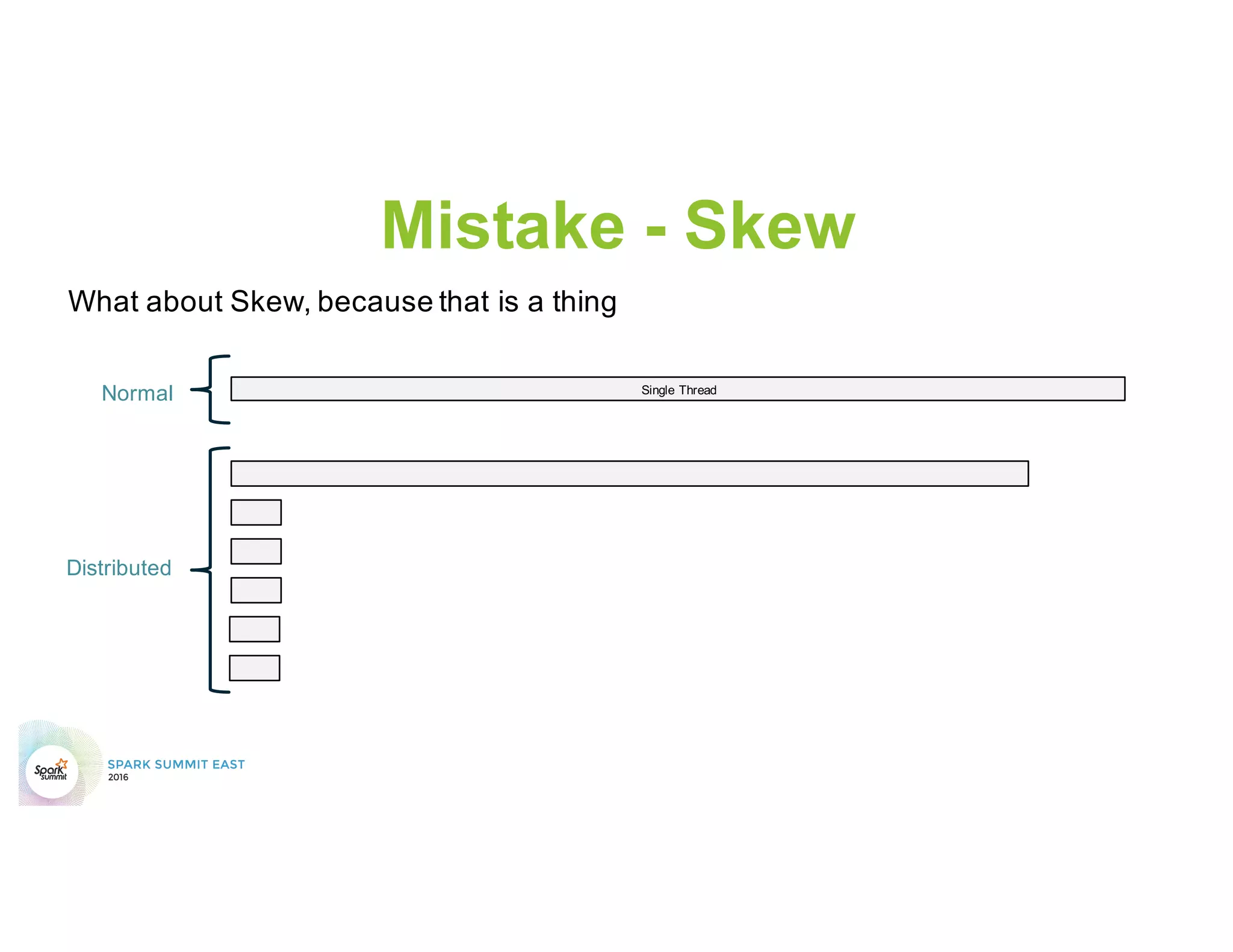
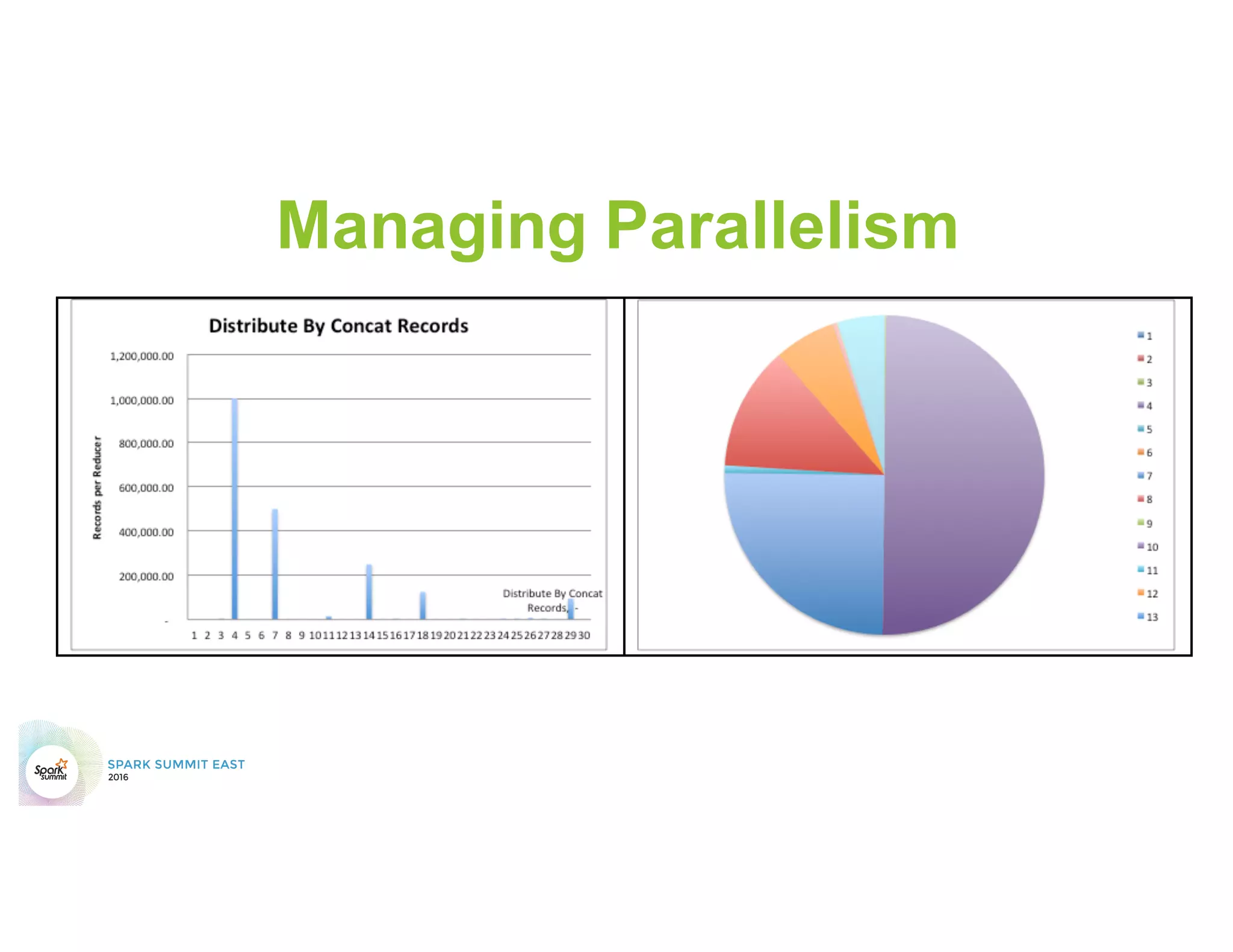
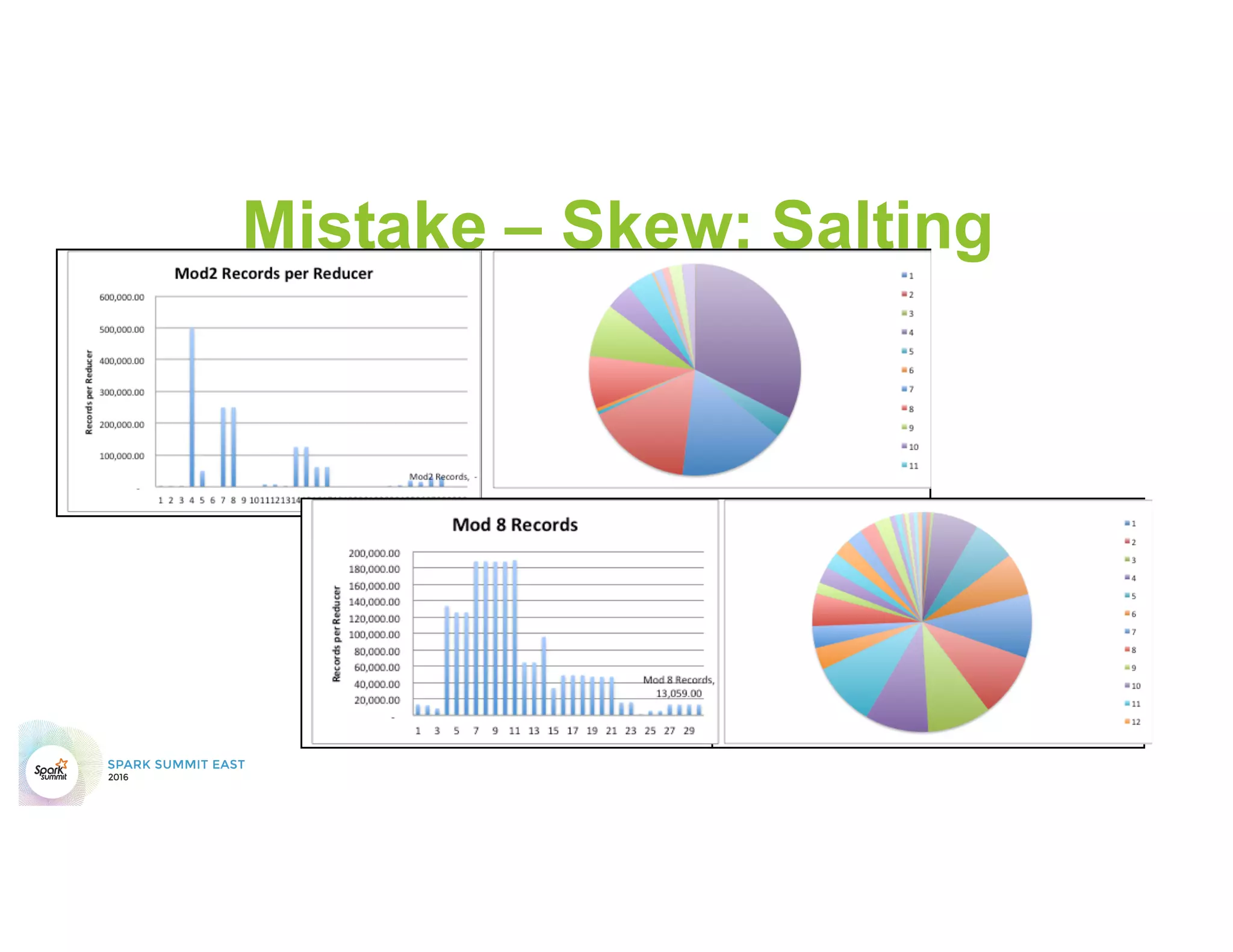
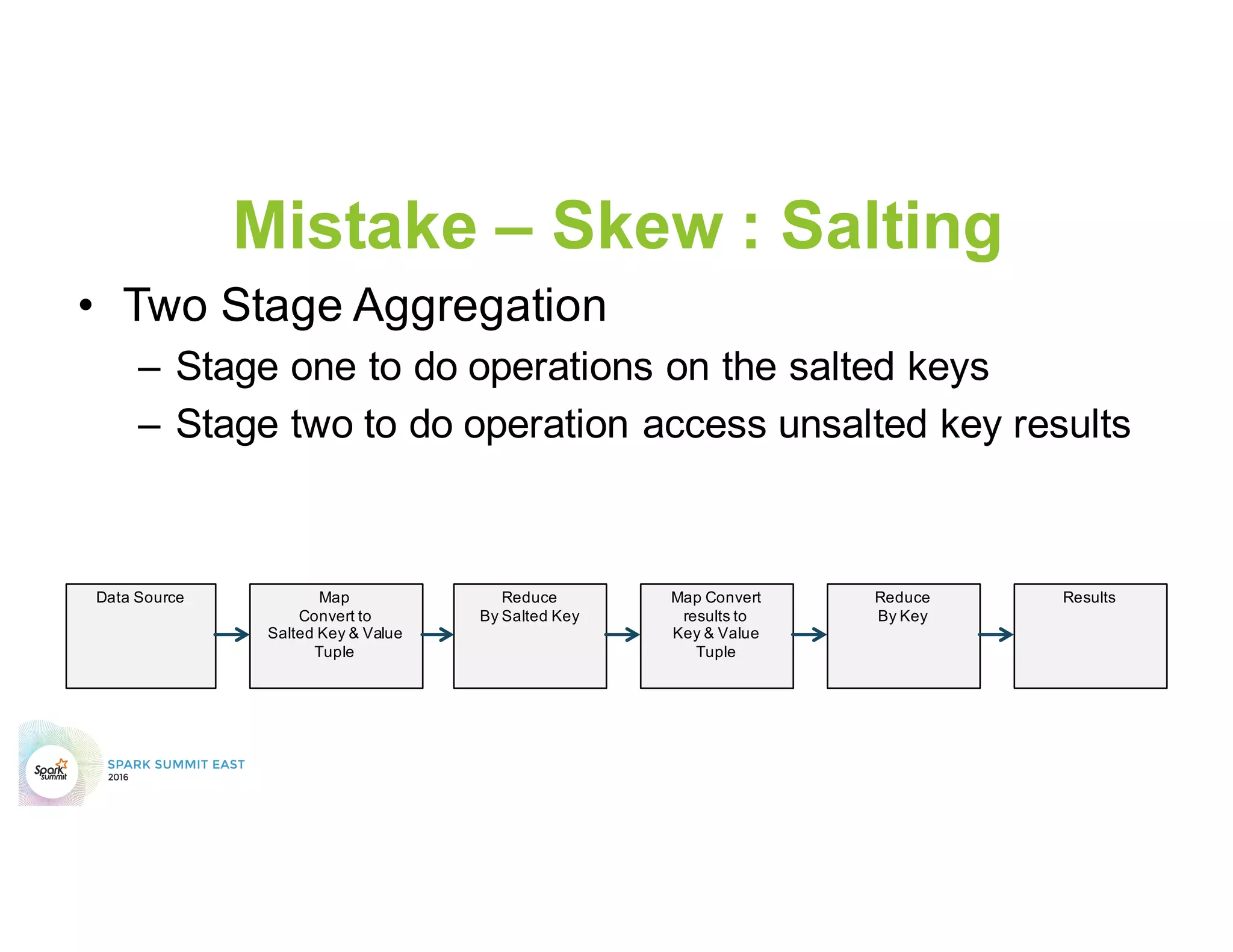
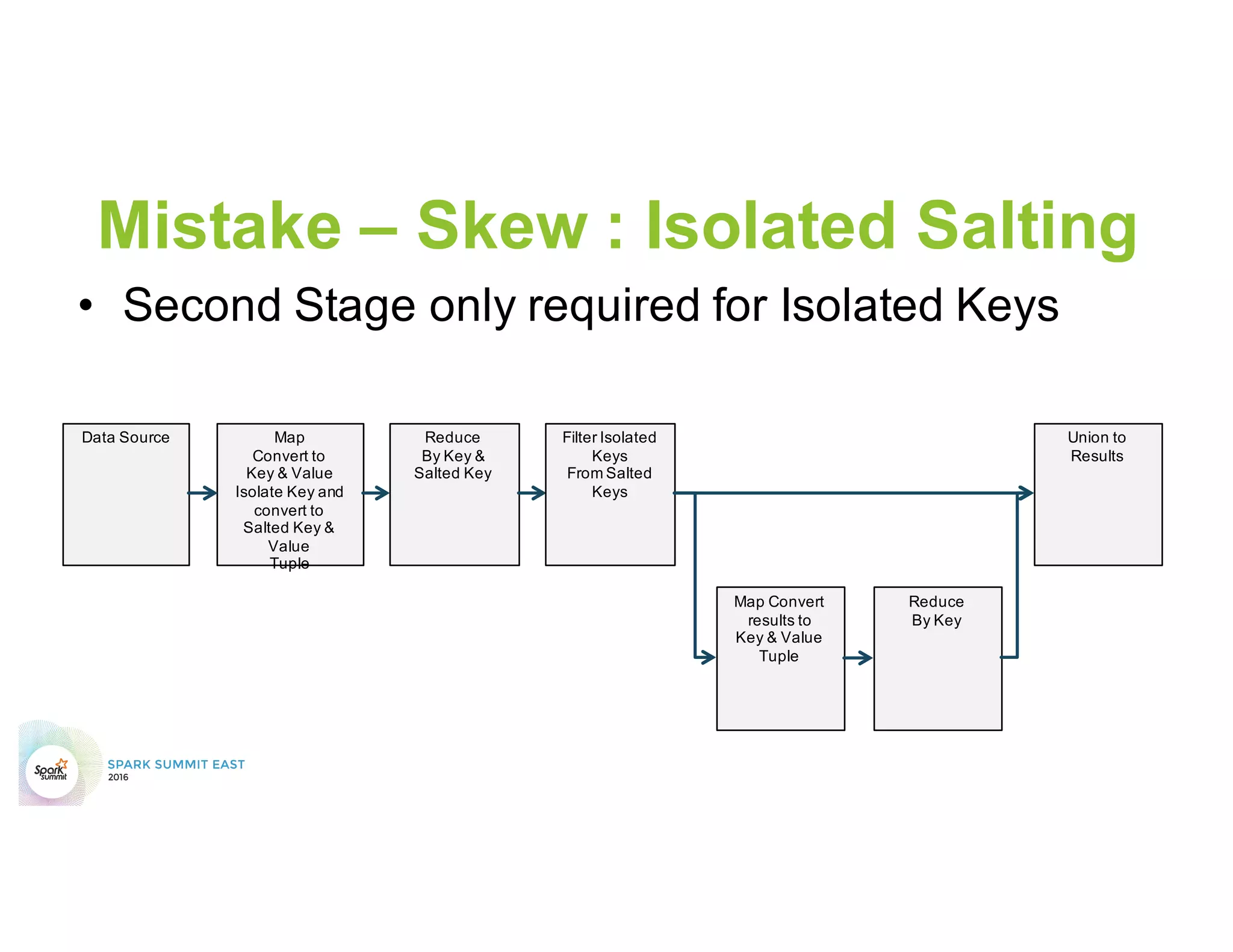
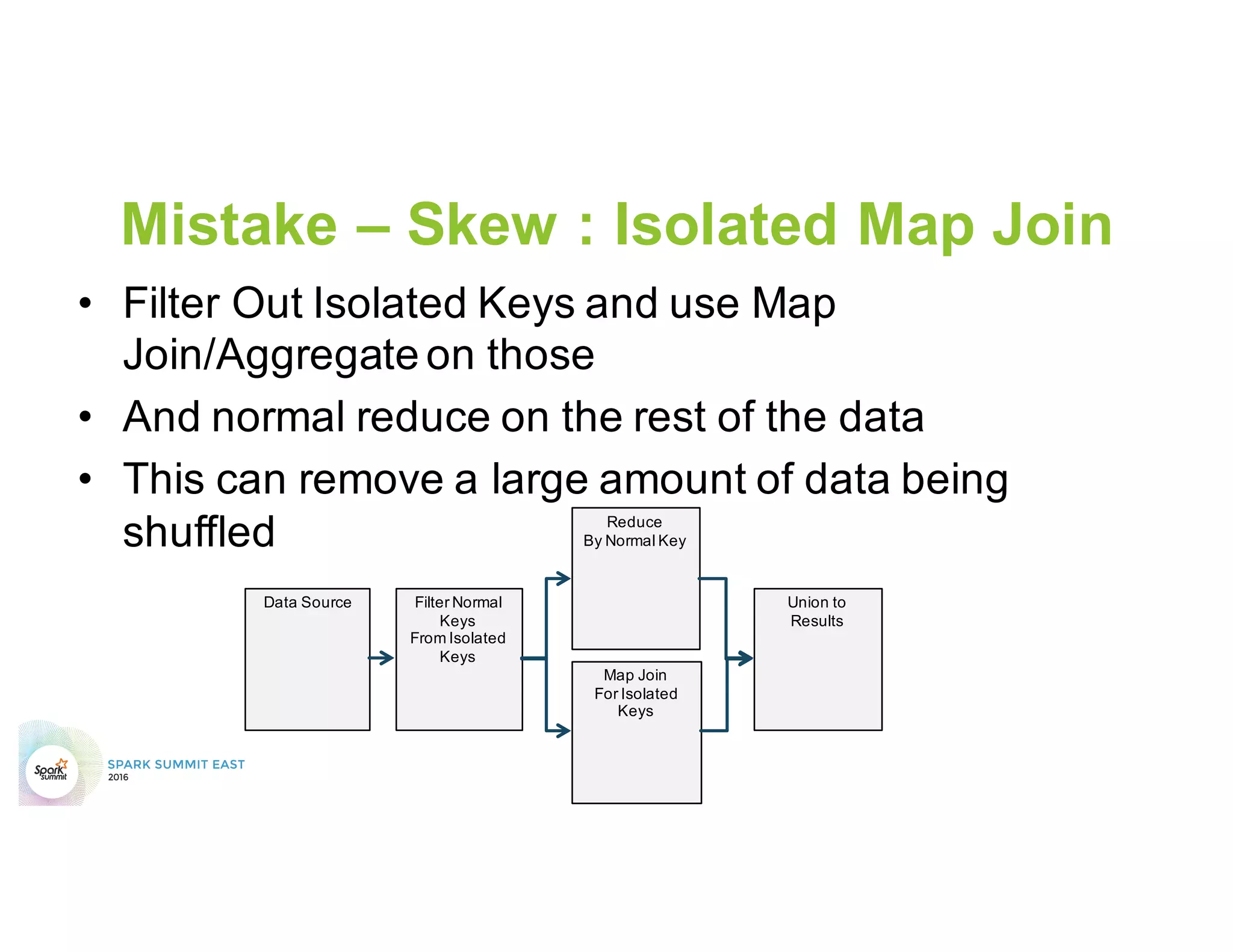
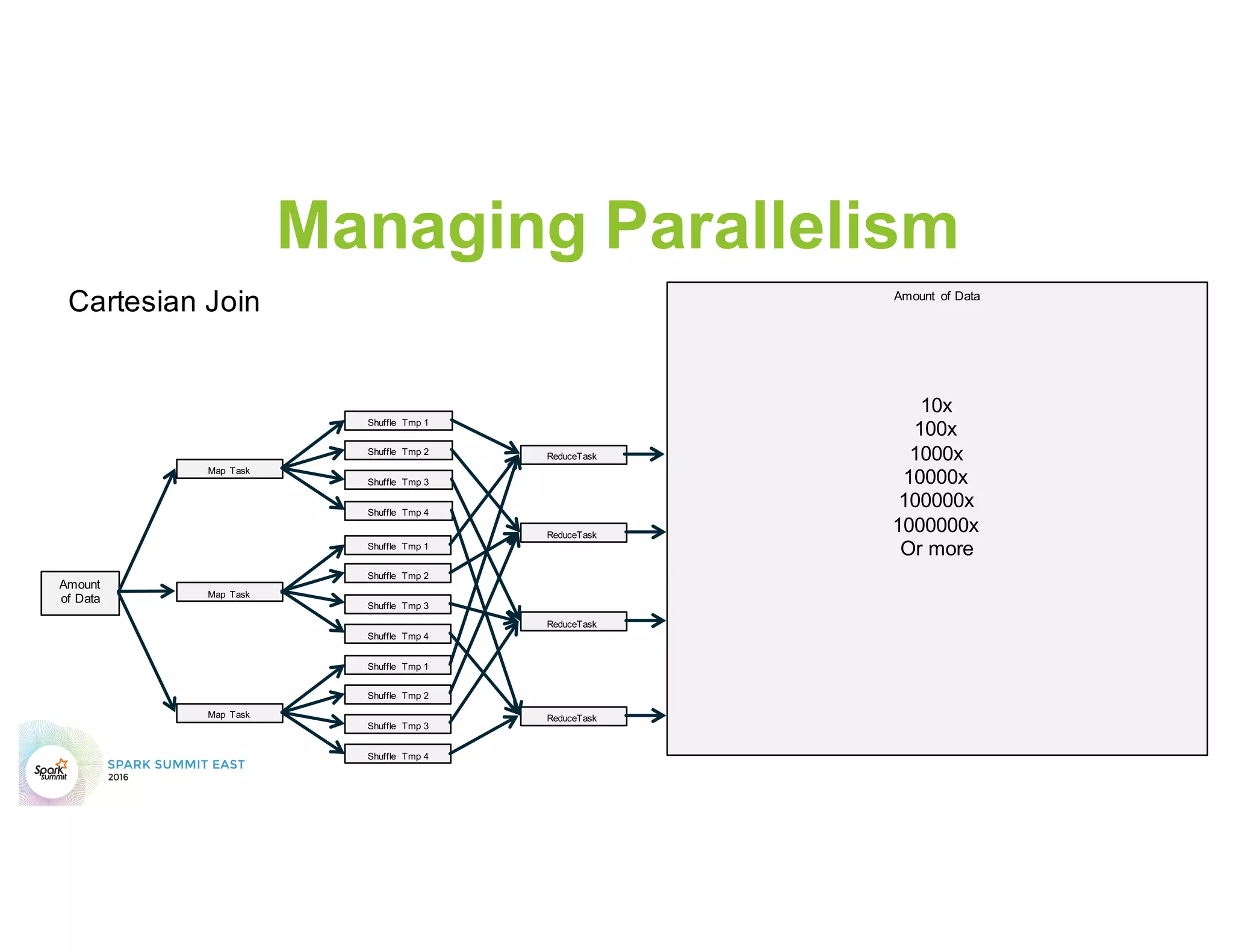
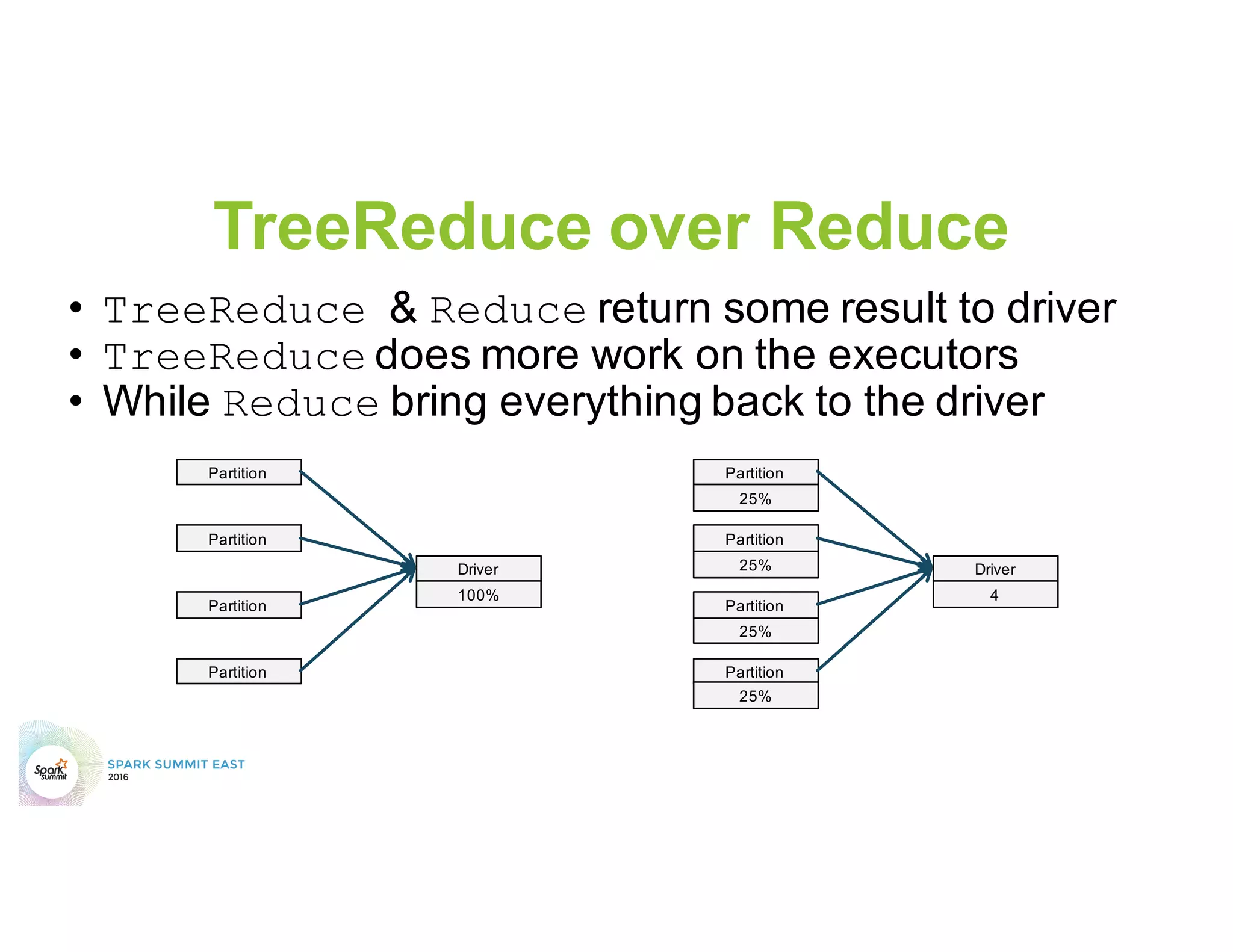
This document discusses common mistakes people make when writing Spark applications and provides recommendations to address them. It covers issues related to executor configuration, application failures due to shuffle block sizes exceeding limits, slow jobs caused by data skew, and managing the DAG to avoid excessive shuffles and stages. Recommendations include using smaller executors, increasing the number of partitions, addressing skew through techniques like salting, and preferring ReduceByKey over GroupByKey and TreeReduce over Reduce to improve performance and resource usage.




































![Don’t believe me?
• In MapStatus.scala
def apply(loc: BlockManagerId, uncompressedSizes:
Array[Long]): MapStatus = {
if (uncompressedSizes.length > 2000) {
HighlyCompressedMapStatus(loc, uncompressedSizes)
} else {
new CompressedMapStatus(loc, uncompressedSizes)
}
}](https://image.slidesharecdn.com/top5mistakesv4-160218171402/75/Top-5-mistakes-when-writing-Spark-applications-41-2048.jpg)




































































![[db tech showcase Tokyo 2017] AzureでOSS DB/データ処理基盤のPaaSサービスを使ってみよう (Azure Dat...](https://cdn.slidesharecdn.com/ss_thumbnails/20170907dbtechshowcaseazureossdb-170907082746-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













