Downloaded 97 times

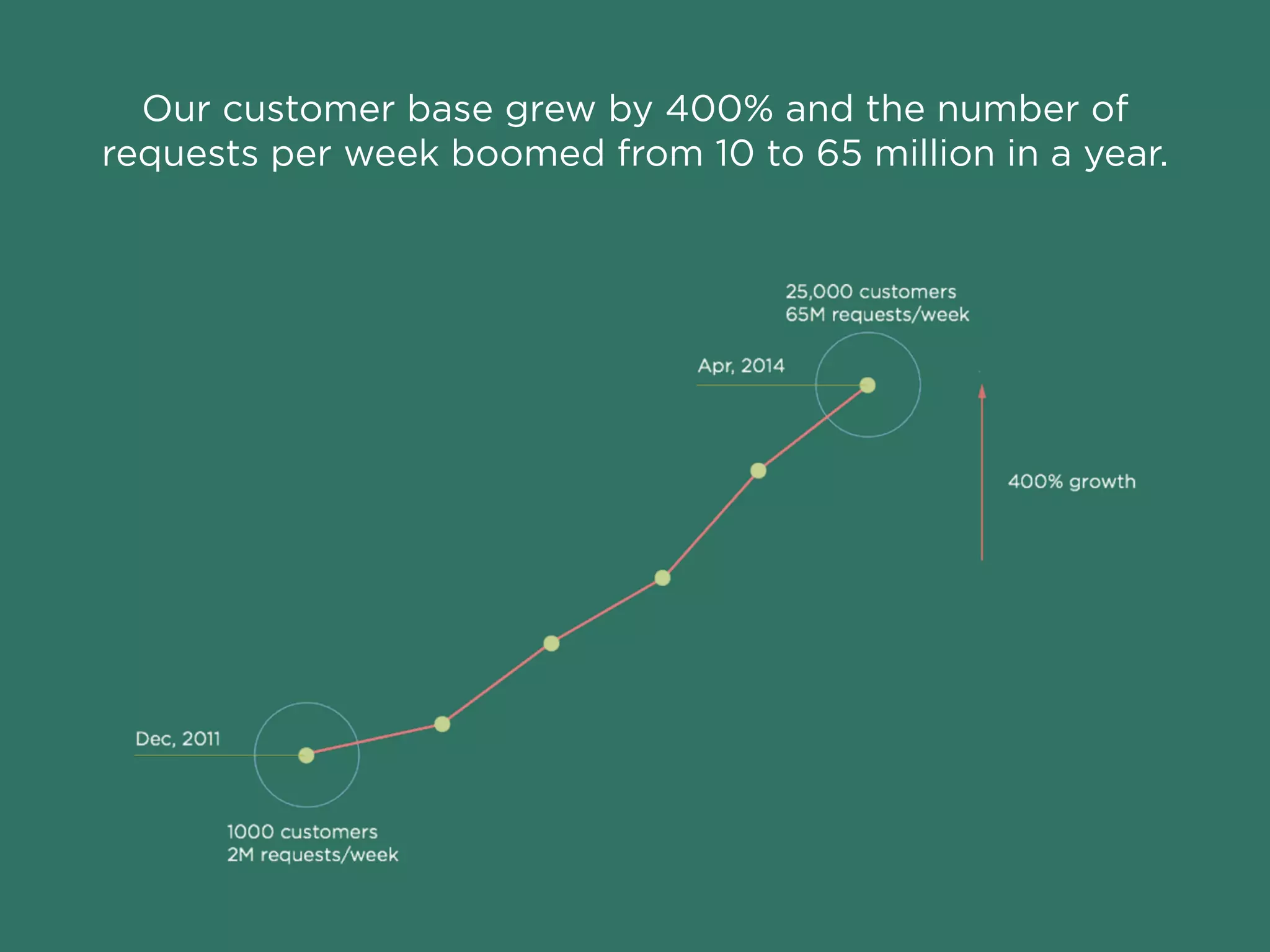















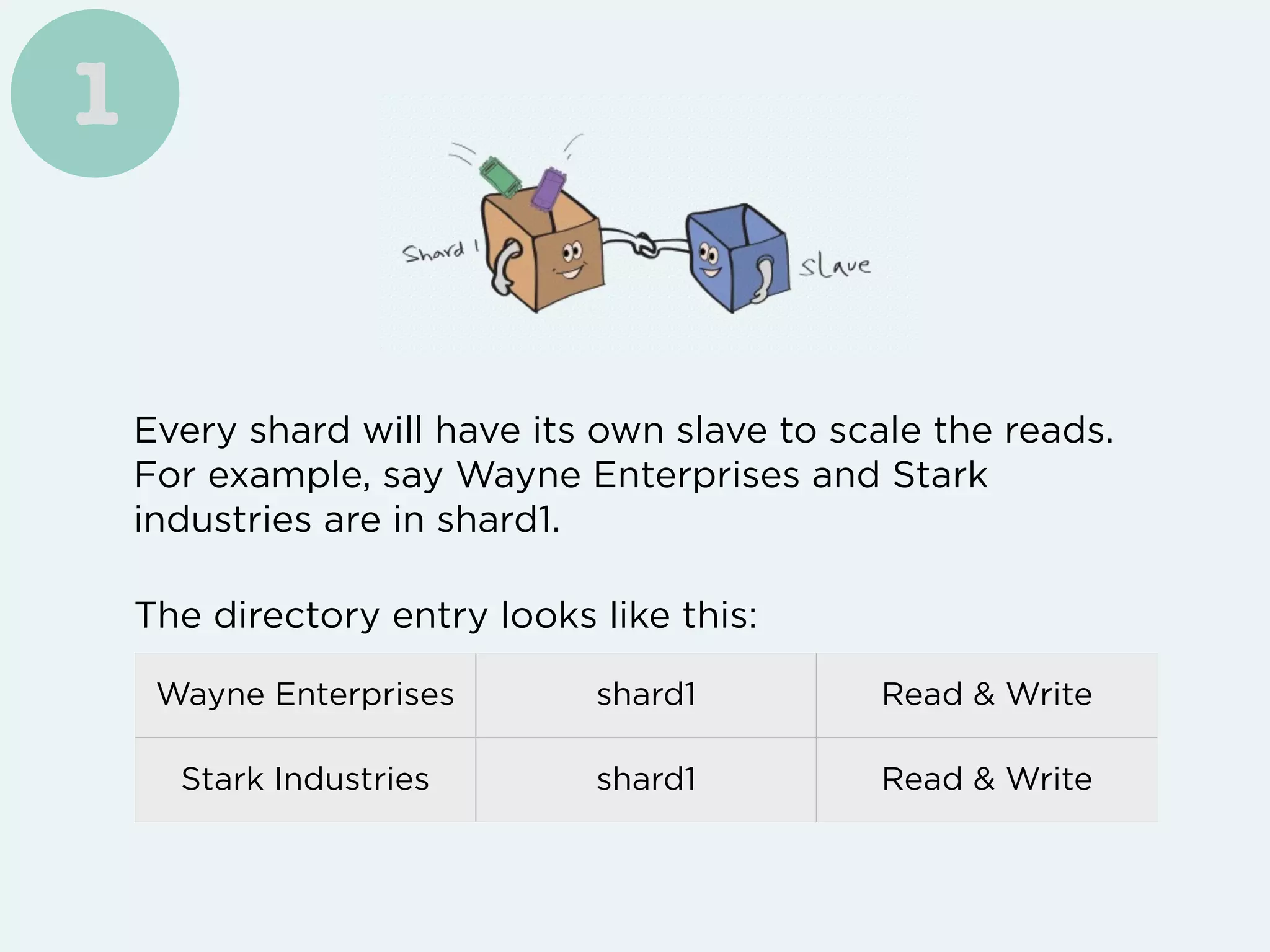

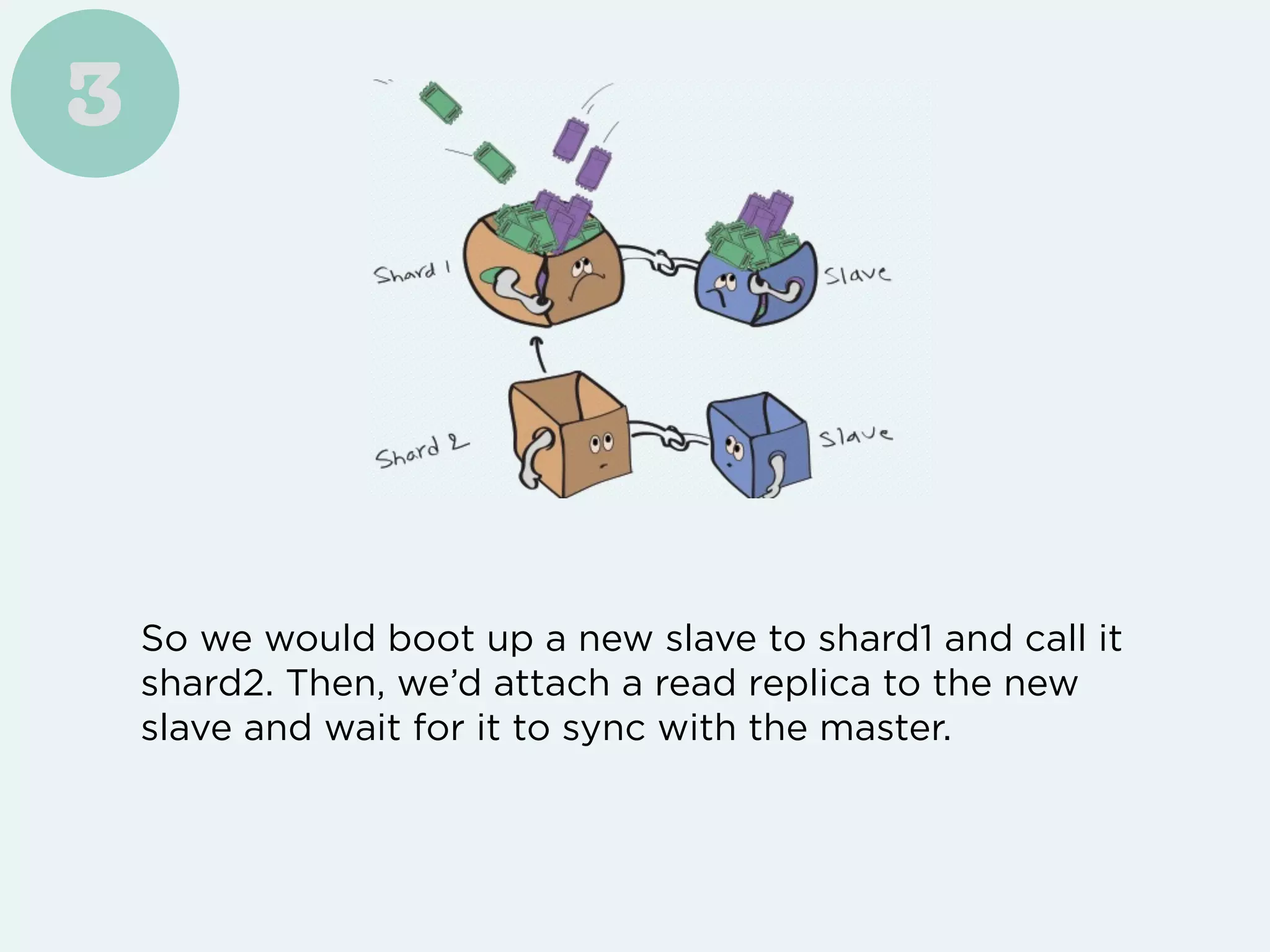


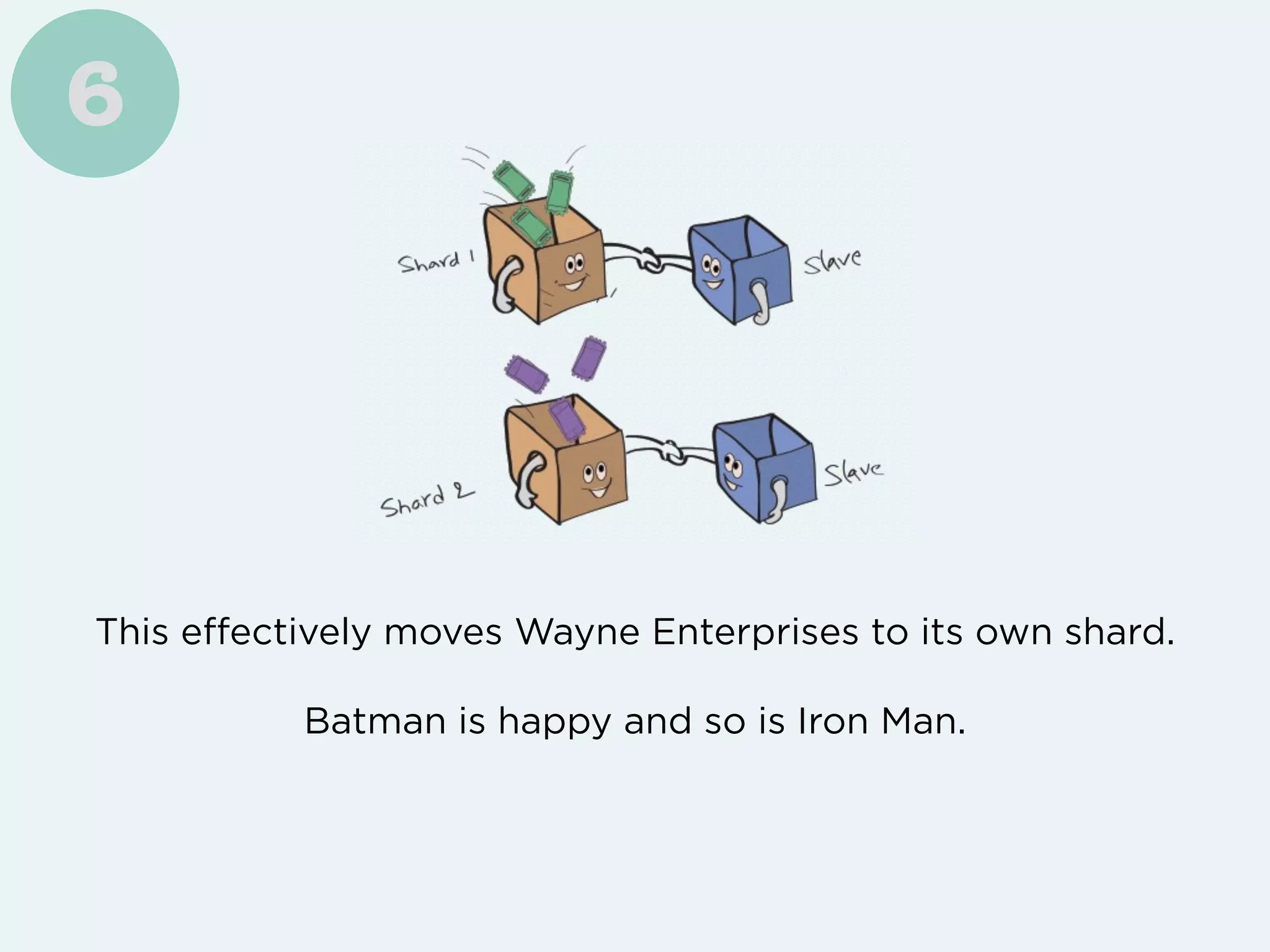




Freshdesk saw their customer base and support requests grow exponentially, requiring them to implement several techniques like vertical scaling, database partitioning, caching, and distributed functions to handle the increased load. However, to truly scale their write performance beyond a single database instance size, they ultimately had to implement directory-based horizontal sharding across multiple database instances.
























































































