Downloaded 17 times










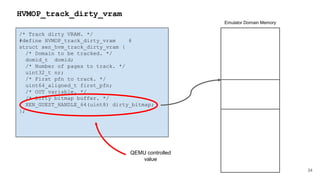

![41
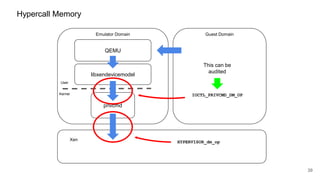
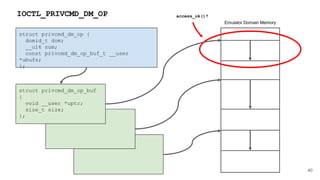
HYPERVISOR_dm_op
HYPERVISOR_dm_op(domid_t domid,
unsigned int nr_bufs,
xen_dm_op_buf_t bufs[]);
struct xen_dm_op_buf {
XEN_GUEST_HANDLE(void) h;
xen_ulong_t size;
};
Emulator Domain Memory
Operation information](https://image.slidesharecdn.com/qemuandxenreducingtheattacksurface-180629142157/85/XPDDS18-Qemu-and-Xen-Reducing-the-attack-surface-Paul-Durrant-Citrix-41-320.jpg)


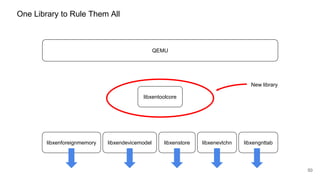
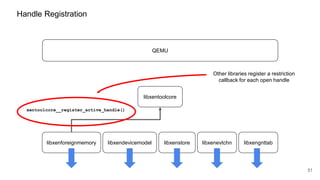
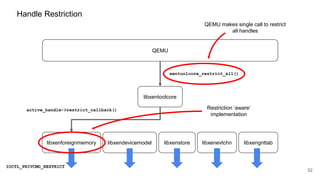
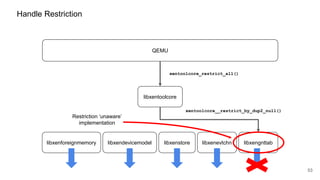


![56
[pauldu@brixham:~]/usr/local/lib/xen/bin/qemu-system-i386 --help
.
.
.
-runas user change to user id user just before starting the VM
.
.
.
QEMU Command Line](https://image.slidesharecdn.com/qemuandxenreducingtheattacksurface-180629142157/85/XPDDS18-Qemu-and-Xen-Reducing-the-attack-surface-Paul-Durrant-Citrix-56-320.jpg)
![57
[pauldu@brixham:~]/usr/local/lib/xen/bin/qemu-system-i386 --help
.
.
.
-runas user change to user id user just before starting the VM
.
.
.
Not actually a UID
but a user name
QEMU Command Line](https://image.slidesharecdn.com/qemuandxenreducingtheattacksurface-180629142157/85/XPDDS18-Qemu-and-Xen-Reducing-the-attack-surface-Paul-Durrant-Citrix-57-320.jpg)
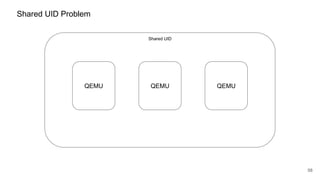
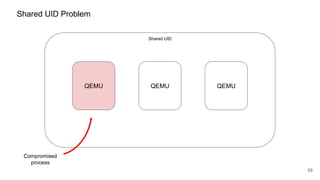
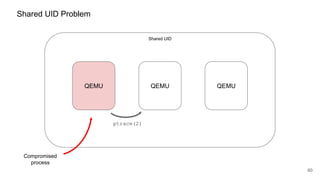
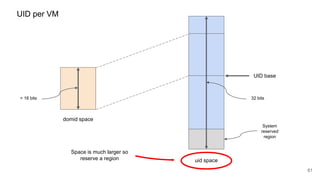
![62
[pauldu@brixham:~]/usr/local/lib/xen/bin/qemu-system-i386 --help
.
.
.
-runas user change to user id user just before starting the VM
.
.
.
This is going to be
awkward
QEMU Command Line](https://image.slidesharecdn.com/qemuandxenreducingtheattacksurface-180629142157/85/XPDDS18-Qemu-and-Xen-Reducing-the-attack-surface-Paul-Durrant-Citrix-62-320.jpg)
![63
[pauldu@brixham:~]/usr/local/lib/xen/bin/qemu-system-i386 --help
.
.
.
-runas user change to user id user just before starting the VM
.
.
.
commit 2c42f1e80103cb926c0703d4c1ac1fb9c3e2c600
Author: Ian Jackson <ian.jackson@eu.citrix.com>
Date: Fri Sep 15 18:10:44 2017 +0100
os-posix: Provide new -runas <uid>:<gid> facility
This allows the caller to specify a uid and gid to use, even if there
is no corresponding password entry. This will be useful in certain
Xen configurations.
But this makes it
better
QEMU Command Line](https://image.slidesharecdn.com/qemuandxenreducingtheattacksurface-180629142157/85/XPDDS18-Qemu-and-Xen-Reducing-the-attack-surface-Paul-Durrant-Citrix-63-320.jpg)
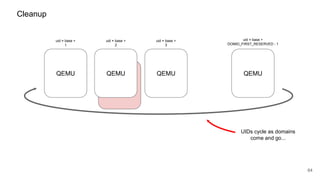
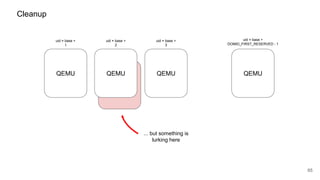
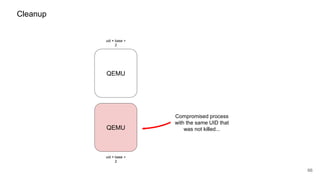
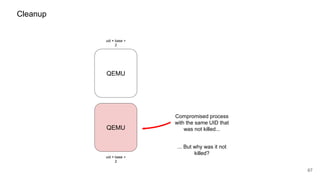
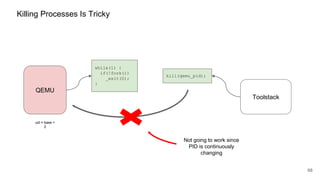
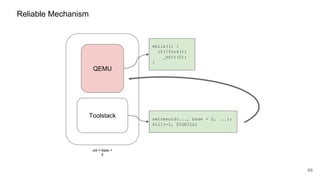
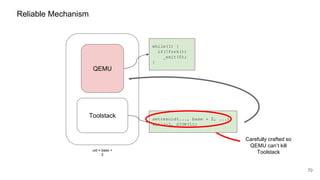
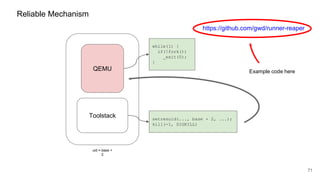








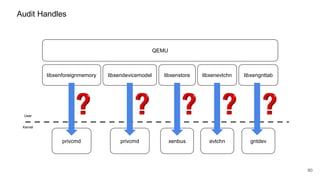




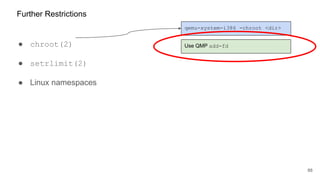
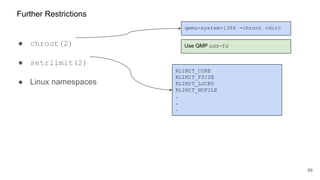
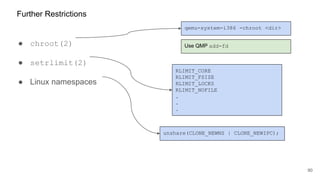


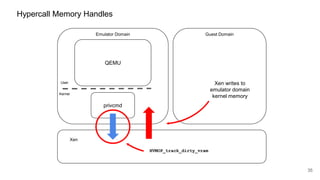
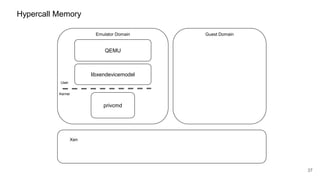
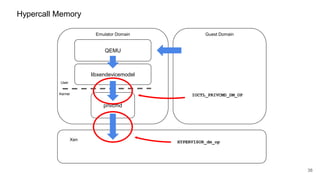
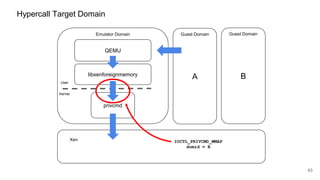
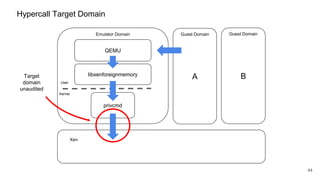
The document discusses security improvements in the QEMU and Xen virtualization systems, focusing on reducing potential attack vectors through direct resource mapping and auditing hypercalls. Key mitigations involve enabling strict controls on memory handling and process privileges to prevent compromised QEMU instances from attacking the host or other guest domains. Additionally, it addresses various issues and proposed solutions related to migration and PCI pass-through functionalities.































































![XPDDS19: [ARM] OP-TEE Mediator in Xen - Volodymyr Babchuk, EPAM Systems](https://cdn.slidesharecdn.com/ss_thumbnails/xendevsummit2019-babchuk-op-tee-190812095541-thumbnail.jpg?width=640&height=640&fit=bounds)










![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)












