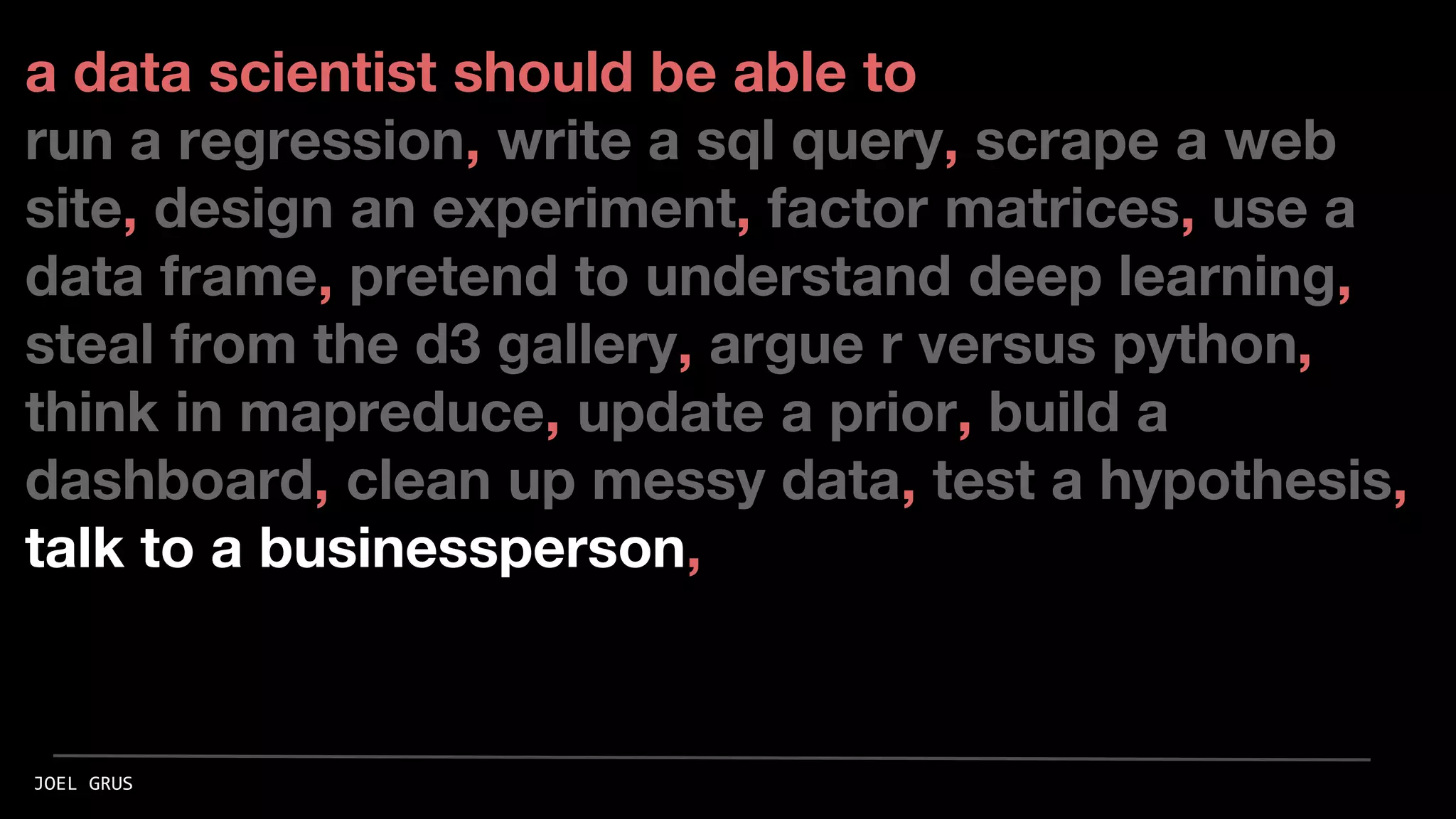
Joel Grus presented at the Seattle DAML meetup discussing essential skills for data scientists, emphasizing the importance of foundational knowledge alongside practical skills. He highlighted the need for proficiency in running regressions, writing SQL queries, web scraping, and hypothesis testing, among other skills. Grus also advocated for learning through building projects and provided insights on the balance between mathematical understanding and practical application in data science.


















































![The Tools Way
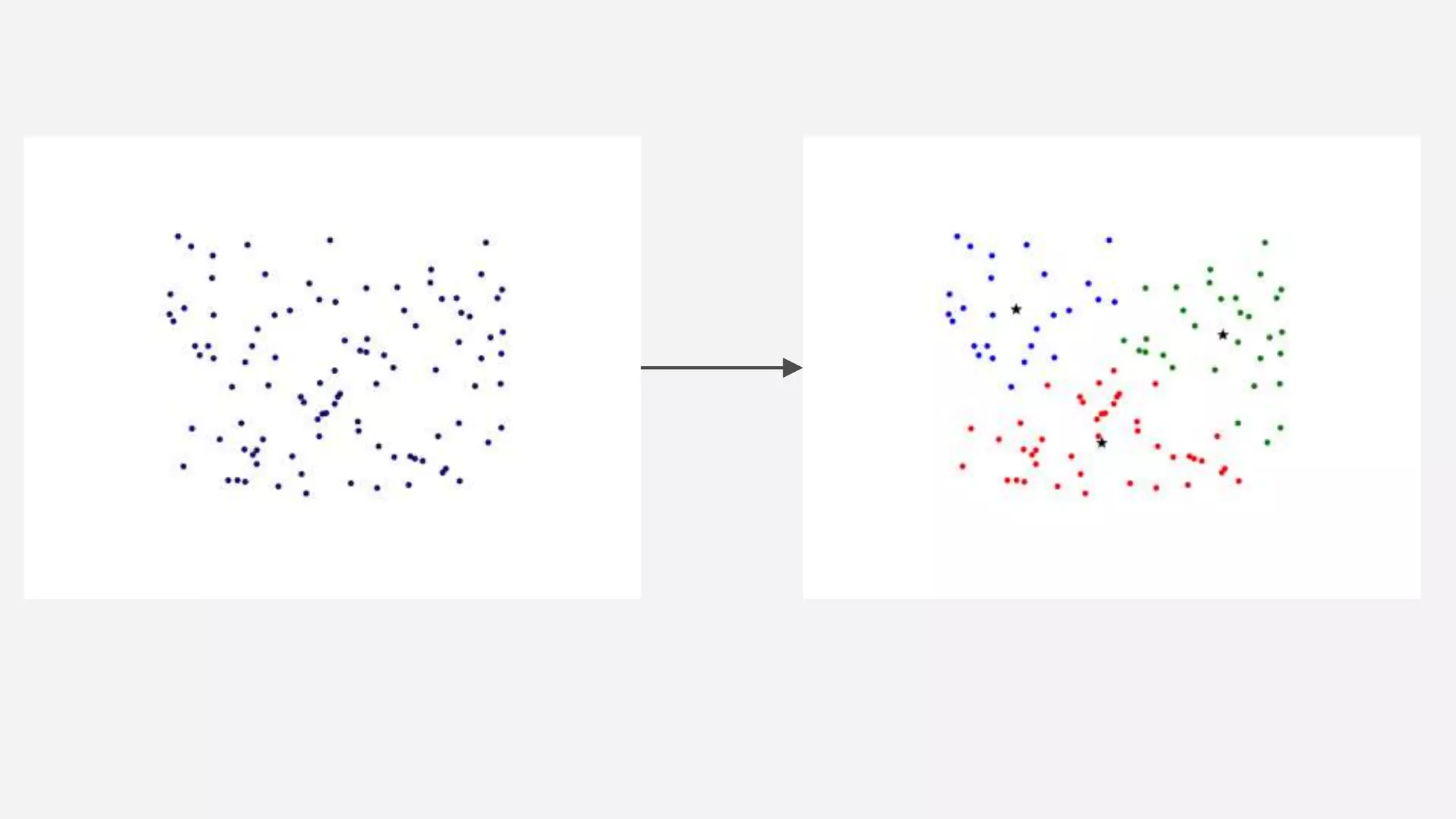
>>> from sklearn import cluster, datasets
>>> iris = datasets.load_iris()
>>> X_iris = iris.data
>>> y_iris = iris.target
>>> k_means = cluster.KMeans(n_clusters=3)
>>> k_means.fit(X_iris)
KMeans(copy_x=True, init='k-means++', ...
>>> print(k_means.labels_[::10])
[1 1 1 1 1 0 0 0 0 0 2 2 2 2 2]
>>> print(y_iris[::10])
[0 0 0 0 0 1 1 1 1 1 2 2 2 2 2]](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-57-2048.jpg)











![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-70-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
start with k randomly chosen points](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-71-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
start with k randomly chosen points
start with no cluster assignments](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-72-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
start with k randomly chosen points
start with no cluster assignments
for each iteration](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-73-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
start with k randomly chosen points
start with no cluster assignments
for each iteration
for each point](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-74-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
start with k randomly chosen points
start with no cluster assignments
for each iteration
for each point
for each mean](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-75-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
start with k randomly chosen points
start with no cluster assignments
for each iteration
for each point
for each mean
compute the distance](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-76-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
start with k randomly chosen points
start with no cluster assignments
for each iteration
for each point
for each mean
compute the distance
assign the point to the cluster of the mean with
the smallest distance](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-77-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
start with k randomly chosen points
start with no cluster assignments
for each iteration
for each point
for each mean
compute the distance
assign the point to the cluster of the mean with
the smallest distance
find the points in each cluster](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-78-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
start with k randomly chosen points
start with no cluster assignments
for each iteration
for each point
for each mean
compute the distance
assign the point to the cluster of the mean with
the smallest distance
find the points in each cluster
and compute the new means](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-79-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
Not impenetrable, but
a lot less helpful than
it could be](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-80-2048.jpg)
![def k_means(points, k, num_iters=10):
means = list(random.sample(points, k))
assignments = [None for _ in points]
for _ in range(num_iters):
# assign each point to closest mean
for i, point_i in enumerate(points):
d_min = float('inf')
for j, mean_j in enumerate(means):
d = sum((x - y)**2
for x, y in zip(point_i, mean_j))
if d < d_min:
d_min = d
assignments[i] = j
# recompute means
for j in range(k):
cluster = [point for i, point in enumerate(points) if assignments[i] ==
j]
means[j] = mean(cluster)
return means
Not impenetrable, but
a lot less helpful than
it could be
Can we make it
simpler?](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-81-2048.jpg)


![def new_means(points, means):
# assign points to clusters
# each cluster is just a list of points
clusters = assign_clusters(points, means)
# return the cluster means
return [mean(cluster)
for cluster in clusters]](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-84-2048.jpg)
![def assign_clusters(points, means):
# one cluster for each mean
# each cluster starts empty
clusters = [[] for _ in means]
# assign each point to cluster
# corresponding to closest mean
for p in points:
index = closest_index(point, means)
clusters[index].append(point)
return clusters](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-85-2048.jpg)
![def closest_index(point, means):
# return index of closest mean
return argmin(distance(point, mean)
for mean in means)
def argmin(xs):
# return index of smallest element
return min(enumerate(xs),
key=lambda pair: pair[1])[0]](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-86-2048.jpg)



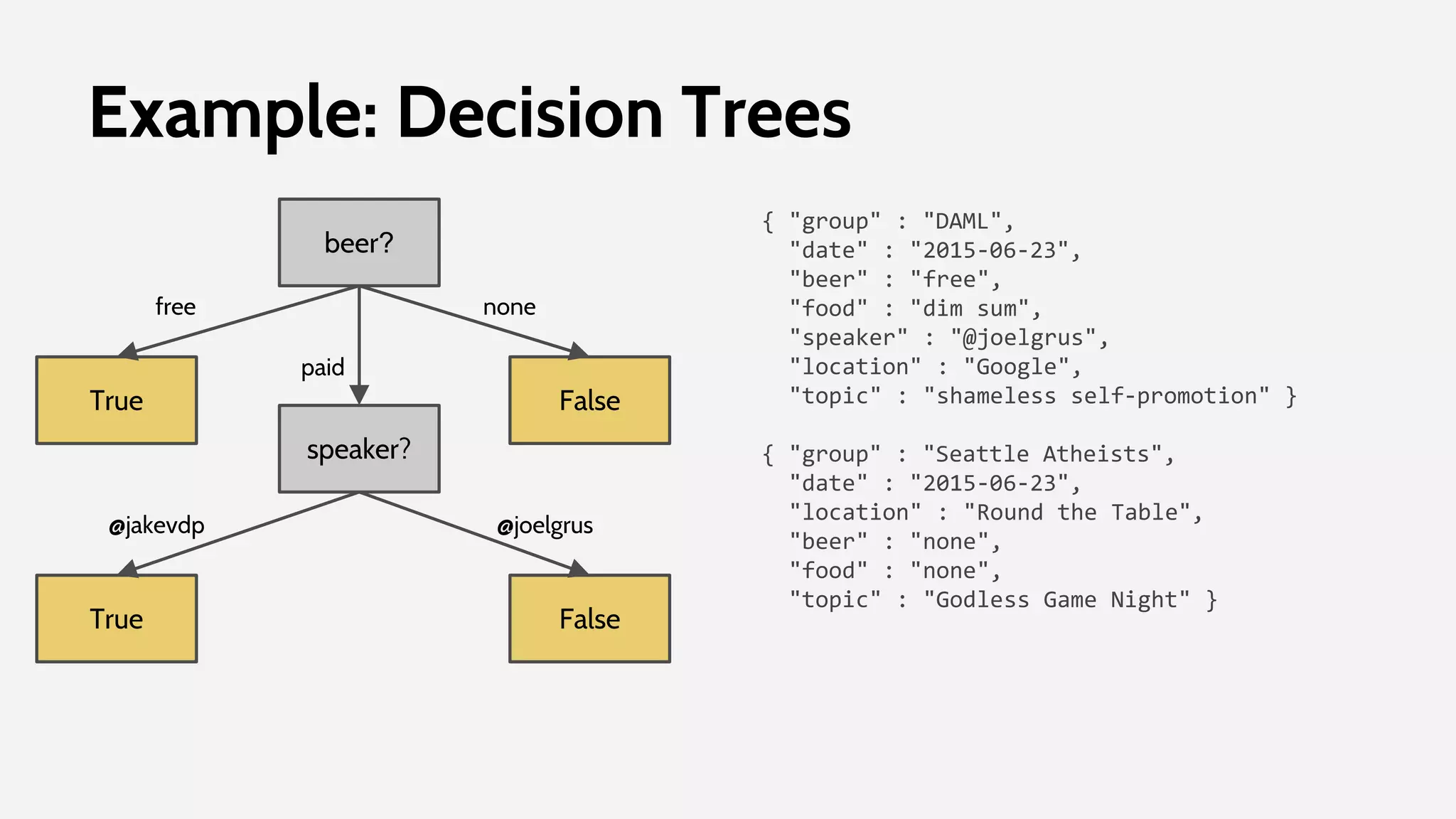
![Example: Decision Trees
class LeafNode:
def __init__(self, prediction):
self.prediction = prediction
def predict(self, input_dict):
return self.prediction
class DecisionNode:
def __init__(self, attribute, subtree_dict):
self.attribute = attribute
self.subtree_dict = subtree_dict
def predict(self, input_dict):
value = input_dict.get(self.attribute)
subtree = self.subtree_dict[value]
return subtree.predict(input)](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-91-2048.jpg)
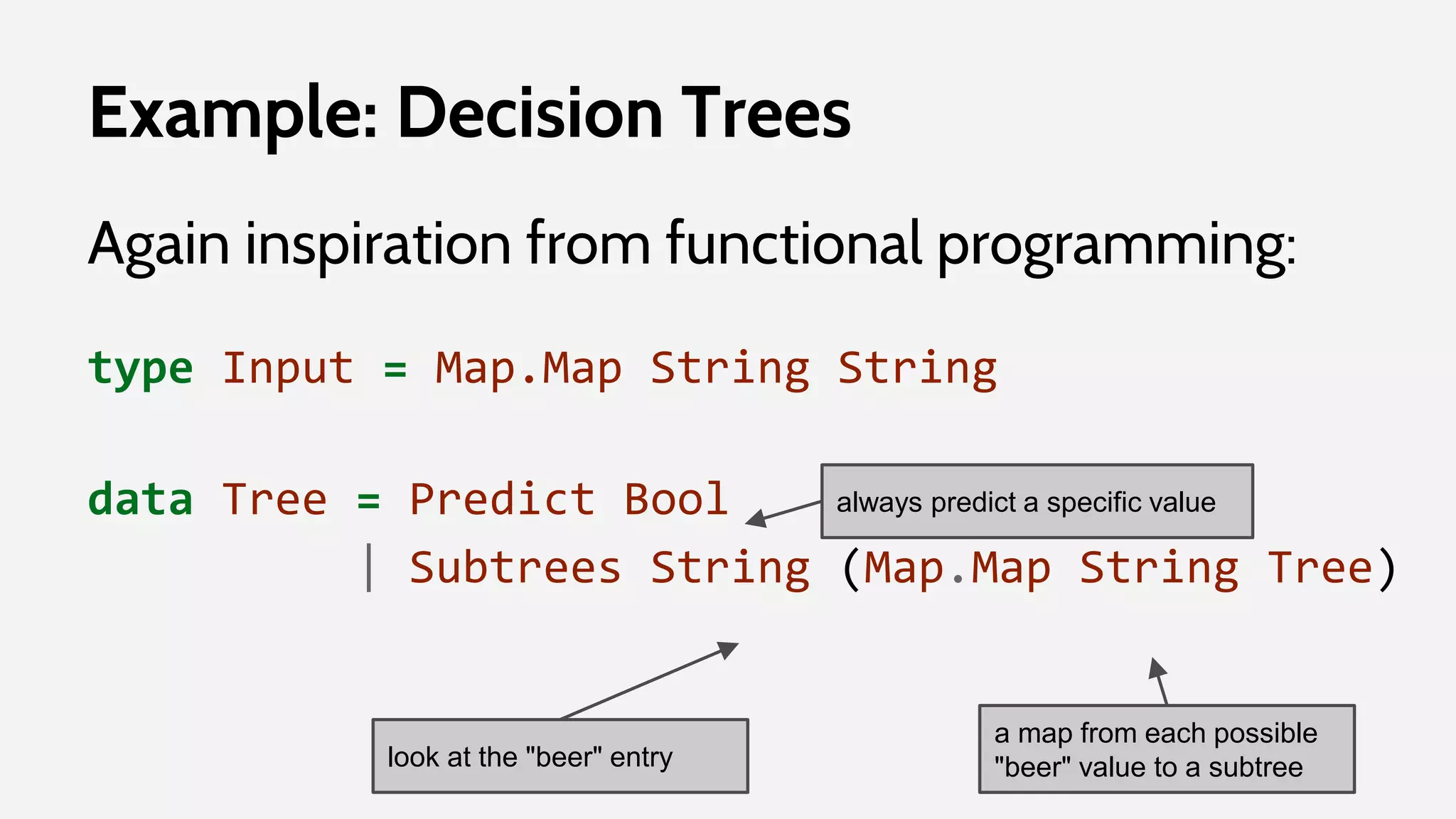

![predict :: Tree -> Input -> Bool
predict (Predict b) _ = b
predict (Subtrees a subtrees) input =
predict subtree input
where subtree = subtrees Map.! (input Map.! a)
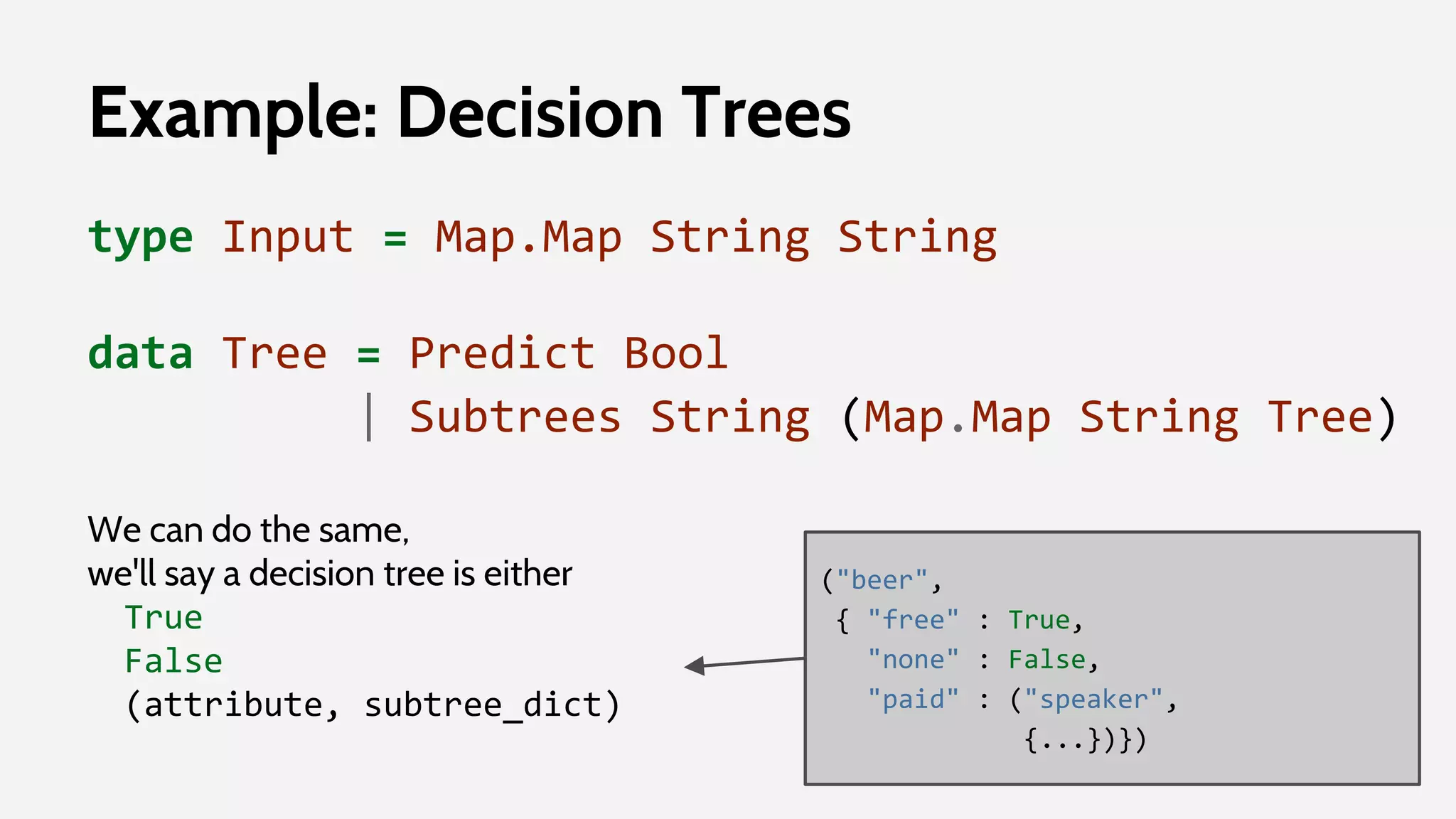
Example: Decision Trees
def predict(tree, input_dict):
# leaf node predicts itself
if tree in (True, False):
return tree
else:
# destructure tree
attribute, subtree_dict = tree
# find appropriate subtree
value = input_dict[attribute]
subtree = subtree_dict[value]
# classify using subtree
return predict(subtree, input_dict)](https://image.slidesharecdn.com/daml-150908205332-lva1-app6892/75/The-Road-to-Data-Science-Joel-Grus-June-2015-95-2048.jpg)






































































![Seller Deck - Presentation [Concert L2].PPTX](https://cdn.slidesharecdn.com/ss_thumbnails/sellerdeck-presentationconcertl2-251219171156-24982daf-thumbnail.jpg?width=640&height=640&fit=bounds)














