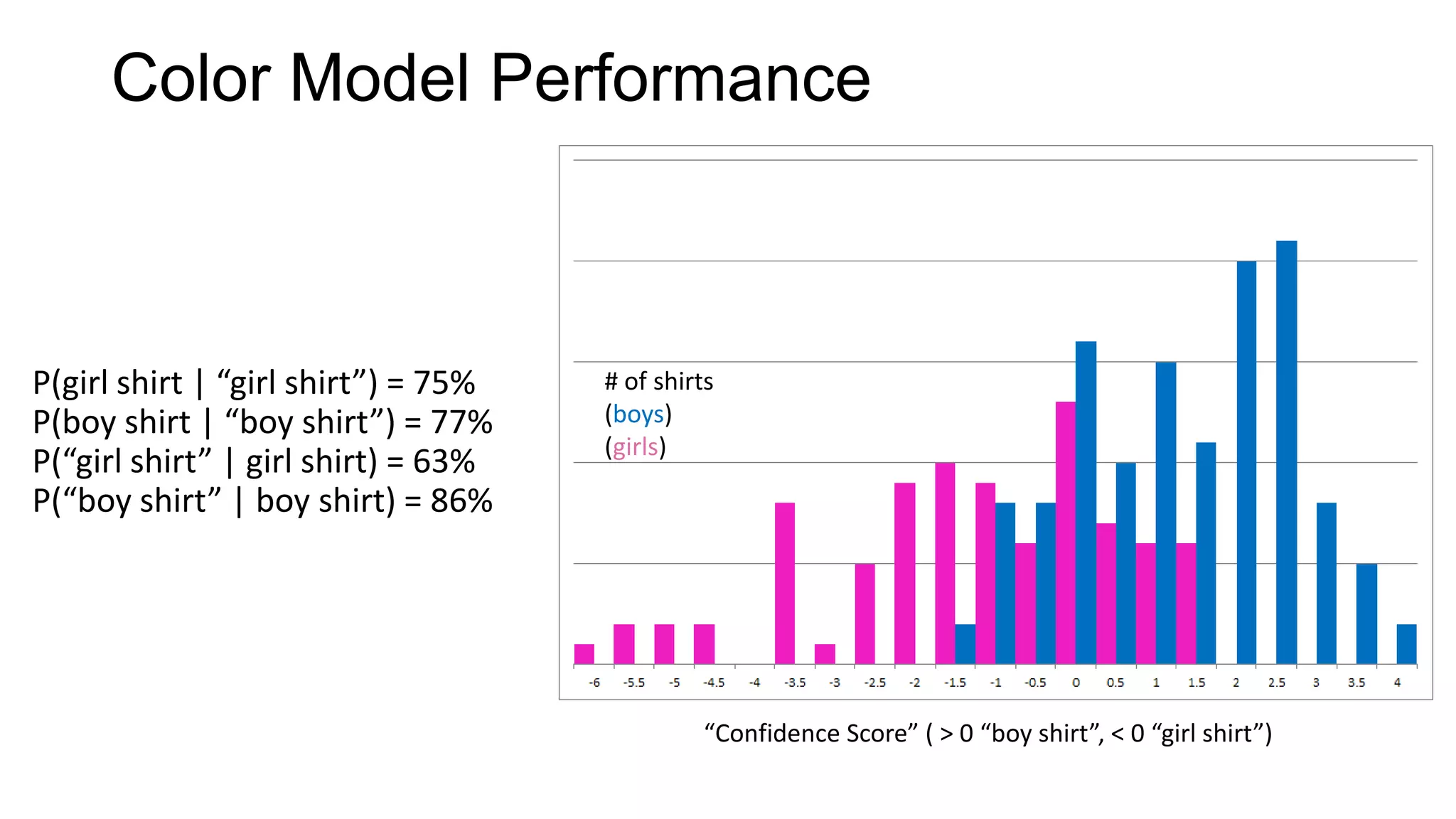
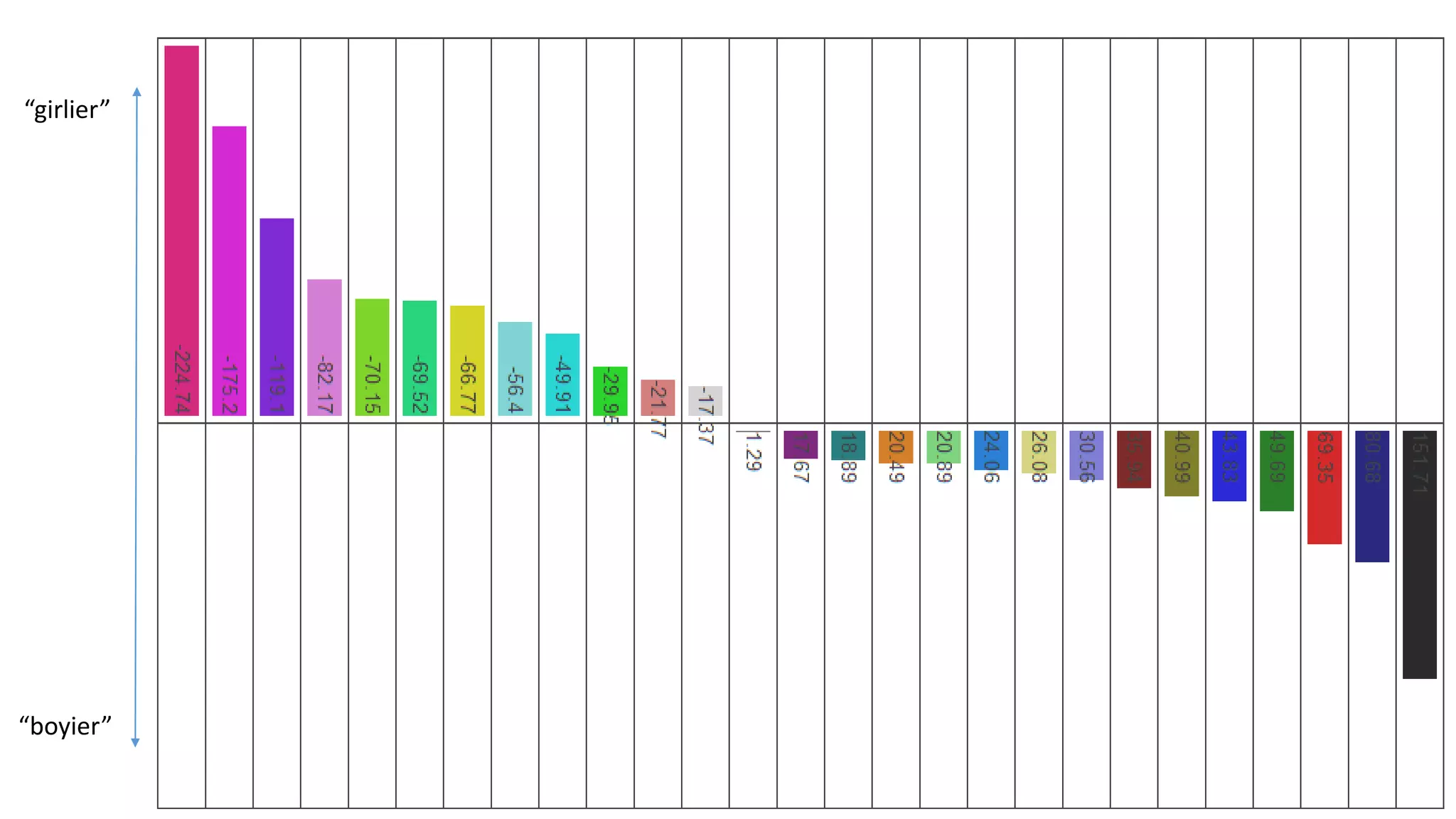
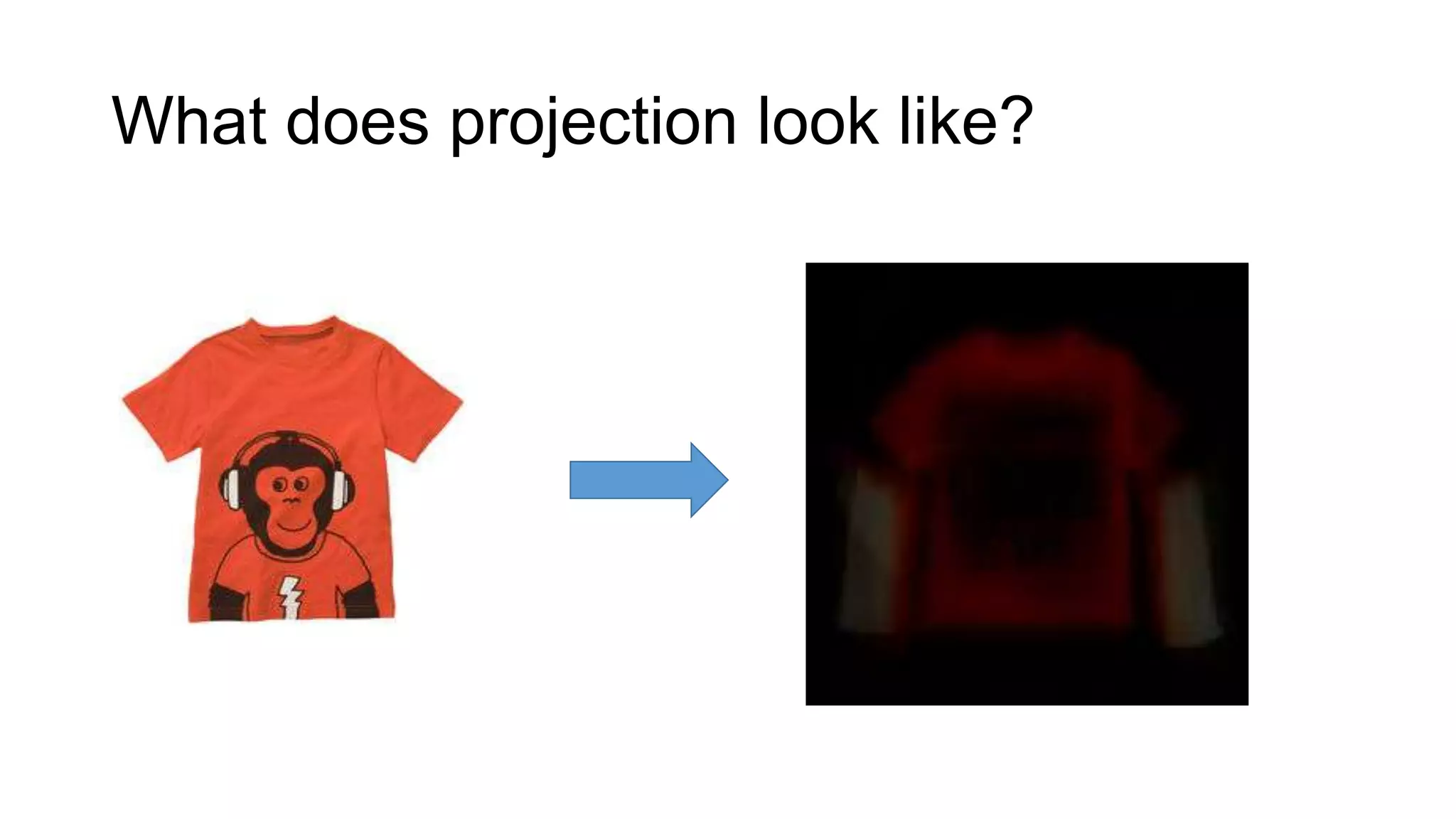
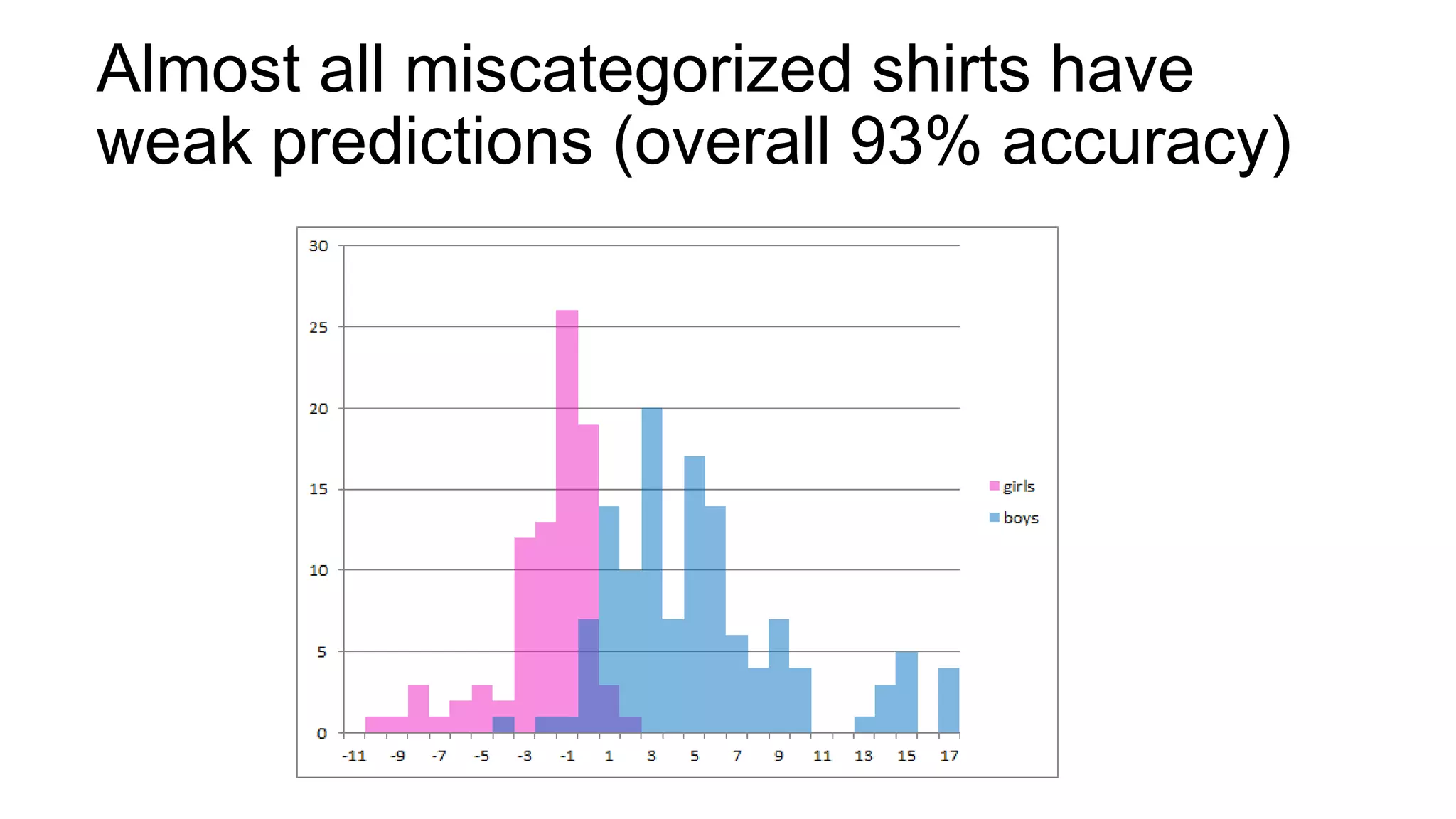
Joel Grus built models to predict whether a toddler shirt is for a boy or girl based solely on images. His first model used color features, achieving 75-77% accuracy. His second model performed dimensionality reduction to find the most informative "eigenshirt" dimensions in the image space, projecting shirts into a 10-dimensional subspace and achieving 93% accuracy. Future work could analyze text on shirts or make images a uniform size/background to improve predictions.













![T shirt%20 designs%20pro-forma(1)[1]](https://cdn.slidesharecdn.com/ss_thumbnails/t-shirt20designs20pro-forma11-130515100310-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



























