1
Copyright (C) 2015National Institute of Informatics, All rights reserved.
Introduction to Machine Learning Theory
for Software Engineers
ソフトウェアエンジニアのための
「機械学習理論」入門
ハンズオン演習ガイド
中井悦司 / Etsuji Nakai
Senior Solution Architect
and Cloud Evangelist
Red Hat K.K.
ver1.7 2015/09/01
2.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
2
ソフトウェアエンジニアのための「機械学習理論」入門
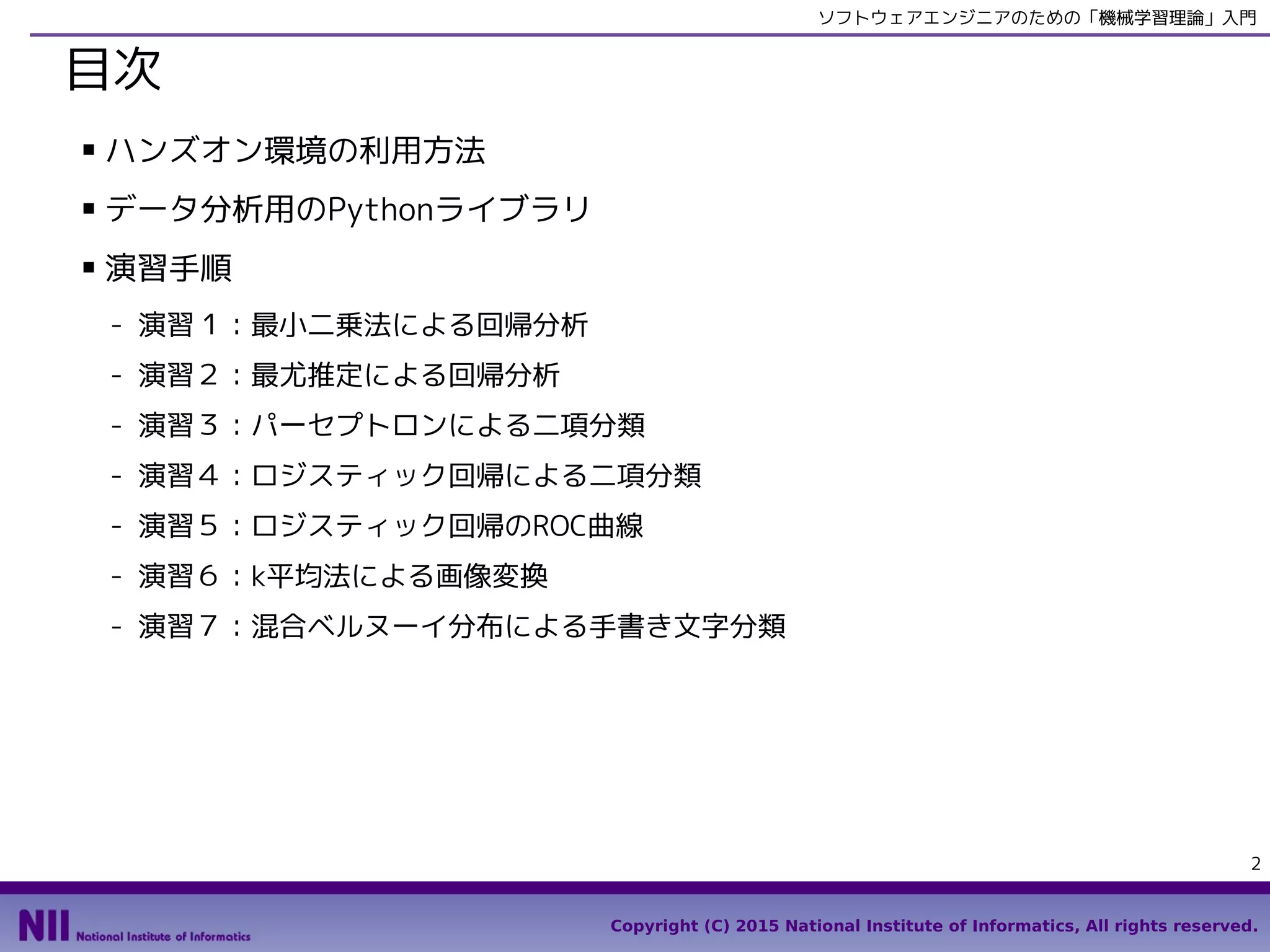
目次
■ ハンズオン環境の利用方法
■ データ分析用のPythonライブラリ
■ 演習手順
- 演習1:最小二乗法による回帰分析
- 演習2:最尤推定による回帰分析
- 演習3:パーセプトロンによる二項分類
- 演習4:ロジスティック回帰による二項分類
- 演習5:ロジスティック回帰のROC曲線
- 演習6:k平均法による画像変換
- 演習7:混合ベルヌーイ分布による手書き文字分類
3.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
3
ソフトウェアエンジニアのための「機械学習理論」入門
ハンズオン環境の利用方法
4.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
4
ソフトウェアエンジニアのための「機械学習理論」入門
ハンズオン環境について
■ Linux(CentOS6)がインストールされたサーバー上にハンズオンユーザー「user01」
〜「user15」が作成されています。
- それぞれのユーザーに個別のVNCデスクトップが用意されており、VNC Viewerから
デスクトップ接続して利用します。
- 接続先IPアドレスとパスワードは、インストラクターから説明があります。
- コマンド端末は、画面左上の「アプリケーション」メニューから「システムツール」
→「端末」を選択します。
■ 各ユーザーのホームディレクトリに「Canopy Express」をインストールします。
- 本環境では各ユーザーのホームディレクトリにインストーラが用意されています。
- Webからダウンロードする場合は、下記のサイトを参照してください。
●
https://www.enthought.com/products/canopy/
5.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
5
ソフトウェアエンジニアのための「機械学習理論」入門
Canopy Expressのインストールと初期設定
■ ホームディレクトリにあるインストーラを実行します。
$ cd
$ bash canopy-1.5.4-rh5-64.sh
Welcome to the Canopy 1.5.4 installer!
To continue the installation, you must review and approve the license term
agreement.
Press Enter to continue
>>>
...(中略)...
Do you approve the license terms? [yes|no]
[no] >>> yes
Canopy will be installed to this location:
/home/user01/Canopy
* Press Enter to accept this location
* Press CTRL-C to abort
* or specify an alternate location. Please ensure that your location
contains only ASCII letters, numbers, and the following punctuation
chars: '.', '_', '-'
[/home/user01/Canopy] >>>
...(中略)...
Thank you for installing Canopy!
[Enter]を押すとライセンスが表示されるので
スペースキーで読み進めます。
「yes」を入力
[Enter]を押す
6.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
6
ソフトウェアエンジニアのための「機械学習理論」入門
Canopy Expressのインストールと初期設定
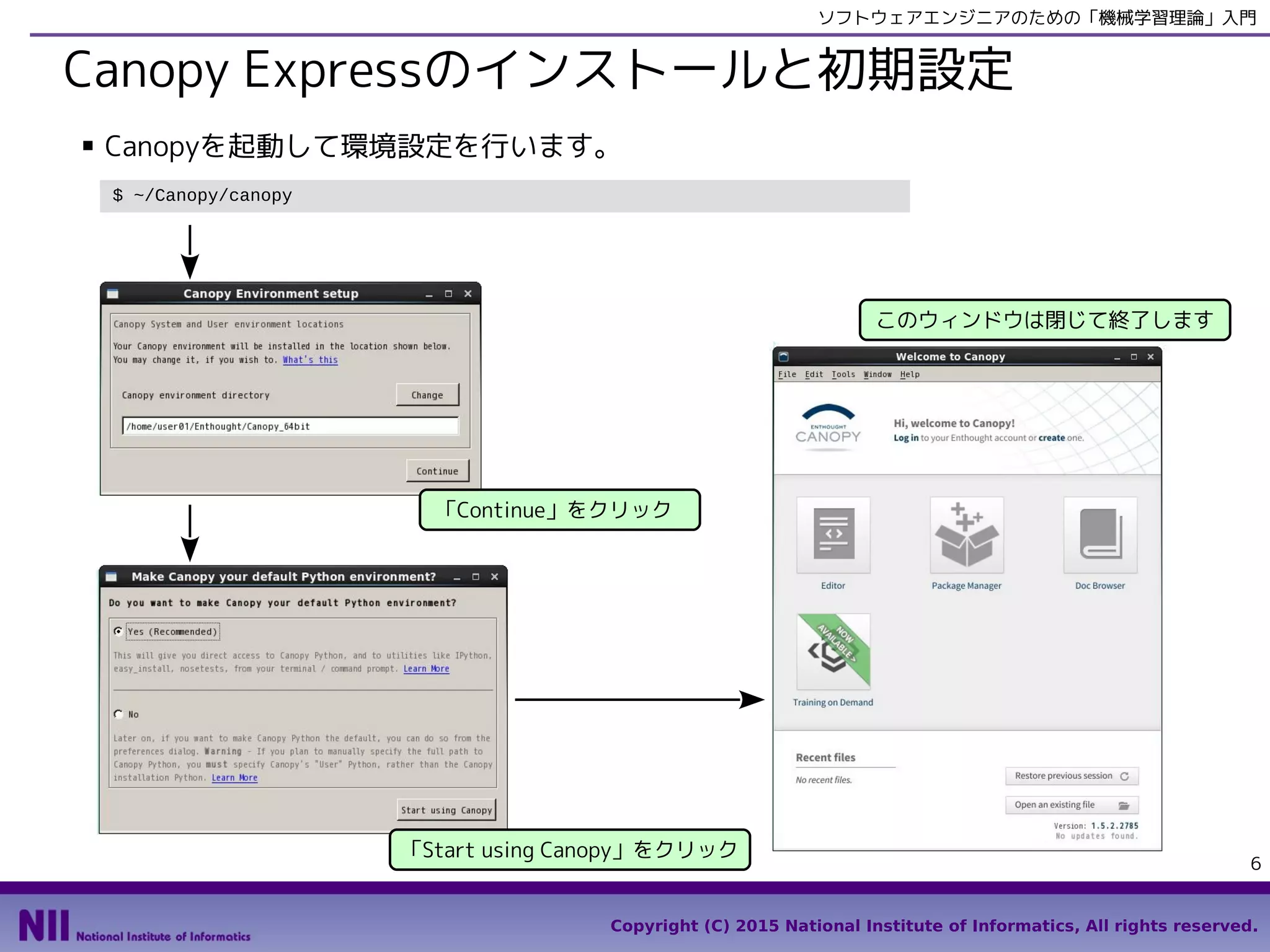
■ Canopyを起動して環境設定を行います。
$ ~/Canopy/canopy
「Continue」をクリック
「Start using Canopy」をクリック
このウィンドウは閉じて終了します
7.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
7
ソフトウェアエンジニアのための「機械学習理論」入門
Canopy Expressのインストールと初期設定
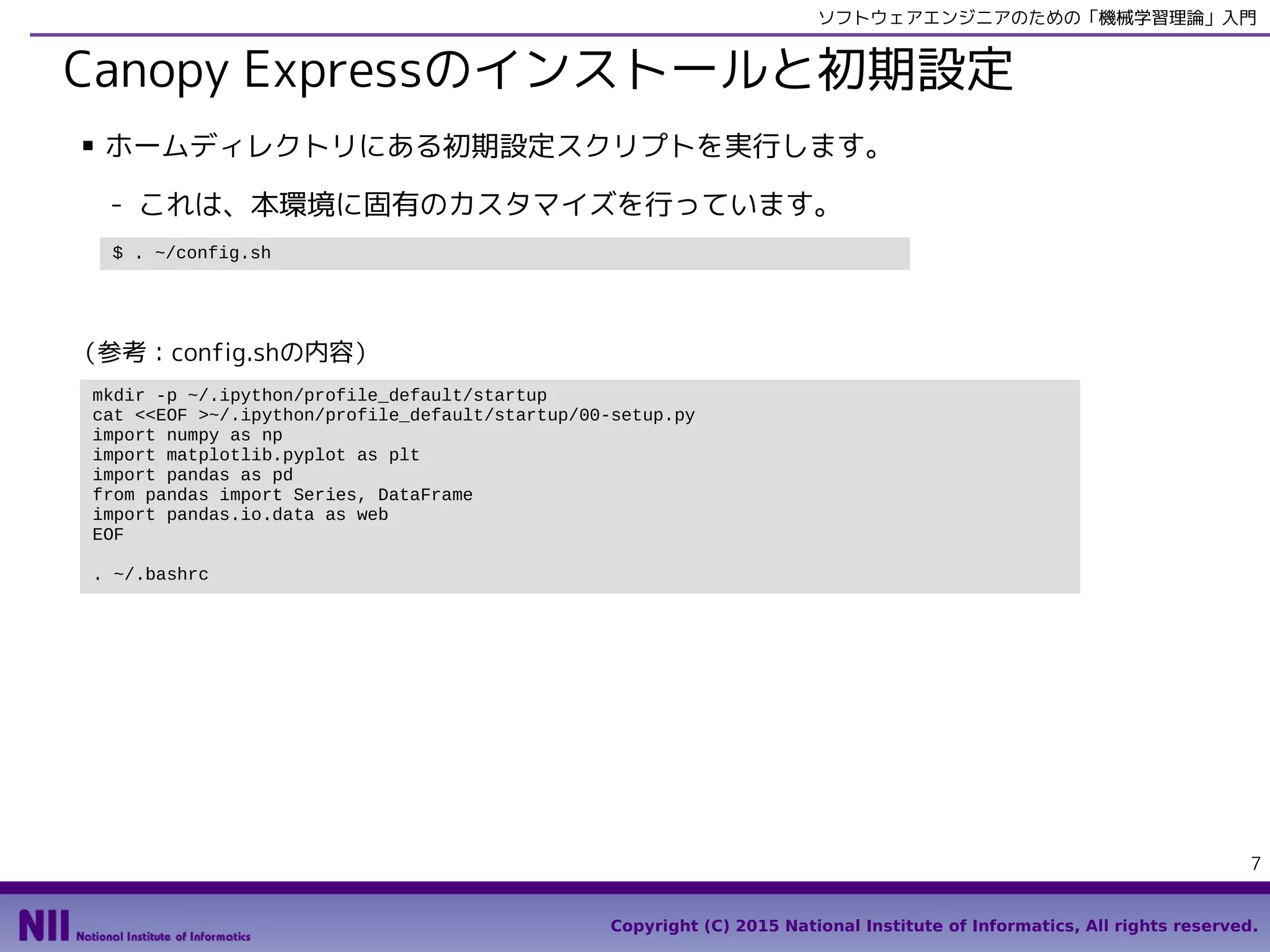
■ サンプルコードをダウンロードして、カスタマイズスクリプトを実行します。
- これは、本環境に固有のカスタマイズを行っています。
mkdir -p ~/.ipython/profile_default/startup
cat <<EOF >~/.ipython/profile_default/startup/00-setup.py
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from pandas import Series, DataFrame
EOF
echo "alias ipython='ipython --pylab'" >> ~/.bashrc
. ~/.bashrc
echo Done.
$ cd
$ wget https://github.com/enakai00/ml4se/raw/master/ml4se.zip
$ unzip ml4se.zip
$ . ml4se/config_centos.sh
(参考:config_centos.shの内容)
8.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
8
ソフトウェアエンジニアのための「機械学習理論」入門
IPythonの使い方
■ 本演習は、IPython(Pythonの対話的操作環境)から行います。
■ IPythonのシェルからは、「!<コマンド>」でOSコマンドが実行できます。
- 「ls」「cd」「cat」などは、「!」を付けなくても実行できます。スクリプトの編集
は、「!vi <ファイル名>」でviエディタを起動します。
- 他のウィンドウでエディタを起動して編集しても構いません。GUIのエディタを使い
たい場合は、デスクトップからフォルダー「ホーム」→「ml4se」→「scripts」を
開いて、中のファイルを右クリック→「geditで開く」を選択します。
$ ipython
Python 2.7.6 | 64-bit | (default, Sep 15 2014, 17:36:10)
Type "copyright", "credits" or "license" for more information.
IPython 2.3.1 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]:
In [1]: ls ml4se
LICENSE README.md config_centos.sh config_mac.sh config_win.bat scripts/
In [2]: cd ~/ml4se/scripts
/home/user01/ml4se/scripts
In [3]: !vi 01-square_error.py
演習用のスクリプトはホームディレクトリの
「ml4se/scripts」ディレクトリー内にあります。
9.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
9
ソフトウェアエンジニアのための「機械学習理論」入門
IPythonの使い方
■ スクリプトの実行は、「%run」コマンドで行います。
■ その他には、ファイル名は [Tab] キーで補完できます。また、[↑][↓] キーで過去の
コマンド履歴の呼び出しが可能です。
In [4]: %run 01-square_error.py
Table of the coefficients
M=0 M=1 M=3 M=9
0 -0.012133 0.737922 0.005026 0.021570
1 NaN -1.500112 9.633393 -121.926645
2 NaN NaN -28.282723 2897.187668
3 NaN NaN 18.422900 -25036.071571
4 NaN NaN NaN 110826.637881
5 NaN NaN NaN -282565.729927
6 NaN NaN NaN 431648.816158
7 NaN NaN NaN -390194.283125
8 NaN NaN NaN 192486.163220
9 NaN NaN NaN -39940.969290
In [5]: exit
In [5]: %paste
■ クリップボードの内容をペーストして実行する
際は、「%paste」コマンドを実行します。
■ IPythonを終了する際は「exit」を入力します。
10.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
10
ソフトウェアエンジニアのための「機械学習理論」入門
データ分析用のPythonライブラリ
11.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
11
ソフトウェアエンジニアのための「機械学習理論」入門
NumPy, pandas, matplotlib について
■ 本演習で使用するPythonスクリプトでは、主に下記のライブラリを使用しています。
- NumPy : ベクトルや行列の演算の他、主要な数学関数や乱数機能を提供します。
- pandas : Rに類似のデータフレーム(スプレッドシートのように、行/列に属性が付
いたデータ構造)を提供します。
- matplotlib : グラフを描画します。
■ これらの詳細は下記の書籍が参考になります。
- Python for Data Analysis(Wes McKinney)
- 邦題は「Pythonによるデータ分析入門」
12.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
12
ソフトウェアエンジニアのための「機械学習理論」入門
NumPyの簡単な利用例
In [1]: import numpy as np
In [2]: a = np.array([[0,1,2],[3,4,5],[6,7,8]])
In [3]: b = np.array([[1,1,1],[2,2,2],[3,3,3]])
In [4]: a
Out[4]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In [5]: b
Out[5]:
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
In [4]: a.T
Out[4]:
array([[0, 3, 6],
[1, 4, 7],
[2, 5, 8]])
In [7]: a*2
Out[7]:
array([[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16]])
In [8]: a+b
Out[8]:
array([[ 1, 2, 3],
[ 5, 6, 7],
[ 9, 10, 11]])
In [6]: np.dot(a,b)
Out[6]:
array([[ 8, 8, 8],
[26, 26, 26],
[44, 44, 44]])
In [15]: np.append(a,b,axis=0)
Out[15]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8],
[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
In [16]: np.append(a,b,axis=1)
Out[16]:
array([[0, 1, 2, 1, 1, 1],
[3, 4, 5, 2, 2, 2],
[6, 7, 8, 3, 3, 3]])
■ 次は、NumPyで行列の計算をする例です。
転置行列
スカラーとの演算は
各成分に適用
行列としての積は、
np.dot()関数を使用
行列成分の結合は、結合の
方向を axis オプションで
指定(0:縦、1:横)
13.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
13
ソフトウェアエンジニアのための「機械学習理論」入門
In [1]: df = DataFrame([[0,1],[2,3],[4,5]], columns=('x','y'))
In [2]: df
Out[2]:
x y
0 0 1
1 2 3
2 4 5
In [3]: df['x']
Out[3]:
0 0
1 2
2 4
Name: x, dtype: int64
In [4]: df.x
Out[4]:
0 0
1 2
2 4
Name: x, dtype: int64
In [5]: df[0:2]
Out[5]:
x y
0 0 1
1 2 3
pandasの簡単な利用例
■ 次は、pandasのデータフレームを使用する例です。
columns
index
columnsの取り出し
(Seriesオブジェクト)
スライス記法は
行の取り出しになる
In [6]: for index, line in df.iterrows():
....: print "index=%d" % index
....: print line
....:
index=0
x 0
y 1
Name: 0, dtype: int64
index=1
x 2
y 3
Name: 1, dtype: int64
index=2
x 4
y 5
Name: 2, dtype: int64
行単位の処理
14.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
14
ソフトウェアエンジニアのための「機械学習理論」入門
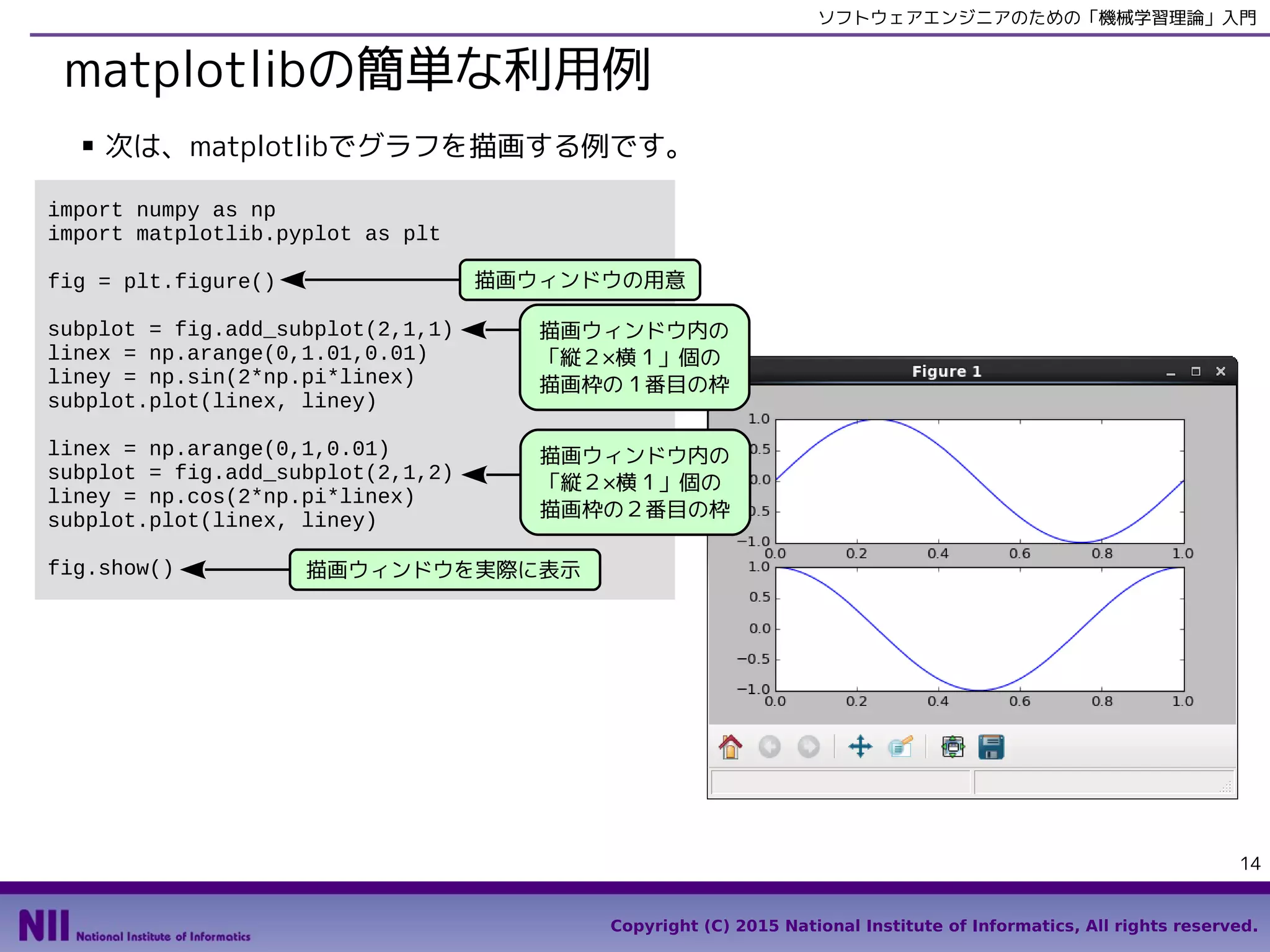
matplotlibの簡単な利用例
■ 次は、matplotlibでグラフを描画する例です。
import numpy as np
import matplotlib.pyplot as plt
fig = plt.figure()
subplot = fig.add_subplot(2,1,1)
linex = np.arange(0,1.01,0.01)
liney = np.sin(2*np.pi*linex)
subplot.plot(linex, liney)
linex = np.arange(0,1,0.01)
subplot = fig.add_subplot(2,1,2)
liney = np.cos(2*np.pi*linex)
subplot.plot(linex, liney)
fig.show()
描画ウィンドウの用意
描画ウィンドウ内の
「縦2×横1」個の
描画枠の1番目の枠
描画ウィンドウ内の
「縦2×横1」個の
描画枠の2番目の枠
描画ウィンドウを実際に表示
15.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
15
ソフトウェアエンジニアのための「機械学習理論」入門
演習手順
16.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
16
ソフトウェアエンジニアのための「機械学習理論」入門
演習1:最小二乗法による回帰分析
■ スクリプト「02-square_error.py」を実行します。
- 最小二乗法による回帰分析を実施します。
■ 具体的な内容は、下記のBlogを参照してください。
- PRML 第1章の多項式フィッティングの例を再現
- http://enakai00.hatenablog.com/entry/2015/04/05/002239
■ スクリプトの下記の値を変えると、データ数(x軸上の観測点の数)を変更できます。
- データ数によって結果がどのように変わるか観察してください。
In [1]: %run 02-square_error.py
#------------#
# Parameters #
#------------#
N=10 # サンプルを取得する位置 x の個数
17.
Copyright (C) 2015National Institute of Informatics, All rights reserved.
17
ソフトウェアエンジニアのための「機械学習理論」入門
演習2:最尤推定による回帰分析
■ スクリプト「03-maximum_likelihood.py」「03-ml_gauss.py」を実行します。
- 最尤推定による回帰分析と最大ログ尤度の計算、および、最尤推定による正規分布
の推定を行います。
■ 具体的な内容は、下記のBlogを参照してください。
- PRML 第1章の「最尤推定によるパラメータフィッティング」の解説
- http://enakai00.hatenablog.com/entry/2015/04/05/220817
■ 「03-loglikelihood.py」の下記の値を変えると、データ数を変更できます。
- データ数によって結果がどのように変わるか観察してください。
■ 「03-ml_gauss.py」を何度か実行して、得られたサンプルによって推定がどのように
変わるか観察してください。
In [1]: %run 03-maximum_likelihood.py
In [2]: %run 03-ml_gauss.py
#------------#
# Parameters #
#------------#
N=10 # サンプルを取得する位置 x の個数


![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
5
ソフトウェアエンジニアのための「機械学習理論」入門
Canopy Expressのインストールと初期設定
■ ホームディレクトリにあるインストーラを実行します。
$ cd
$ bash canopy-1.5.4-rh5-64.sh
Welcome to the Canopy 1.5.4 installer!
To continue the installation, you must review and approve the license term
agreement.
Press Enter to continue
>>>
...(中略)...
Do you approve the license terms? [yes|no]
[no] >>> yes
Canopy will be installed to this location:
/home/user01/Canopy
* Press Enter to accept this location
* Press CTRL-C to abort
* or specify an alternate location. Please ensure that your location
contains only ASCII letters, numbers, and the following punctuation
chars: '.', '_', '-'
[/home/user01/Canopy] >>>
...(中略)...
Thank you for installing Canopy!
[Enter]を押すとライセンスが表示されるので
スペースキーで読み進めます。
「yes」を入力
[Enter]を押す](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-5-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
8
ソフトウェアエンジニアのための「機械学習理論」入門
IPythonの使い方
■ 本演習は、IPython(Pythonの対話的操作環境)から行います。
■ IPythonのシェルからは、「!<コマンド>」でOSコマンドが実行できます。
- 「ls」「cd」「cat」などは、「!」を付けなくても実行できます。スクリプトの編集
は、「!vi <ファイル名>」でviエディタを起動します。
- 他のウィンドウでエディタを起動して編集しても構いません。GUIのエディタを使い
たい場合は、デスクトップからフォルダー「ホーム」→「ml4se」→「scripts」を
開いて、中のファイルを右クリック→「geditで開く」を選択します。
$ ipython
Python 2.7.6 | 64-bit | (default, Sep 15 2014, 17:36:10)
Type "copyright", "credits" or "license" for more information.
IPython 2.3.1 -- An enhanced Interactive Python.
? -> Introduction and overview of IPython's features.
%quickref -> Quick reference.
help -> Python's own help system.
object? -> Details about 'object', use 'object??' for extra details.
In [1]:
In [1]: ls ml4se
LICENSE README.md config_centos.sh config_mac.sh config_win.bat scripts/
In [2]: cd ~/ml4se/scripts
/home/user01/ml4se/scripts
In [3]: !vi 01-square_error.py
演習用のスクリプトはホームディレクトリの
「ml4se/scripts」ディレクトリー内にあります。](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-8-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
9
ソフトウェアエンジニアのための「機械学習理論」入門
IPythonの使い方
■ スクリプトの実行は、「%run」コマンドで行います。
■ その他には、ファイル名は [Tab] キーで補完できます。また、[↑][↓] キーで過去の
コマンド履歴の呼び出しが可能です。
In [4]: %run 01-square_error.py
Table of the coefficients
M=0 M=1 M=3 M=9
0 -0.012133 0.737922 0.005026 0.021570
1 NaN -1.500112 9.633393 -121.926645
2 NaN NaN -28.282723 2897.187668
3 NaN NaN 18.422900 -25036.071571
4 NaN NaN NaN 110826.637881
5 NaN NaN NaN -282565.729927
6 NaN NaN NaN 431648.816158
7 NaN NaN NaN -390194.283125
8 NaN NaN NaN 192486.163220
9 NaN NaN NaN -39940.969290
In [5]: exit
In [5]: %paste
■ クリップボードの内容をペーストして実行する
際は、「%paste」コマンドを実行します。
■ IPythonを終了する際は「exit」を入力します。](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-9-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
12
ソフトウェアエンジニアのための「機械学習理論」入門
NumPyの簡単な利用例
In [1]: import numpy as np
In [2]: a = np.array([[0,1,2],[3,4,5],[6,7,8]])
In [3]: b = np.array([[1,1,1],[2,2,2],[3,3,3]])
In [4]: a
Out[4]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In [5]: b
Out[5]:
array([[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
In [4]: a.T
Out[4]:
array([[0, 3, 6],
[1, 4, 7],
[2, 5, 8]])
In [7]: a*2
Out[7]:
array([[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16]])
In [8]: a+b
Out[8]:
array([[ 1, 2, 3],
[ 5, 6, 7],
[ 9, 10, 11]])
In [6]: np.dot(a,b)
Out[6]:
array([[ 8, 8, 8],
[26, 26, 26],
[44, 44, 44]])
In [15]: np.append(a,b,axis=0)
Out[15]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8],
[1, 1, 1],
[2, 2, 2],
[3, 3, 3]])
In [16]: np.append(a,b,axis=1)
Out[16]:
array([[0, 1, 2, 1, 1, 1],
[3, 4, 5, 2, 2, 2],
[6, 7, 8, 3, 3, 3]])
■ 次は、NumPyで行列の計算をする例です。
転置行列
スカラーとの演算は
各成分に適用
行列としての積は、
np.dot()関数を使用
行列成分の結合は、結合の
方向を axis オプションで
指定(0:縦、1:横)](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-12-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
13
ソフトウェアエンジニアのための「機械学習理論」入門
In [1]: df = DataFrame([[0,1],[2,3],[4,5]], columns=('x','y'))
In [2]: df
Out[2]:
x y
0 0 1
1 2 3
2 4 5
In [3]: df['x']
Out[3]:
0 0
1 2
2 4
Name: x, dtype: int64
In [4]: df.x
Out[4]:
0 0
1 2
2 4
Name: x, dtype: int64
In [5]: df[0:2]
Out[5]:
x y
0 0 1
1 2 3
pandasの簡単な利用例
■ 次は、pandasのデータフレームを使用する例です。
columns
index
columnsの取り出し
(Seriesオブジェクト)
スライス記法は
行の取り出しになる
In [6]: for index, line in df.iterrows():
....: print "index=%d" % index
....: print line
....:
index=0
x 0
y 1
Name: 0, dtype: int64
index=1
x 2
y 3
Name: 1, dtype: int64
index=2
x 4
y 5
Name: 2, dtype: int64
行単位の処理](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-13-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
16
ソフトウェアエンジニアのための「機械学習理論」入門
演習1:最小二乗法による回帰分析
■ スクリプト「02-square_error.py」を実行します。
- 最小二乗法による回帰分析を実施します。
■ 具体的な内容は、下記のBlogを参照してください。
- PRML 第1章の多項式フィッティングの例を再現
- http://enakai00.hatenablog.com/entry/2015/04/05/002239
■ スクリプトの下記の値を変えると、データ数(x軸上の観測点の数)を変更できます。
- データ数によって結果がどのように変わるか観察してください。
In [1]: %run 02-square_error.py
#------------#
# Parameters #
#------------#
N=10 # サンプルを取得する位置 x の個数](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-16-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
17
ソフトウェアエンジニアのための「機械学習理論」入門
演習2:最尤推定による回帰分析
■ スクリプト「03-maximum_likelihood.py」「03-ml_gauss.py」を実行します。
- 最尤推定による回帰分析と最大ログ尤度の計算、および、最尤推定による正規分布
の推定を行います。
■ 具体的な内容は、下記のBlogを参照してください。
- PRML 第1章の「最尤推定によるパラメータフィッティング」の解説
- http://enakai00.hatenablog.com/entry/2015/04/05/220817
■ 「03-loglikelihood.py」の下記の値を変えると、データ数を変更できます。
- データ数によって結果がどのように変わるか観察してください。
■ 「03-ml_gauss.py」を何度か実行して、得られたサンプルによって推定がどのように
変わるか観察してください。
In [1]: %run 03-maximum_likelihood.py
In [2]: %run 03-ml_gauss.py
#------------#
# Parameters #
#------------#
N=10 # サンプルを取得する位置 x の個数](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-17-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
18
ソフトウェアエンジニアのための「機械学習理論」入門
演習3:パーセプトロンによる二項分類
■ スクリプト「04-perceptron.py」を実行します。
- パーセプトロンによる二項分類を実施します。
■ 具体的な内容は、下記のBlogを参照してください。
- Perceptronのパラメータ変化を見るコード
- http://enakai00.hatenablog.com/entry/2015/04/12/201156
■ 分類用のデータは、2種類の2次元正規分布を用いてランダムに生成しています。下記の
パラメータでデータ数、中心座標、分散を変更できます。
- これらのパラメータを変更して、実行結果がどのように変わるか観察してください。
In [1]: %run 04-perceptron.py
N1 = 30 # クラス t=1 のデータ数
Mu1 = [0,0] # クラス t=1 の中心座標
N2 = 20 # クラス t=-1 のデータ数
Mu2 = [15,10] # クラス t=-1 の中心座標
Variances = [20,25] # 両クラス共通の分散(2種類の分散で計算を実施)](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-18-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
19
ソフトウェアエンジニアのための「機械学習理論」入門
演習4:ロジスティック回帰による二項分類
■ スクリプト「05-logstic_vs_perceptron.py」を実行します。
- ロジスティック回帰とパーセプトロンによる二項分類の結果を比較します。
■ 具体的な内容は、下記のBlogを参照してください。
- Logistic RegressionとPerceptronを比較するコード
- http://enakai00.hatenablog.com/entry/2015/04/11/235712
■ 何度かスクリプトを実行して、ロジスティック回帰とパーセプトロンの結果の違いを比
較してください。
In [1]: %run 05-logstic_vs_perceptron.py](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-19-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
20
ソフトウェアエンジニアのための「機械学習理論」入門
演習5:ロジスティック回帰のROC曲線
■ スクリプト「05-roc_curve.py」を実行します。
- ロジスティック回帰を実施して、その結果をROC曲線で表示します。
■ 具体的な内容は、下記のBlogを参照してください。
- ロジスティック回帰のROC曲線を描くコード
- http://enakai00.hatenablog.com/entry/2015/04/12/104837
■ 下記のパラメータでトレーニングセットの分散を変更できます。
- このパラメータを変更して、ROC曲線がどのように変わるか観察してください。
In [1]: %run 05-roc_curve.py
#------------#
# Parameters #
#------------#
Variances = [50,150] # 両クラス共通の分散(2種類の分散で計算を実施)](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-20-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
21
ソフトウェアエンジニアのための「機械学習理論」入門
演習6:k平均法による画像変換
■ スクリプト「06-k_means.py」を実行します。
- 画像ファイル「photo.jpg」を読み込んで、k平均法で減色処理をしたファイル
「output*.bmp」(*は色数)を出力します。
■ 具体的な内容は、下記のBlogを参照してください。
- k-means法で画像を減色するサンプルコード
- http://enakai00.hatenablog.com/entry/2015/04/14/181305
■ 下記のパラメータで減色後の色数を変更できます。
- このパラメータを変更して、さまざまな減色処理を試してください。
- 自分の好きな画像ファイルを用いて、減色処理を行ってみてください。
In [1]: %run 06-k_means.py
#------------#
# Parameters #
#------------#
Colors = [2, 3, 5, 16] # 減色後の色数(任意の個数の色数を指定できます)](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-21-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
22
ソフトウェアエンジニアのための「機械学習理論」入門
演習7:混合ベルヌーイ分布による手書き文字分類
■ スクリプト「07-prep_data.py」を実行して、トレーニングセット用のデータファイル
「sample-images.txt」を用意します。
- データファイル「sample-images.txt」の他に、サンプルとして、用意したデータの
先頭10文字が可読性のある形式で「samples.txt」に書きだされます。
■ 下記のパラメータで抽出文字の種類と合計の文字数を変更できます。
In [1]: %run 07-prep_data.py
#------------#
# Parameters #
#------------#
Num = 600 # 抽出する文字数
Chars = '[036]' # 抽出する数字(任意の個数の数字を指定可能)](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-22-2048.jpg)
![Copyright (C) 2015 National Institute of Informatics, All rights reserved.
23
ソフトウェアエンジニアのための「機械学習理論」入門
演習7(続き)
■ スクリプト「07-mix_em.py」を実行します。
- 混合ベルヌーイ分布を用いたEM法により、手書き文字の分類が行われます。
■ 具体的な内容は、下記のBlogを参照してください。
- EM法による手書き文字の分類
- http://enakai00.hatenablog.com/entry/2015/04/18/220126
■ 下記のパラメータで分類する文字数と反復回数を変更できます。
- さまざまな文字の組み合わせを異なる文字数で分類して、その結果を観察してくださ
い。分類結果は、ランダムに決まる初期値に依存するので、同じ条件でも複数回実行
すると、結果が変わることがあります。
In [1]: %run 07-mix_em.py
#------------#
# Parameters #
#------------#
K = 3 # 分類する文字数
N = 10 # 反復回数](https://image.slidesharecdn.com/machinelearningtheroyhandson20150420-150424000955-conversion-gate02/75/slide-23-2048.jpg)






































































