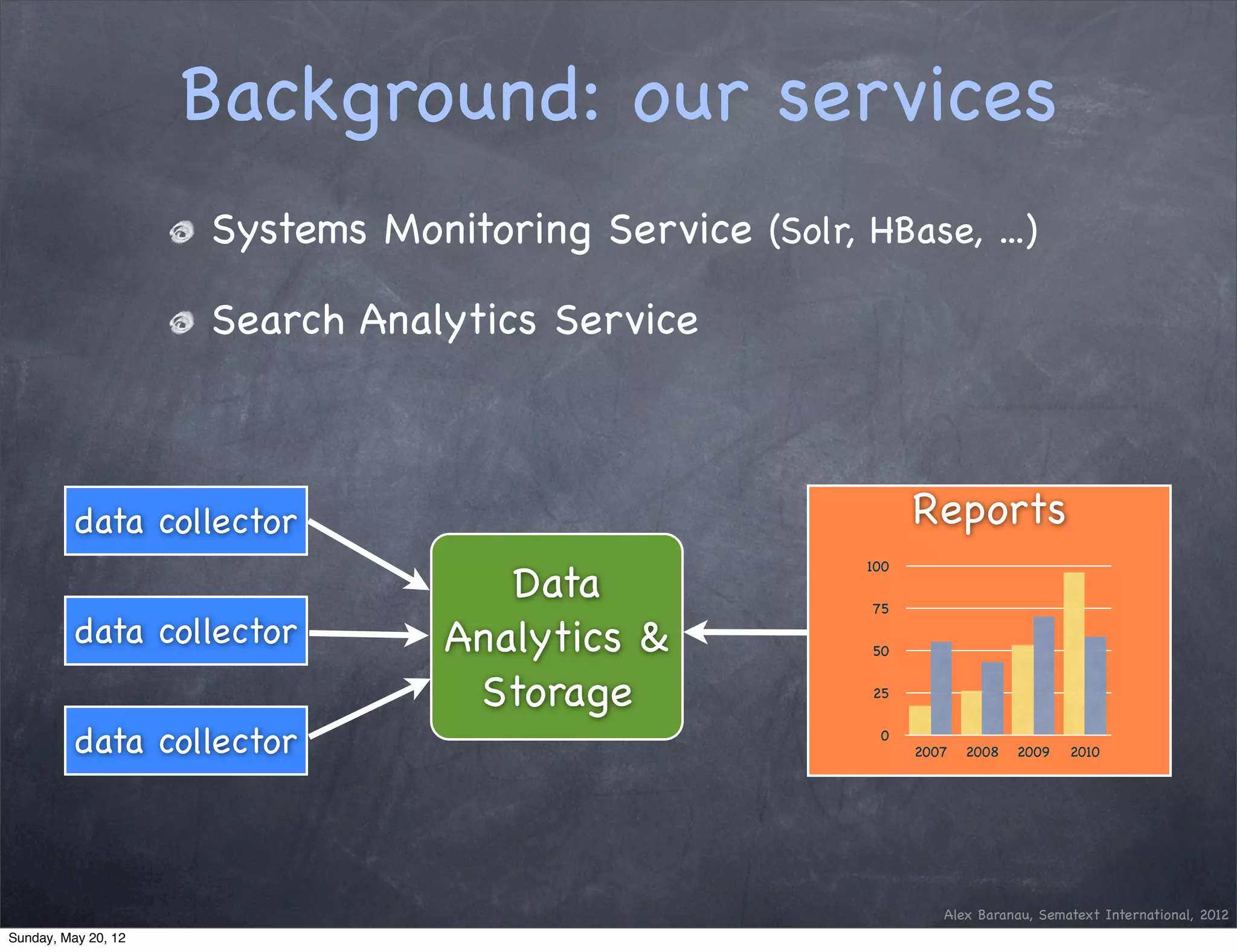
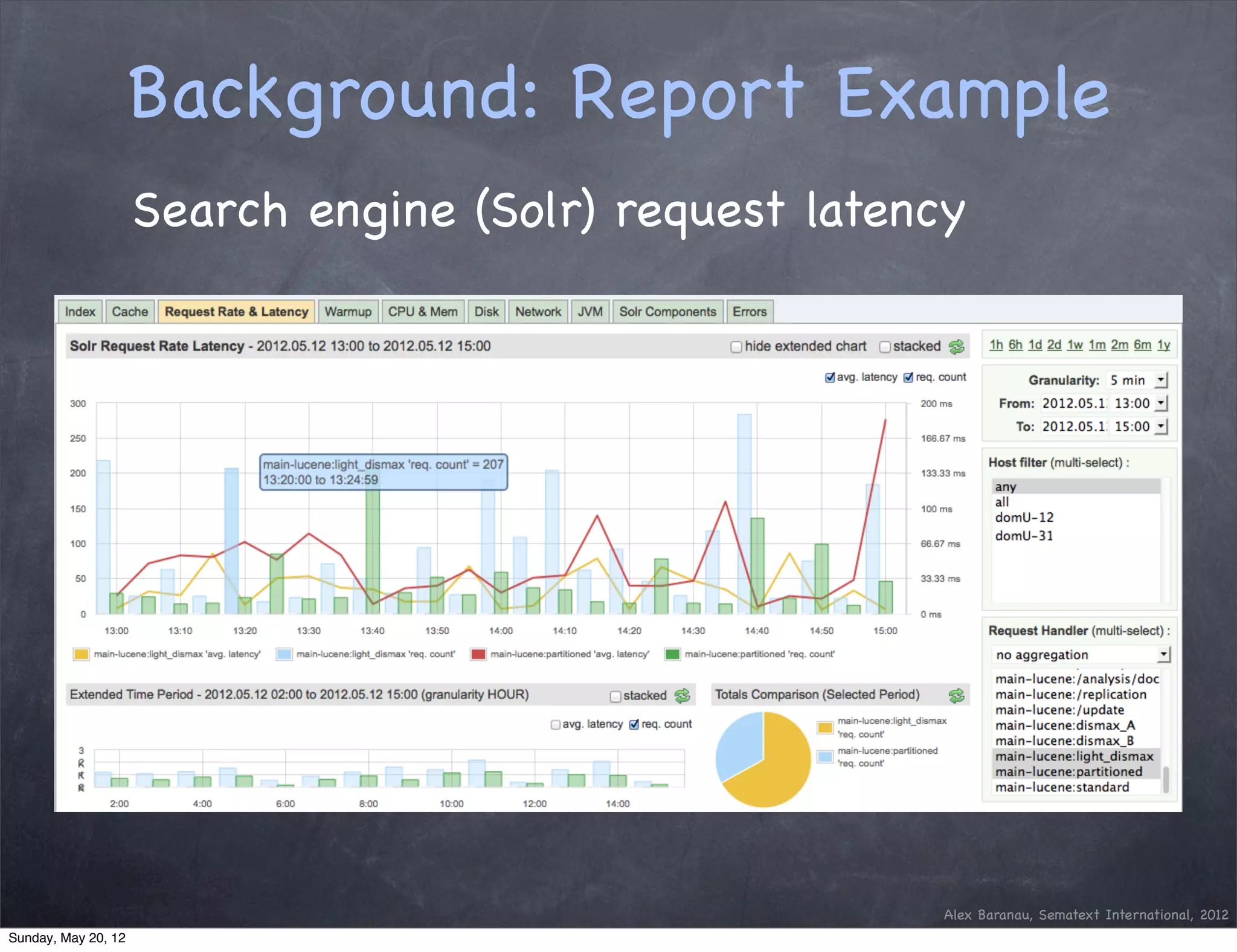
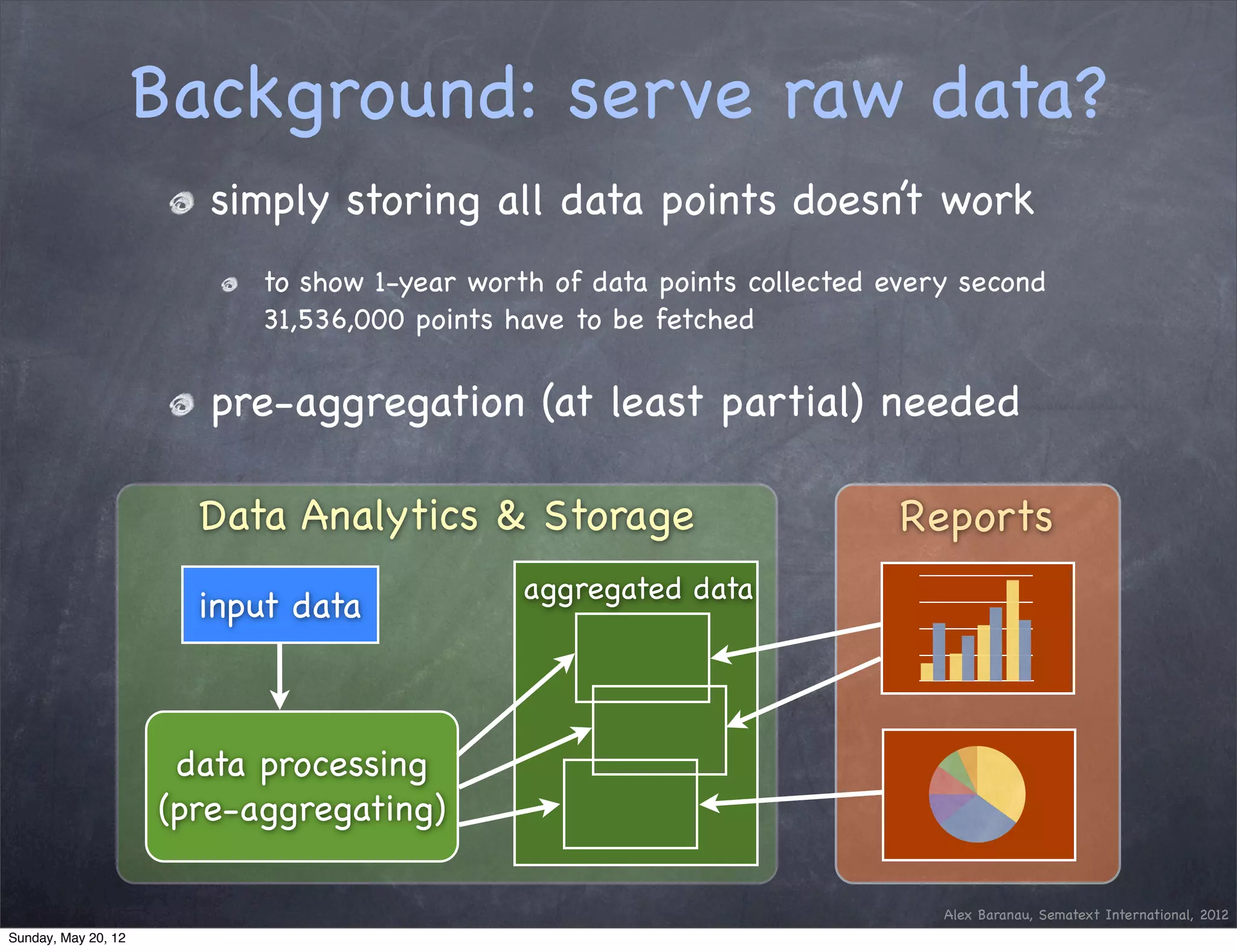
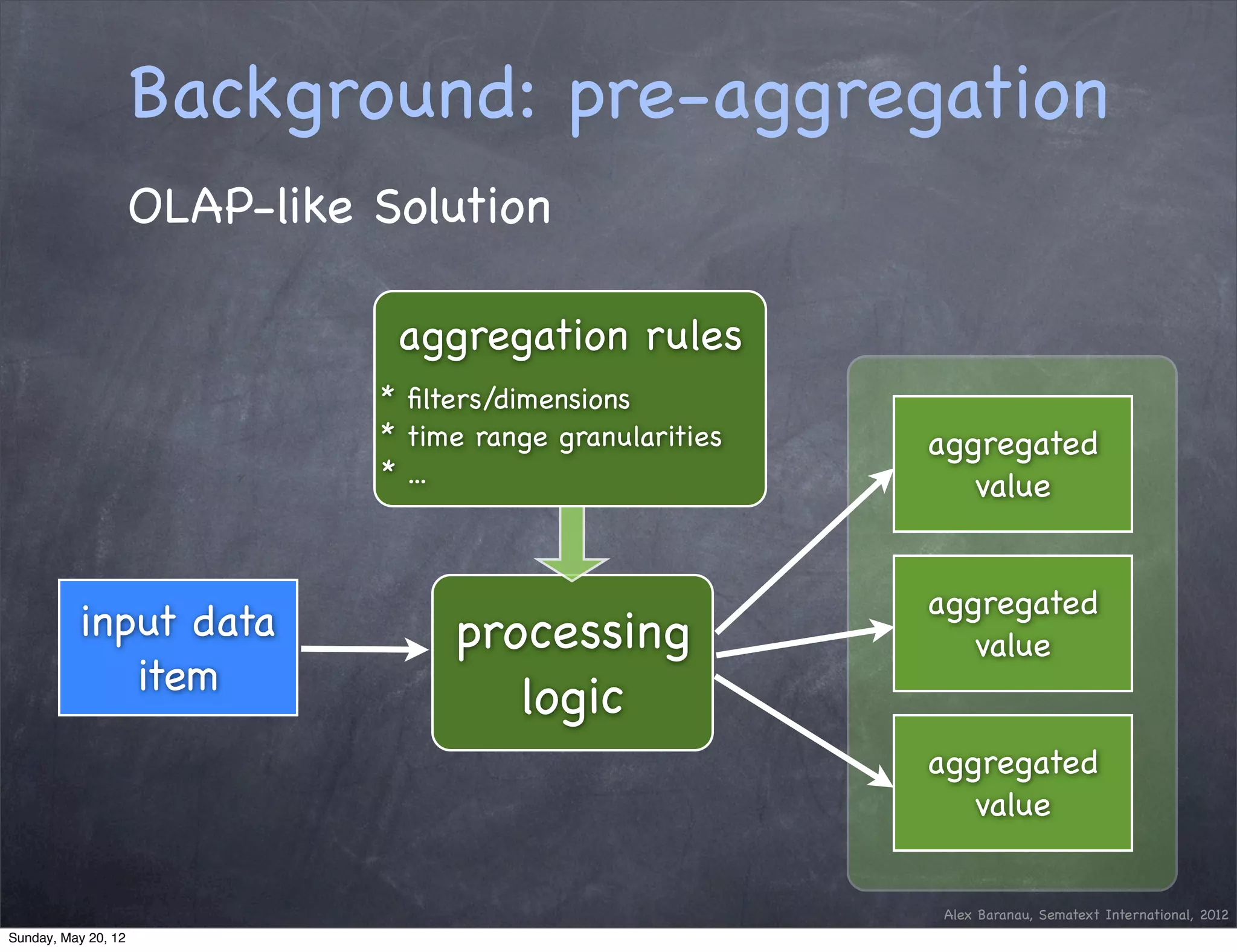
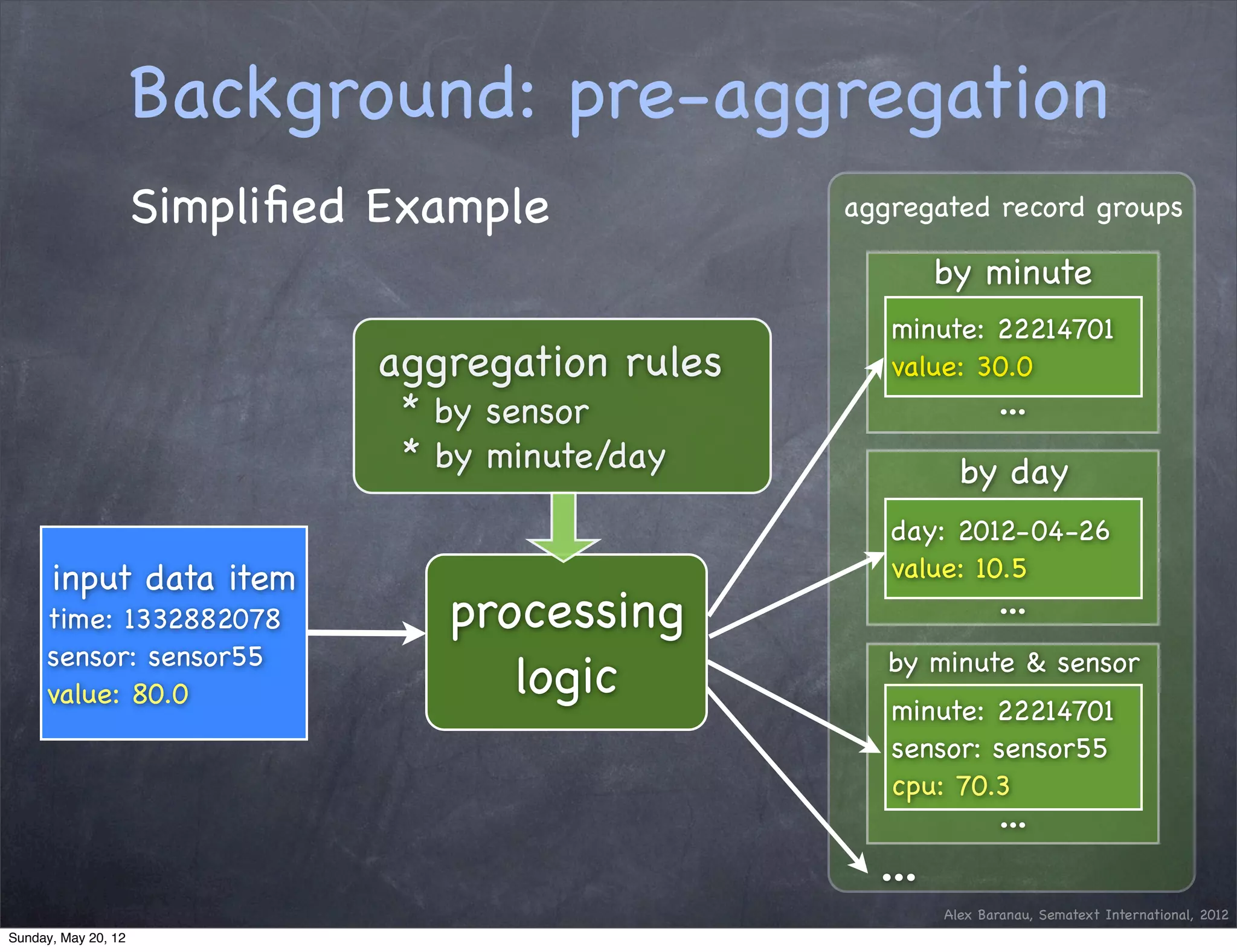
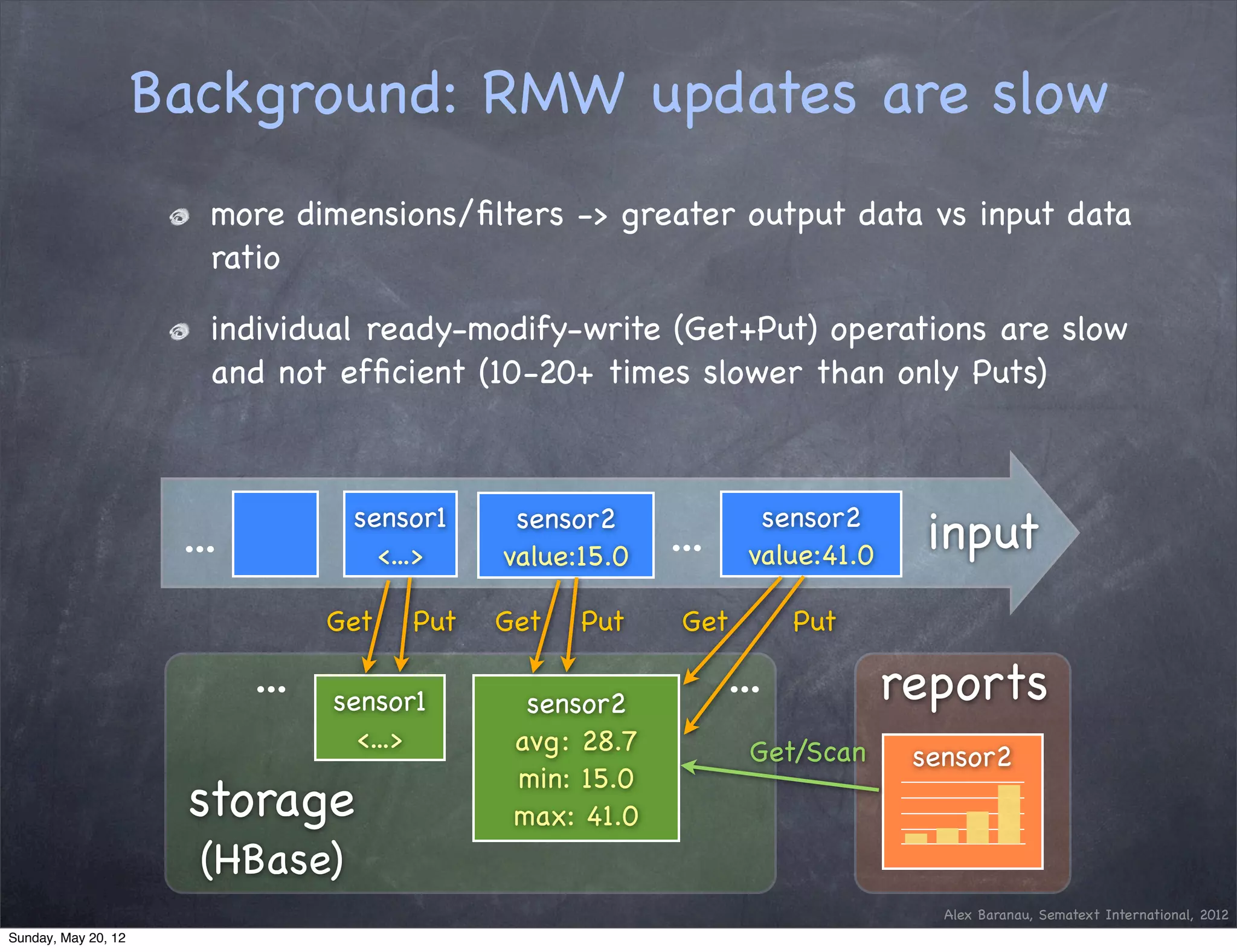
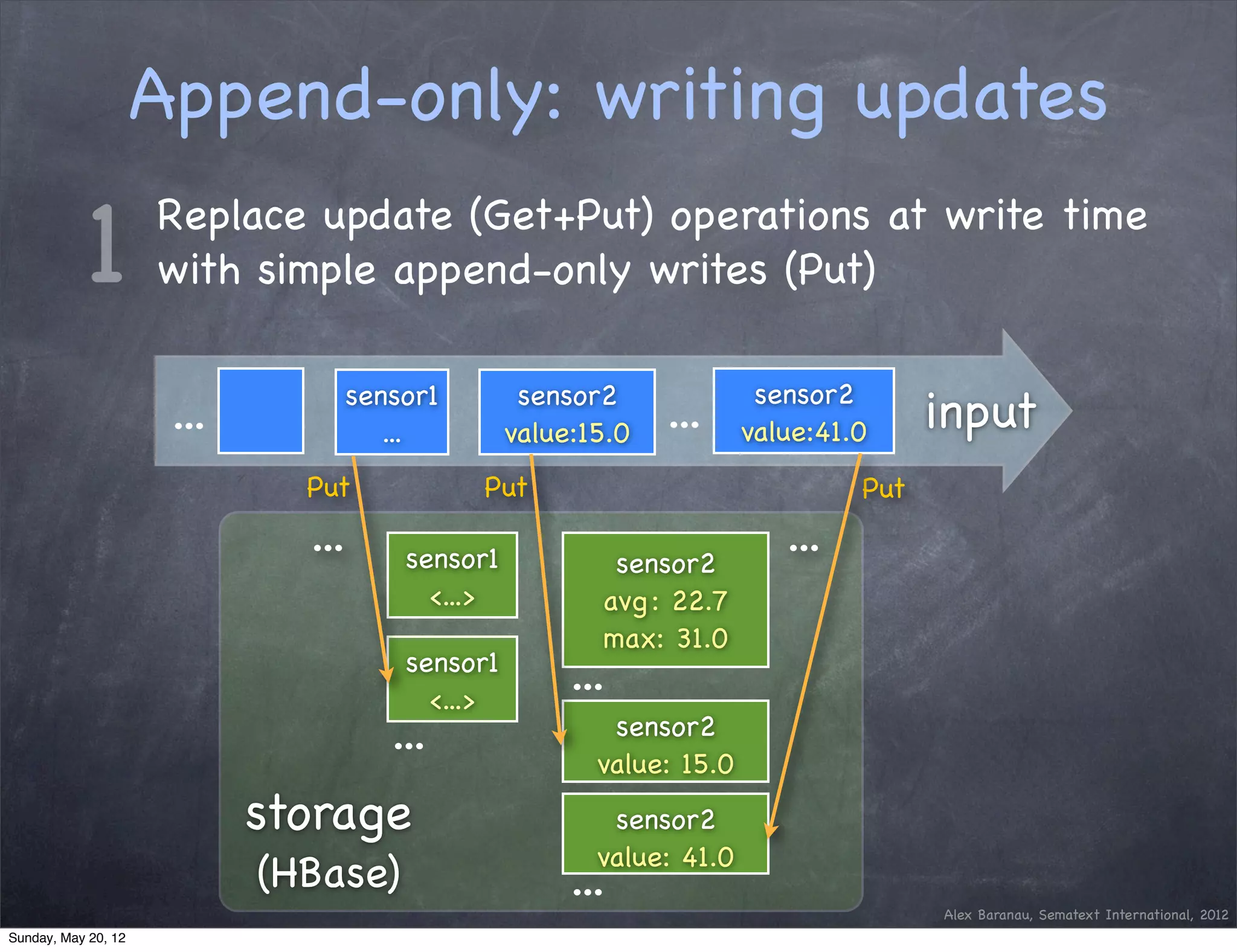
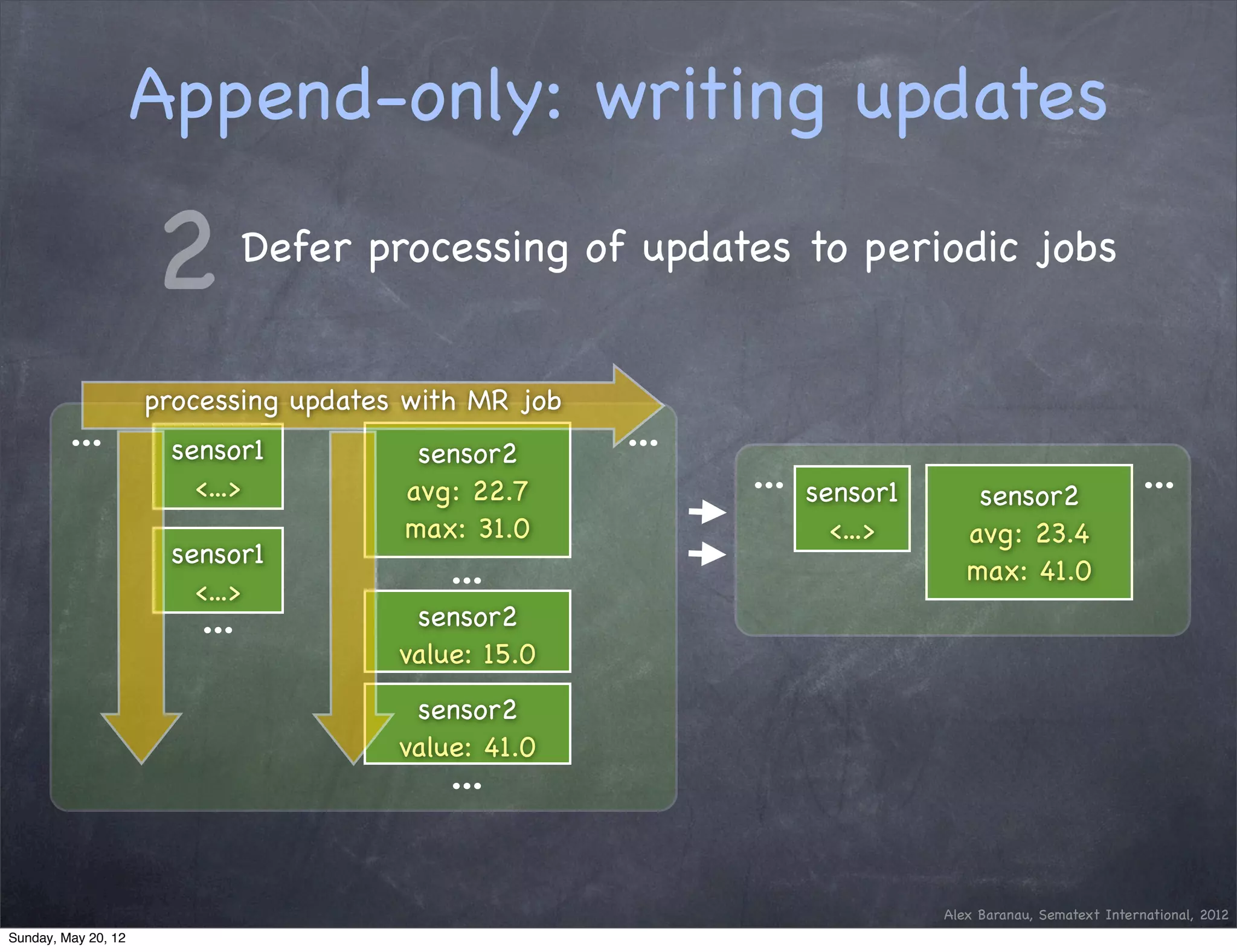
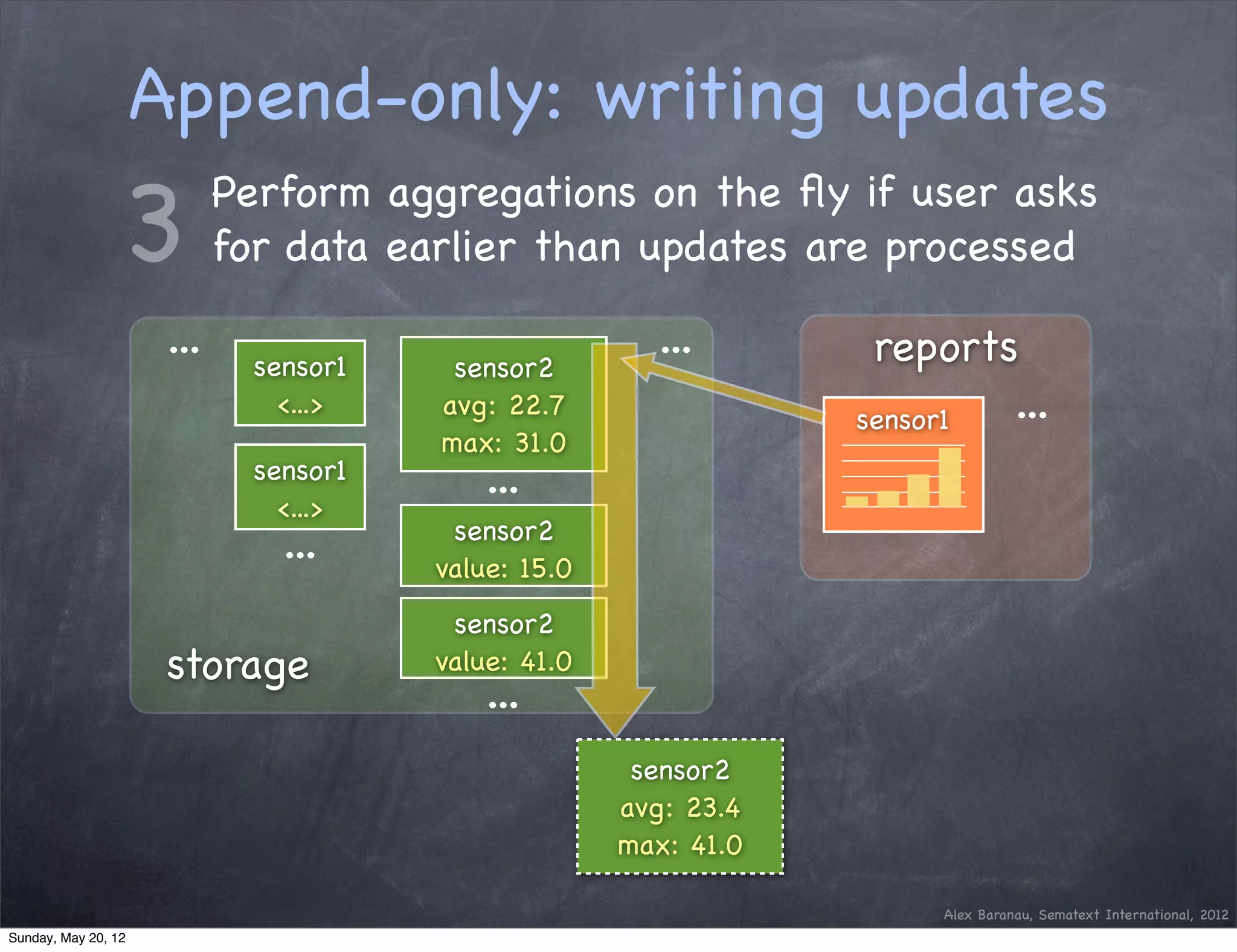
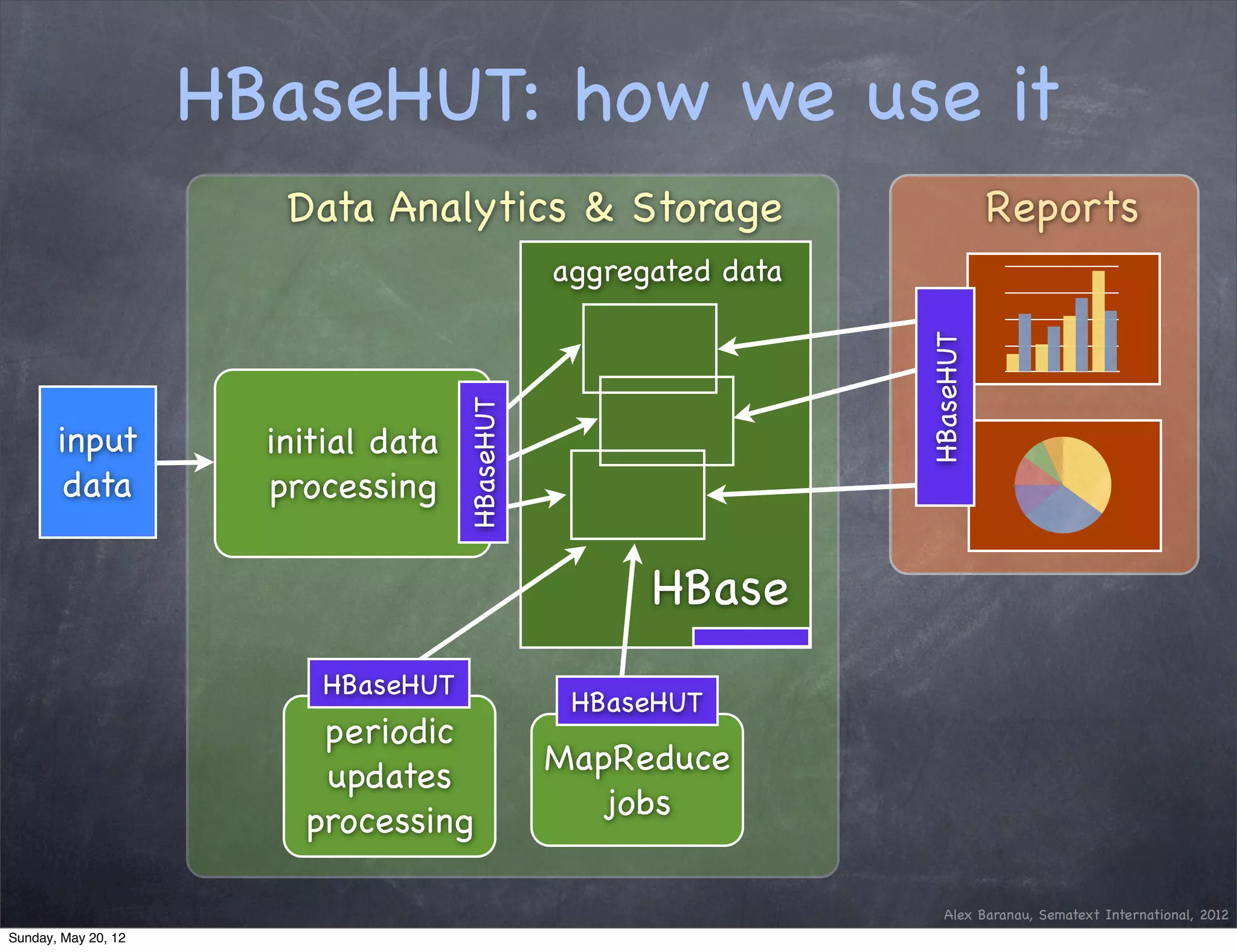
This document discusses using an append-only approach with HBase to enable real-time analytics. The append-only approach aims to increase update throughput by replacing read-modify-write operations with simple append writes. Updates are processed periodically by jobs rather than on-the-fly to reduce operations and resources. This allows handling high volumes of incoming data changes in real-time while enabling rollback of changes.
























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







