Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Ryuji Tamagawa
2,764 views
データベース勉強会 In 広島 mongodb
MongoDBの概要と、特にレプリカセットの耐障害性の話です。
Software
◦
Read more
12
Save
Share
Embed
Embed presentation
Download
Downloaded 12 times
1
/ 44
2
/ 44
3
/ 44
4
/ 44
5
/ 44
6
/ 44
7
/ 44
8
/ 44
9
/ 44
10
/ 44
11
/ 44
12
/ 44
13
/ 44
14
/ 44
15
/ 44
16
/ 44
17
/ 44
18
/ 44
19
/ 44
20
/ 44
21
/ 44
22
/ 44
23
/ 44
24
/ 44
25
/ 44
26
/ 44
27
/ 44
28
/ 44
29
/ 44
30
/ 44
31
/ 44
32
/ 44
33
/ 44
34
/ 44
35
/ 44
36
/ 44
37
/ 44
38
/ 44
39
/ 44
40
/ 44
41
/ 44
42
/ 44
43
/ 44
44
/ 44
More Related Content
PDF
RDB経験者に送るMongoDBの勘所(db tech showcase tokyo 2013)
by
Ryuji Tamagawa
PPTX
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
PDF
DB tech showcase: 噂のMongoDBその用途は?
by
Hiroaki Kubota
PPTX
MongoDBの監視
by
Tetsutaro Watanabe
PDF
初めてのMongo db
by
Ryuji Tamagawa
PPTX
Mongo db勉強会の補足
by
CROOZ, inc.
PDF
WiredTigerストレージエンジン楽しい
by
Akihiro Kuwano
PDF
Introduction to MongoDB
by
moai kids
RDB経験者に送るMongoDBの勘所(db tech showcase tokyo 2013)
by
Ryuji Tamagawa
初心者向けMongoDBのキホン!
by
Tetsutaro Watanabe
DB tech showcase: 噂のMongoDBその用途は?
by
Hiroaki Kubota
MongoDBの監視
by
Tetsutaro Watanabe
初めてのMongo db
by
Ryuji Tamagawa
Mongo db勉強会の補足
by
CROOZ, inc.
WiredTigerストレージエンジン楽しい
by
Akihiro Kuwano
Introduction to MongoDB
by
moai kids
What's hot
PPT
[大図解]ピグライフはこう動いている
by
Akihiro Kuwano
PDF
大規模ソーシャルゲーム開発から学んだPHP&MySQL実践テクニック
by
infinite_loop
PDF
PHP+MySQLを使ったスケーラブルなソーシャルゲーム開発
by
infinite_loop
PDF
さいきんの InnoDB Adaptive Flushing (仮)
by
Takanori Sejima
PDF
サーバーのおしごと
by
Yugo Shimizu
PPTX
Node.js×mongo dbで3年間サービス運用してみた話
by
leverages_event
PDF
サーバサイドNodeの使い道
by
pospome
PPT
ザ・ドキュメント~うまくいかないNoSQL~
by
Akihiro Kuwano
PDF
サーバー未経験者がソーシャルゲームを通して知ったサーバーの事
by
Manabu Koga
PDF
Node js 入門
by
Satoshi Takami
PPTX
AngularJS2でつまづいたこと
by
Takehiro Takahashi
PPT
mongoDB: OSC Tokyo2010 spring
by
ichikaway
PDF
Db tech showcase2015 how to replicate between clusters
by
Hiroaki Kubota
PDF
Node.jsでサーバプログラマ デビューしよう
by
Yuusuke Takeuchi
PDF
Hello, Node.js
by
Shin Sekaryo
PPT
Node.js で Web アプリ開発
by
Tatsumi Naganuma
PPTX
MongoDB World 2014に行ってきた!
by
Tetsutaro Watanabe
PDF
Node.js を選ぶとき 選ばないとき
by
Ryunosuke SATO
PDF
MongoDB very basic (Japanese) / MongoDB基礎の基礎
by
Naruhiko Ogasawara
PDF
大阪Node学園 七時限目 「ゼロからはじめるnode.js」
by
Shunsuke Watanabe
[大図解]ピグライフはこう動いている
by
Akihiro Kuwano
大規模ソーシャルゲーム開発から学んだPHP&MySQL実践テクニック
by
infinite_loop
PHP+MySQLを使ったスケーラブルなソーシャルゲーム開発
by
infinite_loop
さいきんの InnoDB Adaptive Flushing (仮)
by
Takanori Sejima
サーバーのおしごと
by
Yugo Shimizu
Node.js×mongo dbで3年間サービス運用してみた話
by
leverages_event
サーバサイドNodeの使い道
by
pospome
ザ・ドキュメント~うまくいかないNoSQL~
by
Akihiro Kuwano
サーバー未経験者がソーシャルゲームを通して知ったサーバーの事
by
Manabu Koga
Node js 入門
by
Satoshi Takami
AngularJS2でつまづいたこと
by
Takehiro Takahashi
mongoDB: OSC Tokyo2010 spring
by
ichikaway
Db tech showcase2015 how to replicate between clusters
by
Hiroaki Kubota
Node.jsでサーバプログラマ デビューしよう
by
Yuusuke Takeuchi
Hello, Node.js
by
Shin Sekaryo
Node.js で Web アプリ開発
by
Tatsumi Naganuma
MongoDB World 2014に行ってきた!
by
Tetsutaro Watanabe
Node.js を選ぶとき 選ばないとき
by
Ryunosuke SATO
MongoDB very basic (Japanese) / MongoDB基礎の基礎
by
Naruhiko Ogasawara
大阪Node学園 七時限目 「ゼロからはじめるnode.js」
by
Shunsuke Watanabe
Similar to データベース勉強会 In 広島 mongodb
PDF
大規模化するピグライフを支えるインフラ ~MongoDBとChefについて~ (前編)
by
Akihiro Kuwano
PDF
MongoDB勉強会資料
by
Hiromune Shishido
PDF
MongoDBざっくり解説
by
知教 本間
PDF
業務システムにおけるMongoDB活用法
by
Yoshitaka Mori
PDF
MongoDBのアレをアレする
by
Akihiro Kuwano
PPTX
比べてみよう リレーショナル vs ドキュメント.pptx
by
MariMurotani
PPT
MongoDB
by
あしたのオープンソース研究所
PPTX
Mongo dbを知ろう
by
CROOZ, inc.
PDF
MongoDB概要:金融業界でのMongoDB
by
ippei_suzuki
PDF
CyberAgentにおけるMongoDB
by
Akihiro Kuwano
PDF
Mongo dbを知ろう devlove関西
by
Ryuji Tamagawa
PPTX
Mongo db world 2018
by
Creationline,inc.
PPT
Mongodb
by
Satoru Mikami
PDF
CasualなMongoDBのサービス運用Tips
by
Naoki Sega
DOC
20110302 Mongo Tokyo
by
Kenichi Masuda
DOC
20110301 Mongo Tokyo
by
Kenichi Masuda
PDF
はじめてのMongoDB
by
Keisuke Izumiya
PDF
20120831 mongoid
by
Takeshi AKIMA
PDF
何を基準に選定すべきなのか!? 〜ビッグデータ×IoT×AI時代のデータベースのアーキテクチャとメカニズムの比較〜
by
griddb
PDF
Mongodb 紹介
by
Ryo Matsumura
大規模化するピグライフを支えるインフラ ~MongoDBとChefについて~ (前編)
by
Akihiro Kuwano
MongoDB勉強会資料
by
Hiromune Shishido
MongoDBざっくり解説
by
知教 本間
業務システムにおけるMongoDB活用法
by
Yoshitaka Mori
MongoDBのアレをアレする
by
Akihiro Kuwano
比べてみよう リレーショナル vs ドキュメント.pptx
by
MariMurotani
MongoDB
by
あしたのオープンソース研究所
Mongo dbを知ろう
by
CROOZ, inc.
MongoDB概要:金融業界でのMongoDB
by
ippei_suzuki
CyberAgentにおけるMongoDB
by
Akihiro Kuwano
Mongo dbを知ろう devlove関西
by
Ryuji Tamagawa
Mongo db world 2018
by
Creationline,inc.
Mongodb
by
Satoru Mikami
CasualなMongoDBのサービス運用Tips
by
Naoki Sega
20110302 Mongo Tokyo
by
Kenichi Masuda
20110301 Mongo Tokyo
by
Kenichi Masuda
はじめてのMongoDB
by
Keisuke Izumiya
20120831 mongoid
by
Takeshi AKIMA
何を基準に選定すべきなのか!? 〜ビッグデータ×IoT×AI時代のデータベースのアーキテクチャとメカニズムの比較〜
by
griddb
Mongodb 紹介
by
Ryo Matsumura
More from Ryuji Tamagawa
PDF
Apache Sparkの紹介
by
Ryuji Tamagawa
PPTX
hbstudy 74 Site Reliability Engineering
by
Ryuji Tamagawa
PDF
20171012 found IT #9 PySparkの勘所
by
Ryuji Tamagawa
PDF
ヘルシープログラマ・翻訳と実践
by
Ryuji Tamagawa
PDF
BigQueryの課金、節約しませんか
by
Ryuji Tamagawa
PDF
Google Big Query
by
Ryuji Tamagawa
PDF
20160127三木会 RDB経験者のためのspark
by
Ryuji Tamagawa
PDF
丸の内MongoDB勉強会#20LT 2.8のストレージエンジン動かしてみました
by
Ryuji Tamagawa
PDF
足を地に着け落ち着いて考える
by
Ryuji Tamagawa
PDF
20151205 Japan.R SparkRとParquet
by
Ryuji Tamagawa
PDF
Performant data processing with PySpark, SparkR and DataFrame API
by
Ryuji Tamagawa
PDF
20170927 pydata tokyo データサイエンスな皆様に送る分散処理の基礎の基礎、そしてPySparkの勘所
by
Ryuji Tamagawa
PDF
20161215 python pandas-spark四方山話
by
Ryuji Tamagawa
PDF
PySparkの勘所(20170630 sapporo db analytics showcase)
by
Ryuji Tamagawa
PDF
You might be paying too much for BigQuery
by
Ryuji Tamagawa
PDF
20161004 データ処理のプラットフォームとしてのpythonとpandas 東京
by
Ryuji Tamagawa
PDF
20170210 sapporotechbar7
by
Ryuji Tamagawa
PDF
Google BigQueryについて 紹介と推測
by
Ryuji Tamagawa
PDF
20160708 データ処理のプラットフォームとしてのpython 札幌
by
Ryuji Tamagawa
PDF
lessons learned from talking at rakuten technology conference
by
Ryuji Tamagawa
Apache Sparkの紹介
by
Ryuji Tamagawa
hbstudy 74 Site Reliability Engineering
by
Ryuji Tamagawa
20171012 found IT #9 PySparkの勘所
by
Ryuji Tamagawa
ヘルシープログラマ・翻訳と実践
by
Ryuji Tamagawa
BigQueryの課金、節約しませんか
by
Ryuji Tamagawa
Google Big Query
by
Ryuji Tamagawa
20160127三木会 RDB経験者のためのspark
by
Ryuji Tamagawa
丸の内MongoDB勉強会#20LT 2.8のストレージエンジン動かしてみました
by
Ryuji Tamagawa
足を地に着け落ち着いて考える
by
Ryuji Tamagawa
20151205 Japan.R SparkRとParquet
by
Ryuji Tamagawa
Performant data processing with PySpark, SparkR and DataFrame API
by
Ryuji Tamagawa
20170927 pydata tokyo データサイエンスな皆様に送る分散処理の基礎の基礎、そしてPySparkの勘所
by
Ryuji Tamagawa
20161215 python pandas-spark四方山話
by
Ryuji Tamagawa
PySparkの勘所(20170630 sapporo db analytics showcase)
by
Ryuji Tamagawa
You might be paying too much for BigQuery
by
Ryuji Tamagawa
20161004 データ処理のプラットフォームとしてのpythonとpandas 東京
by
Ryuji Tamagawa
20170210 sapporotechbar7
by
Ryuji Tamagawa
Google BigQueryについて 紹介と推測
by
Ryuji Tamagawa
20160708 データ処理のプラットフォームとしてのpython 札幌
by
Ryuji Tamagawa
lessons learned from talking at rakuten technology conference
by
Ryuji Tamagawa
データベース勉強会 In 広島 mongodb
1.
MongoDBの特徴と トラブルシューティング @第5回
中国地方DB勉強会 in 広島 ! 玉川竜司@大阪
2.
自己紹介 • 玉川竜司
• FB: Ryuji Tamagawa • Twitter: @tamagawa_ryuji • 本業ソフト開発(Sky株式会社) • 兼業翻訳者(ほぼオライリー)
3.
What’s New &
Next
4.
今日のお題は MongoDB
5.
MongoDBのいいところ • 一言で言うなら「お手軽」 - いい意味で
• Webアプリケーションで求められる機能が手っ取り早く使える • 多目的の高性能「オートマ車」 • インストーラやパッケージですぐ動きます • セカンダリインデックスやクエリオプティマイザがある • 多くの言語で、仕様がある程度統一されているドライバが利用可能
6.
MEANスタック • JSONでバックエンドからフロントエンドまで統一
• MongoDB、Express、AngularJS、Node.js • 昨日のOSCでも取りあげられていたようです
7.
エコシステムの形成 • 世界的に見れば、NoSQLデータベースとしては最もメジャーな存在になっ
てきた → 周辺が充実してきている • クラウド上で実績多数。MongoHQなど、as a serviceでも提供されてい る • GUIツールも増えてきました • MMS(http://www.mongodb.com/mongodb-management-service) - バックアップ、運用管理などを行ってくれる本家のクラウドサービス
8.
ただし • 集計は(今のところ)ちょっと苦手 - とはいえ改善中
• (ほんとの)ビッグデータはちょっと難しいかも • 基本的に、オンメモリでいけるかどうかが問題 • そういえば、でかいメモリのインスタンス、AWSでもAzureで もさくらでも増えましたね・・・
9.
RDBとの違い • 物理構造の違い
• 論理構造の違い • トレードオフの柔軟性 • レプリカセット • シャーディング
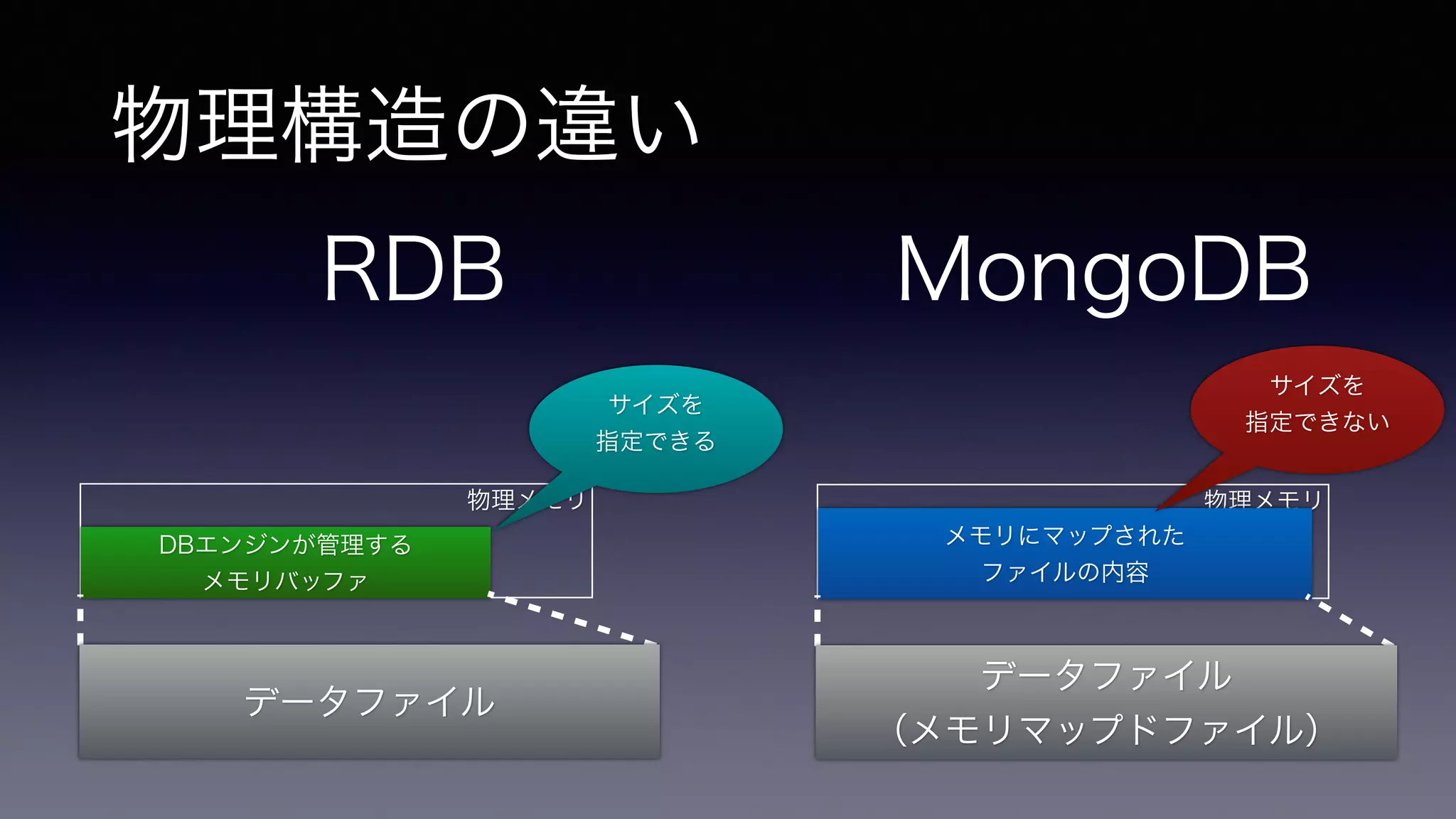
10.
物理構造の違い RDB MongoDB
物理メモリ物理メモリ DBエンジンが管理する メモリバッファ サイズを 指定できる データファイル メモリにマップされた ファイルの内容 サイズを 指定できない データファイル (メモリマップドファイル)
11.
物理構造の違い(2) • とにかく、「ホット」なデータが物理メモリに収まるかが肝心
• RDBほど細かなメモリのチューニングはできない • データが大きいなら、RAMを増やすか、シャーディングでスケール アウト
12.
論理構造の違い RDB MongoDB
{ _id: new ObjectId(""), slug: "gardening-tools", ancestors: [{ name: "Home", _id: new ObjectId(""), slug: "home" }, { name: "Outdoors", _id: new ObjectId(“"), slug: "outdoors" } ], }
13.
論理構造の違い(2) • スキーマの自由度は高い(特に変更に強い)
• ドキュメントを超えたアトミック性はない • 設計上のトレードオフが生じる • 一つのドキュメントで閉じない場合はIDで参照 • そうなると、処理をプログラムで書く必要が出てくる
14.
トレードオフの柔軟性 RDB MongoDB
書いたら 必ず 永続化 書き込み結果は 必ず確認 書き込み保証 する?しない? しなけりゃ高速 WAL使う? いくつのレプリ カへ書けたら成功 したことにする?
15.
トレードオフの柔軟性(2) • 書き込みの確実性とパフォーマンスはトレードオフ
• 大量のログの記録などでは、多少こぼれるリスクを抱えてもコストダウ ンしたいこともある • 逆に、データセンター間で複製できていることを保証したいこともある • 書き込み保証(Write Concern)、WAL、レプリカへの書き込み、タ ギングなどで、多彩な調整が可能
16.
レプリカセットとシャーディングについて • これらについては、「技術的には」RDBとの対立概念ではない
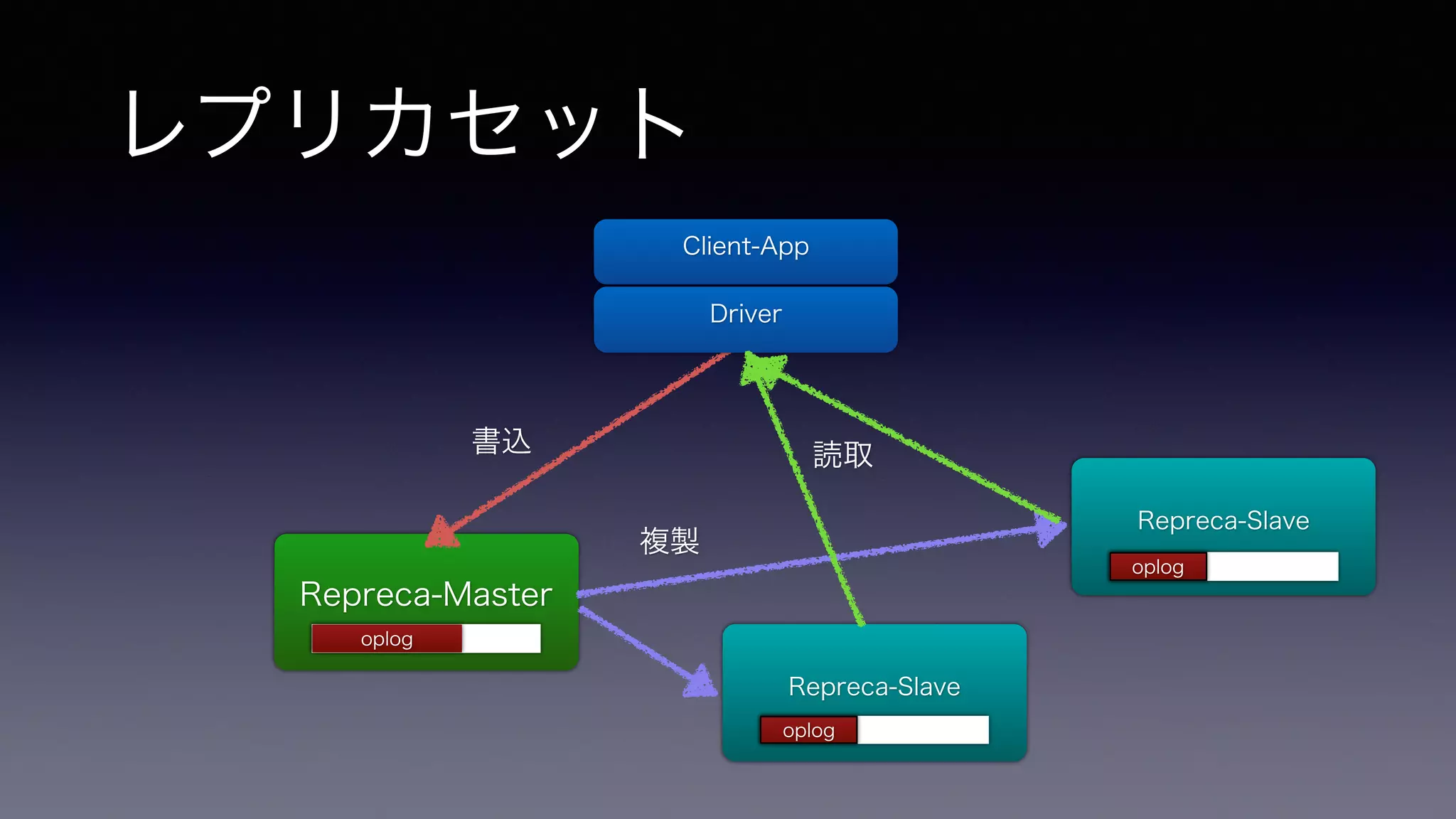
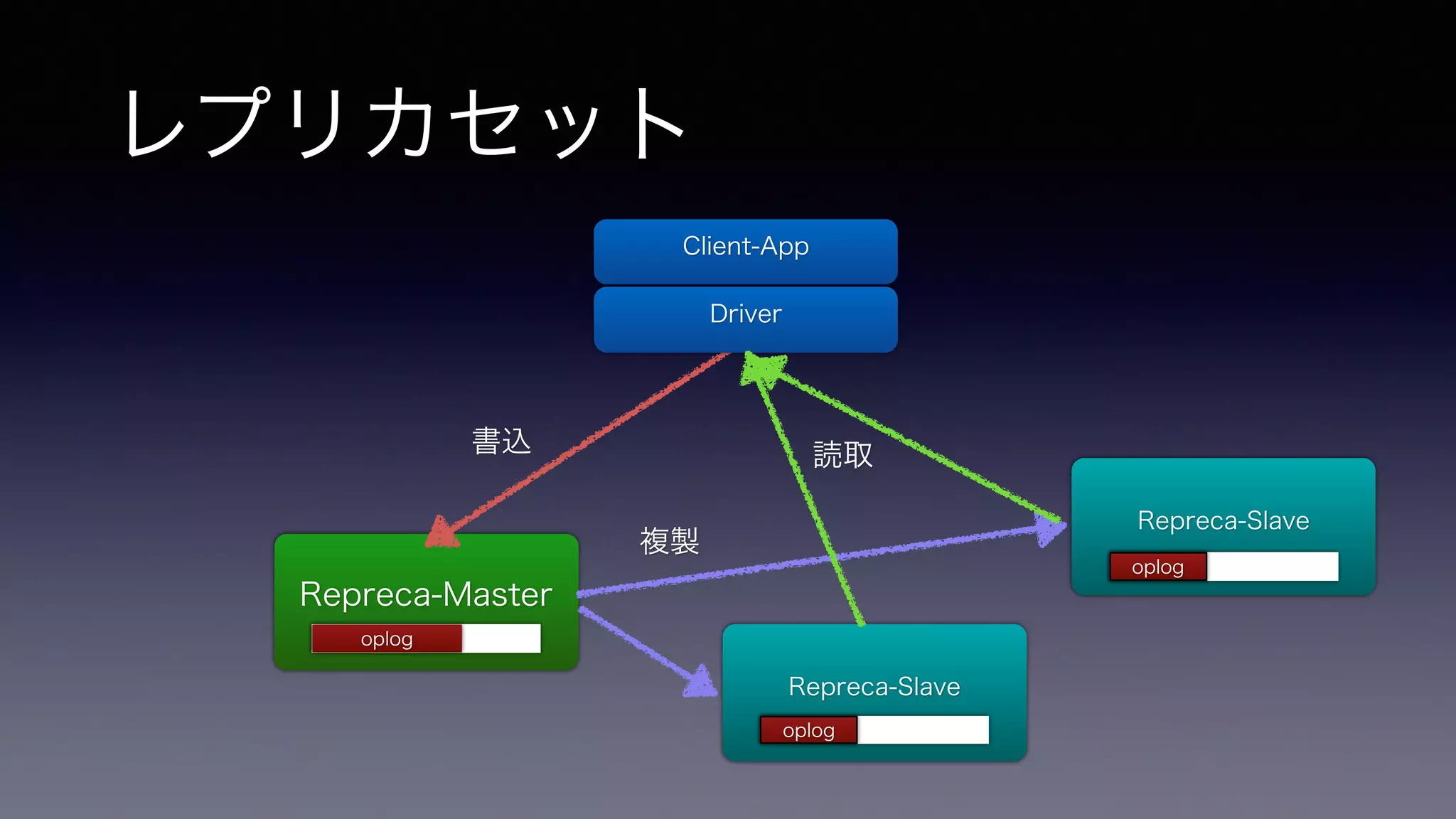
• ただし、商用RDBではコストが跳ね上がる(ですよね?)機能 • MongoDBでは最初から組み込まれて、非常にお手軽 & 便利 • 大まかには • 読み込みのパフォーマンスと耐障害性を向上させるのがレプリカセット • 書き込みのパフォーマンスを向上させるのがシャーディング
17.
レプリカセット Repreca-Master Client-App
Driver Repreca-Slave Repreca-Slave 書込 複製 読取 oploogplog oplog oplog
18.
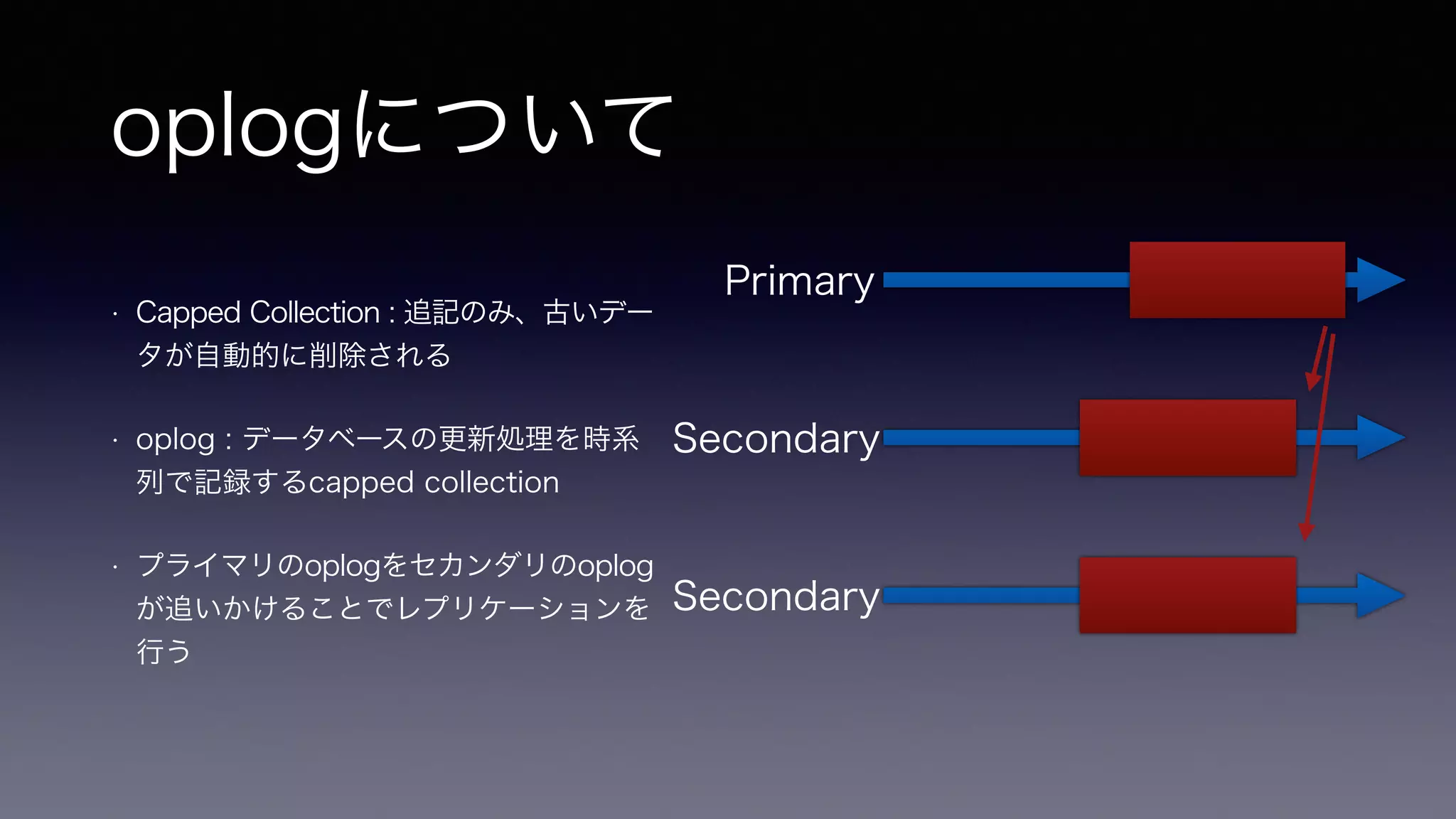
oplogについて • Capped
Collection : 追記のみ、古いデー タが自動的に削除される • oplog : データベースの更新処理を時系 列で記録するcapped collection • プライマリのoplogをセカンダリのoplog が追いかけることでレプリケーションを 行う Primary Secondary Secondary
19.
レプリカセット Repreca-Master Client-App
Driver Repreca-Slave Repreca-Slave 書込 複製 読取 oploogplog oplog oplog
20.
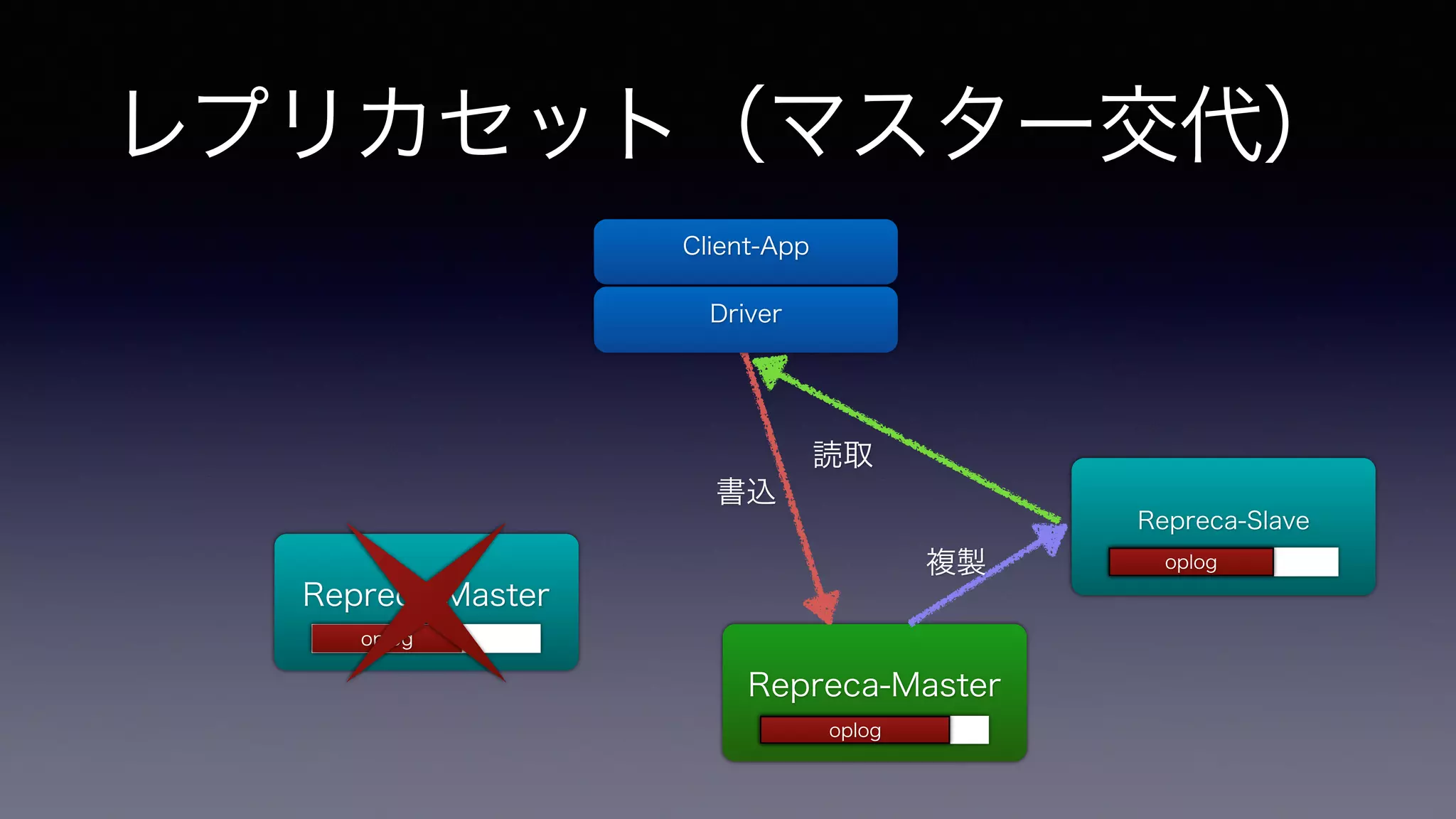
レプリカセット(マスター交代) Repreca-Master Repreca-Master
Repreca-Slave 書込 複製 Client-App Driver 読取 oploogplog opolopglog oploogplog
21.
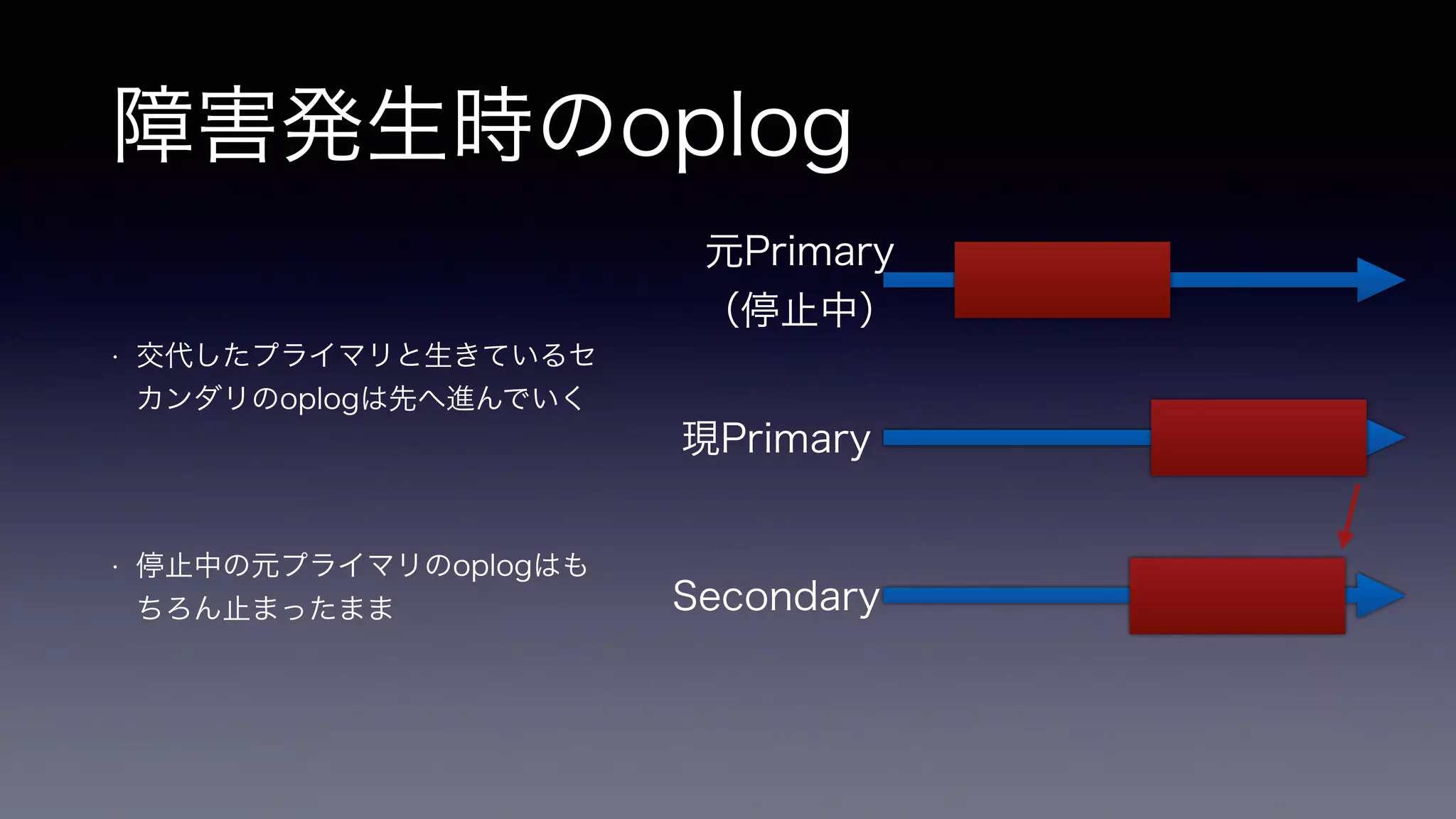
障害発生時のoplog • 交代したプライマリと生きているセ
カンダリのoplogは先へ進んでいく ! • 停止中の元プライマリのoplogはも ちろん止まったまま 元Primary (停止中) 現Primary Secondary
22.
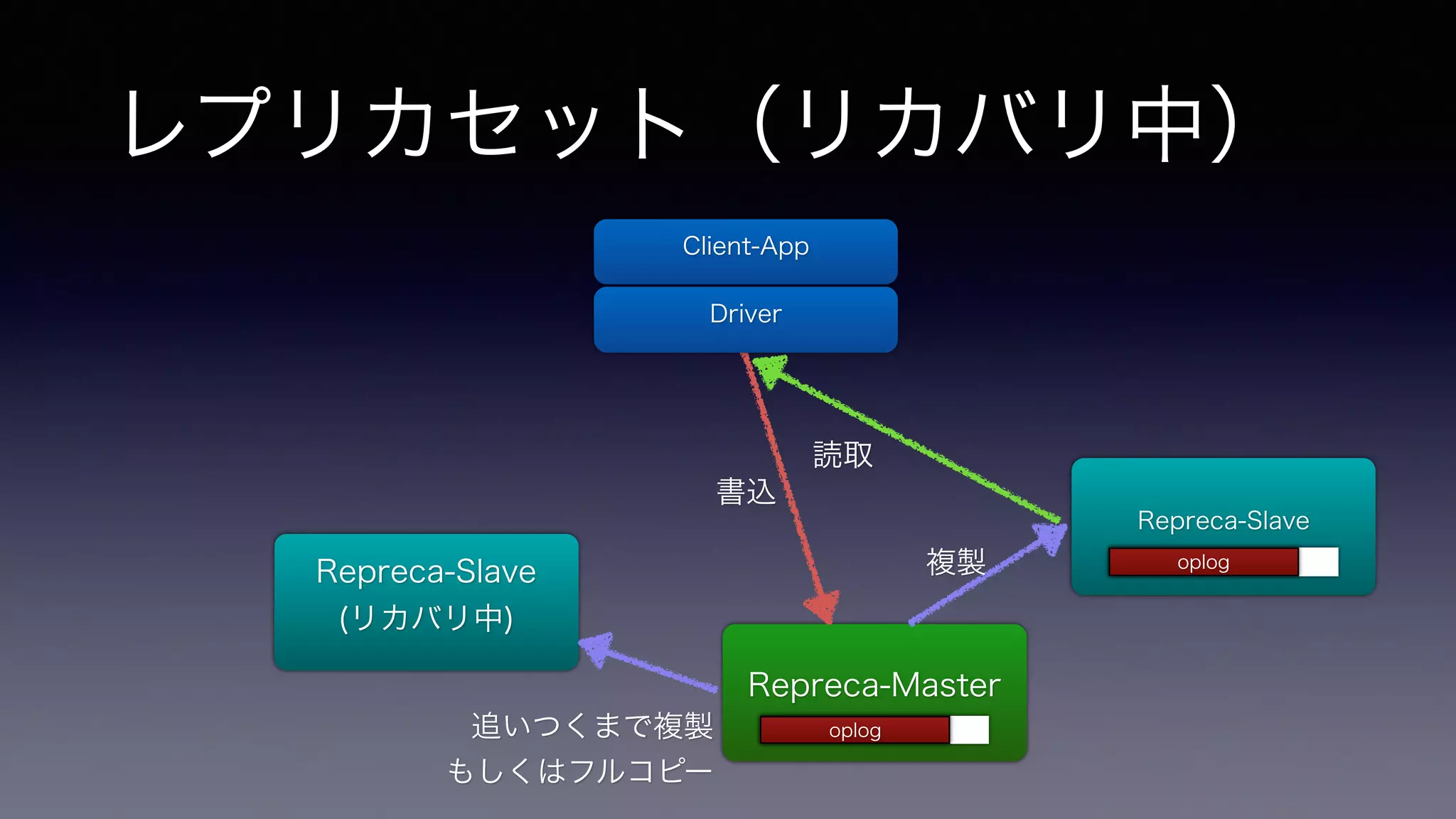
レプリカセット(リカバリ中) Repreca-Slave (リカバリ中)
Repreca-Master Repreca-Slave 書込 複製 Client-App Driver 読取 ! 追いつくまで複製 もしくはフルコピー opolopglog opolopglog
23.
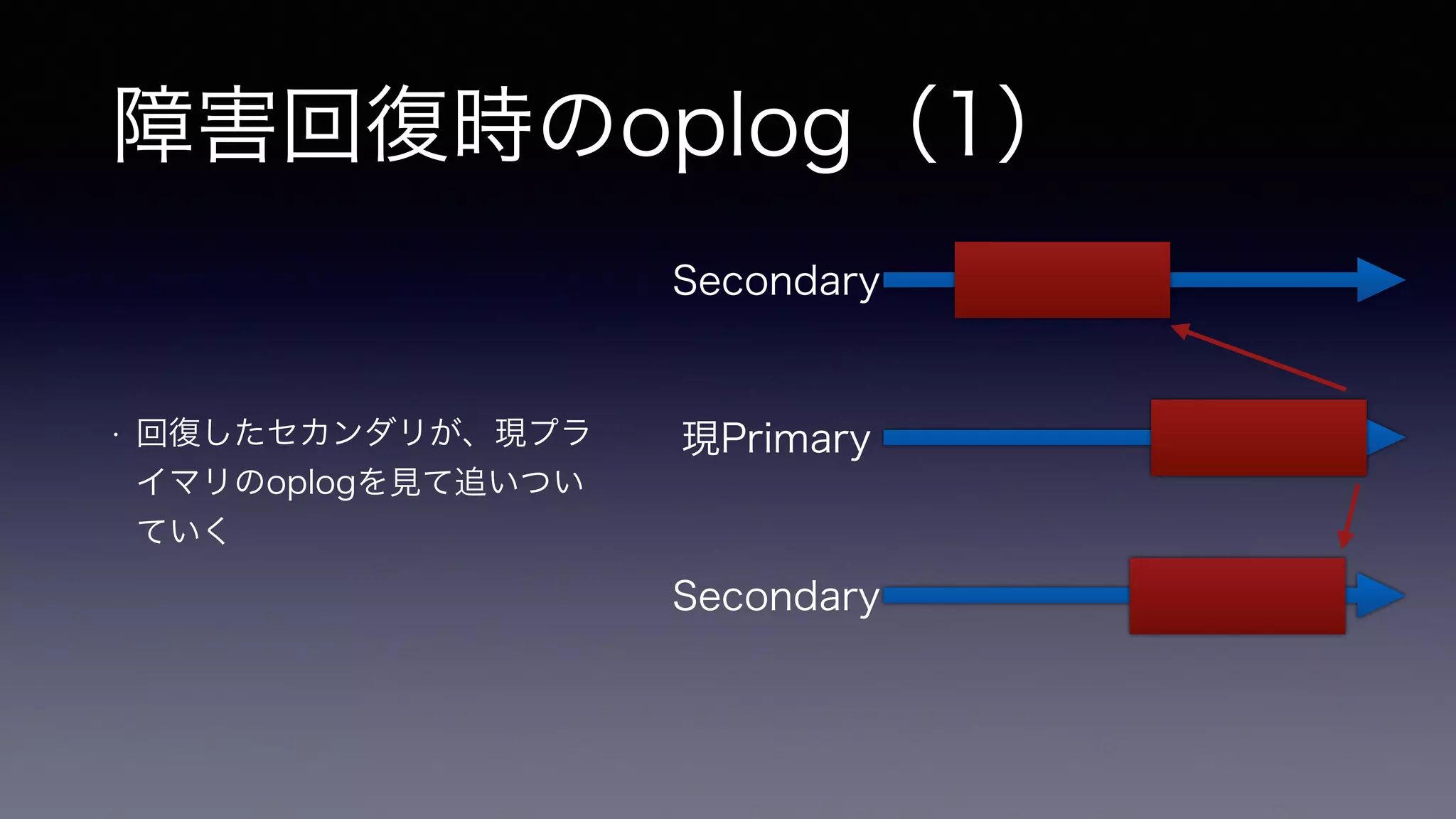
障害回復時のoplog(1) • 回復したセカンダリが、現プラ
イマリのoplogを見て追いつい ていく Secondary 現Primary Secondary
24.
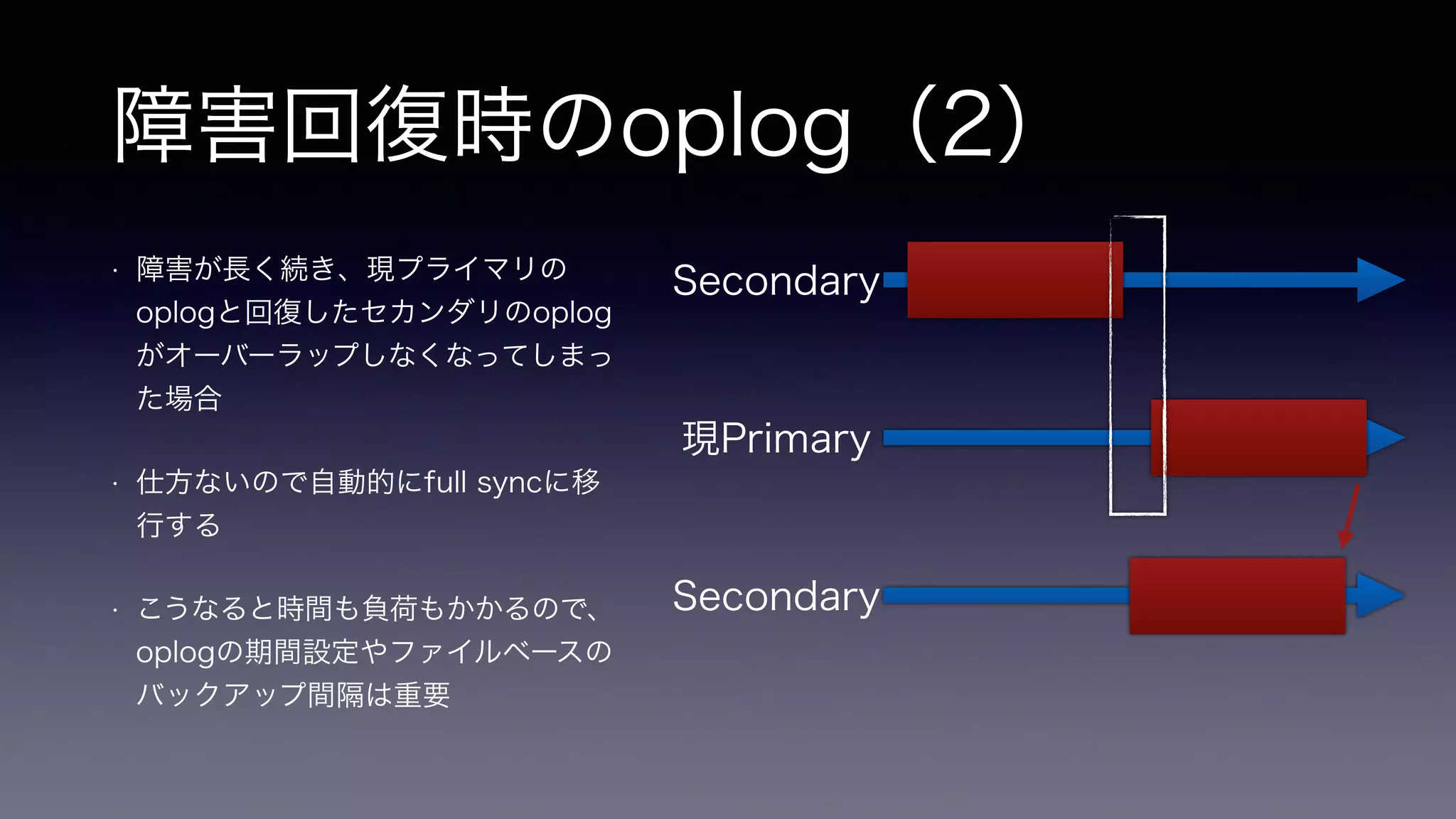
障害回復時のoplog(2) • 障害が長く続き、現プライマリの
oplogと回復したセカンダリのoplog がオーバーラップしなくなってしまっ た場合 • 仕方ないので自動的にfull syncに移 行する • こうなると時間も負荷もかかるので、 oplogの期間設定やファイルベースの バックアップ間隔は重要 Secondary 現Primary Secondary
25.
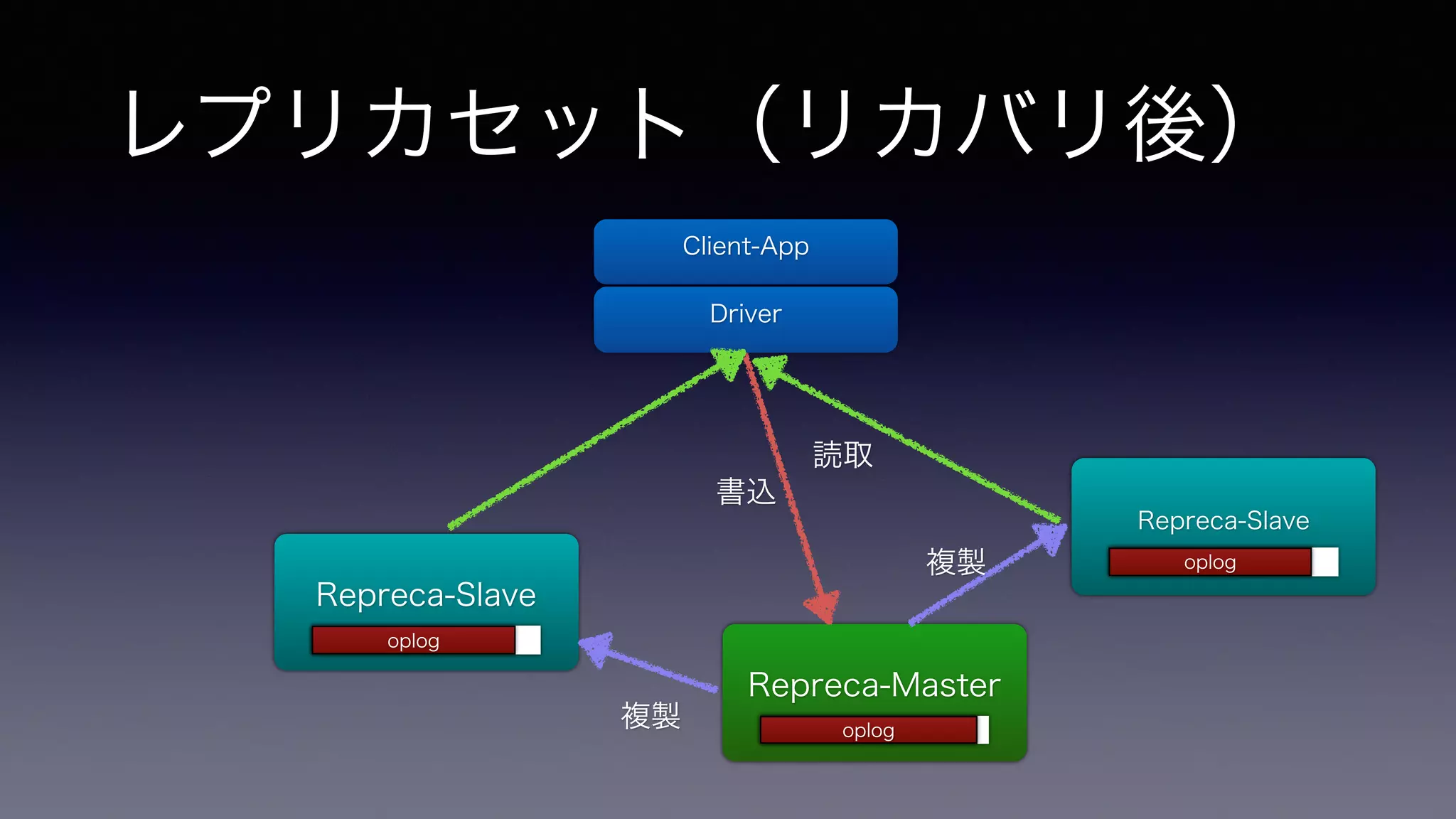
レプリカセット(リカバリ後) Repreca-Slave Repreca-Master
Repreca-Slave 書込 複製 Client-App Driver 読取 ! 複製oopplologg opolpolgog opolpolgog
26.
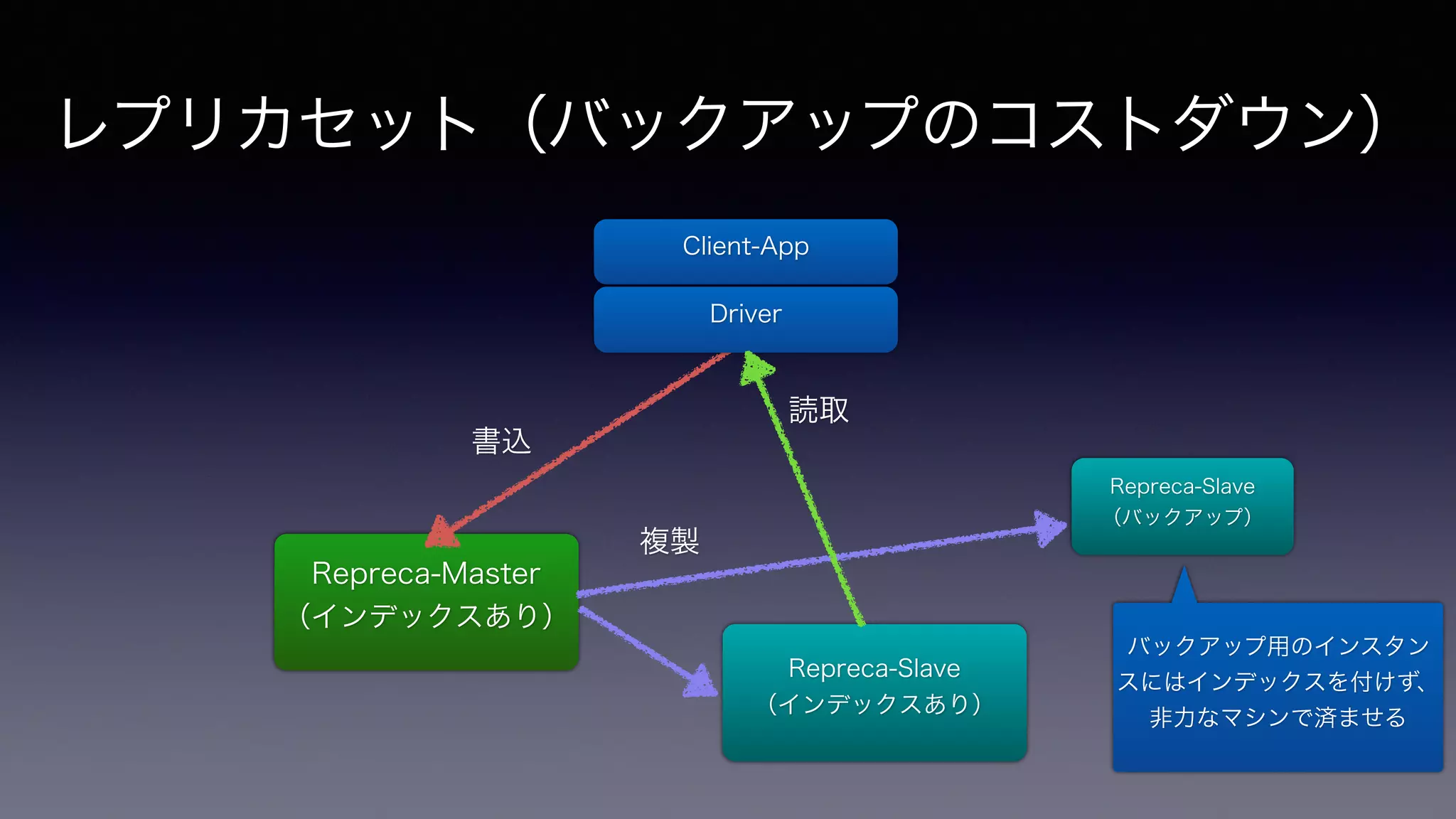
レプリカセット(バックアップのコストダウン) Repreca-Master (インデックスあり)
Client-App Driver Repreca-Slave (インデックスあり) Repreca-Slave (バックアップ) 書込 複製 読取 バックアップ用のインスタン スにはインデックスを付けず、 非力なマシンで済ませる
27.
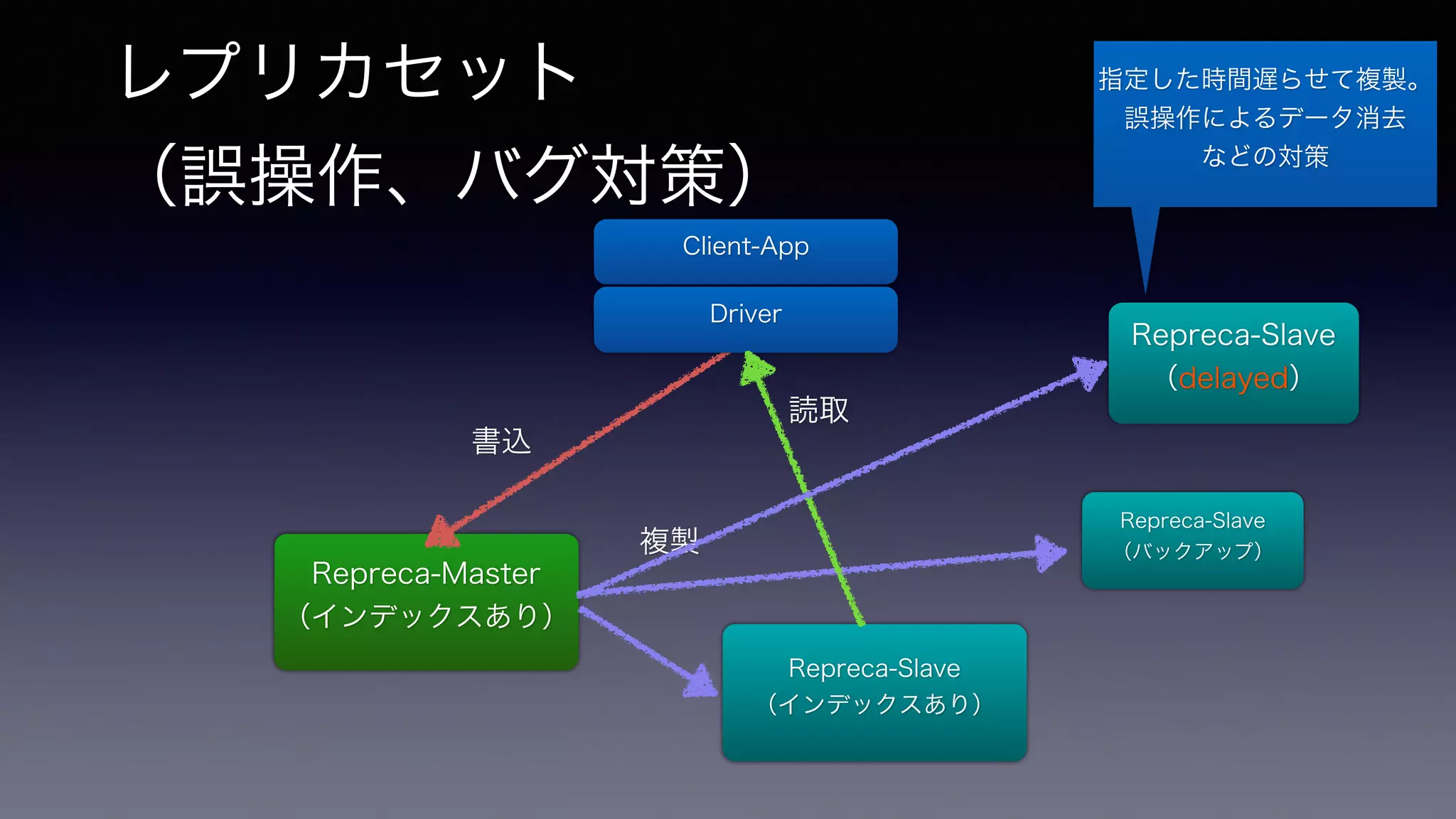
レプリカセット (誤操作、バグ対策) Repreca-Master
(インデックスあり) Client-App Driver Repreca-Slave (インデックスあり) 指定した時間遅らせて複製。 誤操作によるデータ消去 などの対策 Repreca-Slave (バックアップ) 書込 複製 読取 Repreca-Slave (delayed)
28.
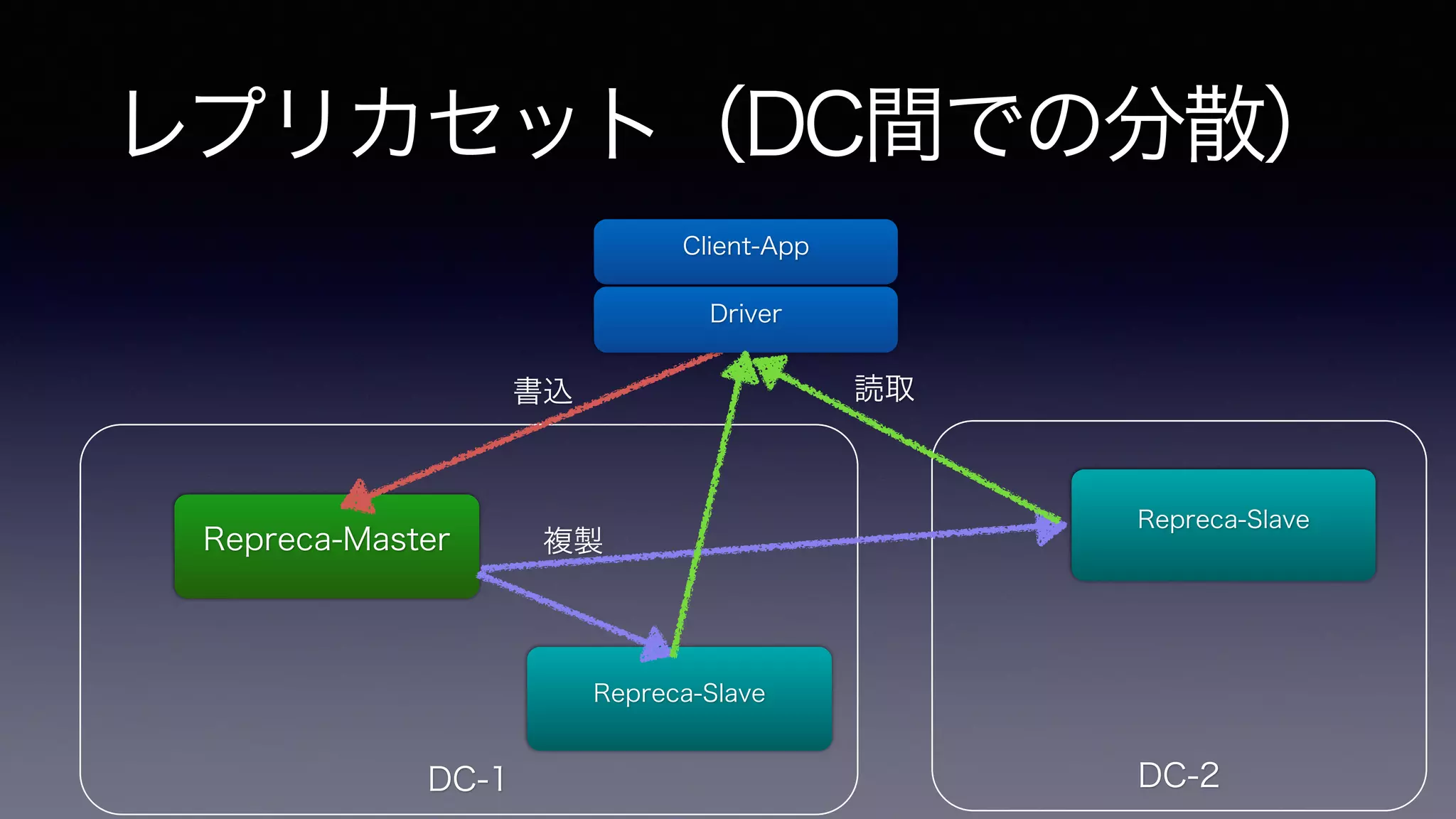
レプリカセット(DC間での分散) Repreca-Master 複製
Client-App Driver Repreca-Slave Repreca-Slave 書込 読取 DC-1 DC-2
29.
レプリカセットのまとめ • 読み取り負荷の分散
• 耐障害性 • 自動フェイルオーバー & リカバリ • 多彩なトレードオフ
30.
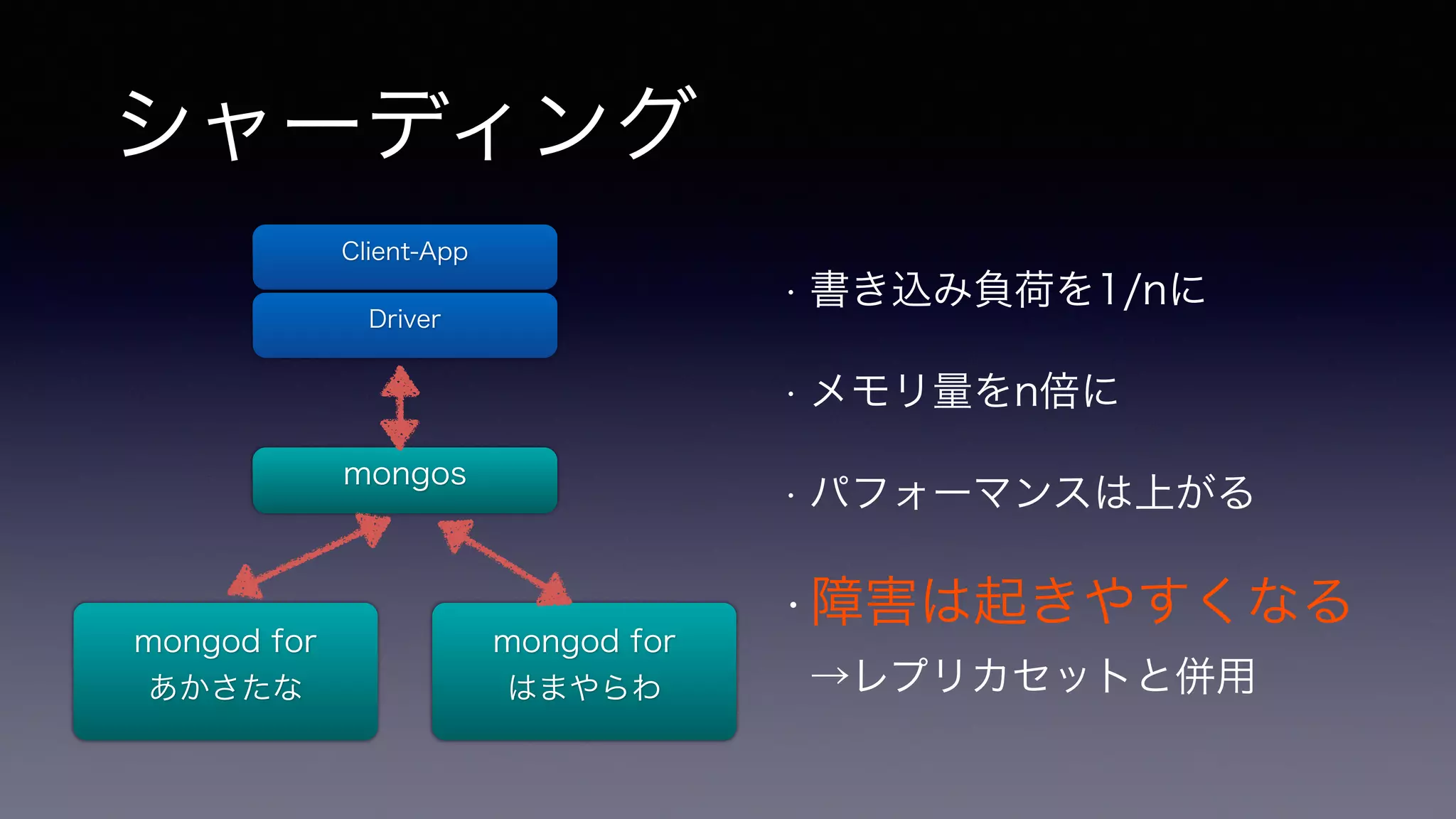
シャーディング • 書き込み負荷を1/nに
• メモリ量をn倍に • パフォーマンスは上がる •障害は起きやすくなる →レプリカセットと併用 Client-App Driver mongos mongod for あかさたな mongod for はまやらわ
31.
やっと バックアップとリストアの話 注)今回、ユーザー認証とかロールの話は、
時間ないのであえてすっ飛ばします
32.
ここ参照 • P.288~
• 基本的になるのは2つの方法 • データベースファイル+ジャーナ ルファイルを直接バックアップ・ リストア • ツールを使ってダンプ・リストア
33.
特徴的なこと • そもそもトランザクションが(ほとんど)ないので、
大きなトランザクションのロールフォワードを考える 必要がない→楽ちん(実はアプリとのトレードオフな わけですが) • レプリカセットは重要
34.
公式ドキュメントのシナリオ • ファイルシステムのスナップショットによるバックアップとリストア
• バックアップからのレプリカセットのリストア • MongoDBのツールを使ったバックアップとリストア • シャードクラスタのバックアップとリストア • 予想外のシャットダウンからのデータリカバリ
35.
ファイルシステムのスナップショットに よるバックアップとリストア •
普通にデータベースファイルをバックアップ/リストアするのと同じ。 • ただし、OSのスナップショット機能を前提として考えた方がよさそう • メインのデータがあるディスクでジャーナリングしている場合、わりと単純 • ジャーナリングをしていない場合、あるいはジャーナルが別ディスクの場合 • db.fsyncLock()でファイルの整合性を保障(ただしバグっているらしい…) • レプリカセットのセカンダリを使うという手もある
36.
バックアップからのレプリカセットのリストア • 想定されるシナリオ:
• 初期データセットの実働環境のレプリカセットへの展開 • バックアップデータセットからのレプリカセット再構築 • まずレプリカセットのプライマリにバックアップデータをリストア • データが少なければ、そこから空のセカンダリへ同期 • データが多ければ、セカンダリにセカンダリのバックアップをリストアして同期
37.
MongoDBのツールを使ったバックアッ プとリストア •
mongodumpとmongorestore • ドキュメントレベルでのリストアになるので、インデックスは再構 築になる → 時間かかるので要注意
38.
シャードクラスタのバックアップとリストア • 小規模なシャードクラスタ(根本的に矛盾してますが)なら、普通にツールでバッ
クアップ/リストア • 通常は、シャード毎にバックアップ/リストアを行うことになる(難易度アップ) • ただし、シャードの境界は動的に変わるので、そこの対処はケースバイケース • 出て行ったドキュメントは無視してOK • バックアップ→リストアの間に当該シャードに入ってきたドキュメントがあっ た場合は、「どうにかして」対処が必要
39.
予想外のシャットダウンからのデータ リカバリ •
ジャーナリング無効 & 単独インスタンスで、クリーンにシャットダ ウンされなかった場合、データファイルの破損の可能性があるので、 リペアの手順を踏むこと • シリアスな運用であれば、ジャーナリングを有効にするか、レプリ カセットを使うべきです
40.
改善継続中 - 2.6以降について少し
• 最新バージョンは2.6系 • aggregation framework - サイズの制約の緩和 • Write protocolの改善 - レイテンシの低減 • Index Intersection - 複数インデクスの同時活用のはず… • 2.8/3.0はかなり大規模なアップデートになる模様
41.
まとめ
42.
今日話したこと • 運用についてはドキュメントをきっちり読見ましょう
• この本に基本は書かれています。概要把握にどうぞ。 • 電子書籍もあります。 • http://www.oreilly.co.jp/books/ 9784873115900/ • そのほかにもMongoDB関連の電子書籍があるの で、オライリージャパンのサイトで検索を。
43.
それはともかく • 簡単に始められて
• かなり深く使うこともできます • ただし落とし穴もあります →コミュニティへどうぞ! http://www.mongodb.jp • まずは手を動かしてみましょう! • レプリカセットをお手軽に試せます: • https://bitbucket.org/tamagawa_ryuji/mongodb_replicaset_playground_on_vagrant
44.
ご清聴ありがとうございました。
Download











![論理構造の違い
RDB MongoDB
{
_id: new ObjectId(""),
slug: "gardening-tools",
ancestors:
[{ name: "Home",
_id: new ObjectId(""),
slug: "home" },
{ name: "Outdoors",
_id: new ObjectId(“"),
slug: "outdoors"
} ],
}](https://image.slidesharecdn.com/in-mongodb-140921081955-phpapp01/75/In-mongodb-12-2048.jpg)



























![[大図解]ピグライフはこう動いている](https://cdn.slidesharecdn.com/ss_thumbnails/pigglifegreexca-110817005057-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


























































