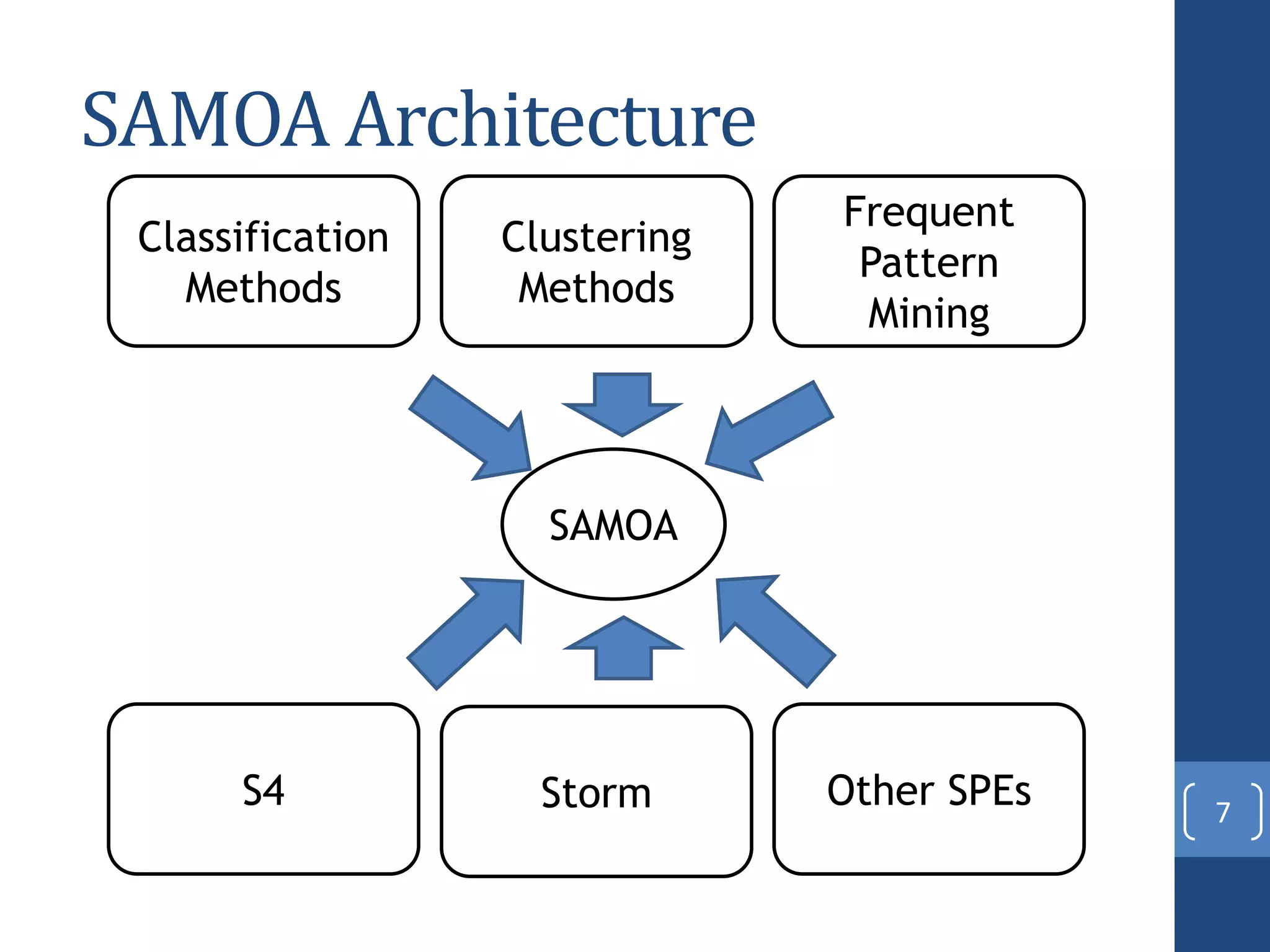
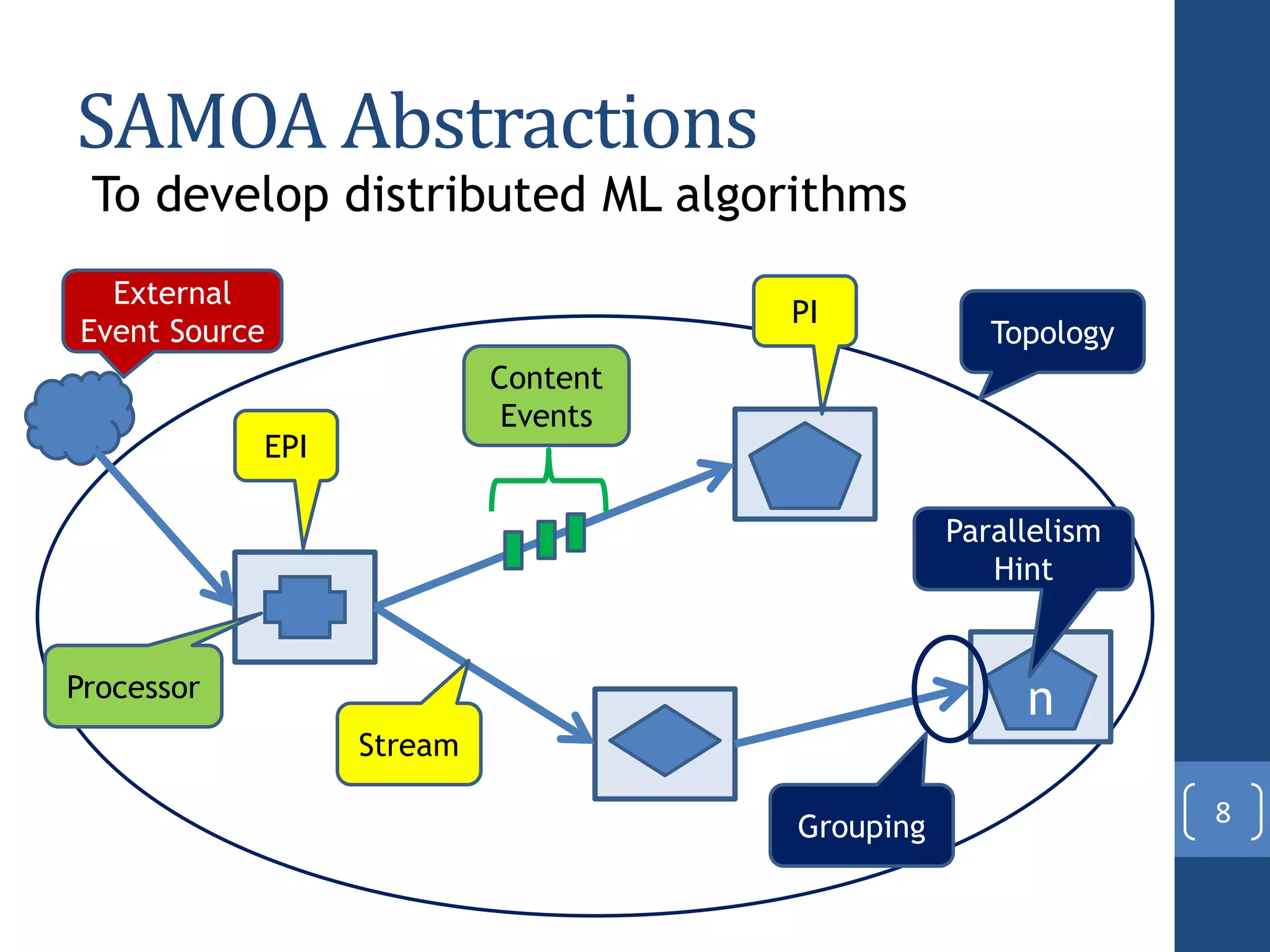
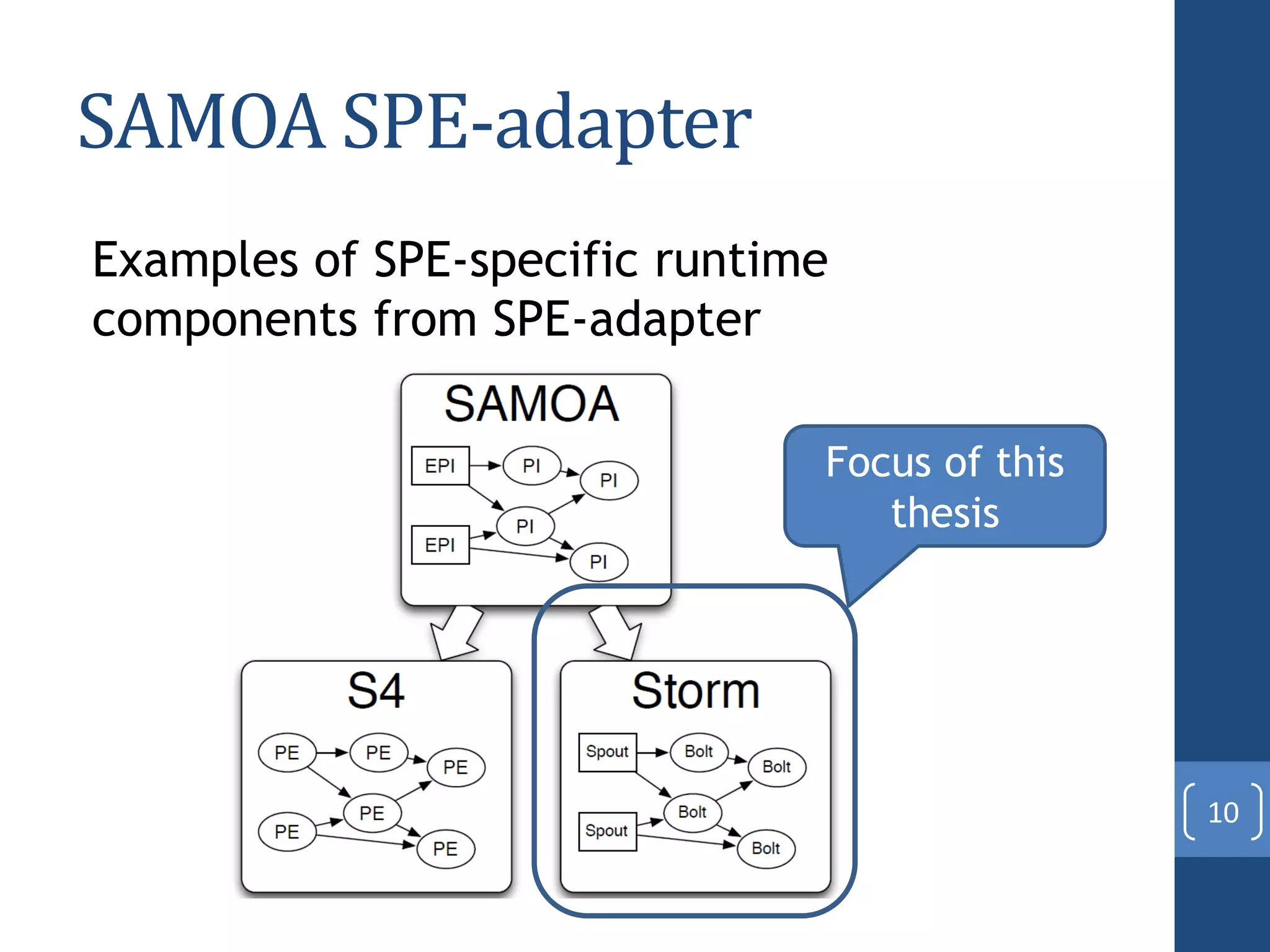
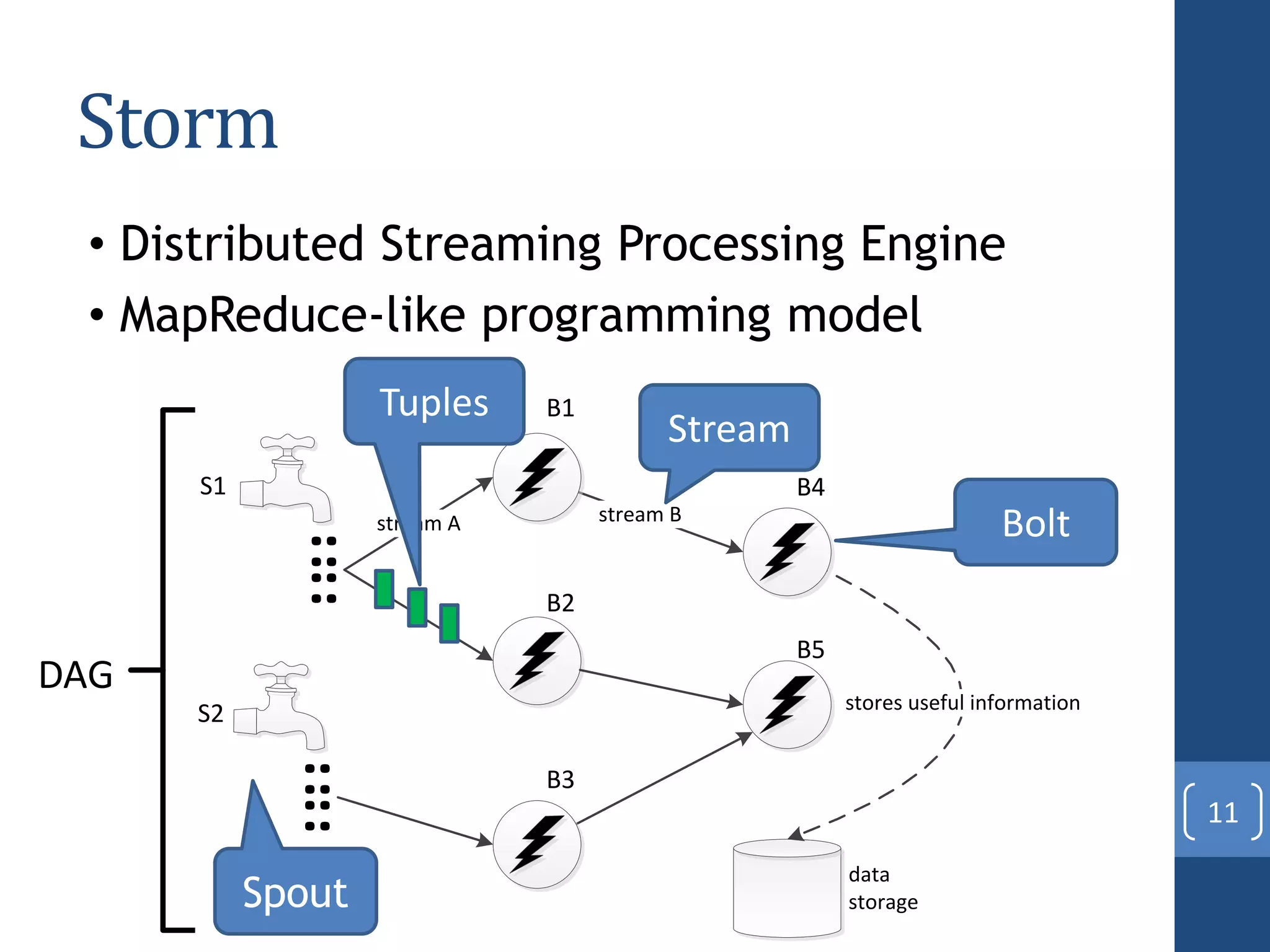
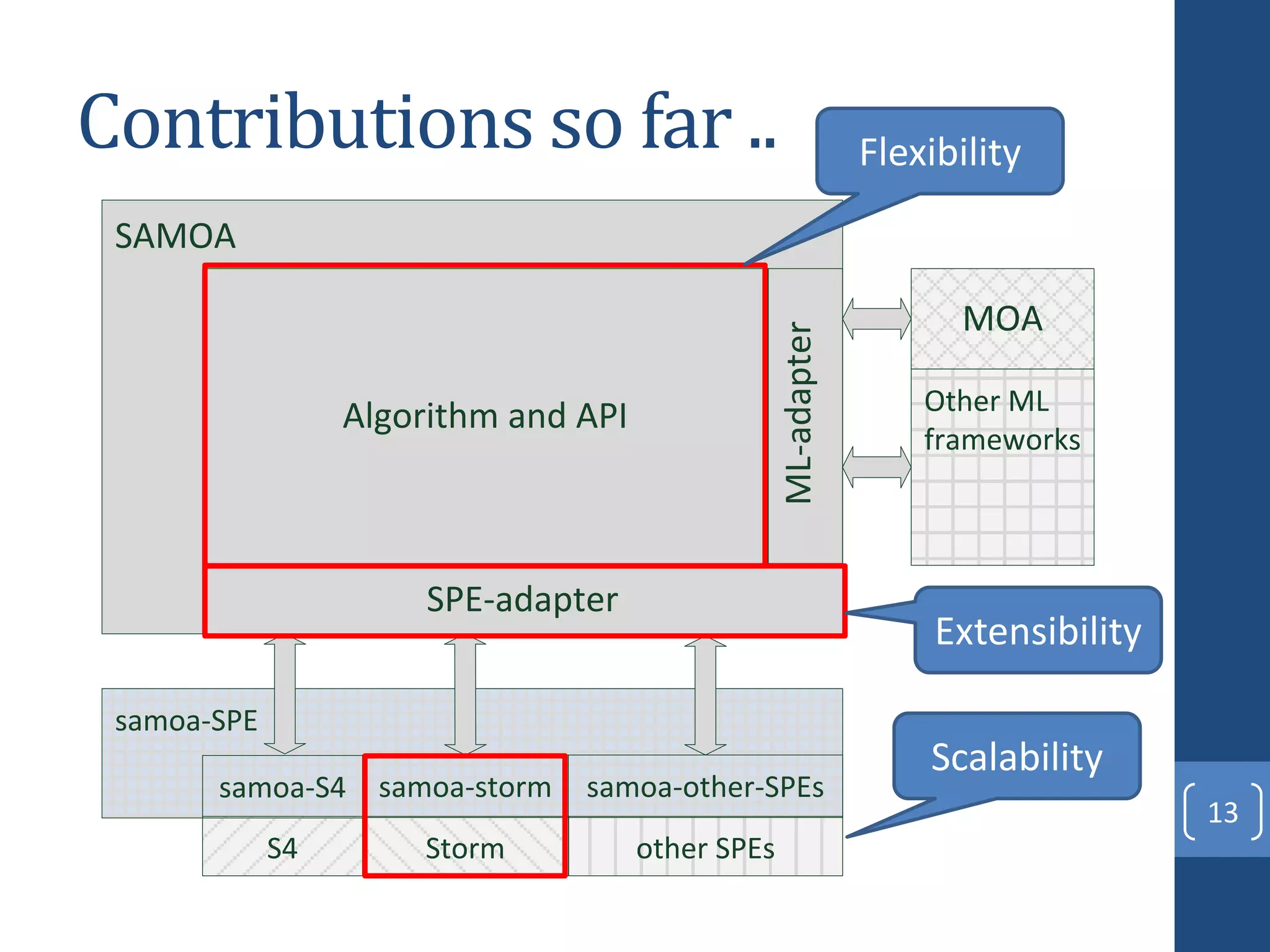
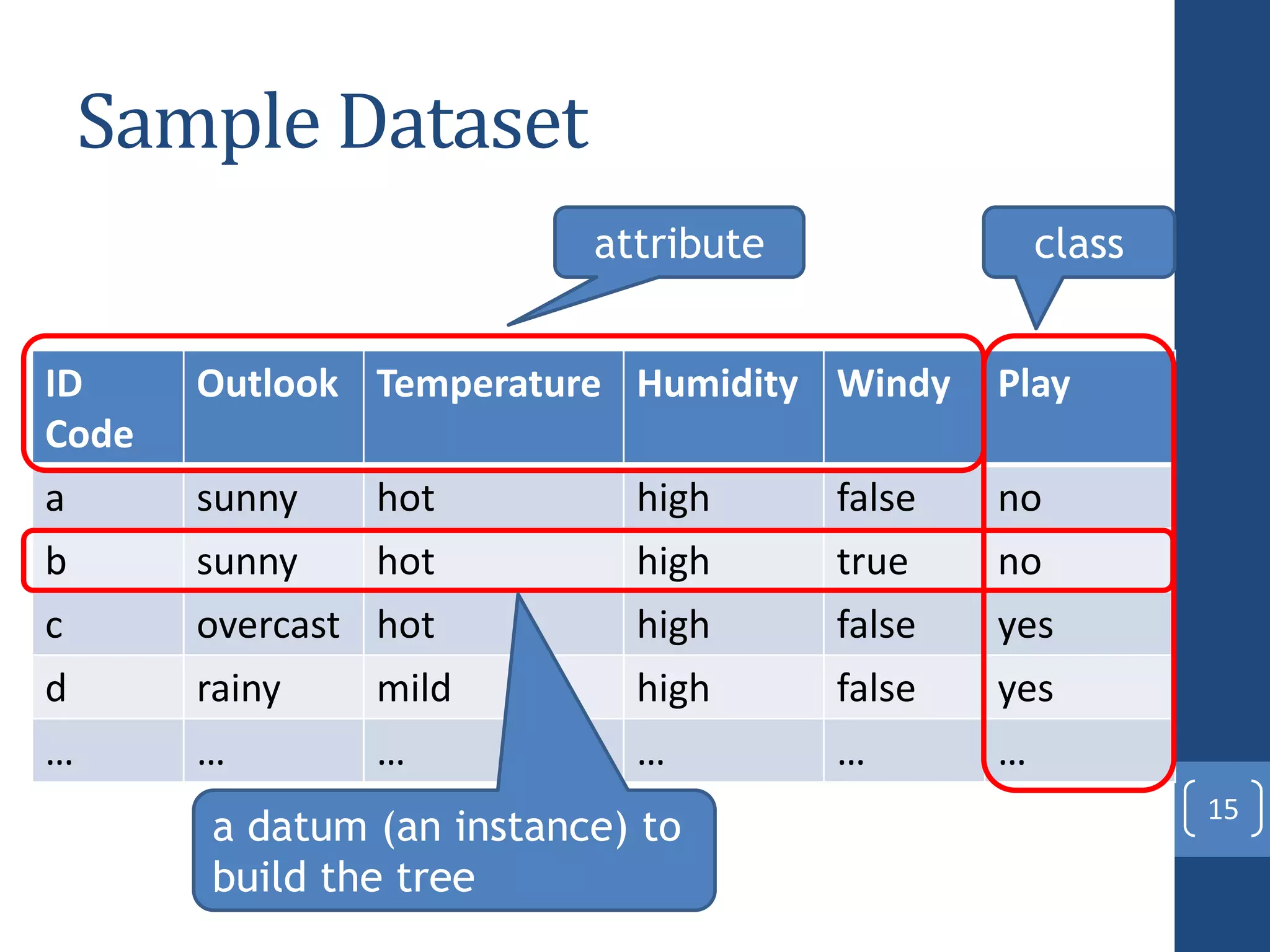
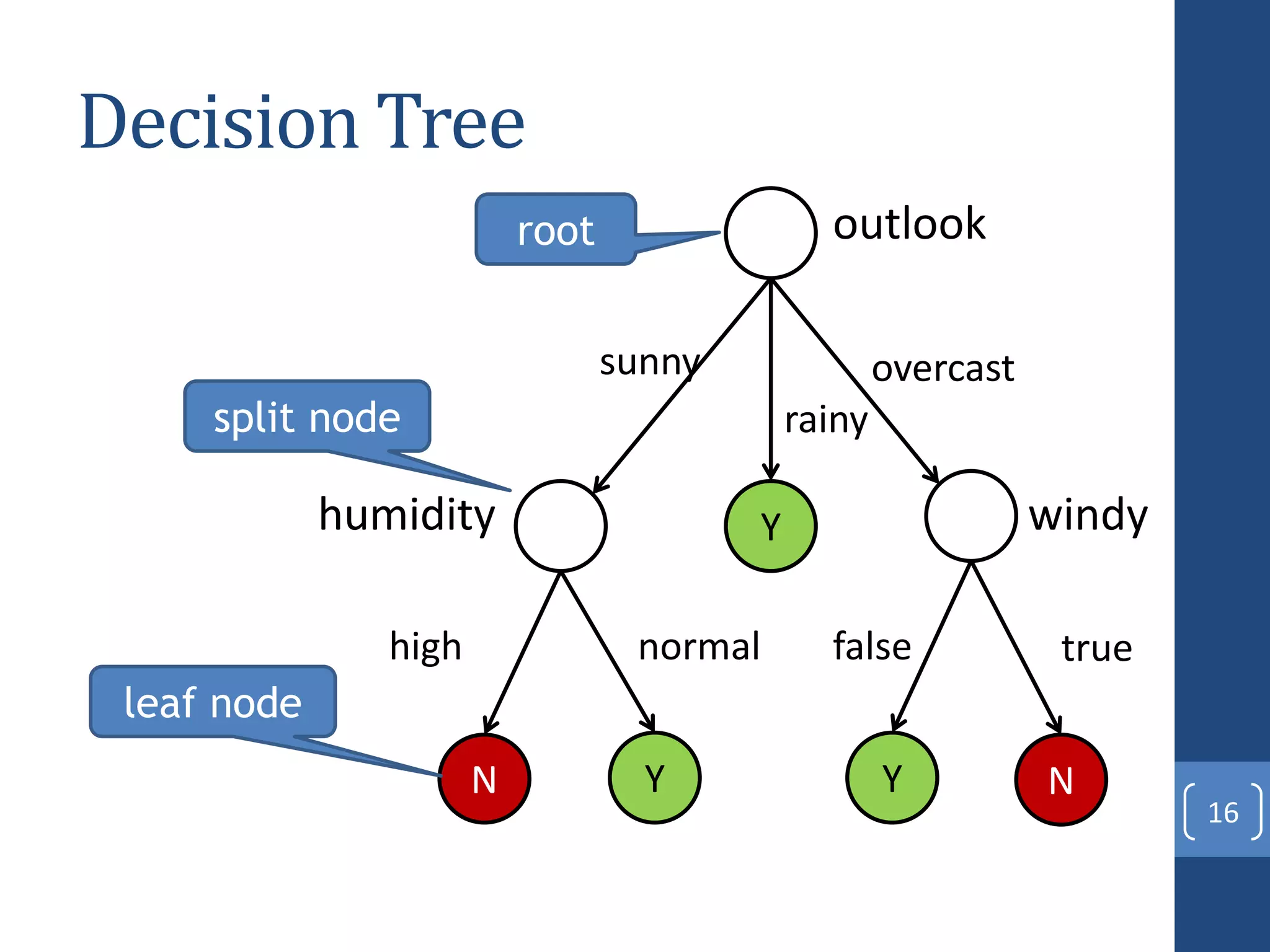
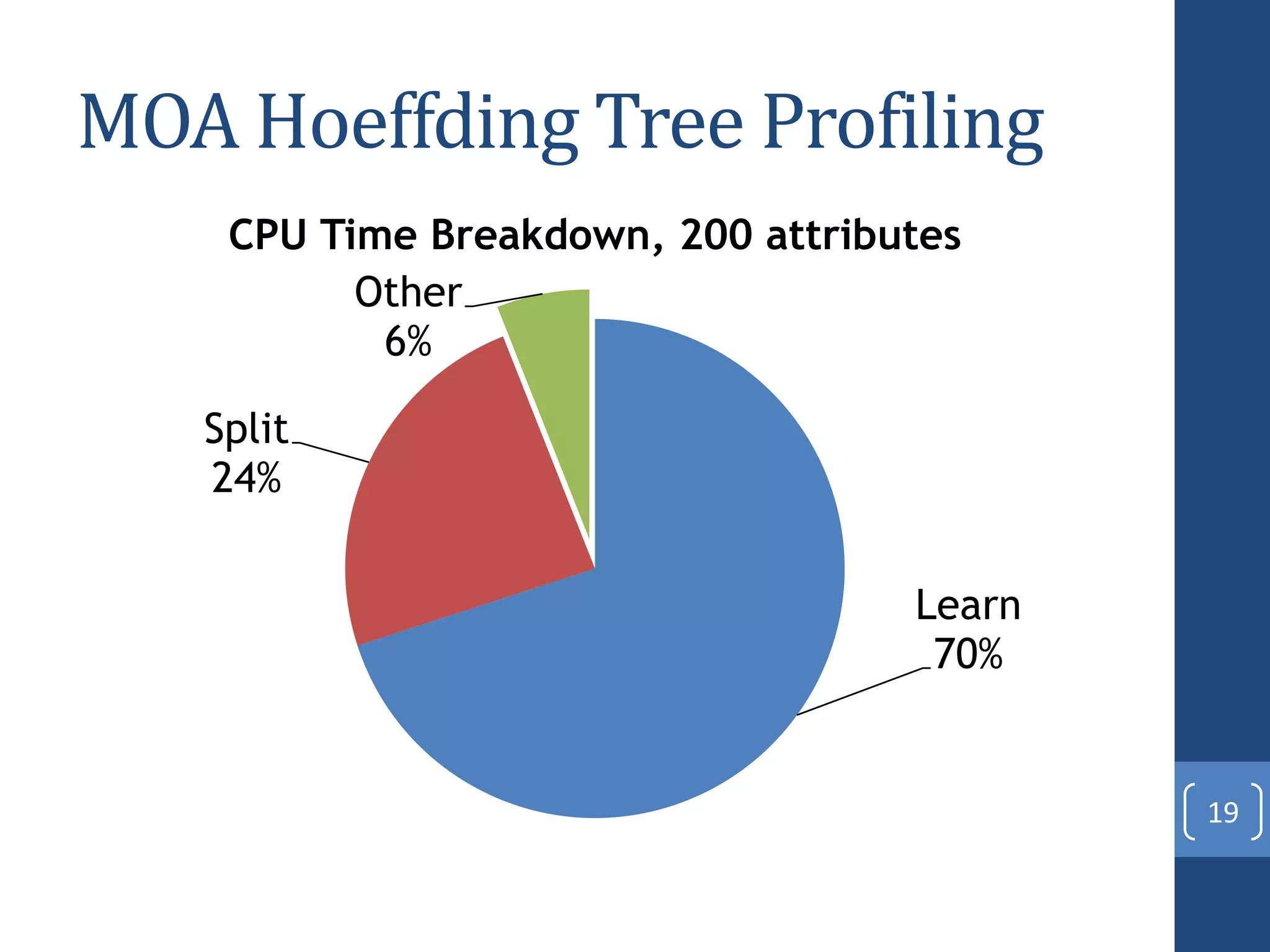
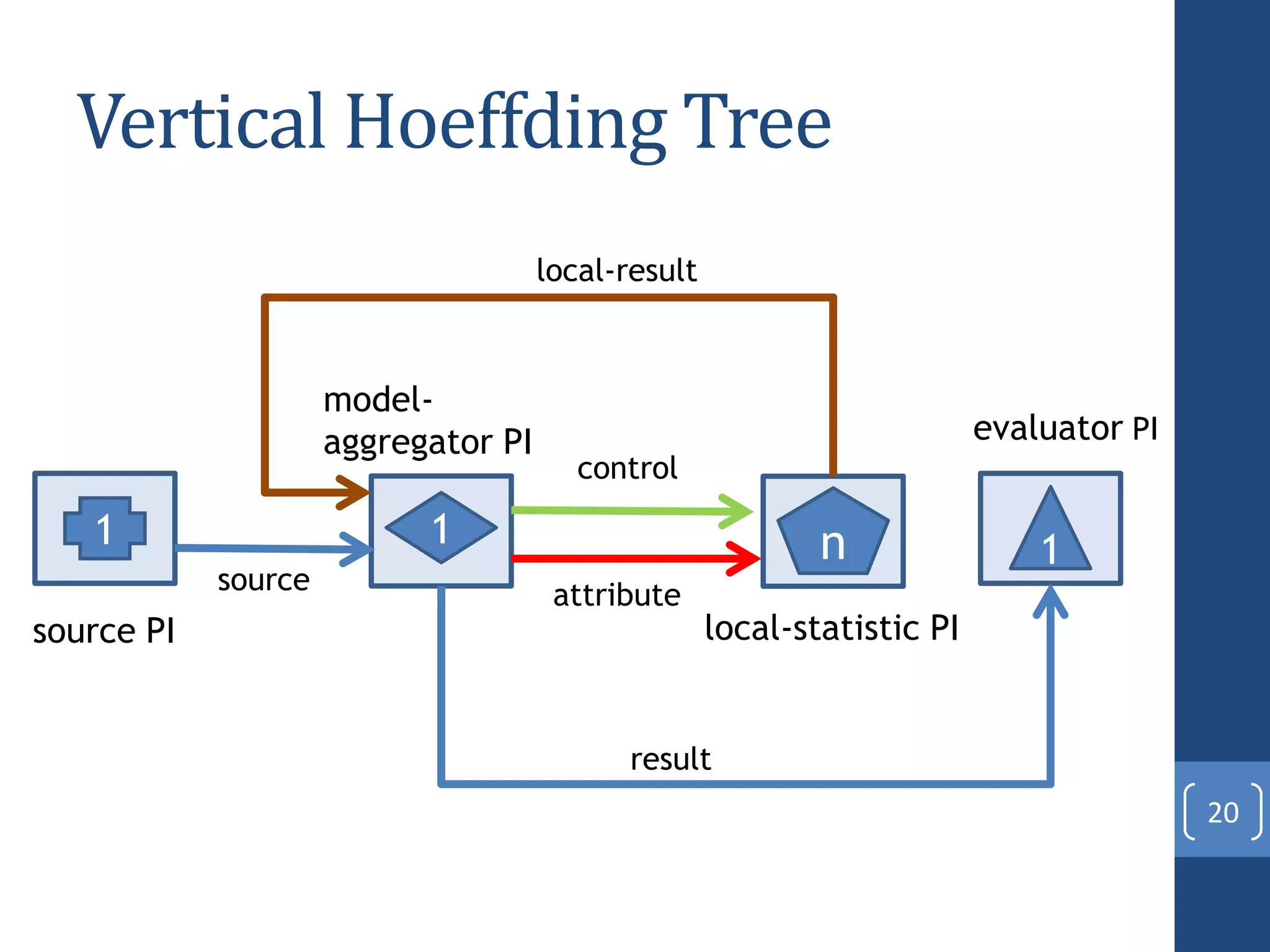
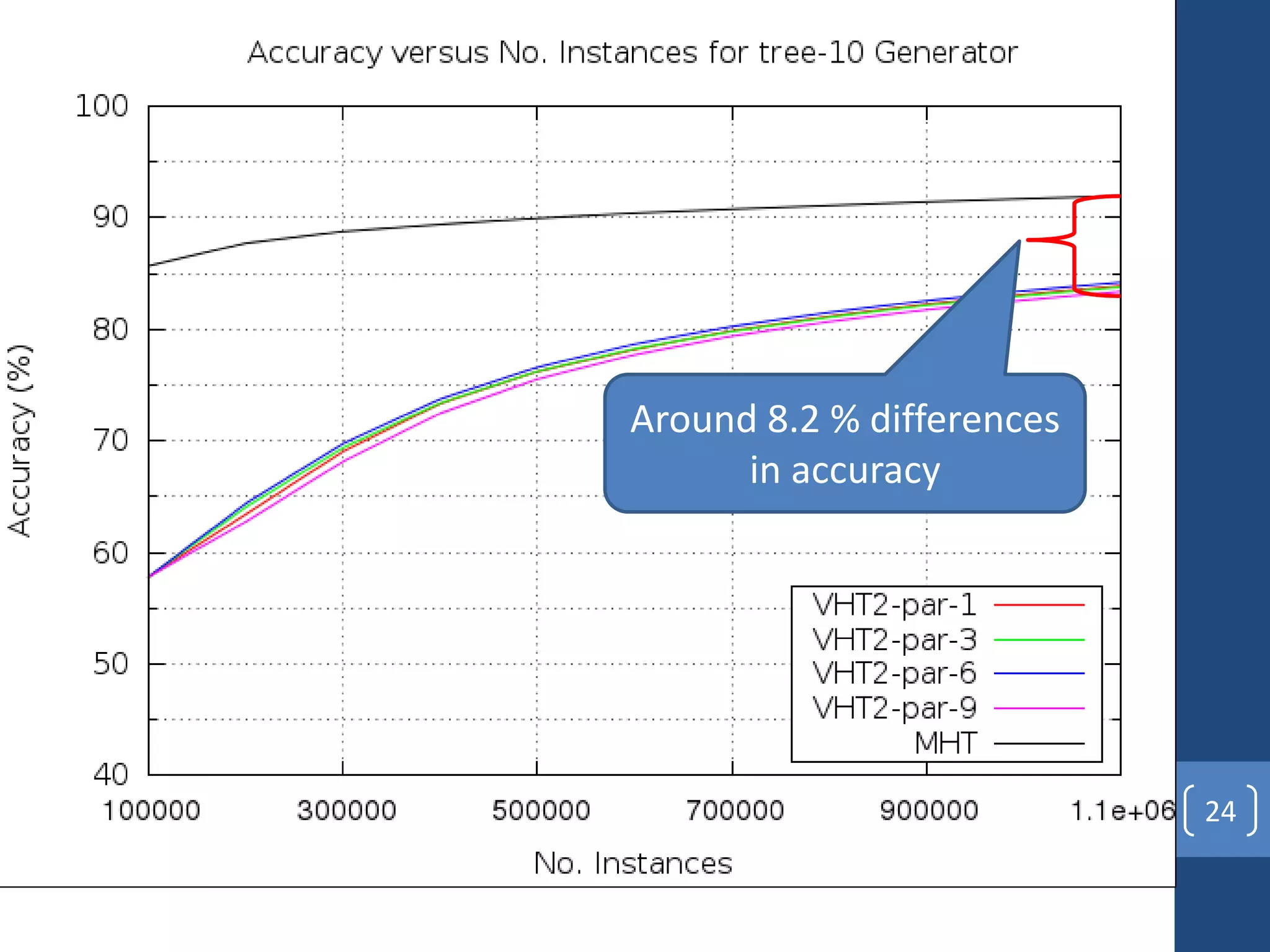
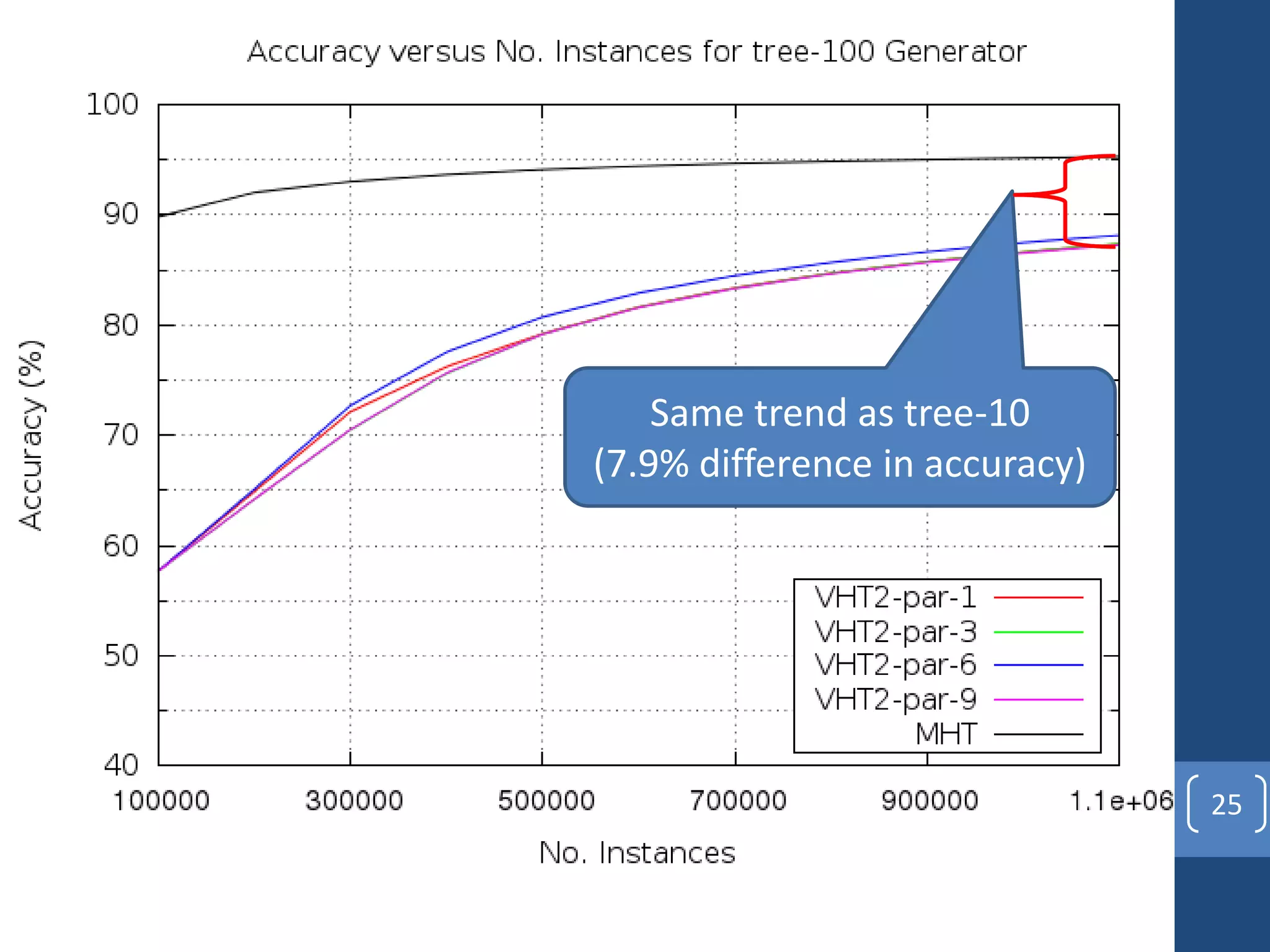
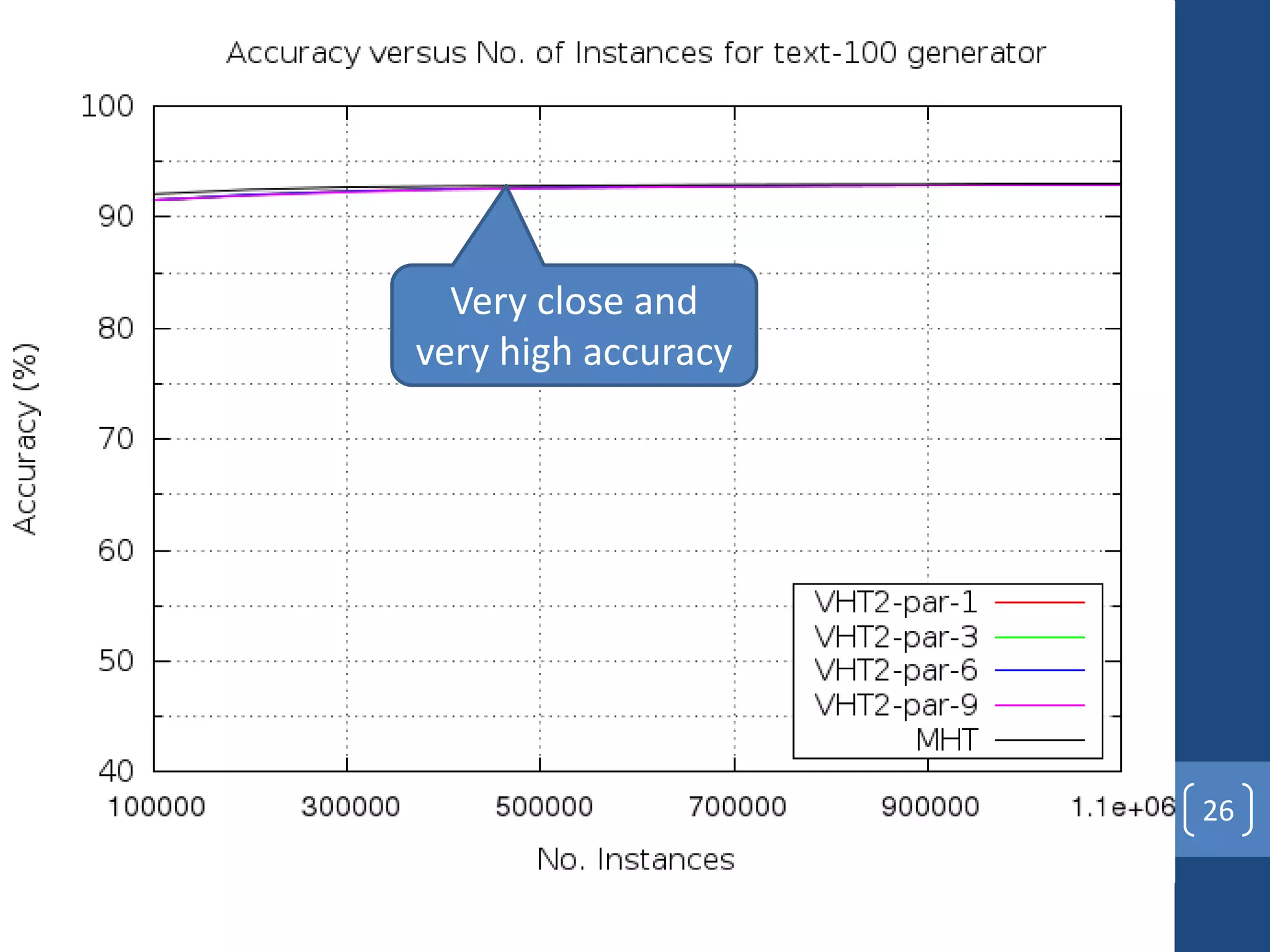
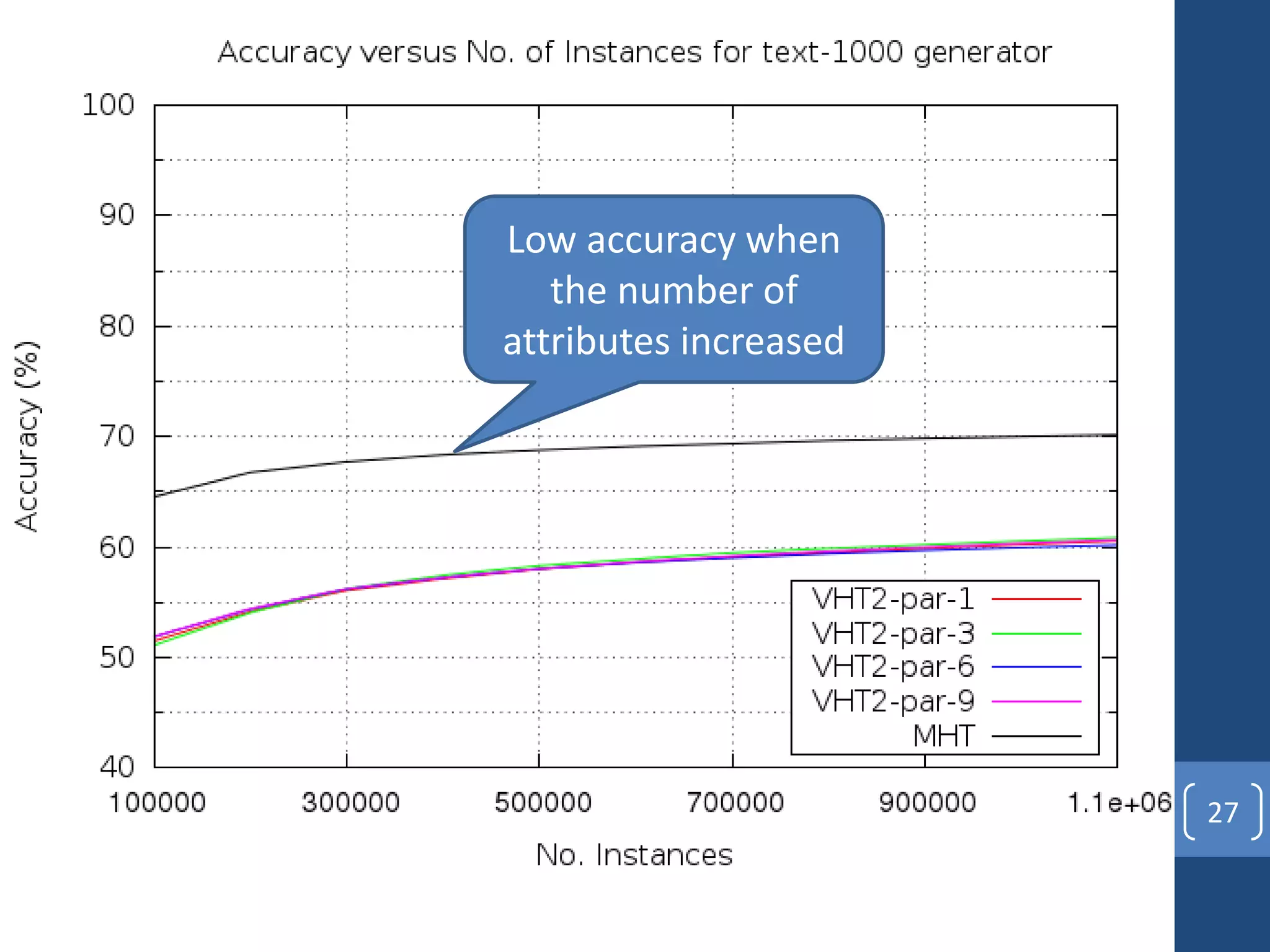
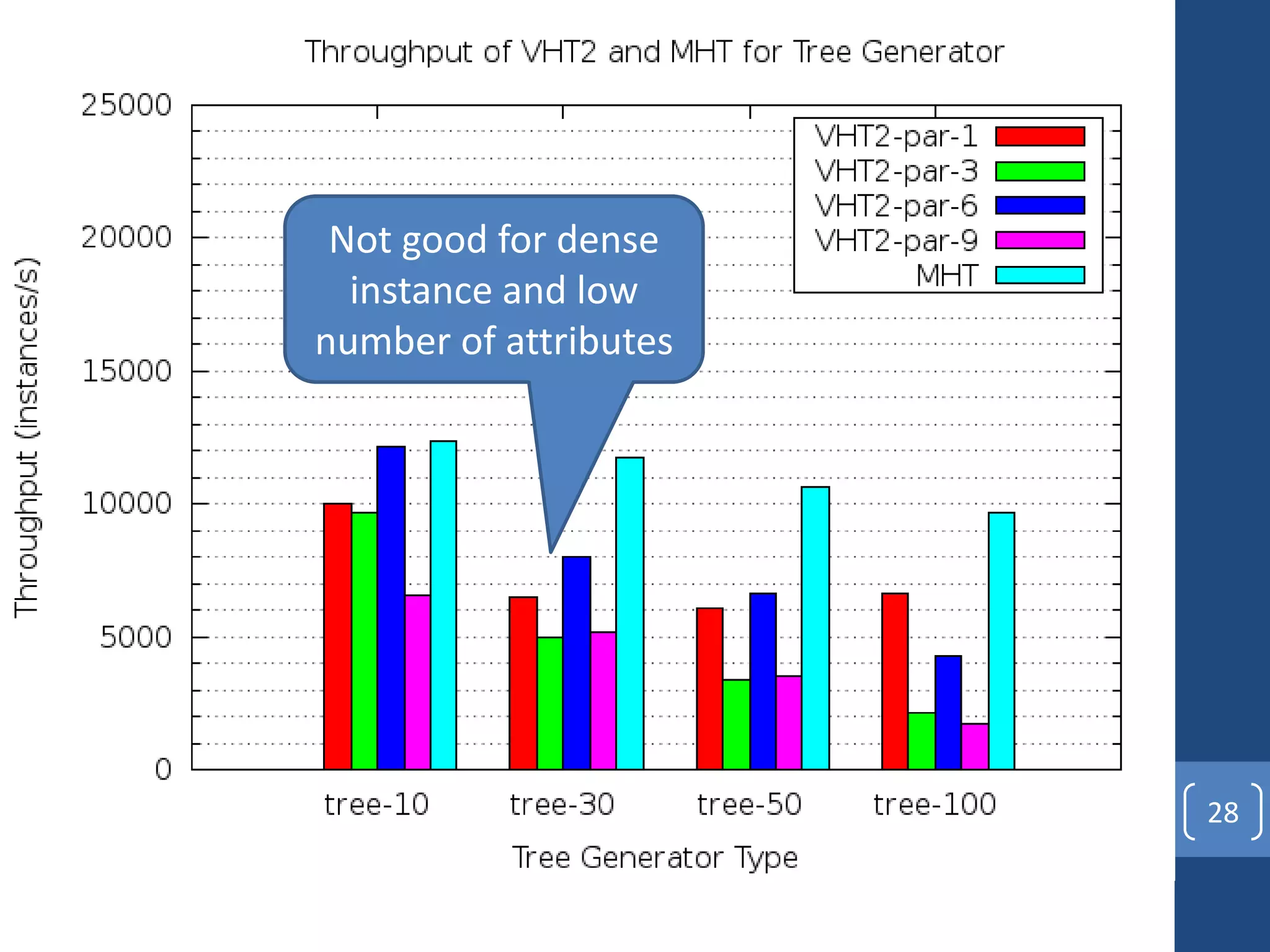
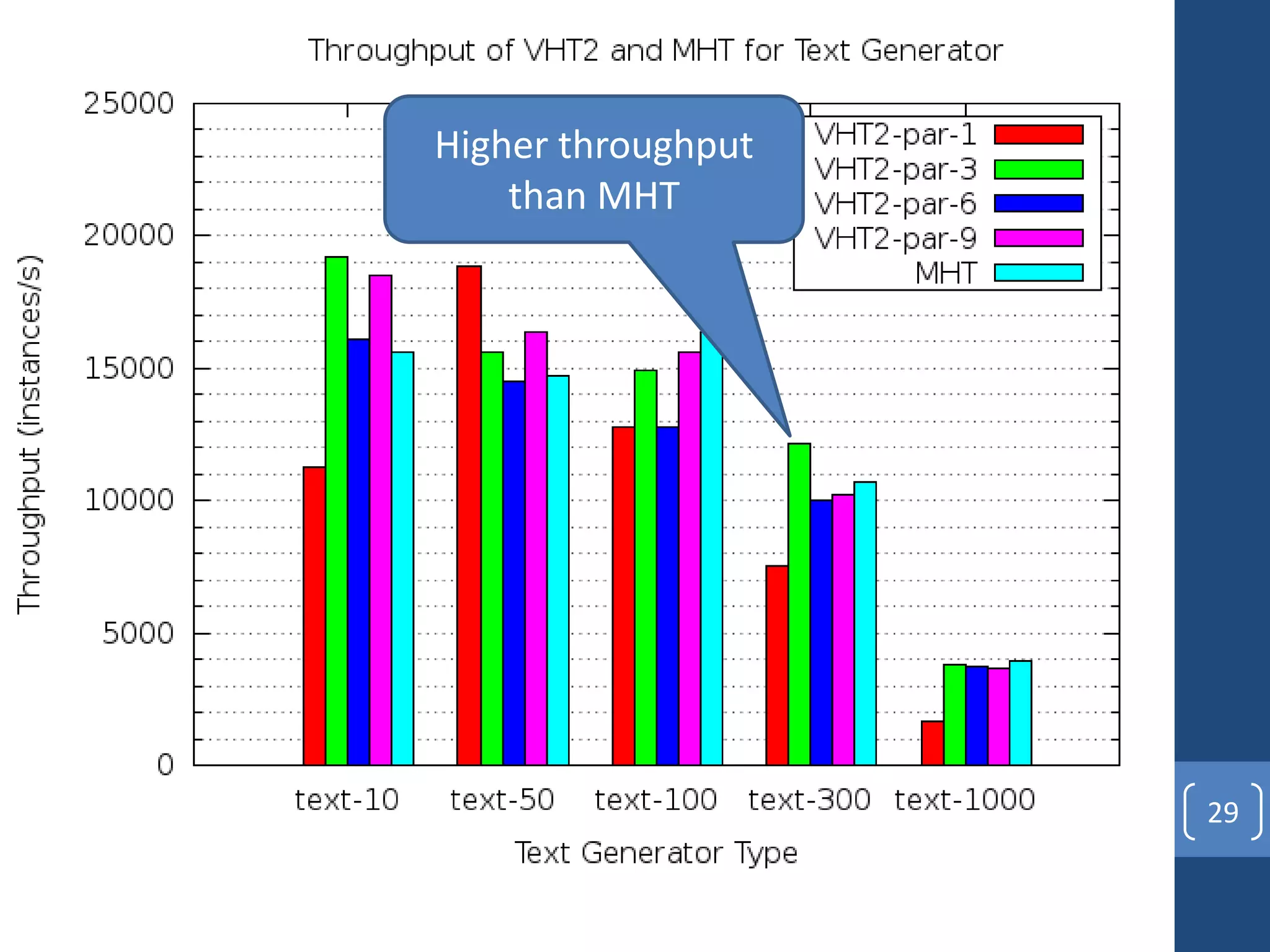
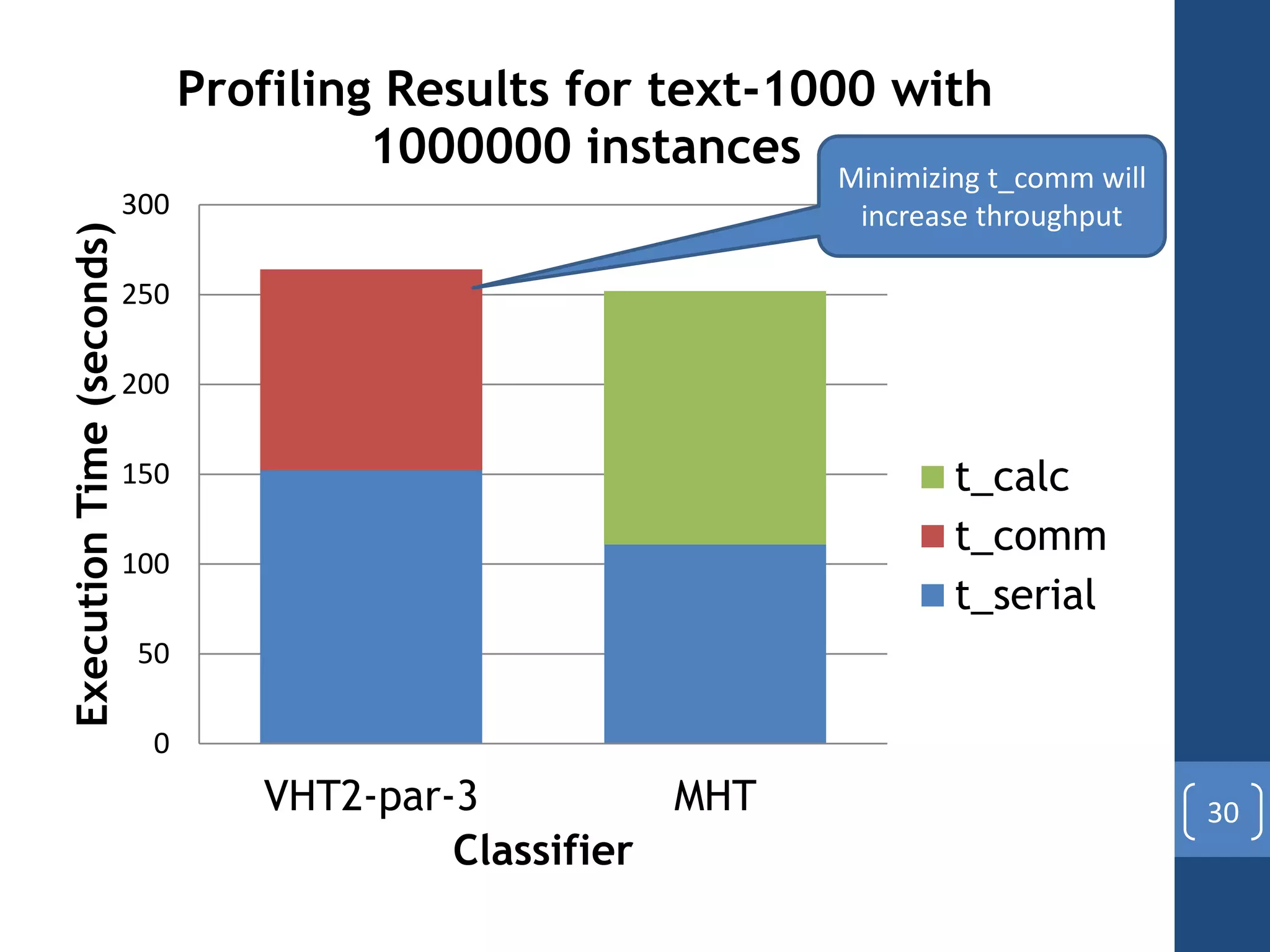
This document presents a distributed decision tree learning algorithm called Vertical Hoeffding Tree (VHT) for mining big data streams. It summarizes the contributions of the master's thesis, which include: (1) Developing the SAMOA framework for distributed streaming machine learning, (2) Integrating SAMOA with the Storm distributed stream processing engine, and (3) Implementing the VHT algorithm to improve scalability over the standard Hoeffding Tree algorithm when dealing with high-dimensional data streams. The evaluation shows that VHT achieves similar accuracy to Hoeffding Tree but higher throughput, especially on datasets with many attributes.