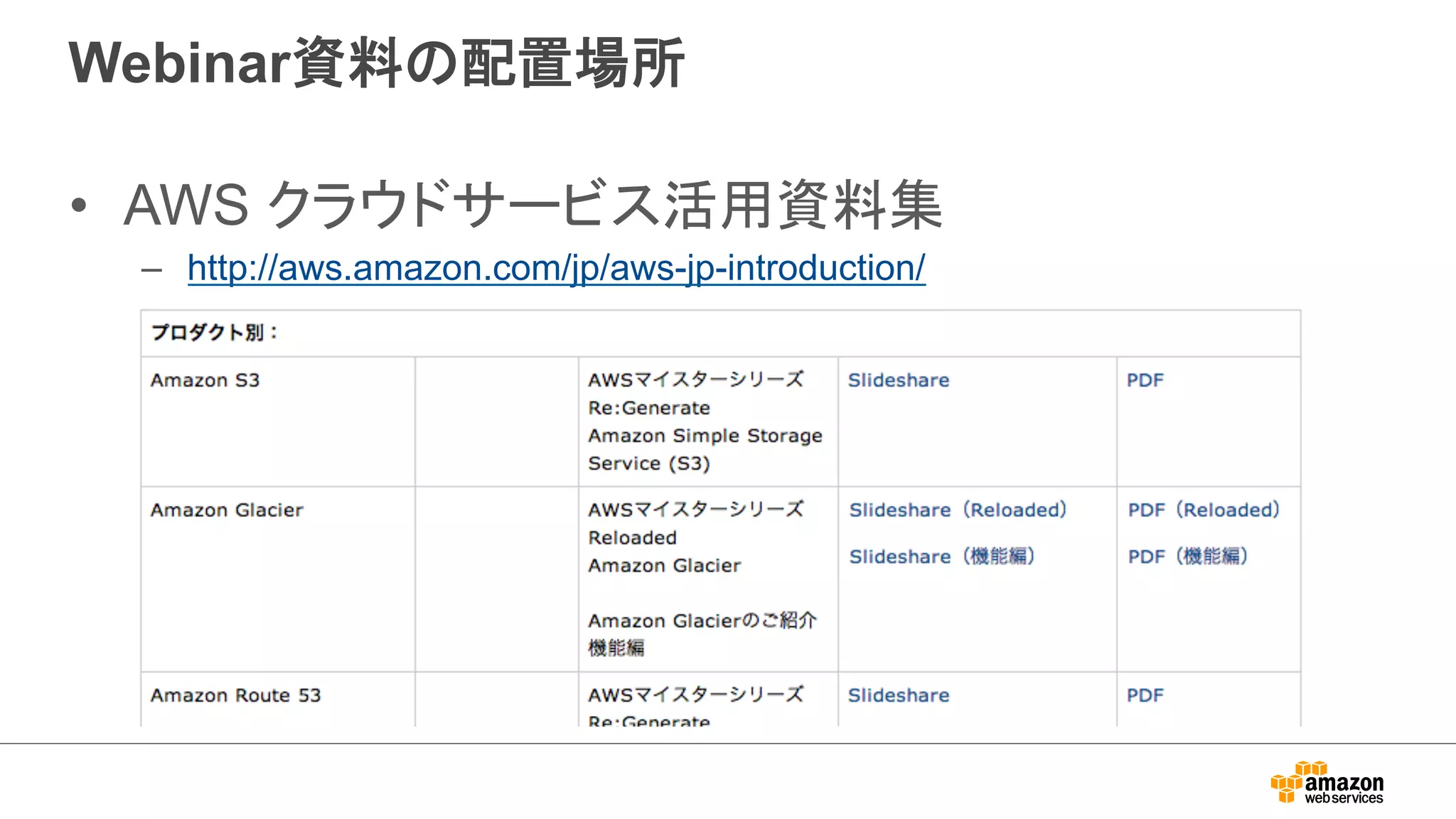
Hive 0.13 Support
• Hive12より、1000個以上の新機能、改善やバッグフィックスが追加され
ています
• パフォーマンスの向上
– Hive12より、数倍のパフォーマンス向上が期待できます
• Sub queryのサポート
SELECT * FROM A
WHERE EXISTS (
SELECT null
FROM B
WHERE B.id = A.id
AND B.date '2009-10-01')
SELECT key FROM t1
GROUP BY key
HAVING COUNT(value) IN (
SELECT p FROM t2);
Sub queryサポートの例
http://hortonworks.com/blog/announcing-apache-hive-0-13-completion-stinger-initiative/
17.
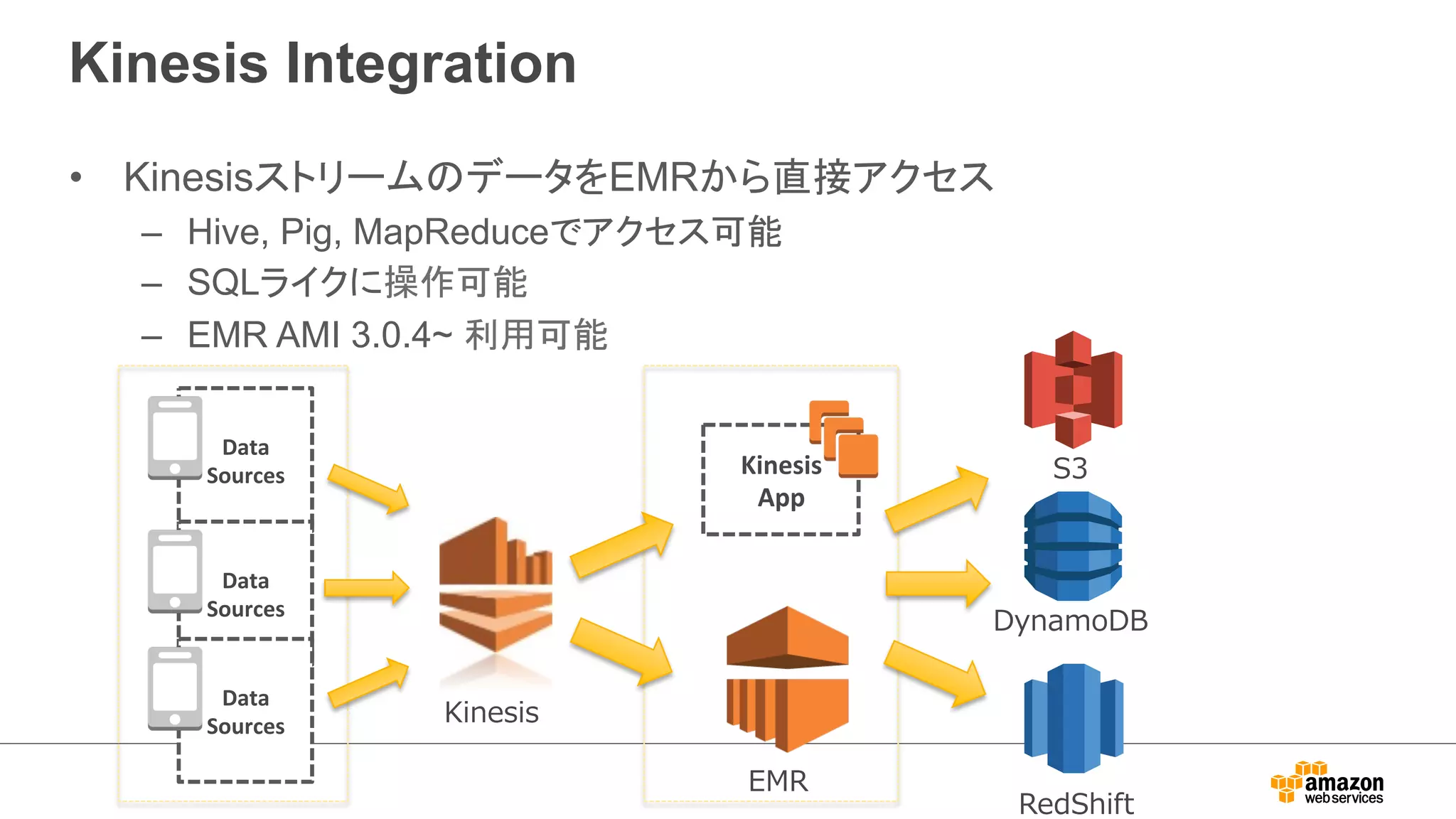
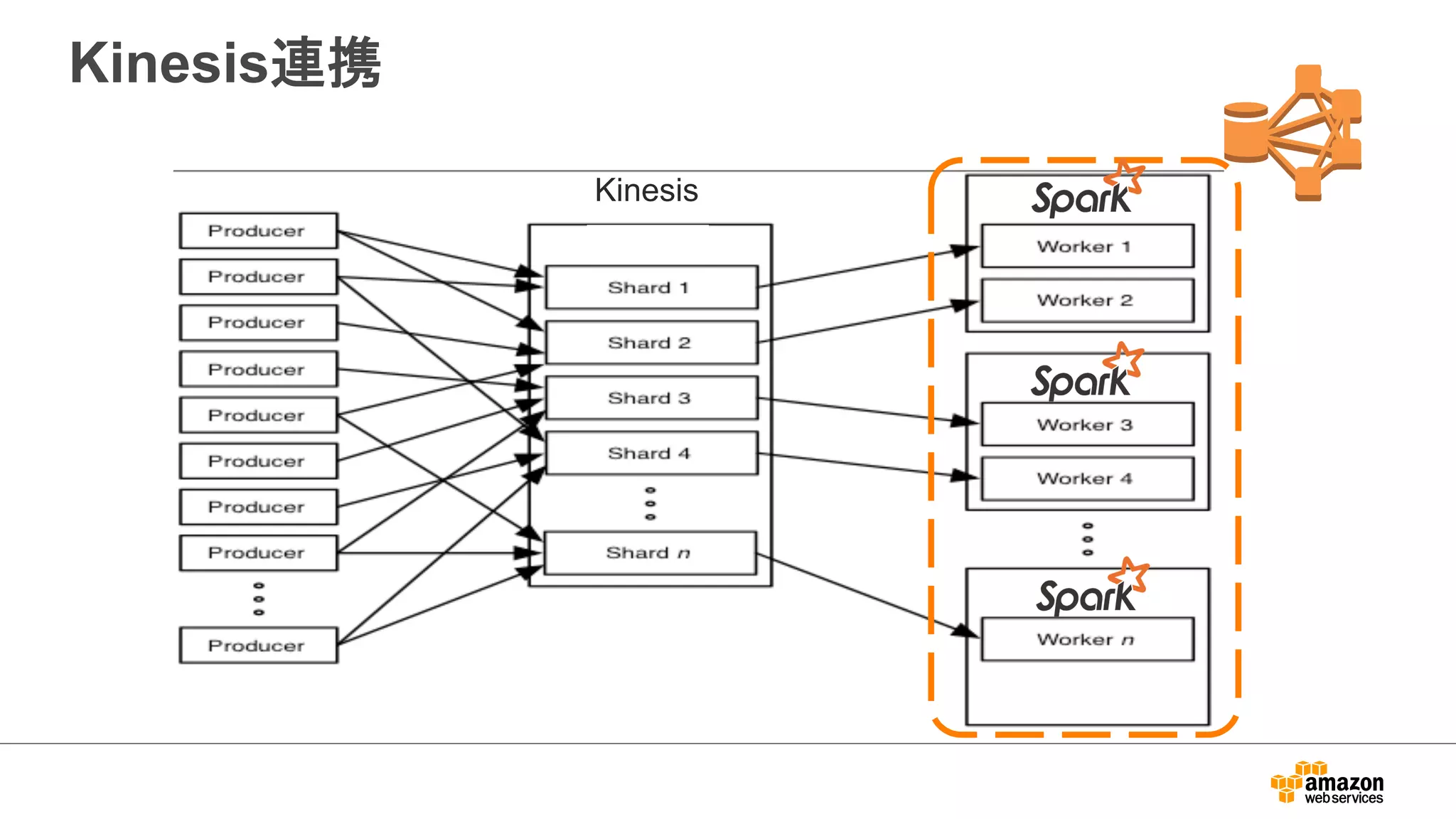
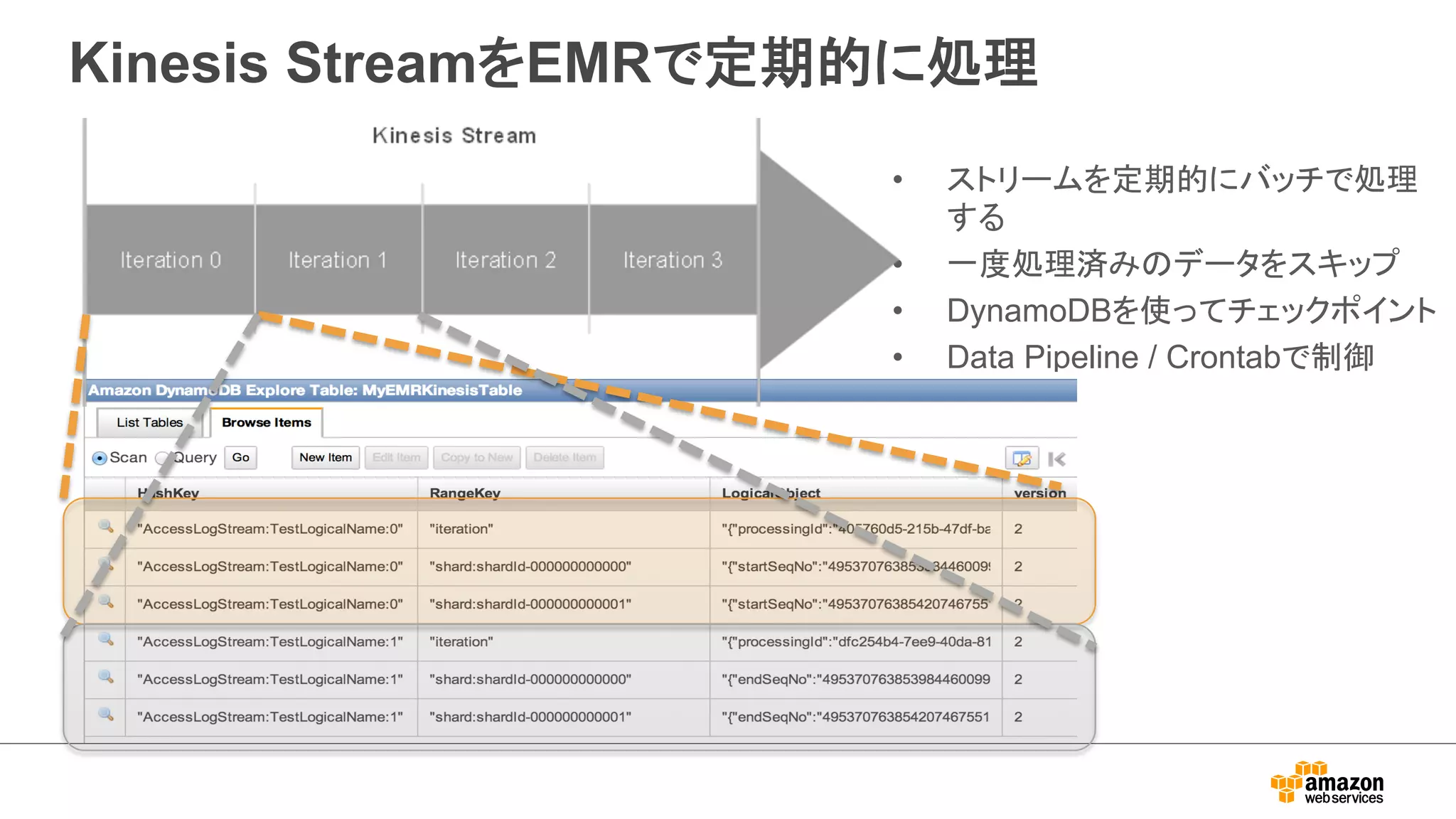
Kinesis Integration
•KinesisストリームのデータをEMRから直接アクセス
– Hive, Pig, MapReduceでアクセス可能
– SQLライクに操作可能
– EMR AMI 3.0.4~ 利用可能
Data
Sources
Data
Sources
Data
Sources
RedShift
Kinesis
S3
App
DynamoDB
Kinesis
EMR
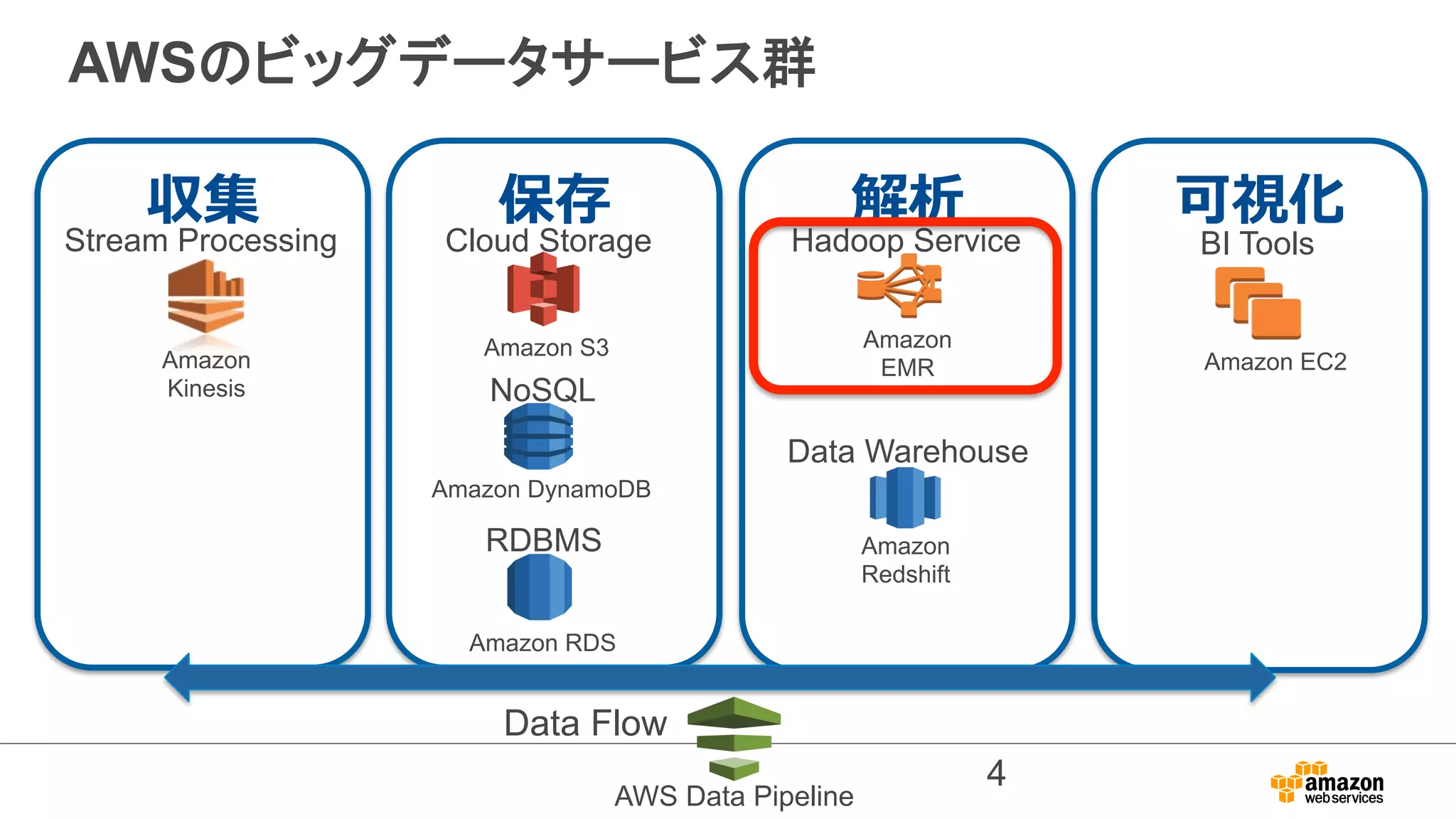
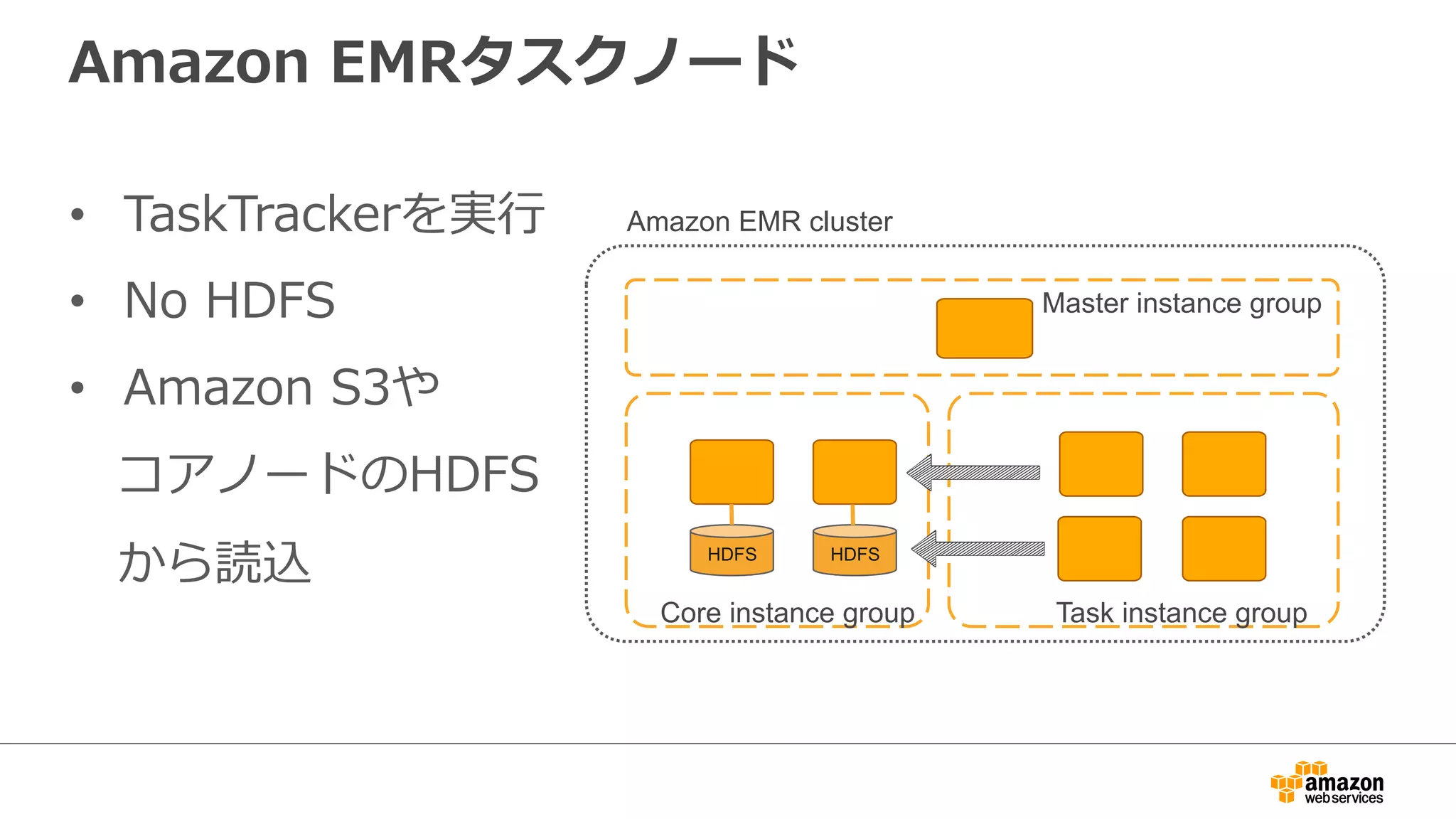
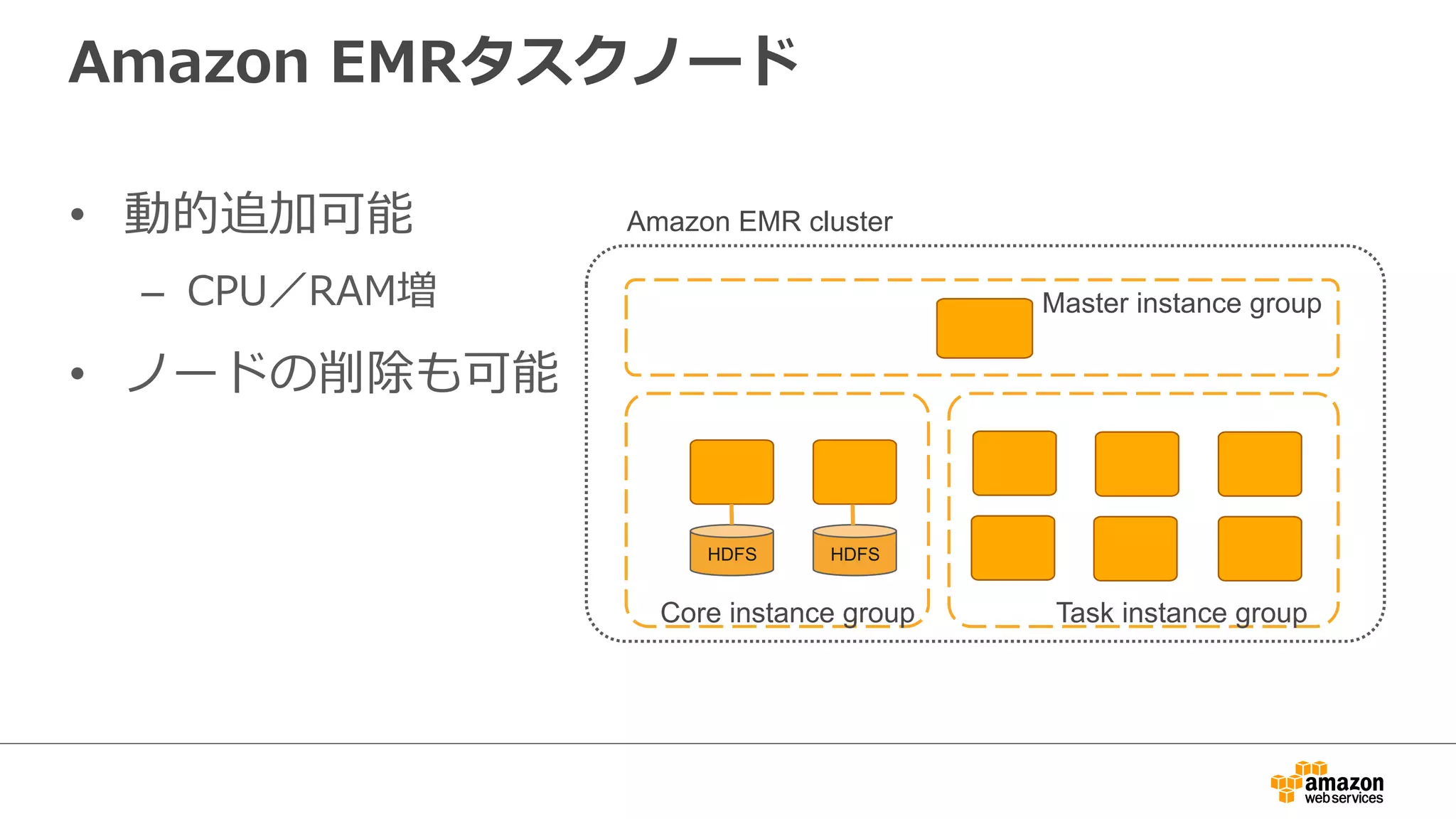
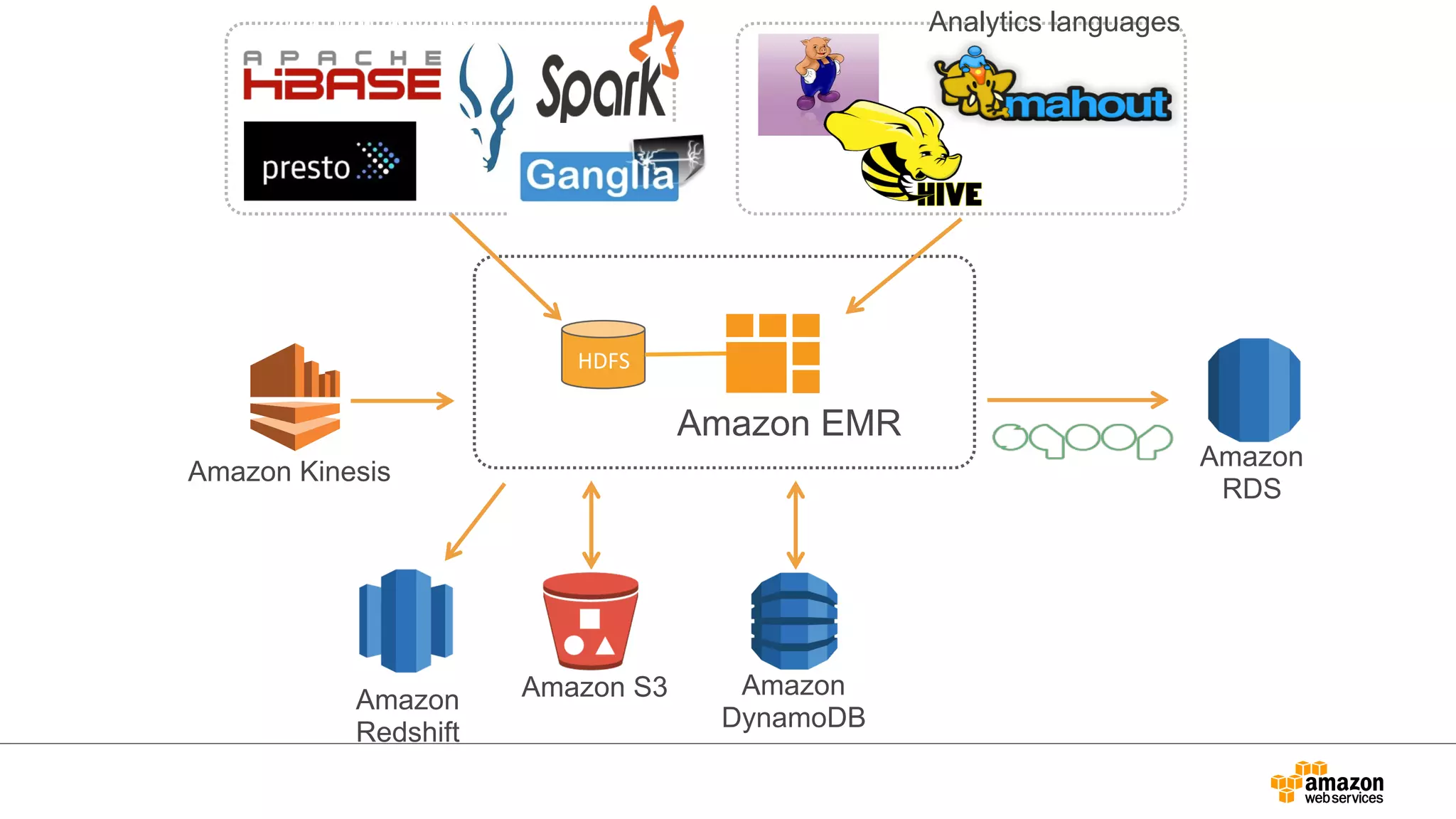
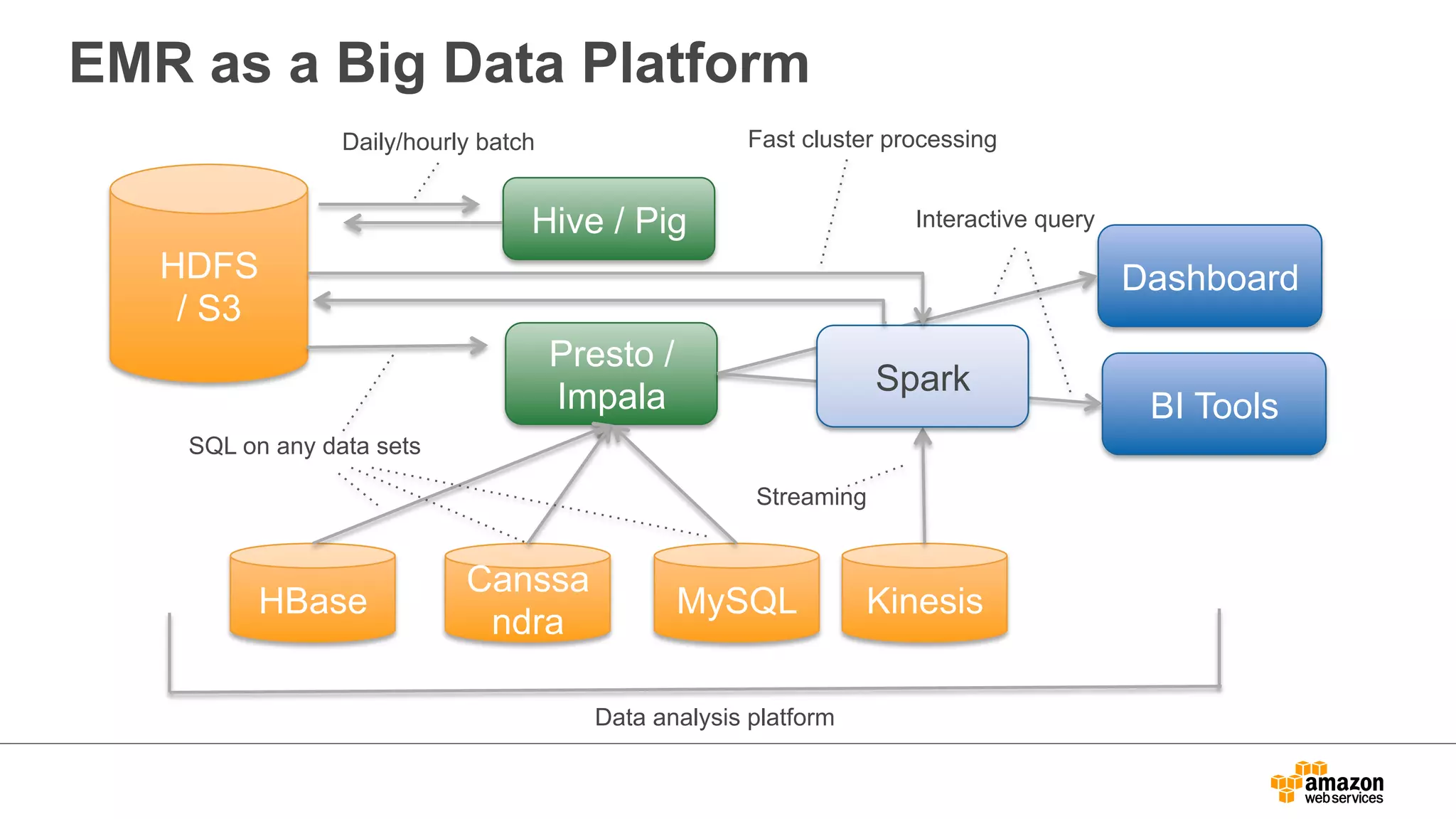
EMR as aBig Data Platform
Daily/hourly batch
Hive / Pig
Presto /
Impala
Dashboard
BI Tools
HDFS
/ S3
HBase Canssa
Fast cluster processing
Interactive query
ndra MySQL Kinesis
SQL on any data sets
Streaming
Spark
Data analysis platform
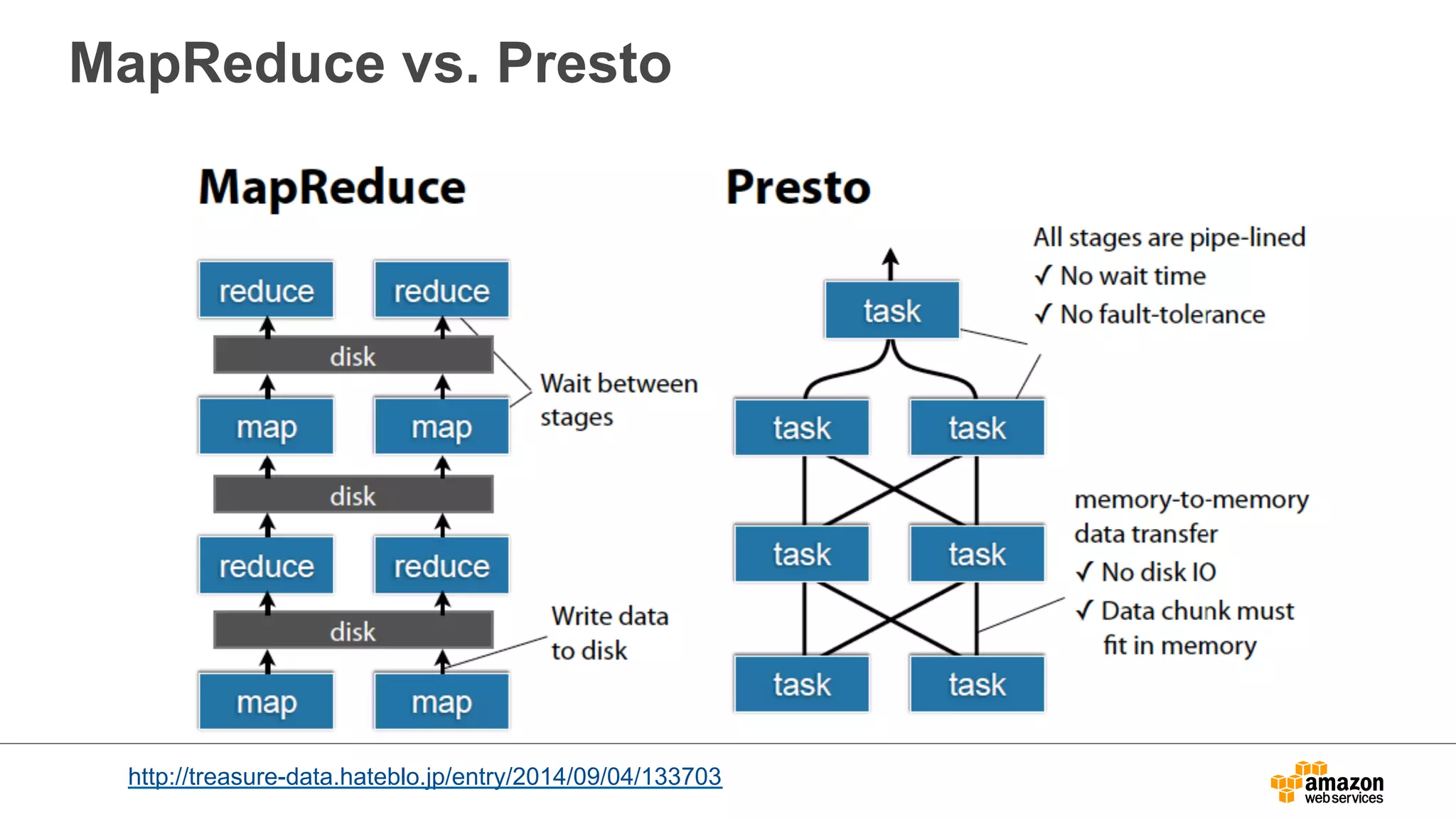
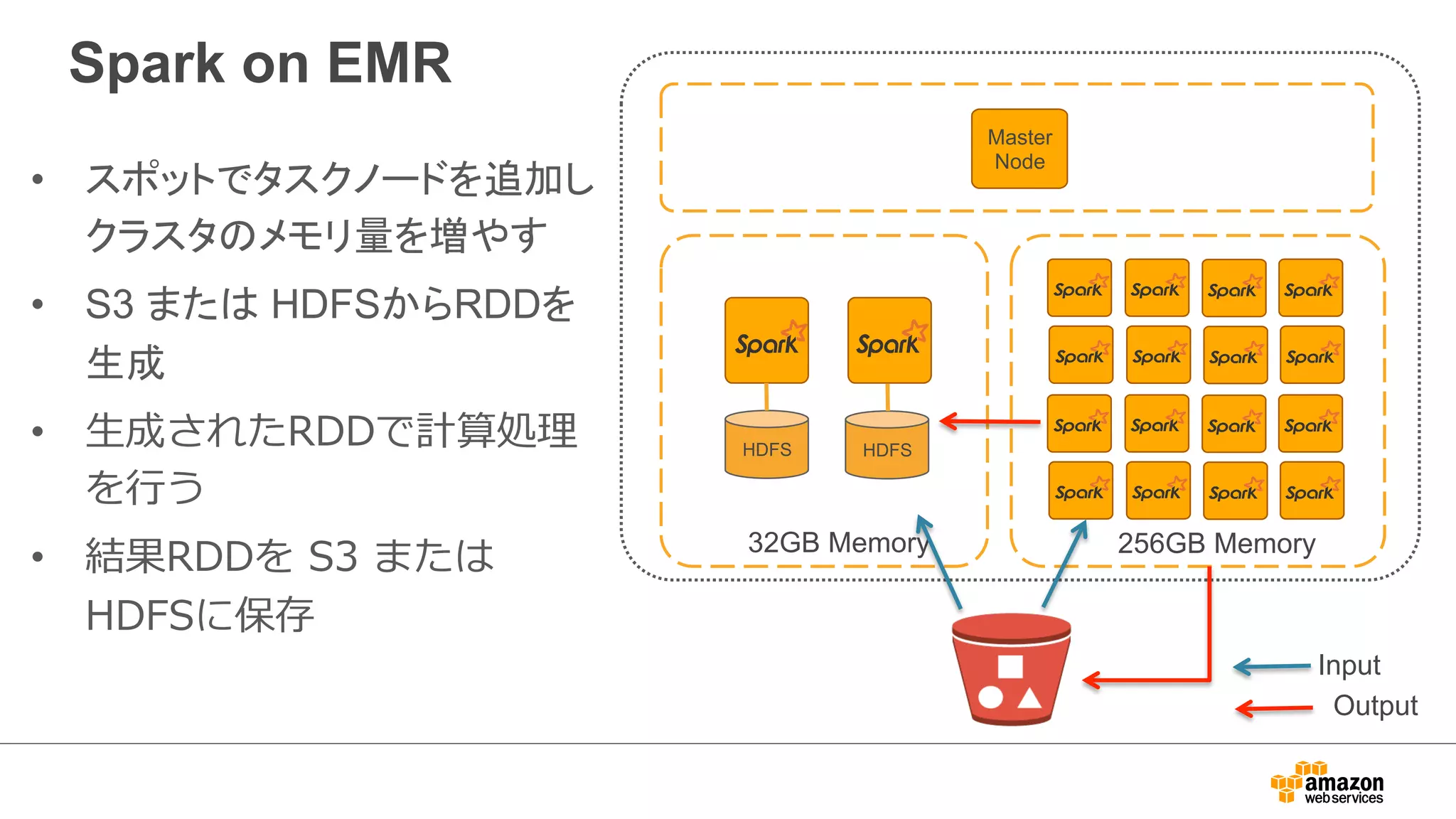
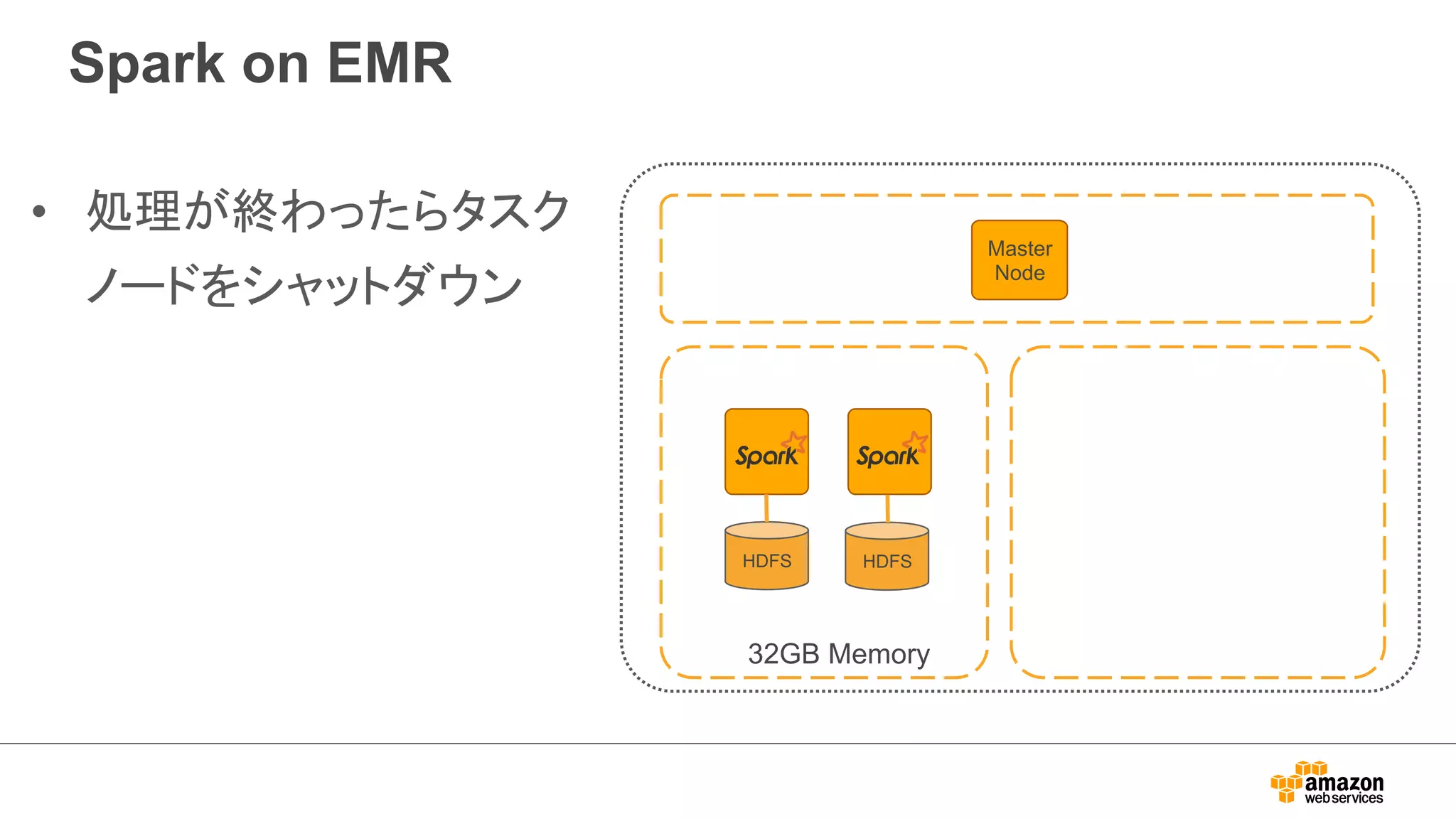
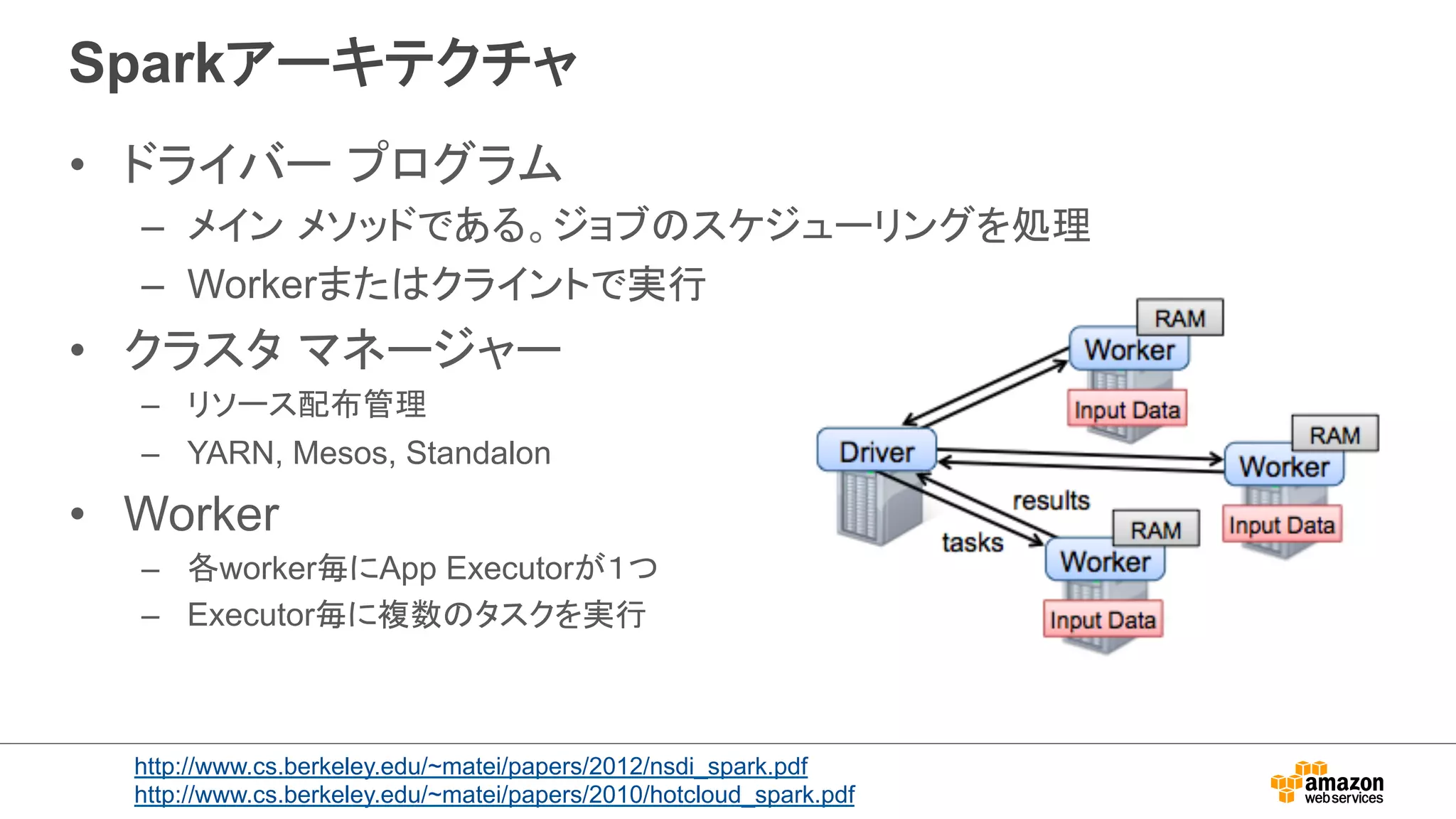
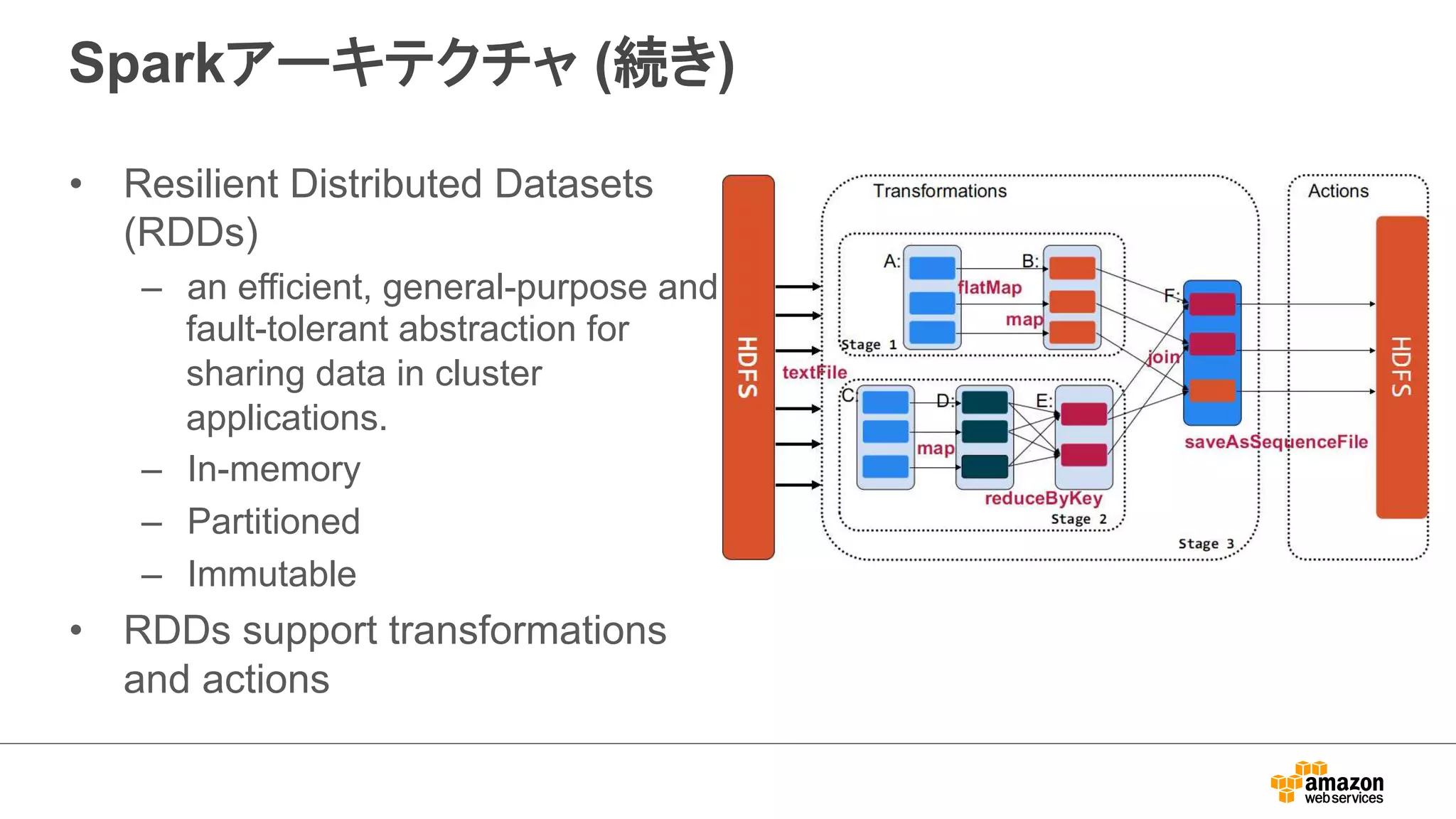
Sparkアーキテクチャ (続き)
•Resilient Distributed Datasets
(RDDs)
– an efficient, general-purpose and
fault-tolerant abstraction for
sharing data in cluster
applications.
– In-memory
– Partitioned
– Immutable
• RDDs support transformations
and actions









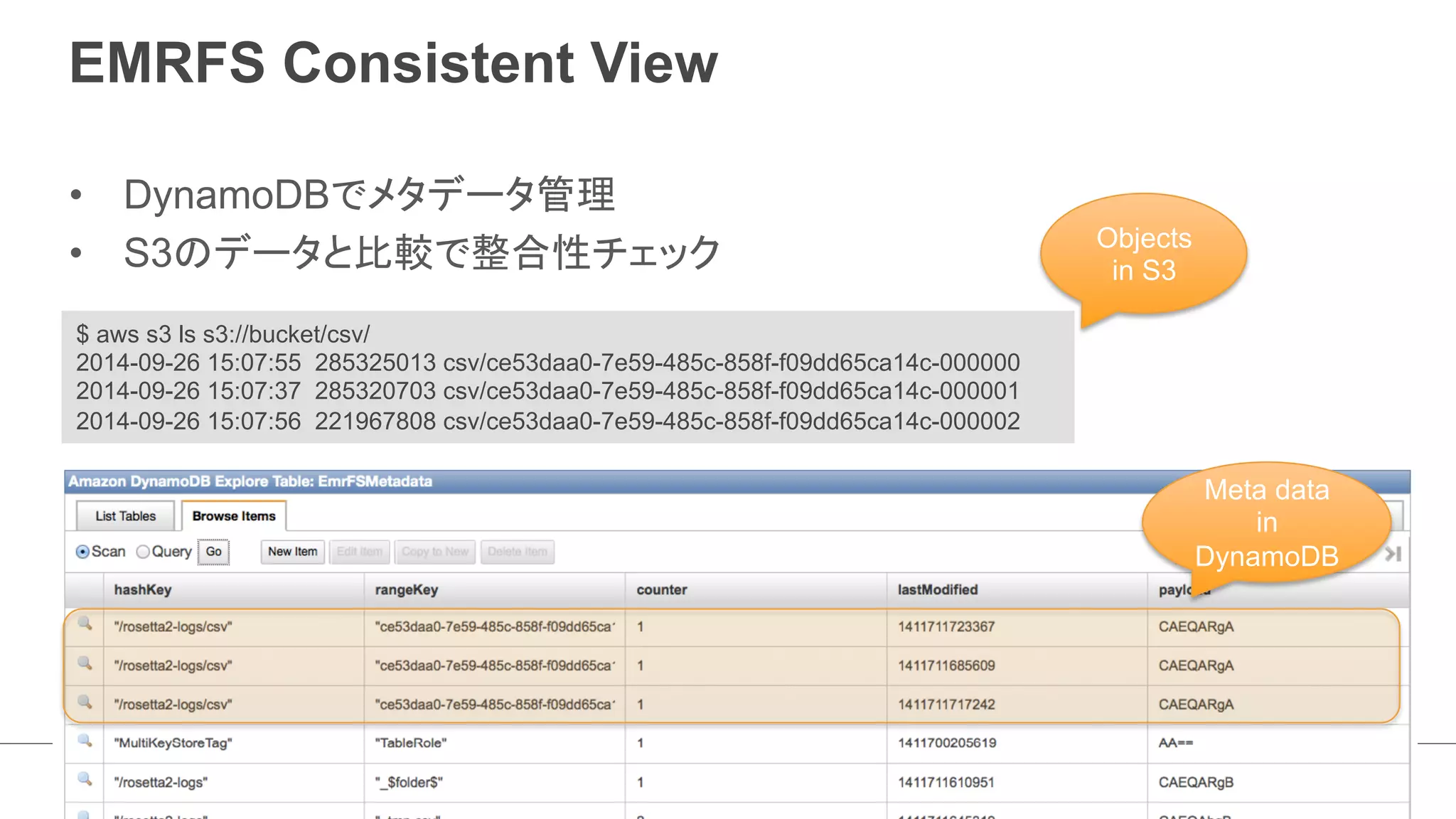
![EMRFS Consistent View
• Emrfs コマンドでファイル操作
– EMRFSが管理するファイルの整合性を保つため
$ emrfs --help
emrfs 1.0
Usage: emrfs [describe-metadata|set-metadata-capacity|delete-metadata|create-metadata|list-metadata-stores|diff|
delete|sync|import] [options] args...
• 直接S3でファイルを追加・削除された場合不整合が発生
$ aws s3 rm s3://bucket/csv/528235e6-322a-4e29-bed3-ac937f713584-000000
Directly
delete in
hive select * from apache_logs_csv limit 10;
S3
OK
Failed with exception java.io.IOException:com.amazon.ws.emr.hadoop.fs.consistency.exception.ConsistencyException: 1
items inconsistent (no s3 object for associated metadata item). First object: /bucket/csv/528235e6-322a-4e29-bed3-
ac937f713584-000000
Time taken: 0.06 seconds
ConsistencyEx
ception発生](https://image.slidesharecdn.com/20141001-aws-blackbelt-emr-public-141001061957-phpapp02/75/AWS-Black-Belt-Tech-Amazon-EMR-22-2048.jpg)










![小さいファイルの扱い
S3DistCpサンプル
./elastic-mapreduce --jobflow j-3GY8JC4179IOK --jar
/home/hadoop/lib/emr-s3distcp-1.0.jar
--args '--src,s3://myawsbucket/cf,
--dest,s3://myawsbucket/combined,
--groupBy,.*XABCD12345678.([0-9]+-[0-9]+-[0-9]+-[0-9]+).*,
--targetSize,1024,
--outputCodec,lzo,--deleteOnSuccess’](https://image.slidesharecdn.com/20141001-aws-blackbelt-emr-public-141001061957-phpapp02/75/AWS-Black-Belt-Tech-Amazon-EMR-36-2048.jpg)



























































![[AWSマイスターシリーズ] Amazon Elastic MapReduce (EMR)](https://cdn.slidesharecdn.com/ss_thumbnails/20130925aws-meister-regenerate-emrpublic-130926030316-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)







![[JAWSBigData#11]Cloudera on AWSと Amazon EMRを両方本番運用し 3つの観点から比較してみる](https://cdn.slidesharecdn.com/ss_thumbnails/dljawsbigdata11clouderaonawsamazonemr3-180207013607-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[20220126] JAWS-UG 2022初頭までに葬ったAWSアンチパターン大紹介](https://cdn.slidesharecdn.com/ss_thumbnails/20220126-anti-220126190603-thumbnail.jpg?width=640&height=640&fit=bounds)
