Download to read offline


![INTRODUCTION | MOTIVATION
3
Natural Language Expressions
PREVIOUS WORK [1]
[1] A. Khoreva et al., Video Object Segmentation with Language Referring Expressions. ACCV 2018](https://image.slidesharecdn.com/recurrentinstancesegmentationwithlinguisticreferringexpressions-190917164051/85/Recurrent-Instance-Segmentation-with-Linguistic-Referring-Expressions-3-320.jpg)
![Model
time
Model
One-shot RVOS [2]
INTRODUCTION | VIDEO OBJECT SEGMENTATION
Model
time
Model
Referring expression
“the woman”
4[2] C. Ventura et al., RVOS: End-to-End Recurrent Network for Video Object Segmentation. CVPR 2019](https://image.slidesharecdn.com/recurrentinstancesegmentationwithlinguisticreferringexpressions-190917164051/85/Recurrent-Instance-Segmentation-with-Linguistic-Referring-Expressions-4-320.jpg)


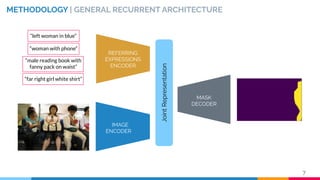
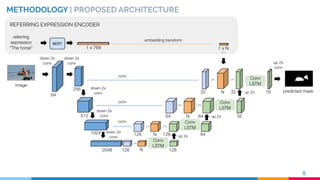
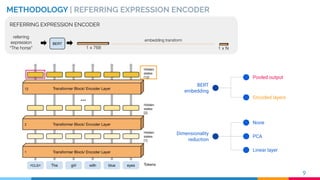
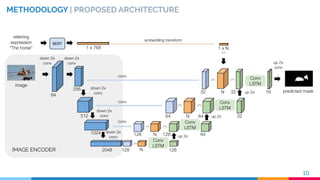
![IMAGE ENCODER
METHODOLOGY | IMAGE ENCODER
RVOS [2] ENCODER
MULTI-RESOLUTION
VISUAL FEATURES
11[2] C. Ventura et al., RVOS: End-to-End Recurrent Network for Video Object Segmentation. CVPR 2019](https://image.slidesharecdn.com/recurrentinstancesegmentationwithlinguisticreferringexpressions-190917164051/85/Recurrent-Instance-Segmentation-with-Linguistic-Referring-Expressions-11-320.jpg)
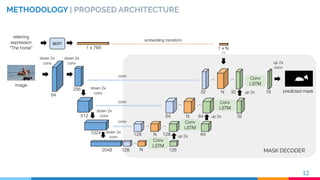
![MASK DECODER
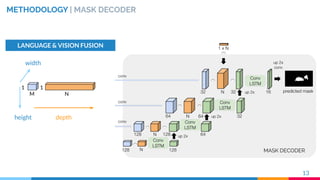
METHODOLOGY | MASK DECODER
RVOS [2] SPATIAL RECURRENCE
space
14[2] C. Ventura et al., RVOS: End-to-End Recurrent Network for Video Object Segmentation. CVPR 2019](https://image.slidesharecdn.com/recurrentinstancesegmentationwithlinguisticreferringexpressions-190917164051/85/Recurrent-Instance-Segmentation-with-Linguistic-Referring-Expressions-14-320.jpg)




![METHODOLOGY | VIDEO BASELINE ARCHITECTURE
MAttNet [3] + RVOS
[3] Licheng Yu et al., MAttNet: Modular Attention Network for Referring Expression Comprehension. CVPR 2018
21](https://image.slidesharecdn.com/recurrentinstancesegmentationwithlinguisticreferringexpressions-190917164051/85/Recurrent-Instance-Segmentation-with-Linguistic-Referring-Expressions-21-320.jpg)
![EXPERIMENTS | VIDEO DATASET
DAVIS 2017
+ EXPRESSIONS BY KHOREVA [1]
22[1] A. Khoreva et al., Video Object Segmentation with Language Referring Expressions. ACCV 2018](https://image.slidesharecdn.com/recurrentinstancesegmentationwithlinguisticreferringexpressions-190917164051/85/Recurrent-Instance-Segmentation-with-Linguistic-Referring-Expressions-22-320.jpg)



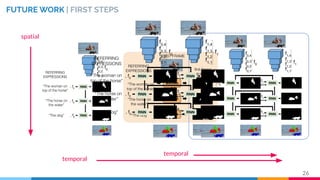




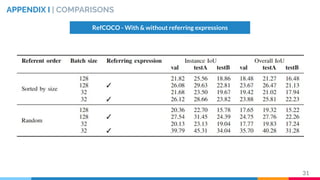
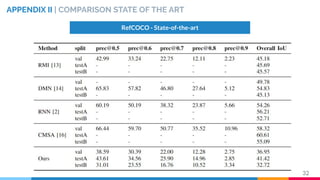

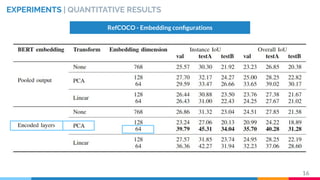
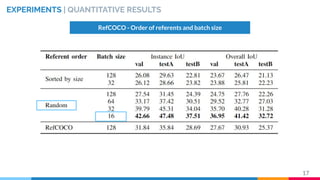
This master's thesis proposes a recurrent architecture to perform instance segmentation on images and videos using linguistic referring expressions. The model encodes referring expressions with BERT and visual features with an RVOS encoder, then decodes masks with a recurrent fusion of language and vision. Experiments on the RefCOCO dataset show the model outperforms baselines when incorporating referring expressions. The architecture is extended to video by adding temporal recurrence to an MAttNet+RVOS baseline, demonstrating promising initial results on the DAVIS dataset.



















































![[DSC Europe 25] Bojan Djuricic - Predictive Design Process.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/5awdrbedqdek3gqu2ezy-4-the-predictive-design-bojan-djuricic-260120105856-6c399e9b-thumbnail.jpg?width=640&height=640&fit=bounds)






