![LFrance/Belgium 0.94242 0.82359
LFrance/Germany 1.0000 0.96585
LBelgium/Germany 0.96585 1.0000
Normality tests and descriptive statistics
The dataset is: new09.in7
The sample is: 1973(5) - 1990(2)
Normality test for DLBelgium
Observations 202
Mean 0.0049006
Std.Devn. 0.0040206
Skewness 0.55869
Excess Kurtosis -0.35971
Minimum -0.0029746
Maximum 0.016097
Asymptotic test: Chi^2(2) = 11.597 [0.0030]**
Normality test: Chi^2(2) = 23.525 [0.0000]**
Normality test for DLFrance
Observations 202
Mean 0.0067183
Std.Devn. 0.0037830
Skewness 0.28292
Excess Kurtosis -0.22797
Minimum -0.0024968
Maximum 0.019186
Asymptotic test: Chi^2(2) = 3.1322 [0.2089]
Normality test: Chi^2(2) = 3.9005 [0.1422]
Normality test for DLGermany
Observations 202
Mean 0.0028933
Std.Devn. 0.0030606
Skewness 0.59041
Excess Kurtosis 0.35519](data:image/gif;base64,R0lGODlhAQABAIAAAAAAAP///yH5BAEAAAAALAAAAAABAAEAAAIBRAA7)
Recommended
Recommended
More Related Content
Similar to data.docx(1) Means, standard deviations and correlationsTh.docx
Similar to data.docx(1) Means, standard deviations and correlationsTh.docx (20)
More from theodorelove43763
More from theodorelove43763 (20)
Recently uploaded
Recently uploaded (20)
data.docx(1) Means, standard deviations and correlationsTh.docx
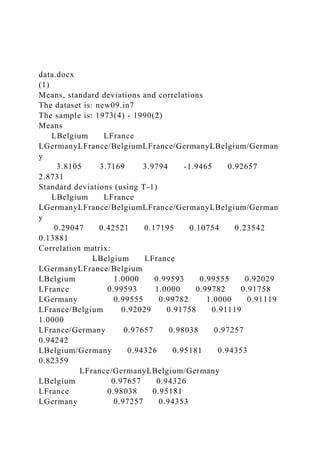
- 1. data.docx (1) Means, standard deviations and correlations The dataset is: new09.in7 The sample is: 1973(4) - 1990(2) Means LBelgium LFrance LGermanyLFrance/BelgiumLFrance/GermanyLBelgium/German y 3.8105 3.7169 3.9794 -1.9465 0.92657 2.8731 Standard deviations (using T-1) LBelgium LFrance LGermanyLFrance/BelgiumLFrance/GermanyLBelgium/German y 0.29047 0.42521 0.17195 0.10754 0.23542 0.13881 Correlation matrix: LBelgium LFrance LGermanyLFrance/Belgium LBelgium 1.0000 0.99593 0.99555 0.92029 LFrance 0.99593 1.0000 0.99782 0.91758 LGermany 0.99555 0.99782 1.0000 0.91119 LFrance/Belgium 0.92029 0.91758 0.91119 1.0000 LFrance/Germany 0.97657 0.98038 0.97257 0.94242 LBelgium/Germany 0.94326 0.95181 0.94353 0.82359 LFrance/GermanyLBelgium/Germany LBelgium 0.97657 0.94326 LFrance 0.98038 0.95181 LGermany 0.97257 0.94353
- 2. LFrance/Belgium 0.94242 0.82359 LFrance/Germany 1.0000 0.96585 LBelgium/Germany 0.96585 1.0000 Normality tests and descriptive statistics The dataset is: new09.in7 The sample is: 1973(5) - 1990(2) Normality test for DLBelgium Observations 202 Mean 0.0049006 Std.Devn. 0.0040206 Skewness 0.55869 Excess Kurtosis -0.35971 Minimum -0.0029746 Maximum 0.016097 Asymptotic test: Chi^2(2) = 11.597 [0.0030]** Normality test: Chi^2(2) = 23.525 [0.0000]** Normality test for DLFrance Observations 202 Mean 0.0067183 Std.Devn. 0.0037830 Skewness 0.28292 Excess Kurtosis -0.22797 Minimum -0.0024968 Maximum 0.019186 Asymptotic test: Chi^2(2) = 3.1322 [0.2089] Normality test: Chi^2(2) = 3.9005 [0.1422] Normality test for DLGermany Observations 202 Mean 0.0028933 Std.Devn. 0.0030606 Skewness 0.59041 Excess Kurtosis 0.35519
- 3. Minimum -0.0033465 Maximum 0.012716 Asymptotic test: Chi^2(2) = 12.798 [0.0017]** Normality test: Chi^2(2) = 12.800 [0.0017]** Normality test for DLFrance/Belgium Observations 202 Mean 0.0017844 Std.Devn. 0.011918 Skewness 0.48711 Excess Kurtosis 4.8743 Minimum -0.055216 Maximum 0.043456 Asymptotic test: Chi^2(2) = 207.95 [0.0000]** Normality test: Chi^2(2) = 83.018 [0.0000]** Normality test for DLFrance/Germany Observations 202 Mean 0.0037082 Std.Devn. 0.012603 Skewness 1.0110 Excess Kurtosis 3.1420 Minimum -0.038558 Maximum 0.050134 Asymptotic test: Chi^2(2) = 117.50 [0.0000]** Normality test: Chi^2(2) = 28.248 [0.0000]** Normality test for DLBelgium/Germany Observations 202 Mean 0.0019238 Std.Devn. 0.0078273 Skewness 4.2544 Excess Kurtosis 31.142 Minimum -0.018404 Maximum 0.069908 Asymptotic test: Chi^2(2) = 8772.2 [0.0000]**
- 4. Normality test: Chi^2(2) = 415.61 [0.0000]** (2) Unit-root test Stationary EQ( 1) Modelling DLFrance by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant -0.0160450 0.007638 -2.10 0.0369 0.0217 Trend -0.000107278 1.858e-005 -5.77 0.0000 0.1435 LFrance_1 0.00908918 0.002558 3.55 0.0005 0.0597 sigma 0.00279924 RSS 0.00155930985 R^2 0.460593 F(2,199) = 84.96 [0.000]** log-likelihood 902.324 DW 1.08 no. of observations 202 no. of parameters 3 mean(DLFrance) 0.00671834 var(DLFrance) 1.43108e-005 // Batch code for EQ( 1) module("PcGive"); package("PcGive", "Single-equation"); usedata("new09.in7"); system { Y = DLFrance; Z = Constant, Trend, LFrance_1; } estimate("OLS", 1973, 5, 1990, 2); EQ( 2) Modelling DLFrance by OLS The dataset is: new09.in7
- 5. The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant 0.0269034 0.001874 14.4 0.0000 0.5076 LFrance_1 -0.00543452 0.0005012 -10.8 0.0000 0.3702 sigma 0.00301714 RSS 0.00182062088 R^2 0.370198 F(1,200) = 117.6 [0.000]** log-likelihood 886.676 DW 0.911 no. of observations 202 no. of parameters 2 mean(DLFrance) 0.00671834 var(DLFrance) 1.43108e-005 EQ( 3) Modelling DLFrance by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 LFrance_1 0.00171584 8.072e-005 21.3 0.0000 0.6921 sigma 0.00428889 RSS 0.00369731806 log-likelihood 815.124 DW 0.452 no. of observations 202 no. of parameters 1 mean(DLFrance) 0.00671834 var(DLFrance) 1.43108e-005 EQ( 4) Modelling DLBelgium by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant 0.0215108 0.01391 1.55 0.1235 0.0119 Trend -1.75107e-005 2.083e-005 -0.841 0.4015 0.0035 LBelgium_1 -0.00388990 0.004198 -0.927 0.3553 0.0043
- 6. sigma 0.00343212 RSS 0.00234411488 R^2 0.282144 F(2,199) = 39.11 [0.000]** log-likelihood 861.15 DW 1.34 no. of observations 202 no. of parameters 3 mean(DLBelgium) 0.00490063 var(DLBelgium) 1.61655e- 005 EQ( 5) Modelling DLBelgium by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant 0.0328908 0.003186 10.3 0.0000 0.3476 LBelgium_1 -0.00734906 0.0008341 -8.81 0.0000 0.2796 sigma 0.00342961 RSS 0.00235244174 R^2 0.279594 F(1,200) = 77.62 [0.000]** log-likelihood 860.792 DW 1.33 no. of observations 202 no. of parameters 2 mean(DLBelgium) 0.00490063 var(DLBelgium) 1.61655e- 005 EQ( 6) Modelling DLBelgium by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 LBelgium_1 0.00123717 7.802e-005 15.9 0.0000 0.5557 sigma 0.00423554 RSS 0.00360589874 log-likelihood 817.653 DW 0.874 no. of observations 202 no. of parameters 1 mean(DLBelgium) 0.00490063 var(DLBelgium) 1.61655e-
- 7. 005 EQ( 7) Modelling DLGermany by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant 0.0218191 0.01885 1.16 0.2484 0.0067 Trend -6.70422e-006 1.501e-005 -0.447 0.6557 0.0010 LGermany_1 -0.00458449 0.005113 -0.897 0.3710 0.0040 sigma 0.00284988 RSS 0.00161623889 R^2 0.145862 F(2,199) = 16.99 [0.000]** log-likelihood 898.702 DW 1.26 no. of observations 202 no. of parameters 3 mean(DLGermany) 0.00289333 var(DLGermany) 9.36755e- 006 EQ( 8) Modelling DLGermany by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant 0.0299740 0.004654 6.44 0.0000 0.1718 LGermany_1 -0.00680706 0.001169 -5.82 0.0000 0.1450 sigma 0.00284417 RSS 0.00161785847 R^2 0.145006 F(1,200) = 33.92 [0.000]** log-likelihood 898.601 DW 1.26 no. of observations 202 no. of parameters 2 mean(DLGermany) 0.00289333 var(DLGermany) 9.36755e- 006
- 8. EQ( 9) Modelling DLGermany by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 LGermany_1 0.000713342 5.508e-005 13.0 0.0000 0.4549 sigma 0.00311743 RSS 0.00195338812 log-likelihood 879.567 DW 1.05 no. of observations 202 no. of parameters 1 mean(DLGermany) 0.00289333 var(DLGermany) 9.36755e- 006 EQ(10) Modelling DLFrance/Belgium by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant -0.0820533 0.04060 -2.02 0.0446 0.0201 Trend 5.27450e-005 3.517e-005 1.50 0.1353 0.0112 LFrance/Belgium_1 -0.0402793 0.01914 -2.10 0.0366 0.0218 sigma 0.0118449 RSS 0.0279202324 R^2 0.0269562 F(2,199) = 2.756 [0.066] log-likelihood 610.928 DW 1.23 no. of observations 202 no. of parameters 3 mean(Y) 0.00178439 var(Y) 0.000142048 EQ(11) Modelling DLFrance/Belgium by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2)
- 9. Coefficient Std.Error t-value t-prob Part.R^2 Constant -0.0255781 0.01521 -1.68 0.0943 0.0139 LFrance/Belgium_1 -0.0140523 0.007802 -1.80 0.0732 0.0160 sigma 0.0118819 RSS 0.0282357082 R^2 0.0159616 F(1,200) = 3.244 [0.073] log-likelihood 609.793 DW 1.25 no. of observations 202 no. of parameters 2 mean(Y) 0.00178439 var(Y) 0.000142048 EQ(12) Modelling DLFrance/Belgium by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 LFrance/Belgium_1 -0.000956051 0.0004306 -2.22 0.0275 0.0239 sigma 0.0119357 RSS 0.0286347099 log-likelihood 608.376 DW 1.25 no. of observations 202 no. of parameters 1 mean(Y) 0.00178439 var(Y) 0.000142048 EQ(17) Modelling DLFrance/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant 0.0192151 0.009474 2.03 0.0439 0.0203 Trend 7.54858e-005 7.164e-005 1.05 0.2933 0.0055 LFrance/Germany_1 -0.0251260 0.01782 -1.41 0.1600
- 10. 0.0099 sigma 0.0125617 RSS 0.0314015384 R^2 0.0213727 F(2,199) = 2.173 [0.117] log-likelihood 599.06 DW 1.24 no. of observations 202 no. of parameters 3 mean(Y) 0.00370822 var(Y) 0.000158848 EQ(18) Modelling DLFrance/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant 0.00998048 0.003598 2.77 0.0061 0.0370 LFrance/Germany_1 -0.00678005 0.003770 -1.80 0.0736 0.0159 sigma 0.0125652 RSS 0.0315767197 R^2 0.0159132 F(1,200) = 3.234 [0.074] log-likelihood 598.498 DW 1.25 no. of observations 202 no. of parameters 2 mean(Y) 0.00370822 var(Y) 0.000158848 EQ(19) Modelling DLFrance/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 LFrance/Germany_1 0.00335708 0.0009417 3.57 0.0005 0.0595 sigma 0.0127727 RSS 0.0327915104 log-likelihood 594.686 DW 1.22 no. of observations 202 no. of parameters 1 mean(Y) 0.00370822 var(Y) 0.000158848
- 11. EQ(20) Modelling DLBelgium/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant 0.0324338 0.03354 0.967 0.3346 0.0047 Trend 1.68881e-005 3.010e-005 0.561 0.5753 0.0016 LBelgium/Germany_1 -0.0112248 0.01269 -0.885 0.3774 0.0039 sigma 0.00785526 RSS 0.0122793188 R^2 0.00780208 F(2,199) = 0.7824 [0.459] log-likelihood 693.893 DW 1.34 no. of observations 202 no. of parameters 3 mean(Y) 0.00192383 var(Y) 6.12667e-005 EQ(21) Modelling DLBelgium/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 Constant 0.0147556 0.01147 1.29 0.1998 0.0082 LBelgium/Germany_1 -0.00446743 0.003989 -1.12 0.2641 0.0062 sigma 0.00784179 RSS 0.0122987469 R^2 0.00623224 F(1,200) = 1.254 [0.264] log-likelihood 693.734 DW 1.34 no. of observations 202 no. of parameters 2 mean(Y) 0.00192383 var(Y) 6.12667e-005 EQ(22) Modelling DLBelgium/Germany by OLS
- 12. The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 LBelgium/Germany_1 0.000657903 0.0001922 3.42 0.0007 0.0551 sigma 0.00785456 RSS 0.0124005016 log-likelihood 692.901 DW 1.34 no. of observations 202 no. of parameters 1 mean(Y) 0.00192383 var(Y) 6.12667e-005 H0 unit root H1 STATIONARY ALMOST OF THEM SUGGEST I0 ADF TEST H0 I(1) H1 I(2) EQ(23) Modelling DLBelgium/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLBelgium/Germany_1 0.336949 0.06742 5.00 0.0000 0.1125 LBelgium/Germany_1 -0.0179784 0.01208 -1.49 0.1383 0.0111 Constant 0.0494398 0.03191 1.55 0.1229 0.0120 Trend 3.40206e-005 2.873e-005 1.18 0.2377 0.0071
- 13. sigma 0.00743136 RSS 0.0108793353 R^2 0.119947 F(3,197) = 8.95 [0.000]** log-likelihood 702.125 DW 1.82 no. of observations 201 no. of parameters 4 mean(Y) 0.00194223 var(Y) 6.15032e-005 EQ(24) Modelling DLBelgium/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLBelgium/Germany_1 0.326982 0.06696 4.88 0.0000 0.1075 LBelgium/Germany_1 -0.00439956 0.003809 -1.16 0.2495 0.0067 Constant 0.0139460 0.01096 1.27 0.2047 0.0081 sigma 0.00743891 RSS 0.0109567886 R^2 0.113682 F(2,198) = 12.7 [0.000]** log-likelihood 701.412 DW 1.82 no. of observations 201 no. of parameters 3 mean(Y) 0.00194223 var(Y) 6.15032e-005 EQ(25) Modelling DLBelgium/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLBelgium/Germany_1 0.329561 0.06703 4.92 0.0000 0.1083 LBelgium/Germany_1 0.000441060 0.0001882 2.34 0.0201 0.0269 sigma 0.00745046 RSS 0.0110463712
- 14. log-likelihood 700.594 DW 1.82 no. of observations 201 no. of parameters 2 mean(Y) 0.00194223 var(Y) 6.15032e-005 EQ(26) Modelling DLFrance/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLFrance/Germany_1 0.394828 0.06590 5.99 0.0000 0.1541 Constant 0.0253629 0.008845 2.87 0.0046 0.0401 LFrance/Germany_1 -0.0411394 0.01669 -2.46 0.0146 0.0299 Trend 0.000146035 6.721e-005 2.17 0.0310 0.0234 sigma 0.011599 RSS 0.0265035905 R^2 0.17352 F(3,197) = 13.79 [0.000]** log-likelihood 612.638 DW 1.94 no. of observations 201 no. of parameters 4 mean(Y) 0.00373002 var(Y) 0.000159542 EQ(27) Modelling DLFrance/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLFrance/Germany_1 0.370646 0.06556 5.65 0.0000 0.1390 Constant 0.00761390 0.003423 2.22 0.0273 0.0244 LFrance/Germany_1 -0.00568251 0.003554 -1.60 0.1115 0.0127
- 15. sigma 0.0117074 RSS 0.0271387011 R^2 0.153715 F(2,198) = 17.98 [0.000]** log-likelihood 610.258 DW 1.92 no. of observations 201 no. of parameters 3 mean(Y) 0.00373002 var(Y) 0.000159542 EQ(28) Modelling DLFrance/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLFrance/Germany_1 0.390919 0.06556 5.96 0.0000 0.1516 LFrance/Germany_1 0.00196840 0.0009030 2.18 0.0304 0.0233 sigma 0.011823 RSS 0.0278166762 log-likelihood 607.779 DW 1.92 no. of observations 201 no. of parameters 2 mean(Y) 0.00373002 var(Y) 0.000159542 EQ(29) Modelling DLBelgium/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLBelgium/Germany_1 0.336949 0.06742 5.00 0.0000 0.1125 Constant 0.0494398 0.03191 1.55 0.1229 0.0120 Trend 3.40206e-005 2.873e-005 1.18 0.2377 0.0071 LBelgium/Germany_1 -0.0179784 0.01208 -1.49 0.1383 0.0111 sigma 0.00743136 RSS 0.0108793353
- 16. R^2 0.119947 F(3,197) = 8.95 [0.000]** log-likelihood 702.125 DW 1.82 no. of observations 201 no. of parameters 4 mean(Y) 0.00194223 var(Y) 6.15032e-005 EQ(30) Modelling DLBelgium/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLBelgium/Germany_1 0.326982 0.06696 4.88 0.0000 0.1075 Constant 0.0139460 0.01096 1.27 0.2047 0.0081 LBelgium/Germany_1 -0.00439956 0.003809 -1.16 0.2495 0.0067 sigma 0.00743891 RSS 0.0109567886 R^2 0.113682 F(2,198) = 12.7 [0.000]** log-likelihood 701.412 DW 1.82 no. of observations 201 no. of parameters 3 mean(Y) 0.00194223 var(Y) 6.15032e-005 EQ(31) Modelling DLBelgium/Germany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLBelgium/Germany_1 0.329561 0.06703 4.92 0.0000 0.1083 LBelgium/Germany_1 0.000441060 0.0001882 2.34 0.0201 0.0269 sigma 0.00745046 RSS 0.0110463712 log-likelihood 700.594 DW 1.82 no. of observations 201 no. of parameters 2
- 17. mean(Y) 0.00194223 var(Y) 6.15032e-005 EQ(32) Modelling DLBelgium by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLBelgium_1 0.326990 0.06678 4.90 0.0000 0.1085 Constant 0.0218492 0.01332 1.64 0.1024 0.0135 LBelgium_1 -0.00481865 0.004012 -1.20 0.2312 0.0073 Trend -1.78575e-006 1.997e-005 -0.0894 0.9288 0.0000 sigma 0.00323924 RSS 0.00206705122 R^2 0.366874 F(3,197) = 38.05 [0.000]** log-likelihood 869.03 DW 2.07 no. of observations 201 no. of parameters 4 mean(DLBelgium) 0.0049045 var(DLBelgium) 1.62429e- 005 EQ(33) Modelling DLBelgium by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLBelgium_1 0.327704 0.06613 4.96 0.0000 0.1103 Constant 0.0229921 0.003726 6.17 0.0000 0.1613 LBelgium_1 -0.00516766 0.0009288 -5.56 0.0000 0.1352 sigma 0.00323111 RSS 0.00206713512 R^2 0.366848 F(2,198) = 57.36 [0.000]** log-likelihood 869.025 DW 2.07
- 18. no. of observations 201 no. of parameters 3 mean(DLBelgium) 0.0049045 var(DLBelgium) 1.62429e- 005 EQ(34) Modelling DLBelgium by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLBelgium_1 0.563880 0.05875 9.60 0.0000 0.3165 LBelgium_1 0.000537264 9.763e-005 5.50 0.0000 0.1321 sigma 0.00351932 RSS 0.00246473478 log-likelihood 851.345 DW 2.26 no. of observations 201 no. of parameters 2 mean(DLBelgium) 0.0049045 var(DLBelgium) 1.62429e- 005 EQ(35) Modelling DLFrance by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLFrance_1 0.465581 0.06391 7.28 0.0000 0.2122 Constant -0.00635720 0.006970 -0.912 0.3628 0.0042 LFrance_1 0.00411569 0.002388 1.72 0.0864 0.0148 Trend -5.22226e-005 1.823e-005 -2.86 0.0046 0.0400 sigma 0.00249668 RSS 0.00122797857 R^2 0.57419 F(3,197) = 88.55 [0.000]** log-likelihood 921.365 DW 2.13 no. of observations 201 no. of parameters 4
- 19. mean(DLFrance) 0.00670529 var(DLFrance) 1.43476e-005 EQ(36) Modelling DLFrance by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLFrance_1 0.541023 0.05928 9.13 0.0000 0.2961 Constant 0.0125788 0.002251 5.59 0.0000 0.1363 LFrance_1 -0.00256031 0.0005327 -4.81 0.0000 0.1045 sigma 0.00254171 RSS 0.00127913695 R^2 0.556451 F(2,198) = 124.2 [0.000]** log-likelihood 917.263 DW 2.2 no. of observations 201 no. of parameters 3 mean(DLFrance) 0.00670529 var(DLFrance) 1.43476e-005 EQ(37) Modelling DLFrance by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLFrance_1 0.774790 0.04509 17.2 0.0000 0.5974 LFrance_1 0.000377414 9.312e-005 4.05 0.0001 0.0763 sigma 0.00272799 RSS 0.00148094365 log-likelihood 902.541 DW 2.45 no. of observations 201 no. of parameters 2 mean(DLFrance) 0.00670529 var(DLFrance) 1.43476e-005 EQ(38) Modelling DLGermany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2)
- 20. Coefficient Std.Error t-value t-prob Part.R^2 DLGermany_1 0.365669 0.06631 5.51 0.0000 0.1337 Constant 0.0197762 0.01776 1.11 0.2667 0.0063 LGermany_1 -0.00453649 0.004816 -0.942 0.3474 0.0045 Trend 9.17538e-007 1.418e-005 0.0647 0.9485 0.0000 sigma 0.00266156 RSS 0.00139552576 R^2 0.254234 F(3,197) = 22.39 [0.000]** log-likelihood 908.511 DW 2.03 no. of observations 201 no. of parameters 4 mean(DLGermany) 0.00287059 var(DLGermany) 9.30977e- 006 EQ(39) Modelling DLGermany by OLS The dataset is: new09.in7 The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLGermany_1 0.365186 0.06572 5.56 0.0000 0.1349 Constant 0.0186701 0.004802 3.89 0.0001 0.0709 LGermany_1 -0.00423450 0.001187 -3.57 0.0005 0.0604 sigma 0.00265486 RSS 0.00139555543 R^2 0.254218 F(2,198) = 33.75 [0.000]** log-likelihood 908.509 DW 2.03 no. of observations 201 no. of parameters 3 mean(DLGermany) 0.00287059 var(DLGermany) 9.30977e- 006 EQ(40) Modelling DLGermany by OLS The dataset is: new09.in7
- 21. The estimation sample is: 1973(6) - 1990(2) Coefficient Std.Error t-value t-prob Part.R^2 DLGermany_1 0.468260 0.06223 7.52 0.0000 0.2215 LGermany_1 0.000374458 6.579e-005 5.69 0.0000 0.1400 sigma 0.00274739 RSS 0.00150208012 log-likelihood 901.116 DW 2.11 no. of observations 201 no. of parameters 2 mean(DLGermany) 0.00287059 var(DLGermany) 9.30977e- 006 Unit-root tests The dataset is: new09.in7 The sample is: 1974(5) - 1990(2) LFrance: ADF tests (T=190, Constant; 5%=-2.88 1%=-3.47) D-lag t-adf beta Y_1 sigma t-DY_lag t-prob AIC F-prob 12 -1.357 0.99925 0.002062 3.358 0.0010 -12.30 11 -1.542 0.99913 0.002121 0.04993 0.9602 -12.25 0.0010 10 -1.553 0.99912 0.002115 0.7887 0.4314 -12.26 0.0042 9 -1.613 0.99909 0.002112 1.623 0.1063 -12.26 0.0090 8 -1.762 0.99901 0.002122 0.03910 0.9689 -12.26 0.0067 7 -1.782 0.99901 0.002116 -1.004 0.3165 -12.27 0.0142 6 -1.693 0.99906 0.002116 4.666 0.0000 -12.28 0.0183 5 -2.310 0.99866 0.002233 2.328 0.0210 -12.17 0.0000
- 22. 4 -2.774 0.99840 0.002260 -2.795 0.0057 -12.15 0.0000 3 -2.300 0.99867 0.002301 5.080 0.0000 -12.12 0.0000 2 -3.405* 0.99797 0.002450 2.586 0.0105 -12.00 0.0000 1 -4.317** 0.99751 0.002487 9.193 0.0000 -11.98 0.0000 0 -10.13** 0.99434 0.002988 -11.62 0.0000 LBelgium: ADF tests (T=190, Constant; 5%=-2.88 1%=-3.47) D-lag t-adf beta Y_1 sigma t-DY_lag t-prob AIC F-prob 12 -1.597 0.99792 0.003028 3.324 0.0011 -11.53 11 -1.894 0.99747 0.003112 -0.2390 0.8114 -11.48 0.0011 10 -1.884 0.99751 0.003104 -0.7801 0.4364 -11.49 0.0046 9 -1.817 0.99761 0.003101 1.347 0.1798 -11.50 0.0097 8 -2.001 0.99739 0.003108 1.148 0.2525 -11.50 0.0103 7 -2.202 0.99715 0.003111 -0.7425 0.4588 -11.50 0.0125 6 -2.115 0.99730 0.003107 1.692 0.0924 -11.51 0.0193 5 -2.457 0.99691 0.003122 2.009 0.0460 -11.50 0.0122 4 -2.943* 0.99635 0.003148 3.500 0.0006 -11.49 0.0051 3 -3.999** 0.99511 0.003242 0.9936 0.3217 -11.44 0.0001 2 -4.581** 0.99471 0.003242 0.9753 0.3307 -11.44 0.0001 1 -5.312** 0.99430 0.003242 4.105 0.0001 -11.45
- 23. 0.0002 0 -8.407** 0.99199 0.003376 -11.37 0.0000 LGermany: ADF tests (T=190, Constant; 5%=-2.88 1%=-3.47) D-lag t-adf beta Y_1 sigma t-DY_lag t-prob AIC F-prob 12 -0.9617 0.99863 0.002338 3.426 0.0008 -12.05 11 -1.337 0.99805 0.002408 3.889 0.0001 -11.99 0.0008 10 -1.903 0.99715 0.002502 0.7668 0.4442 -11.92 0.0000 9 -2.039 0.99698 0.002499 1.961 0.0514 -11.93 0.0000 8 -2.395 0.99648 0.002518 1.040 0.2996 -11.92 0.0000 7 -2.650 0.99618 0.002519 1.808 0.0723 -11.92 0.0000 6 -3.180* 0.99554 0.002535 -2.974 0.0033 -11.91 0.0000 5 -2.549 0.99643 0.002588 -0.3619 0.7179 -11.88 0.0000 4 -2.535 0.99654 0.002582 -0.8986 0.3700 -11.89 0.0000 3 -2.411 0.99677 0.002581 1.527 0.1286 -11.89 0.0000 2 -2.785 0.99634 0.002590 0.9681 0.3343 -11.89 0.0000 1 -3.062* 0.99607 0.002590 5.313 0.0000 -11.90 0.0000 0 -4.730** 0.99385 0.002771 -11.77 0.0000 LFrance/Belgium: ADF tests (T=190, Constant; 5%=-2.88 1%=- 3.47) D-lag t-adf beta Y_1 sigma t-DY_lag t-prob AIC
- 24. F-prob 12 -1.110 0.99116 0.01047 -0.8751 0.3827 -9.048 11 -1.126 0.99105 0.01046 -1.072 0.2852 -9.054 0.3827 10 -1.142 0.99092 0.01047 -2.186 0.0301 -9.058 0.3861 9 -1.188 0.99045 0.01058 1.229 0.2208 -9.042 0.0864 8 -1.165 0.99063 0.01059 2.479 0.0141 -9.044 0.0884 7 -1.143 0.99068 0.01074 0.3712 0.7109 -9.021 0.0152 6 -1.144 0.99069 0.01072 -0.2431 0.8082 -9.031 0.0270 5 -1.149 0.99067 0.01069 -1.023 0.3075 -9.041 0.0454 4 -1.158 0.99060 0.01069 -0.8568 0.3926 -9.046 0.0517 3 -1.161 0.99058 0.01068 -2.119 0.0355 -9.052 0.0636 2 -1.226 0.98997 0.01078 -0.9129 0.3625 -9.039 0.0247 1 -1.289 0.98948 0.01078 5.761 0.0000 -9.045 0.0296 0 -1.090 0.99037 0.01166 -8.892 0.0000 LFrance/Germany: ADF tests (T=190, Constant; 5%=-2.88 1%=- 3.47) D-lag t-adf beta Y_1 sigma t-DY_lag t-prob AIC F-prob 12 -0.6070 0.99789 0.01055 -2.396 0.0176 -9.033 11 -0.5990 0.99789 0.01069 -1.805 0.0728 -9.011 0.0176 10 -0.5818 0.99794 0.01076 -0.3928 0.6949 -9.003 0.0119
- 25. 9 -0.5804 0.99795 0.01073 1.063 0.2891 -9.013 0.0288 8 -0.5674 0.99800 0.01073 2.019 0.0450 -9.017 0.0376 7 -0.5464 0.99805 0.01083 2.034 0.0434 -9.005 0.0145 6 -0.5394 0.99806 0.01092 0.1321 0.8950 -8.993 0.0057 5 -0.5412 0.99806 0.01089 -0.6065 0.5449 -9.004 0.0107 4 -0.5307 0.99810 0.01087 -0.7124 0.4771 -9.012 0.0165 3 -0.5201 0.99814 0.01086 -0.9540 0.3413 -9.020 0.0231 2 -0.5204 0.99814 0.01085 -0.5035 0.6152 -9.026 0.0274 1 -0.5291 0.99812 0.01083 5.395 0.0000 -9.035 0.0390 0 -0.5403 0.99794 0.01161 -8.901 0.0000 LBelgium/Germany: ADF tests (T=190, Constant; 5%=-2.88 1%=-3.47) D-lag t-adf beta Y_1 sigma t-DY_lag t-prob AIC F-prob 12 -0.6166 0.99782 0.006538 0.5495 0.5834 -9.990 11 -0.6083 0.99785 0.006525 -1.173 0.2423 -9.998 0.5834 10 -0.6252 0.99779 0.006532 -1.808 0.0722 -10.00 0.4350 9 -0.6861 0.99756 0.006573 0.9361 0.3505 -9.993 0.1806 8 -0.6261 0.99778 0.006571 0.6478 0.5180 -9.999 0.2177 7 -0.5868 0.99793 0.006560 1.005 0.3160 -10.01 0.2881
- 26. 6 -0.5306 0.99813 0.006560 -0.2897 0.7724 -10.01 0.3028 5 -0.5494 0.99807 0.006544 1.481 0.1402 -10.02 0.3982 4 -0.4962 0.99825 0.006565 1.109 0.2690 -10.02 0.3054 3 -0.4448 0.99843 0.006569 1.607 0.1097 -10.02 0.2985 2 -0.3763 0.99867 0.006597 -1.197 0.2328 -10.02 0.2126 1 -0.4202 0.99852 0.006605 4.826 0.0000 -10.02 0.2005 0 -0.2665 0.99900 0.006985 -9.917 0.0003 (3) 黄色部分是重要的数据 SYS( 1) Estimating the system by OLS The dataset is: new09.in7 The estimation sample is: 1974(4) - 1990(2) URF equation for: LFrance/Belgium Coefficient Std.Error t-value t-prob LFrance/Belgium_1 1.27793 0.07985 16.0 0.0000 LFrance/Belgium_2 -0.309790 0.1287 -2.41 0.0172
- 27. LFrance/Belgium_3 -0.135067 0.1286 -1.05 0.2954 LFrance/Belgium_4 0.0602494 0.1277 0.472 0.6377 LFrance/Belgium_5 -0.0144114 0.1285 -0.112 0.9109 LFrance/Belgium_6 -0.00309561 0.1268 -0.0244 0.9806 LFrance/Belgium_7 0.0294940 0.1275 0.231 0.8174 LFrance/Belgium_8 0.162431 0.1272 1.28 0.2037 LFrance/Belgium_9 -0.0270322 0.1271 -0.213 0.8319 LFrance/Belgium_10 -0.267770 0.1229 -2.18 0.0309 LFrance/Belgium_11 0.111255 0.1227 0.906 0.3661 LFrance/Belgium_12 -0.00155779 0.07546 -0.0206 0.9836 LFrance_1 0.385940 0.4200 0.919 0.3596 LFrance_2 -1.31872 0.7486 -1.76 0.0801 LFrance_3 1.97146 0.7607 2.59 0.0105 LFrance_4 -1.04391 0.7477 -1.40 0.1647 LFrance_5 0.324587 0.7649 0.424 0.6719 LFrance_6 -0.567520 0.7572 -0.750 0.4547 LFrance_7 0.460296 0.7576 0.608 0.5444 LFrance_8 -0.100251 0.7546 -0.133 0.8945 LFrance_9 -0.223160 0.7339 -0.304 0.7615 LFrance_10 0.760773 0.7369 1.03 0.3035 LFrance_11 -1.23509 0.7159 -1.73 0.0865 LFrance_12 0.597129 0.4041 1.48 0.1416 LBelgium_1 -0.0722244 0.2914 -0.248 0.8046 LBelgium_2 0.337063 0.4337 0.777 0.4382 LBelgium_3 -0.410626 0.4445 -0.924 0.3570 LBelgium_4 -0.450874 0.4508 -1.00 0.3188 LBelgium_5 0.432919 0.4426 0.978 0.3295 LBelgium_6 -0.191279 0.4382 -0.437 0.6631 LBelgium_7 0.115131 0.4390 0.262 0.7935 LBelgium_8 -0.250199 0.4402 -0.568 0.5706 LBelgium_9 0.637659 0.4348 1.47 0.1445 LBelgium_10 -0.503691 0.4372 -1.15 0.2511 LBelgium_11 0.479278 0.4390 1.09 0.2766 LBelgium_12 -0.111923 0.2770 -0.404 0.6867 Constant -0.307948 0.1164 -2.65 0.0090
- 28. sigma = 0.0101403 RSS = 0.01583507807 URF equation for: LFrance Coefficient Std.Error t-value t-prob LFrance/Belgium_1 0.0104870 0.01579 0.664 0.5075 LFrance/Belgium_2 -0.0111617 0.02544 -0.439 0.6614 LFrance/Belgium_3 -0.0237979 0.02544 -0.936 0.3509 LFrance/Belgium_4 0.0589219 0.02525 2.33 0.0209 LFrance/Belgium_5 -0.00695515 0.02541 -0.274 0.7847 LFrance/Belgium_6 -0.0373424 0.02508 -1.49 0.1385 LFrance/Belgium_7 0.0230060 0.02521 0.912 0.3630 LFrance/Belgium_8 -0.0271489 0.02516 -1.08 0.2822 LFrance/Belgium_9 0.0329476 0.02514 1.31 0.1919 LFrance/Belgium_10 -0.0419706 0.02430 -1.73 0.0862 LFrance/Belgium_11 0.0288738 0.02427 1.19 0.2360 LFrance/Belgium_12 -0.00523507 0.01492 -0.351 0.7262 LFrance_1 1.47084 0.08304 17.7 0.0000 LFrance_2 -0.493216 0.1480 -3.33 0.0011 LFrance_3 0.361839 0.1504 2.41 0.0173 LFrance_4 -0.638682 0.1478 -4.32 0.0000 LFrance_5 0.316810 0.1512 2.09 0.0378 LFrance_6 0.290642 0.1497 1.94 0.0540 LFrance_7 -0.320522 0.1498 -2.14 0.0339 LFrance_8 -0.0522679 0.1492 -0.350 0.7266 LFrance_9 0.0848384 0.1451 0.585 0.5596 LFrance_10 0.150978 0.1457 1.04 0.3017 LFrance_11 -0.118942 0.1415 -0.840 0.4020 LFrance_12 -0.0425372 0.07991 -0.532 0.5953 LBelgium_1 -0.103993 0.05762 -1.80 0.0730 LBelgium_2 0.205379 0.08574 2.40 0.0178 LBelgium_3 -0.254146 0.08788 -2.89 0.0044 LBelgium_4 0.0752933 0.08913 0.845 0.3995 LBelgium_5 0.0359132 0.08750 0.410 0.6821 LBelgium_6 0.110359 0.08664 1.27 0.2047 LBelgium_7 -0.131423 0.08680 -1.51 0.1320 LBelgium_8 0.0330297 0.08703 0.380 0.7048
- 29. LBelgium_9 0.0910438 0.08597 1.06 0.2912 LBelgium_10 -0.224310 0.08645 -2.59 0.0104 LBelgium_11 0.124484 0.08679 1.43 0.1535 LBelgium_12 0.0203587 0.05477 0.372 0.7106 Constant 0.0354463 0.02301 1.54 0.1255 sigma = 0.00200488 RSS = 0.0006190098657 URF equation for: LBelgium Coefficient Std.Error t-value t-prob LFrance/Belgium_1 0.00357489 0.02257 0.158 0.8743 LFrance/Belgium_2 -0.0126261 0.03636 -0.347 0.7289 LFrance/Belgium_3 -0.00383292 0.03636 -0.105 0.9162 LFrance/Belgium_4 0.0264039 0.03609 0.732 0.4655 LFrance/Belgium_5 -0.0208393 0.03632 -0.574 0.5670 LFrance/Belgium_6 -0.00161438 0.03585 -0.0450 0.9641 LFrance/Belgium_7 -0.0247817 0.03604 -0.688 0.4927 LFrance/Belgium_8 0.0423463 0.03596 1.18 0.2408 LFrance/Belgium_9 -0.00238368 0.03593 -0.0663 0.9472 LFrance/Belgium_10 -0.0369844 0.03474 -1.06 0.2887 LFrance/Belgium_11 0.0293605 0.03469 0.846 0.3986 LFrance/Belgium_12 -0.0180046 0.02133 -0.844 0.3998 LFrance_1 -0.0995052 0.1187 -0.838 0.4032 LFrance_2 0.165785 0.2116 0.784 0.4345 LFrance_3 0.101434 0.2150 0.472 0.6377 LFrance_4 -0.177123 0.2113 -0.838 0.4032 LFrance_5 0.0245123 0.2162 0.113 0.9099 LFrance_6 0.340829 0.2140 1.59 0.1133 LFrance_7 -0.374297 0.2141 -1.75 0.0824 LFrance_8 -0.0700255 0.2133 -0.328 0.7431 LFrance_9 0.177214 0.2074 0.854 0.3942 LFrance_10 0.180473 0.2082 0.867 0.3875 LFrance_11 -0.394862 0.2023 -1.95 0.0528 LFrance_12 0.173936 0.1142 1.52 0.1298 LBelgium_1 1.06640 0.08235 12.9 0.0000 LBelgium_2 -0.160496 0.1226 -1.31 0.1923
- 30. LBelgium_3 -0.178947 0.1256 -1.42 0.1563 LBelgium_4 0.305609 0.1274 2.40 0.0176 LBelgium_5 -0.0198356 0.1251 -0.159 0.8742 LBelgium_6 -0.126473 0.1238 -1.02 0.3087 LBelgium_7 -0.0291057 0.1241 -0.235 0.8148 LBelgium_8 0.151122 0.1244 1.21 0.2263 LBelgium_9 -0.0326786 0.1229 -0.266 0.7906 LBelgium_10 -0.0869635 0.1236 -0.704 0.4826 LBelgium_11 0.0450370 0.1241 0.363 0.7171 LBelgium_12 -0.00605258 0.07829 -0.0773 0.9385 Constant 0.0622459 0.03289 1.89 0.0603 sigma = 0.00286568 RSS = 0.001264666523 log-likelihood 2436.99964 -T/2log|Omega| 3250.05141 |Omega| 1.6600113e-015 log|Y'Y/T| -6.84461615 R^2(LR) 1 R^2(LM) 0.990616 no. of observations 191 no. of parameters 111 F-test on regressors except unrestricted: F(111,456) = 35967.7 [0.0000] ** F-tests on retained regressors, F(3,152) = LFrance/Belgium_1 84.5353 [0.000]**LFrance/Belgium_2 1.98731 [0.118] LFrance/Belgium_3 0.620620 [0.603] LFrance/Belgium_4 1.84291 [0.142] LFrance/Belgium_5 0.119660 [0.948] LFrance/Belgium_6 0.767952 [0.514] LFrance/Belgium_7 0.572443 [0.634] LFrance/Belgium_8 1.77795 [0.154] LFrance/Belgium_9 0.649431 [0.584] LFrance/Belgium_10 2.61722 [0.053] LFrance/Belgium_11 0.826255 [0.481] LFrance/Belgium_12 0.242228 [0.867] LFrance_1 112.831 [0.000]** LFrance_2 5.30298 [0.002]**
- 31. LFrance_3 3.91118 [0.010]* LFrance_4 6.60333 [0.000]** LFrance_5 1.52990 [0.209] LFrance_6 1.87779 [0.136] LFrance_7 2.16555 [0.094] LFrance_8 0.0662745 [0.978] LFrance_9 0.317530 [0.813] LFrance_10 0.823492 [0.483] LFrance_11 2.34789 [0.075] LFrance_12 1.90022 [0.132] LBelgium_1 64.1130 [0.000]** LBelgium_2 3.25593 [0.023]* LBelgium_3 3.14657 [0.027]* LBelgium_4 2.19467 [0.091] LBelgium_5 0.372815 [0.773] LBelgium_6 1.27165 [0.286] LBelgium_7 0.801519 [0.495] LBelgium_8 0.578631 [0.630] LBelgium_9 1.09842 [0.352] LBelgium_10 2.56105 [0.057] LBelgium_11 1.01961 [0.386] LBelgium_12 0.117583 [0.950] Constant 3.88549 [0.010]* correlation of URF residuals (standard deviations on diagonal) LFrance/Belgium LFrance LBelgium LFrance/Belgium 0.010140 0.051944 -0.040747 LFrance 0.051944 0.0020049 0.24802 LBelgium -0.040747 0.24802 0.0028657 correlation between actual and fitted LFrance/Belgium LFrance LBelgium 0.99549 0.99999 0.99995 I(1) cointegration analysis, 1974(4) - 1990(2) eigenvalue loglik for rank 2409.911 0
- 32. 0.15264 2425.728 1 0.081940 2433.893 2 0.032007 2437.000 3 H0:rank<= Trace test [ Prob] 0 54.177 [0.000] ** 1 22.542 [0.022] * 2 6.2133 [0.181] Asymptotic p-values based on: Restricted constant Restricted variables: [0] = Constant Number of lags used in the analysis: 12 beta (scaled on diagonal; cointegrating vectors in columns) LFrance/Belgium 1.0000 0.80740 -5.6671 LFrance -1.2433 1.0000 1.7194 LBelgium 1.7382 -1.8156 1.0000 Constant -0.18262 4.8069 -22.299 alpha LFrance/Belgium -0.064213 -0.067818 -0.00028364 LFrance -0.0069044 0.0027978 -0.00092994 LBelgium -0.028709 0.012456 0.00012874 long-run matrix, rank 3 LFrance/Belgium LFrance LBelgium Constant LFrance/Belgium -0.11736 0.011531 0.011234 - 0.30795 LFrance 0.00062463 0.0097832 -0.018011 0.035446 LBelgium -0.019382 0.048371 -0.072388 0.062246
- 33. // Batch code for SYS( 1) module("PcGive"); package("PcGive", "Multiple-equation"); usedata("new09.in7"); system { Y = "LFrance/Belgium", LFrance, LBelgium; Z = Constant, "LFrance/Belgium_1", "LFrance/Belgium_2", "LFrance/Belgium_3", "LFrance/Belgium_4", "LFrance/Belgium_5", "LFrance/Belgium_6", "LFrance/Belgium_7", "LFrance/Belgium_8", "LFrance/Belgium_9", "LFrance/Belgium_10", "LFrance/Belgium_11", "LFrance/Belgium_12", LFrance_1, LFrance_2, LFrance_3, LFrance_4, LFrance_5, LFrance_6, LFrance_7, LFrance_8, LFrance_9, LFrance_10, LFrance_11, LFrance_12, LBelgium_1, LBelgium_2, LBelgium_3, LBelgium_4, LBelgium_5, LBelgium_6, LBelgium_7, LBelgium_8, LBelgium_9, LBelgium_10, LBelgium_11, LBelgium_12; } estimate("OLS", 1974, 4, 1990, 2); dynamics(); SYS( 2) Cointegrated VAR The dataset is: new09.in7 The estimation sample is: 1974(4) - 1990(2) Cointegrated VAR (12) in: [0] = LFrance/Belgium
- 34. [1] = LFrance [2] = LBelgium Restricted variables: [0] = Constant Number of lags used in the analysis: 12 beta LFrance/Belgium 1.0000 LFrance -1.2433 LBelgium 1.7382 Constant -0.18262 alpha LFrance/Belgium -0.064213 LFrance -0.0069044 LBelgium -0.028709 Standard errors of alpha LFrance/Belgium 0.023864 LFrance 0.0046458 LBelgium 0.0066255 Restricted long-run matrix, rank 1 LFrance/Belgium LFrance LBelgium Constant LFrance/Belgium -0.064213 0.079837 -0.11162 0.011726 LFrance -0.0069044 0.0085843 -0.012001 0.0012609 LBelgium -0.028709 0.035694 -0.049902 0.0052427 Standard errors of long-run matrix LFrance/Belgium 0.023864 0.029670 0.041480 0.0043579 LFrance 0.0046458 0.0057762 0.0080753
- 35. 0.00084840 LBelgium 0.0066255 0.0082376 0.011517 0.0012099 Reduced form beta LFrance/Belgium -1.0000 LFrance 1.2433 LBelgium -1.7382 Constant 0.18262 Standard errors of reduced form beta LFrance/Belgium 0.00000 LFrance 0.28616 LBelgium 0.45912 Constant 0.72170 Moving-average impact matrix 0.96145 4.6128 -3.2599 1.7958 37.208 -12.965 0.73138 23.960 -7.3983 log-likelihood 2425.72842 -T/2log|Omega| 3238.7802 no. of observations 191 no. of parameters 105 rank of long-run matrix 1 no. long-run restrictions 0 beta is not identified No restrictions imposed LFrance/Belgium: Portmanteau(12): 1.48753 LFrance : Portmanteau(12): 8.94026 LBelgium : Portmanteau(12): 8.36552 LFrance/Belgium: Normality test: Chi^2(2) = 38.144 [0.0000]** LFrance : Normality test: Chi^2(2) = 22.000 [0.0000]** LBelgium : Normality test: Chi^2(2) = 2.9930 [0.2239] LFrance/Belgium: ARCH 1-7 test: F(7,142) = 3.9842 [0.0005]**
- 36. LFrance : ARCH 1-7 test: F(7,142) = 0.28833 [0.9576] LBelgium : ARCH 1-7 test: F(7,142) = 0.62275 [0.7365] LFrance/Belgium: Hetero test: F(72,81) = 0.91774 [0.6438] LFrance : Hetero test: F(72,81) = 0.50705 [0.9982] LBelgium : Hetero test: F(72,81) = 0.51161 [0.9979] Vector Portmanteau(12): 45.4787 Vector Normality test: Chi^2(6) = 61.569 [0.0000]** Vector Hetero test: F(432,463)= 0.81429 [0.9848] SYS( 3) Estimating the system by OLS The dataset is: new09.in7 The estimation sample is: 1974(4) - 1990(2) URF equation for: LFrance/Germany Coefficient Std.Error t-value t-prob LFrance/Germany_1 1.18243 0.08104 14.6 0.0000 LFrance/Germany_2 -0.254381 0.1257 -2.02 0.0447 LFrance/Germany_3 -0.0111361 0.1263 -0.0882 0.9299 LFrance/Germany_4 0.0268588 0.1254 0.214 0.8307 LFrance/Germany_5 -0.0811245 0.1244 -0.652 0.5153 LFrance/Germany_6 0.0385568 0.1183 0.326 0.7450 LFrance/Germany_7 0.138214 0.1182 1.17 0.2442 LFrance/Germany_8 -0.0552427 0.1194 -0.463 0.6442 LFrance/Germany_9 0.0907171 0.1157 0.784 0.4344 LFrance/Germany_10 -0.0938167 0.1118 -0.839 0.4028 LFrance/Germany_11 -0.105044 0.1098 -0.957 0.3401 LFrance/Germany_12 0.00748530 0.07084 0.106 0.9160 LFrance_1 0.568700 0.3908 1.46 0.1476 LFrance_2 -1.66185 0.6607 -2.52 0.0129 LFrance_3 2.12237 0.6768 3.14 0.0021 LFrance_4 -1.31341 0.6667 -1.97 0.0506 LFrance_5 0.906003 0.6936 1.31 0.1935 LFrance_6 -1.40503 0.6899 -2.04 0.0434 LFrance_7 1.08005 0.6955 1.55 0.1225 LFrance_8 -0.128726 0.6988 -0.184 0.8541
- 37. LFrance_9 -0.665868 0.6794 -0.980 0.3286 LFrance_10 0.497608 0.6871 0.724 0.4701 LFrance_11 -0.330165 0.6828 -0.484 0.6294 LFrance_12 0.384502 0.3981 0.966 0.3356 LGermany_1 -0.399822 0.3462 -1.15 0.2500 LGermany_2 0.428888 0.5277 0.813 0.4176 LGermany_3 -0.113032 0.5192 -0.218 0.8279 LGermany_4 -0.306531 0.5163 -0.594 0.5536 LGermany_5 0.349434 0.5177 0.675 0.5007 LGermany_6 0.475014 0.5024 0.945 0.3459 LGermany_7 -1.39212 0.5044 -2.76 0.0065 LGermany_8 0.817985 0.5289 1.55 0.1240 LGermany_9 0.545546 0.5297 1.03 0.3046 LGermany_10 -0.227258 0.5266 -0.432 0.6666 LGermany_11 0.284420 0.5199 0.547 0.5851 LGermany_12 -0.450999 0.3254 -1.39 0.1677 Constant -0.131695 0.2478 -0.531 0.5959 sigma = 0.00994372 RSS = 0.01522714336 URF equation for: LFrance Coefficient Std.Error t-value t-prob LFrance/Germany_1 0.00237054 0.01727 0.137 0.8910 LFrance/Germany_2 -0.0222292 0.02678 -0.830 0.4079 LFrance/Germany_3 0.0109498 0.02691 0.407 0.6847 LFrance/Germany_4 0.0263148 0.02672 0.985 0.3263 LFrance/Germany_5 0.0127706 0.02651 0.482 0.6306 LFrance/Germany_6 -0.0559919 0.02521 -2.22 0.0278 LFrance/Germany_7 0.0377117 0.02519 1.50 0.1365 LFrance/Germany_8 -0.0132246 0.02544 -0.520 0.6039 LFrance/Germany_9 0.0120699 0.02466 0.489 0.6252 LFrance/Germany_10 -0.0146932 0.02383 -0.617 0.5384 LFrance/Germany_11 -0.00135161 0.02339 -0.0578 0.9540 LFrance/Germany_12 0.00345209 0.01509 0.229 0.8194 LFrance_1 1.39022 0.08326 16.7 0.0000 LFrance_2 -0.322240 0.1408 -2.29 0.0234
- 38. LFrance_3 0.167007 0.1442 1.16 0.2486 LFrance_4 -0.556010 0.1421 -3.91 0.0001 LFrance_5 0.372277 0.1478 2.52 0.0128 LFrance_6 0.308417 0.1470 2.10 0.0375 LFrance_7 -0.399356 0.1482 -2.69 0.0078 LFrance_8 -0.0658622 0.1489 -0.442 0.6589 LFrance_9 0.193218 0.1448 1.33 0.1840 LFrance_10 -0.0535239 0.1464 -0.366 0.7152 LFrance_11 -0.0500518 0.1455 -0.344 0.7313 LFrance_12 0.0131828 0.08482 0.155 0.8767 LGermany_1 0.0410234 0.07377 0.556 0.5790 LGermany_2 -0.00344278 0.1124 -0.0306 0.9756 LGermany_3 0.0141478 0.1106 0.128 0.8984 LGermany_4 0.0697912 0.1100 0.634 0.5268 LGermany_5 -0.137718 0.1103 -1.25 0.2138 LGermany_6 0.0525577 0.1071 0.491 0.6242 LGermany_7 -0.0388818 0.1075 -0.362 0.7180 LGermany_8 0.00803967 0.1127 0.0713 0.9432 LGermany_9 -0.0590020 0.1129 -0.523 0.6019 LGermany_10 0.0424012 0.1122 0.378 0.7060 LGermany_11 -0.0357749 0.1108 -0.323 0.7472 LGermany_12 0.0536652 0.06932 0.774 0.4401 Constant -0.0141731 0.05281 -0.268 0.7888 sigma = 0.00211877 RSS = 0.0006913324248 URF equation for: LGermany Coefficient Std.Error t-value t-prob LFrance/Germany_1 -0.00995883 0.01876 -0.531 0.5962 LFrance/Germany_2 0.00806314 0.02909 0.277 0.7820 LFrance/Germany_3 0.0364057 0.02923 1.25 0.2149 LFrance/Germany_4 -0.0432459 0.02903 -1.49 0.1383 LFrance/Germany_5 0.00823761 0.02879 0.286 0.7752 LFrance/Germany_6 -0.00739354 0.02738 -0.270 0.7875 LFrance/Germany_7 -0.000402614 0.02737 -0.0147 0.9883 LFrance/Germany_8 0.00640793 0.02763 0.232 0.8169
- 39. LFrance/Germany_9 -0.0113554 0.02679 -0.424 0.6722 LFrance/Germany_10 0.00921922 0.02588 0.356 0.7222 LFrance/Germany_11 0.00209335 0.02541 0.0824 0.9344 LFrance/Germany_12 -0.00116559 0.01640 -0.0711 0.9434 LFrance_1 0.116560 0.09044 1.29 0.1994 LFrance_2 -0.0817372 0.1529 -0.535 0.5937 LFrance_3 0.0121145 0.1566 0.0773 0.9385 LFrance_4 0.0130135 0.1543 0.0843 0.9329 LFrance_5 -0.117251 0.1605 -0.730 0.4663 LFrance_6 0.157006 0.1597 0.983 0.3270 LFrance_7 -0.109813 0.1610 -0.682 0.4961 LFrance_8 0.0848636 0.1617 0.525 0.6006 LFrance_9 0.267655 0.1573 1.70 0.0908 LFrance_10 -0.349672 0.1590 -2.20 0.0294 LFrance_11 0.0257251 0.1580 0.163 0.8709 LFrance_12 0.0127173 0.09213 0.138 0.8904 LGermany_1 1.16865 0.08013 14.6 0.0000 LGermany_2 -0.244820 0.1221 -2.00 0.0468 LGermany_3 0.118195 0.1202 0.984 0.3269 LGermany_4 -0.108472 0.1195 -0.908 0.3655 LGermany_5 0.0930923 0.1198 0.777 0.4384 LGermany_6 -0.404054 0.1163 -3.47 0.0007 LGermany_7 0.393746 0.1167 3.37 0.0009 LGermany_8 -0.144701 0.1224 -1.18 0.2390 LGermany_9 0.0697007 0.1226 0.569 0.5705 LGermany_10 -0.00537249 0.1219 -0.0441 0.9649 LGermany_11 0.211525 0.1203 1.76 0.0807 LGermany_12 -0.219975 0.07530 -2.92 0.0040 Constant 0.174402 0.05736 3.04 0.0028 sigma = 0.00230147 RSS = 0.0008156992738 log-likelihood 2474.65444 -T/2log|Omega| 3287.70622 |Omega| 1.11910951e-015 log|Y'Y/T| -6.29263643 R^2(LR) 1 R^2(LM) 0.986345 no. of observations 191 no. of parameters 111
- 40. F-test on regressors except unrestricted: F(111,456) = 49332.7 [0.0000] ** F-tests on retained regressors, F(3,152) = LFrance/Germany_1 72.3906 [0.000]**LFrance/Germany_2 1.56110 [0.201] LFrance/Germany_3 0.530140 [0.662] LFrance/Germany_4 1.39341 [0.247] LFrance/Germany_5 0.271015 [0.846] LFrance/Germany_6 1.80232 [0.149] LFrance/Germany_7 1.10053 [0.351] LFrance/Germany_8 0.190291 [0.903] LFrance/Germany_9 0.369824 [0.775] LFrance/Germany_10 0.419550 [0.739] LFrance/Germany_11 0.312637 [0.816] LFrance/Germany_12 0.0250941 [0.995] LFrance_1 95.1567 [0.000]** LFrance_2 3.29445 [0.022]* LFrance_3 3.43553 [0.019]* LFrance_4 6.12358 [0.001]** LFrance_5 3.07888 [0.029]* LFrance_6 3.47117 [0.018]* LFrance_7 3.72339 [0.013]* LFrance_8 0.215050 [0.886] LFrance_9 1.79252 [0.151] LFrance_10 1.88604 [0.134] LFrance_11 0.127775 [0.944] LFrance_12 0.307600 [0.820] LGermany_1 75.0178 [0.000]** LGermany_2 1.70258 [0.169] LGermany_3 0.353433 [0.787] LGermany_4 0.668355 [0.573] LGermany_5 1.15449 [0.329] LGermany_6 5.03881 [0.002]** LGermany_7 7.14852 [0.000]** LGermany_8 1.38611 [0.249]
- 41. LGermany_9 0.651169 [0.583] LGermany_10 0.133081 [0.940] LGermany_11 1.30487 [0.275] LGermany_12 4.20461 [0.007]** Constant 3.57993 [0.015]* correlation of URF residuals (standard deviations on diagonal) LFrance/Germany LFrance LGermany LFrance/Germany 0.0099437 0.15995 0.098497 LFrance 0.15995 0.0021188 0.25420 LGermany 0.098497 0.25420 0.0023015 correlation between actual and fitted LFrance/Germany LFrance LGermany 0.99918 0.99999 0.99991 I(1) cointegration analysis, 1974(4) - 1990(2) eigenvalue loglik for rank 2451.615 0 0.15287 2467.458 1 0.056413 2473.003 2 0.017142 2474.654 3 H0:rank<= Trace test [ Prob] 0 46.080 [0.002] ** 1 14.393 [0.269] 2 3.3025 [0.536] Asymptotic p-values based on: Restricted constant Restricted variables: [0] = Constant Number of lags used in the analysis: 12 beta (scaled on diagonal; cointegrating vectors in columns) LFrance/Germany 1.0000 -0.33556 0.052729 LFrance 0.044039 1.0000 -0.31341 LGermany -1.3365 -2.0026 1.0000
- 42. Constant 4.1392 4.5402 -2.9665 alpha LFrance/Germany -0.097026 0.057534 -0.0029306 LFrance -0.0030697 -0.0046797 -0.0066679 LGermany 0.0070976 0.029879 -0.0031577 long-run matrix, rank 3 LFrance/Germany LFrance LGermany Constant LFrance/Germany -0.11649 0.054180 0.011527 - 0.13170 LFrance -0.0018510 -0.0027252 0.0068069 - 0.014173 LGermany -0.0030948 0.031181 -0.072480 0.17440 SYS( 4) Cointegrated VAR The dataset is: new09.in7 The estimation sample is: 1974(4) - 1990(2) Cointegrated VAR (12) in: [0] = LFrance/Germany [1] = LFrance [2] = LGermany Restricted variables: [0] = Constant Number of lags used in the analysis: 12 beta LFrance/Germany 1.0000 LFrance 0.044039 LGermany -1.3365 Constant 4.1392 alpha
- 43. LFrance/Germany -0.097026 LFrance -0.0030697 LGermany 0.0070976 Standard errors of alpha LFrance/Germany 0.019970 LFrance 0.0042744 LGermany 0.0047086 Restricted long-run matrix, rank 1 LFrance/Germany LFrance LGermany Constant LFrance/Germany -0.097026 -0.0042729 0.12968 - 0.40161 LFrance -0.0030697 -0.00013519 0.0041029 - 0.012706 LGermany 0.0070976 0.00031257 -0.0094863 0.029379 Standard errors of long-run matrix LFrance/Germany 0.019970 0.00087944 0.026691 0.082659 LFrance 0.0042744 0.00018824 0.0057129 0.017692 LGermany 0.0047086 0.00020736 0.0062932 0.019490 Reduced form beta LFrance/Germany -1.0000 LFrance -0.044039 LGermany 1.3365 Constant -4.1392 Standard errors of reduced form beta LFrance/Germany 0.00000 LFrance 0.37250
- 44. LGermany 0.90508 Constant 2.2089 Moving-average impact matrix -0.18798 16.848 4.7169 -0.62231 34.388 6.3657 -0.16115 13.738 3.7389 log-likelihood 2467.45781 -T/2log|Omega| 3280.50959 no. of observations 191 no. of parameters 105 rank of long-run matrix 1 no. long-run restrictions 0 beta is not identified No restrictions imposed LFrance/Germany: Portmanteau(12): 6.85112 LFrance : Portmanteau(12): 8.11577 LGermany : Portmanteau(12): 4.3378 LFrance/Germany: Normality test: Chi^2(2) = 33.424 [0.0000]** LFrance : Normality test: Chi^2(2) = 38.314 [0.0000]** LGermany : Normality test: Chi^2(2) = 3.1750 [0.2044] LFrance/Germany: ARCH 1-7 test: F(7,142) = 1.1036 [0.3641] LFrance : ARCH 1-7 test: F(7,142) = 0.12194 [0.9967] LGermany : ARCH 1-7 test: F(7,142) = 0.44855 [0.8698] LFrance/Germany: Hetero test: F(72,81) = 0.72380 [0.9184] LFrance : Hetero test: F(72,81) = 0.70373 [0.9352] LGermany : Hetero test: F(72,81) = 0.47543 [0.9992] Vector Portmanteau(12): 58.9484 Vector Normality test: Chi^2(6) = 74.927 [0.0000]** Vector Hetero test: F(432,463)= 0.60106 [1.0000] SYS( 5) Estimating the system by OLS The dataset is: new09.in7
- 45. The estimation sample is: 1974(4) - 1990(2) URF equation for: LBelgium/Germany Coefficient Std.Error t-value t-prob LBelgium/Germany_1 1.24411 0.08057 15.4 0.0000 LBelgium/Germany_2 -0.429889 0.1303 -3.30 0.0012 LBelgium/Germany_3 0.242191 0.1348 1.80 0.0744 LBelgium/Germany_4 -0.0840452 0.1334 -0.630 0.5296 LBelgium/Germany_5 0.0963068 0.1260 0.764 0.4458 LBelgium/Germany_6 -0.184540 0.1258 -1.47 0.1446 LBelgium/Germany_7 0.102924 0.1285 0.801 0.4244 LBelgium/Germany_8 -0.0151956 0.1278 -0.119 0.9055 LBelgium/Germany_9 0.0137378 0.1228 0.112 0.9111 LBelgium/Germany_10 -0.0475944 0.1206 -0.395 0.6937 LBelgium/Germany_11 -0.0848517 0.1137 -0.746 0.4567 LBelgium/Germany_12 0.0888137 0.06890 1.29 0.1993 LBelgium_1 0.175739 0.1940 0.906 0.3664 LBelgium_2 -0.200036 0.2639 -0.758 0.4497 LBelgium_3 0.125802 0.2635 0.477 0.6337 LBelgium_4 -0.0591721 0.2655 -0.223 0.8239 LBelgium_5 0.160206 0.2678 0.598 0.5506 LBelgium_6 -0.228600 0.2653 -0.862 0.3902 LBelgium_7 -0.00589070 0.2654 -0.0222 0.9823 LBelgium_8 0.613126 0.2710 2.26 0.0250 LBelgium_9 -0.814964 0.2786 -2.93 0.0040 LBelgium_10 0.0607708 0.2843 0.214 0.8310 LBelgium_11 -0.0625811 0.2797 -0.224 0.8233 LBelgium_12 0.217344 0.1686 1.29 0.1992 LGermany_1 -0.373746 0.2162 -1.73 0.0859 LGermany_2 0.267891 0.3412 0.785 0.4336 LGermany_3 -0.00824147 0.3465 -0.0238 0.9811 LGermany_4 0.0151444 0.3493 0.0434 0.9655 LGermany_5 0.450110 0.3569 1.26 0.2092 LGermany_6 -0.376543 0.3550 -1.06 0.2905
- 46. LGermany_7 -0.351132 0.3493 -1.01 0.3164 LGermany_8 0.249408 0.3406 0.732 0.4651 LGermany_9 0.134627 0.3275 0.411 0.6816 LGermany_10 0.370252 0.3264 1.13 0.2584 LGermany_11 -0.204470 0.3263 -0.627 0.5319 LGermany_12 -0.0934401 0.2143 -0.436 0.6634 Constant -0.0804209 0.1089 -0.739 0.4613 sigma = 0.00614438 RSS = 0.00581402083 URF equation for: LBelgium Coefficient Std.Error t-value t-prob LBelgium/Germany_1 0.0564882 0.03530 1.60 0.1116 LBelgium/Germany_2 -0.0506352 0.05710 -0.887 0.3766 LBelgium/Germany_3 0.0121875 0.05907 0.206 0.8368 LBelgium/Germany_4 0.0364642 0.05844 0.624 0.5336 LBelgium/Germany_5 -0.0796239 0.05520 -1.44 0.1512 LBelgium/Germany_6 0.101231 0.05513 1.84 0.0683 LBelgium/Germany_7 -0.0832351 0.05629 -1.48 0.1413 LBelgium/Germany_8 0.0265802 0.05599 0.475 0.6356 LBelgium/Germany_9 -0.0570059 0.05381 -1.06 0.2911 LBelgium/Germany_10 0.0869395 0.05285 1.65 0.1020 LBelgium/Germany_11 -0.0532367 0.04982 -1.07 0.2870 LBelgium/Germany_12 0.0395195 0.03019 1.31 0.1924 LBelgium_1 0.951219 0.08498 11.2 0.0000 LBelgium_2 -0.140726 0.1156 -1.22 0.2255 LBelgium_3 -0.131885 0.1154 -1.14 0.2550 LBelgium_4 0.276431 0.1163 2.38 0.0187 LBelgium_5 -0.118454 0.1173 -1.01 0.3143 LBelgium_6 0.161914 0.1162 1.39 0.1656 LBelgium_7 -0.338599 0.1163 -2.91 0.0041 LBelgium_8 0.199237 0.1187 1.68 0.0953 LBelgium_9 0.0412499 0.1220 0.338 0.7358 LBelgium_10 -0.105923 0.1245 -0.850 0.3964
- 47. LBelgium_11 0.0981605 0.1225 0.801 0.4243 LBelgium_12 -0.00651130 0.07386 -0.0882 0.9299 LGermany_1 0.222759 0.09472 2.35 0.0199 LGermany_2 -0.293356 0.1495 -1.96 0.0515 LGermany_3 0.463101 0.1518 3.05 0.0027 LGermany_4 -0.370651 0.1531 -2.42 0.0166 LGermany_5 0.0287706 0.1564 0.184 0.8543 LGermany_6 1.07279e-005 0.1555 0.00 0.9999 LGermany_7 0.271382 0.1530 1.77 0.0781 LGermany_8 -0.00624830 0.1492 -0.0419 0.9667 LGermany_9 -0.128807 0.1435 -0.898 0.3707 LGermany_10 0.0195920 0.1430 0.137 0.8912 LGermany_11 -0.151840 0.1430 -1.06 0.2899 LGermany_12 0.0880479 0.09389 0.938 0.3498 Constant -0.229299 0.04770 -4.81 0.0000 sigma = 0.00269192 RSS = 0.001115951271 URF equation for: LGermany Coefficient Std.Error t-value t-prob LBelgium/Germany_1 -0.0362026 0.03033 -1.19 0.2344 LBelgium/Germany_2 0.0568306 0.04906 1.16 0.2485 LBelgium/Germany_3 0.0147421 0.05075 0.290 0.7718 LBelgium/Germany_4 -0.0108972 0.05021 -0.217 0.8285 LBelgium/Germany_5 -0.116697 0.04742 -2.46 0.0150 LBelgium/Germany_6 0.120452 0.04737 2.54 0.0120 LBelgium/Germany_7 -0.0318466 0.04837 -0.658 0.5112 LBelgium/Germany_8 -0.0253422 0.04810 -0.527 0.5991 LBelgium/Germany_9 0.0294442 0.04623 0.637 0.5252 LBelgium/Germany_10 -0.00683282 0.04541 -0.150 0.8806 LBelgium/Germany_11 -0.0270554 0.04281 -0.632 0.5283
- 48. LBelgium/Germany_12 0.0284262 0.02594 1.10 0.2748 LBelgium_1 0.0404842 0.07301 0.554 0.5801 LBelgium_2 -0.00894351 0.09935 -0.0900 0.9284 LBelgium_3 -0.168750 0.09917 -1.70 0.0909 LBelgium_4 0.288801 0.09992 2.89 0.0044 LBelgium_5 -0.238411 0.1008 -2.36 0.0193 LBelgium_6 0.133391 0.09987 1.34 0.1836 LBelgium_7 -0.105906 0.09988 -1.06 0.2907 LBelgium_8 -0.0980220 0.1020 -0.961 0.3380 LBelgium_9 0.289230 0.1049 2.76 0.0065 LBelgium_10 -0.164248 0.1070 -1.53 0.1268 LBelgium_11 -0.0314415 0.1053 -0.299 0.7656 LBelgium_12 0.0501439 0.06346 0.790 0.4306 LGermany_1 1.29590 0.08138 15.9 0.0000 LGermany_2 -0.311902 0.1284 -2.43 0.0163 LGermany_3 0.225749 0.1304 1.73 0.0855 LGermany_4 -0.310123 0.1315 -2.36 0.0196 LGermany_5 0.123547 0.1344 0.920 0.3592 LGermany_6 -0.224938 0.1336 -1.68 0.0943 LGermany_7 0.295004 0.1315 2.24 0.0263 LGermany_8 -0.103835 0.1282 -0.810 0.4192 LGermany_9 0.0448156 0.1233 0.364 0.7167 LGermany_10 -0.0346024 0.1229 -0.282 0.7786 LGermany_11 0.298141 0.1228 2.43 0.0164 LGermany_12 -0.274759 0.08066 -3.41 0.0008 Constant -0.0233588 0.04099 -0.570 0.5696 sigma = 0.00231282 RSS = 0.0008237694326 log-likelihood 2525.68367 -T/2log|Omega| 3338.73545 |Omega| 6.55862423e-016 log|Y'Y/T| -8.14095441 R^2(LR) 1 R^2(LM) 0.992103 no. of observations 191 no. of parameters 111 F-test on regressors except unrestricted: F(111,456) = 31811.5 [0.0000] **
- 49. F-tests on retained regressors, F(3,152) = LBelgium/Germany_1 84.4832 [0.000]**LBelgium/Germany_2 4.84693 [0.003]** LBelgium/Germany_3 1.19021 [0.315] LBelgium/Germany_4 0.302757 [0.823] LBelgium/Germany_5 2.17739 [0.093] LBelgium/Germany_6 2.83358 [0.040]* LBelgium/Germany_7 0.829163 [0.480] LBelgium/Germany_8 0.253797 [0.859] LBelgium/Germany_9 0.740966 [0.529] LBelgium/Germany_10 1.08987 [0.355] LBelgium/Germany_11 0.703625 [0.551] LBelgium/Germany_12 1.53880 [0.207] LBelgium_1 47.3689 [0.000]** LBelgium_2 0.824504 [0.482] LBelgium_3 1.08271 [0.358] LBelgium_4 3.50152 [0.017]* LBelgium_5 1.88295 [0.135] LBelgium_6 1.02400 [0.384] LBelgium_7 2.88040 [0.038]* LBelgium_8 3.81197 [0.011]* LBelgium_9 5.08111 [0.002]** LBelgium_10 0.814791 [0.488] LBelgium_11 0.339140 [0.797] LBelgium_12 0.857423 [0.465] LGermany_1 87.0156 [0.000]** LGermany_2 2.45571 [0.065] LGermany_3 3.33343 [0.021]* LGermany_4 2.87626 [0.038]* LGermany_5 0.906398 [0.440] LGermany_6 1.52991 [0.209] LGermany_7 2.15385 [0.096] LGermany_8 0.388259 [0.762] LGermany_9 0.465400 [0.707] LGermany_10 0.483026 [0.695] LGermany_11 3.39496 [0.020]* LGermany_12
- 50. 5.56514 [0.001]** Constant 8.75168 [0.000]** correlation of URF residuals (standard deviations on diagonal) LBelgium/Germany LBelgium LGermany LBelgium/Germany 0.0061444 -0.16532 -0.11966 LBelgium -0.16532 0.0026919 0.34182 LGermany -0.11966 0.34182 0.0023128 correlation between actual and fitted LBelgium/Germany LBelgium LGermany 0.99917 0.99996 0.99991 I(1) cointegration analysis, 1974(4) - 1990(2) eigenvalue loglik for rank 2492.611 0 0.21606 2515.858 1 0.081106 2523.936 2 0.018136 2525.684 3 H0:rank<= Trace test [ Prob] 0 66.145 [0.000] ** 1 19.651 [0.059] 2 3.4957 [0.504] Asymptotic p-values based on: Restricted constant Restricted variables: [0] = Constant Number of lags used in the analysis: 12 beta (scaled on diagonal; cointegrating vectors in columns) LBelgium/Germany 1.0000 0.39584 0.030822 LBelgium -2.6147 1.0000 -0.57142 LGermany 3.1370 -1.8566 1.0000 Constant -5.2325 2.3655 -1.9104 alpha
- 51. LBelgium/Germany -0.027470 -0.078750 0.019827 LBelgium 0.040111 -0.010946 -0.0033899 LGermany 0.0018460 -0.016235 -0.012932 long-run matrix, rank 3 LBelgium/Germany LBelgium LGermany Constant LBelgium/Germany -0.058031 -0.018254 0.079858 - 0.080421 LBelgium 0.035674 -0.11389 0.14276 -0.22930 LGermany -0.0049789 -0.013672 0.023001 - 0.023359 SYS( 6) Cointegrated VAR The dataset is: new09.in7 The estimation sample is: 1974(4) - 1990(2) Cointegrated VAR (12) in: [0] = LBelgium/Germany [1] = LBelgium [2] = LGermany Restricted variables: [0] = Constant Number of lags used in the analysis: 12 beta LBelgium/Germany 1.0000 LBelgium -2.6147 LGermany 3.1370 Constant -5.2325 alpha LBelgium/Germany -0.027470 LBelgium 0.040111 LGermany 0.0018460
- 52. Standard errors of alpha LBelgium/Germany 0.015225 LBelgium 0.0064922 LGermany 0.0056482 Restricted long-run matrix, rank 1 LBelgium/Germany LBelgium LGermany Constant LBelgium/Germany -0.027470 0.071826 -0.086175 0.14374 LBelgium 0.040111 -0.10488 0.12583 -0.20988 LGermany 0.0018460 -0.0048267 0.0057910 - 0.0096593 Standard errors of long-run matrix LBelgium/Germany 0.015225 0.039808 0.047761 0.079665 LBelgium 0.0064922 0.016975 0.020366 0.033970 LGermany 0.0056482 0.014768 0.017719 0.029554 Reduced form beta LBelgium/Germany -1.0000 LBelgium 2.6147 LGermany -3.1370 Constant 5.2325 Standard errors of reduced form beta LBelgium/Germany 0.00000 LBelgium 0.47463 LGermany 0.72964 Constant 1.0775 Moving-average impact matrix 1.3452 0.54091 8.2649
- 53. 0.61395 -0.35713 16.896 0.082895 -0.47009 11.448 log-likelihood 2515.85803 -T/2log|Omega| 3328.90981 no. of observations 191 no. of parameters 105 rank of long-run matrix 1 no. long-run restrictions 0 beta is not identified No restrictions imposed LBelgium/Germany: Portmanteau(12): 5.96898 LBelgium : Portmanteau(12): 3.39841 LGermany : Portmanteau(12): 6.49229 LBelgium/Germany: Normality test: Chi^2(2) = 121.37 [0.0000]** LBelgium : Normality test: Chi^2(2) = 6.3458 [0.0419]* LGermany : Normality test: Chi^2(2) = 2.1111 [0.3480] LBelgium/Germany: ARCH 1-7 test: F(7,142) = 0.42037 [0.8884] LBelgium : ARCH 1-7 test: F(7,142) = 0.66839 [0.6985] LGermany : ARCH 1-7 test: F(7,142) = 0.12698 [0.9963] LBelgium/Germany: Hetero test: F(72,81) = 0.66325 [0.9616] LBelgium : Hetero test: F(72,81) = 0.37190 [1.0000] LGermany : Hetero test: F(72,81) = 0.49807 [0.9986] Vector Portmanteau(12): 52.0286 Vector Normality test: Chi^2(6) = 120.49 [0.0000]** Vector Hetero test: F(432,463)= 0.69746 [0.9999]
- 54. (4)AR 图acf 和Pasf ---- Maximum likelihood estimation of ARFIMA(4,0,0) model -- -- The estimation sample is: 1973(5) - 1990(2) The dependent variable is: DLFrance/Belgium The dataset is: new09.in7 Coefficient Std.Error t-value t-prob AR-1 0.382891 0.06996 5.47 0.000 AR-2 -0.0181099 0.07466 -0.243 0.809 AR-3 -0.0856939 0.07447 -1.15 0.251 AR-4 -0.0745809 0.06953 -1.07 0.285 Constant 0.00177940 0.0009659 1.84 0.067 log-likelihood 625.927726 no. of observations 202 no. of parameters 6 AIC.T -1239.85545 AIC -6.13789827 mean(DLFrance/Belgium) 0.00178439 var(DLFrance/Belgium) 0.000142048 sigma 0.0109093 sigma^2 0.000119013 BFGS using numerical derivatives (eps1=0.0001; eps2=0.005): Strong convergence
- 55. Used starting values: 0.38482 -0.018468 -0.086797 -0.075880 0.0017844 ---- Maximum likelihood estimation of ARFIMA(3,0,0) model -- -- The estimation sample is: 1973(5) - 1990(2) The dependent variable is: DLFrance/Belgium The dataset is: new09.in7 Coefficient Std.Error t-value t-prob AR-1 0.391643 0.06968 5.62 0.000 AR-2 -0.0169831 0.07482 -0.227 0.821 AR-3 -0.114939 0.06940 -1.66 0.099 Constant 0.00178156 0.001040 1.71 0.088 log-likelihood 625.354221 no. of observations 202 no. of parameters 5 AIC.T -1240.70844 AIC -6.142121 mean(DLFrance/Belgium) 0.00178439 var(DLFrance/Belgium) 0.000142048 sigma 0.0109409 sigma^2 0.000119704 BFGS using numerical derivatives (eps1=0.0001; eps2=0.005): Strong convergence Used starting values: 0.39367 -0.017166 -0.11667 0.0017844 ---- Maximum likelihood estimation of ARFIMA(2,0,0) model -- -- The estimation sample is: 1973(5) - 1990(2) The dependent variable is: DLFrance/Belgium The dataset is: new09.in7 Coefficient Std.Error t-value t-prob
- 56. AR-1 0.399155 0.07004 5.70 0.000 AR-2 -0.0633158 0.06988 -0.906 0.366 Constant 0.00178289 0.001164 1.53 0.127 log-likelihood 623.986982 no. of observations 202 no. of parameters 4 AIC.T -1239.97396 AIC -6.13848497 mean(DLFrance/Belgium) 0.00178439 var(DLFrance/Belgium) 0.000142048 sigma 0.0110163 sigma^2 0.000121359 BFGS using numerical derivatives (eps1=0.0001; eps2=0.005): Strong convergence Used starting values: 0.40113 -0.063965 0.0017844 ---- Maximum likelihood estimation of ARFIMA(1,0,0) model -- -- The estimation sample is: 1973(5) - 1990(2) The dependent variable is: DLFrance/Belgium The dataset is: new09.in7 Coefficient Std.Error t-value t-prob AR-1 0.375174 0.06496 5.78 0.000 Constant 0.00178020 0.001239 1.44 0.152 log-likelihood 623.577387 no. of observations 202 no. of parameters 3 AIC.T -1241.15477 AIC -6.14433056 mean(DLFrance/Belgium) 0.00178439 var(DLFrance/Belgium) 0.000142048 sigma 0.0110389 sigma^2 0.000121857 BFGS using numerical derivatives (eps1=0.0001; eps2=0.005): Strong convergence
- 57. Used starting values: 0.37701 0.0017844 Test for excluding: AR-1 Subset Chi^2(1) = 33.3597 [0.0000] ** Descriptive statistics for residuals: Normality test: Chi^2(2) = 58.149 [0.0000]** ARCH 1-1 test: F(1,198) = 7.5716 [0.0065]** Portmanteau(36): Chi^2(35) = 47.627 [0.0755] ARCH ARCH coefficients: Lag Coefficient Std.Error 1 0.14213 0.07377 2 0.15012 0.0743 3 0.16443 0.07515 4 -0.028656 0.07482 5 0.047427 0.07478 6 -0.039926 0.07482 7 -0.013674 0.07469 8 -0.011489 0.07465 9 0.029838 0.07458 10 -0.0027954 0.07309 11 -0.052836 0.07233 12 0.020861 0.07185 RSS = 1.47674e-005 sigma = 0.000289665 Testing for error ARCH from lags 1 to 12 ARCH 1-12 test: F(12,176) = 1.7613 [0.0579] Residual [1973( 5) - 1990( 2)] saved to new09.in7
- 58. GARCH VOL( 2) Modelling DLFrance/Belgium by restricted GARCH(1,1) The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error robust-SE t-value t-prob Constant X 0.00137385 0.0005496 0.0006335 2.17 0.031 alpha_0 H 2.53091e-005 6.838e-006 1.225e-005 2.07 0.040 alpha_1 H 0.548753 0.1647 0.2417 2.27 0.024 beta_1 H 0.386169 0.1059 0.1239 3.12 0.002 log-likelihood 647.090499 HMSE 7.74626 mean(h_t) 0.000169302 var(h_t) 5.89695e-008 no. of observations 202 no. of parameters 4 AIC.T -1286.181 AIC -6.36723266 mean(DLFrance/Belgium) 0.00178439 var(DLFrance/Belgium) 0.000142048 alpha(1)+beta(1) 0.934922 alpha_i+beta_i>=0, alpha(1)+beta(1)<1 Initial terms of alpha(L)/[1-beta(L)]: 0.54875 0.21191 0.081834 0.031602 0.012204 0.0047127 0.0018199 0.00070278 0.00027139 0.00010480 4.0472e- 005 1.5629e-005 Used sample mean of squared residuals to start recursion Robust-SE based on analytical Information matrix and analytical OPG matrix BFGS using analytical derivatives (eps1=0.0001; eps2=0.005): Strong convergence Used starting values: 0.0017844 2.1595e-005 0.70855 0.13943
- 59. Test for excluding: alpha_1 Subset Chi^2(1) = 11.0952 [0.0009] ** Using robust standard errors: Subset Chi^2(1) = 5.15536 [0.0232] * Portmanteau statistic for scaled residuals Autocorrelation function (ACF) from lag 1 to 12: 0.24488 0.047178 -0.058108 -0.085325 -0.059613 -0.080555 -0.0051672 0.13997 0.19257 0.0078786 -0.13371 -0.15760 Partial autocorrelation function (PACF): 0.24488 -0.013605 -0.070740 -0.057554 -0.023454 -0.065465 0.024169 0.14067 0.12540 -0.091215 -0.13049 -0.078908 Portmanteau(12): Chi^2(12) = 38.040 [0.0002]** Portmanteau statistic for squared scaled residuals Autocorrelation function (ACF) from lag 1 to 12: -0.011257 0.027938 -0.024482 0.032919 0.050857 -0.051928 -0.035495 -0.054797 0.075378 0.023350 -0.028213 0.0044665 Partial autocorrelation function (PACF): -0.011257 0.027815 -0.023885 0.031675 0.052970 -0.053474 -0.038122 -0.051434 0.071194 0.027495 -0.027254 0.010154 Portmanteau(12): Chi^2(10) = 4.0149 [0.9467] EGARCH VOL( 3) Modelling DLFrance/Belgium by EGARCH(1,1)
- 60. The dataset is: new09.in7 The estimation sample is: 1973(5) - 1990(2) Coefficient Std.Error robust-SE t-value t-prob Constant X 0.00101843 0.0005399 0.0005579 1.83 0.069 alpha_0 H -1.41749 0.6391 0.9994 -1.42 0.158 eps[-1] H -0.143496 0.09108 0.1445 -0.993 0.322 |eps[-1]| H 0.691818 0.1431 0.2420 2.86 0.005 beta_1 H 0.833174 0.07042 0.1136 7.33 0.000 log-likelihood 649.124517 HMSE 8.68633 mean(h_t) 0.000159174 var(h_t) 4.75962e-008 no. of observations 202 no. of parameters 5 AIC.T -1288.24903 AIC -6.37747046 mean(DLFrance/Belgium) 0.00178439 var(DLFrance/Belgium) 0.000142048 Used sample mean of squared residuals to start recursion Robust-SE based on numerical Hessian matrix and numerical OPG matrix BFGS using numerical derivatives (eps1=0.0001; eps2=0.005): Strong convergence Used starting values: 0.0017844 1.0047 0.70855 0.00000 0.13943 (5) Forecast Forecasting DLFrance/Belgium from 1990(3) to 1991(5) Horizon Forecast (SE) Actual CondVar 1.0000 0.0010184 0.0051081 0.00013464 2.6093e-
- 61. 005 2.0000 0.0010184 0.0060643 -0.00097591 3.6775e- 005 3.0000 0.0010184 0.0069962 0.0043737 4.8947e- 005 4.0000 0.0010184 0.0078812 0.0029580 6.2113e- 005 5.0000 0.0010184 0.0087034 -0.0045257 7.5749e- 005 6.0000 0.0010184 0.0094536 0.0019288 8.9370e- 005 7.0000 0.0010184 0.010128 -0.0019952 0.00010257 8.0000 0.0010184 0.010726 -0.0011920 0.00011505 9.0000 0.0010184 0.011251 0.0031894 0.00012660 10.000 0.0010184 0.011709 0.0056647 0.00013710 11.000 0.0010184 0.012104 .NaN 0.00014651 12.000 0.0010184 0.012443 .NaN 0.00015484 13.000 0.0010184 0.012734 .NaN 0.00016214 14.000 0.0010184 0.012980 .NaN 0.00016849 mean(Error) = -6.2387e-005 RMSE = 0.0030268 SD(Error) = 0.0030261 MAPE = 165.93 FMBF computer lab1.pdf FMBF: Computer Practical 1 Introduction There are four workshops for the FMBF module this term which will be organised as follows: Practical 1 ARIMA modelling and unit root testing. Practical 2 Cointegration procedures.
- 62. Practical 3 ARCH/GARCH modelling and forecasting. 1 ARIMA Modelling 1.1 Aims In the first part of this session we will firstly load a dataset and experiment with ARIMA modelling. Once the concept has been demonstrated you will be required to find a preferred model for the stock price data that we will be using. The stock price series is raw data so you will need to calculate returns yourself using the calculator function in PcGive. We will demonstrate the procedure for using the Time Series Models package in PcGive by estimating an AR(1) model: 1.2 Key Steps Importing and transforming the data 1. We will be using monthly data on the price of British Airways from 1996 to 2002. Download the file BA.xls from duo that contains these data. 2. Start PcGive. (Start > Search PcGive12)
- 63. 3. Create new database in PcGive. (File > New… > OxMetrics (Data: *.in7) > Frequency: Monthly > Observations: 74 > OK). Practical 4 Review. 4. Copy the price data column from Excel to PcGive. Double click on the first row and type the column title: BA. Note: You could also click File > Open data file... and import the Excel file directly. However, PcGive will not automatically recognise the dates in the leftmost column. If you chose to do it this way you could choose Edit > Change Sample to let PcGive know we are dealing with monthly data from 1996. 5. Use Calculator to calculate the log return, i.e., generate new series Ri which equals the dlog of BA.
- 64. Prior to constructing the model You should plot and carefully examine the ACF and PACF. Recall that we plotted the ACF and PACF last term, and that you can do this by going to the Graphics button in PcGive. (Graphics > Choose the variables and click All plot types > Time-series properties > In Dynamic Properties tick ACF and PACF and click OK) Is a particular model suggested by this graphical analysis? Constructing the model These steps show the construction of an AR(1) model for demonstration. 1 In PcGive select Model > Category: Models for time series data > Model class: ARFIMA models using PcGive. 2 Select Formulate… 3 Select Ri as the dependent variable (Y), add a constant term (PcGive should do this automatically), and press OK.
- 65. 4 Set AR order as 1 and fix the Fractional parameter d at 0. Treatment of the mean should automatically be set to None (or using constant as regressor). 5 Press OK, and select Maximum Likelihood. 6 Press OK and the Estimation Results will appear. 7 Examine the results. Is this model satisfactory? Exercice 1: Identifying your preferred model Carefully examine the results from your model. You should: using ACF and PACF and the Q- statistic (Ljung Box statistic). -estimate the model, overfitting in an effort to isolate the preferred specification. competing models. If you are not prompted to do so by the steps above, you should
- 66. at the least estimate an MA(1) and an ARIMA(1,0,1) model to be clear on the procedure of specifying such models in PcGive. 2 Unit root testing 2.1 Aims In the second part of this session we will examine stationarity testing using PcGive. Price/Earnings data for the US will be used to demonstrate how the software can easily test for the presence of a unit root and display results in a fashion that easily allows us to choose a preferred model cf. the number of lags to include. We will then test for stationarity in monthly data for the FTSE 100 and FTSE All Share. Example 1: Annual Price/Earnings Ratio This example is based on the illustration of the annual price/earnings ratio proposed in Verbeek (2004, p.274). The literature has focussed on whether the price/earnings ratio is mean reverting (why might this be interesting?).
- 67. 1 Load the data PE.xls into PcGive (File > Open… > PE.xls). This is annual data on the ratio of the S&P Composite Stock Price Index and S&P Composite Earnings. The sample (annual data) runs from 1871 to 2002. 2 Plot the log of the series (LOGPE) using GiveWin graphics (Graphics > Choose LOGPE > Actual series) . Does it look stationary? 3 We will test for stationarity with the standard Dickey-Fuller regression, i.e. if we denote the log P/E ratio as Yt 1 1t t t (1) Note that you will need to use Calculator to diff the LOGPE series. Modelling this using Single equation dynamic modelling... gives 1 0.335 0.125
- 68. t t t Y Y e (2) (Model > Category: Model for time-series data > Model class: Single-equation Dynamic Modelling using PcGive > Formulate… > Select DLOGPE as Y and choose lagged LOGPE > Click OK) The full output from PcGive is We can calculate the DF test statistic as -2.57, the 5% critical value being -2.88. Thus we cannot reject the null of a unit root. However, for this result to hold we must have included lags to the extent that the error term is white noise. 2.2 Automated unit root testing Fortunately, PcGive makes it easy to perform unit root testing automatically, saving us having to run a regression each time. It also produces a neat summary table allowing easy
- 69. selection of the appropriate number of lag terms. We will first replicate the results previously obtained: 1 Select Model > Category: Other models > Model class: Descriptive Statistics using PcGive) 2 Select Formulate 3 Add LOGPE to the model and click OK 4 In Descriptive Statistics select Unit-root tests, and then edit Unit-root test settings so that Lag length for differences is 0 and Constant) is selected 5 Click OK and then OK in the Estimate Model dialog 6 The following results should appear in the Results area in GiveWin These are the results we obtained previously. Note that the software automatically calculates the correct test statistic and critical value. 2.3 ADF testing We will now add lags and look at the results from augmented Dickey-Fuller tests:
- 70. 1 Formulate a new model (Descriptive Statistics) 2 Edit Unit-root test settings so that Lag length for differences is 6 and Constant) is selected. Make sure that Report summary table only is selected. The following results are presented There is a rejection of the null of a unit root at the 5% level with one lag. However, none of the other ADF tests reject the null of nonstationarity. Does this concur with the graphical plot of the P/E series that you produced above? Exercice 2: Annual Price/Earnings Ratio cont... Test for the presence of a second unit root in annual price/earnings data (Hint: you will need to difference the data once more). Can you reject the null of nonstationarity? What conclusion does this lead you towards? Exercice 3: Stationarity in the FTSE 100 and ALL SHARE 1. Load the data FTSEDATA.xls that is on duo. This contains monthly data for the FTSE 100 and ALL SHARE from 1985:1. 2. Create logarithms of the two indices, naming them LFTSE100
- 71. and LFTALLSH. 3. Plot the series then test for stationarity adding an appropriate number of lags. 4. Create the first difference of LFTSE100 and LFTALLSH and test for stationarity after plotting the differenced series. 5. Come to conclusions about the presence of a unit root in the two series. 2.4 Points to note unit root test output mean; see Figure 1 and Figure 2. unit root in ammore systematic way (see Harris and Sollis p. 47 and your lecture notes). This will not be considered here. References M. Verbeek. A Guide to Modern Econometrics. John Wiley & Sons, Inc., 2004. Figure 1: Interpreting unit root test output: summary table option
- 72. Figure 2: Interpreting unit root test output: summary table vs. standard output Guide_to_ACF_PACF_plots(computer lab1).pdf Guide to ACF/PACF Plots The plots shown here are those of pure or theoretical ARIMA processes. Here are some general guidelines for identifying the process: Nonstationary series have an ACF that remains significant for half a dozen or more lags, rather than quickly declining to zero. You must difference such a series until it is stationary before you can identify the process. Autoregressive processes have an exponentially declining ACF and spikes in the first one or more lags of the PACF. The number of spikes indicates the order of the autoregression. Moving average processes have spikes in the first one or more lags of the ACF and an exponentially declining PACF. The number of spikes indicates the order of the moving average.
- 73. Mixed (ARMA) processes typically show exponential declines in both the ACF and the PACF. At the identification stage, you do not need to worry about the sign of the ACF or PACF, or about the speed with which an exponentially declining ACF or PACF approaches zero. These depend upon the sign and actual value of the AR and MA coefficients. In some instances, an exponentially declining ACF alternates between positive and negative values. ACF and PACF plots from real data are never as clean as the plots shown here. You must learn to pick out what is essential in any given plot. Always check the ACF and PACF of the residuals, in case your identification is wrong. Bear in mind that: Seasonal processes show these patterns at the seasonal lags (the multiples of the seasonal period). 1 2 You are entitled to treat nonsignificant values as zero. That is, you can ignore values that lie within the confidence intervals on the plots. You do not have to ignore them, however, particularly if they continue the pattern
- 74. of the statistically significant values. An occasional autocorrelation will be statistically significant by chance alone. You can ignore a statistically significant autocorrelation if it is isolated, preferably at a high lag, and if it does not occur at a seasonal lag. Consult any text on ARIMA analysis for a more complete discussion of ACF and PACF plots. ARIMA(0,0,1), θ>0 ACF PACF 3 Guide to ACF/PACF Plots ARIMA(0,0,1), θ<0 ACF PACF ARIMA(0,0,2), θ1θ2>0 ACF PACF 4 ARIMA(1,0,0), φ>0
- 75. ACF PACF ARIMA(1,0,0), φ<0 ACF PACF 5 Guide to ACF/PACF Plots ARIMA(1,0,1), φ<0, θ>0 ACF PACF ARIMA(2,0,0), φ1φ2>0 ACF PACF 6 ARIMA(0,1,0) (integrated series) ACF Table of Contents1. Guide to ACF/PACF PlotsIndex FMBF computer lab2.pdf FMBF: Computer Practical 2
- 76. Introduction This workshop session covers cointegration, using the Engle- Granger and Johansen approaches. You should be aware of the benefits and drawbacks of each approach. 1 Engle-Granger Exercise 1: Cointegration between the S&P and FTSE All-Share 1. Load the data file FMBF Prac2.xls from duo. This contains monthly data on the S&P 500 and FTSE All Share from January 1 1965 to January 1 2004. 2. Log both series (Calculator) and then use the unit root testing facility in Descriptive Statistics to assess the degree of integration of the series (Model > Category: Other models; Model class: Descriptive statistics using PcGive). Notes: most financial variables are I(1) series. To conduct the EG procedure, we should firstly check whether the two time series are I(1). 3. Regress LS&P on LFTSE and a constant using OLS (Model > Category: Models for time-series data; Model class: Single-equation dynamic
- 77. Modelling using PcGive). 4. Save the cointegration regression residual in the database (Test > Test Menu: Store Residuals etc. in Database… > Store in database: Residuals). 5. Test for cointegration by performing a unit-root test on the saved residuals (do not include deterministic components here). 6. Evaluate the results and establish whether or not the series cointegrate (note: make sure you use the correct critical values). 7. If appropriate, build an ECM. Do this by regressing DLS&P on a constant, DLFTSE and the one-period lagged residuals that were previously stored in the database. Interpret your findings. Notes: according to the unit root test of the residuals, since the
- 78. residuals are not stationary, it is not appropriate to put the non-stationary residuals into the ECM. In other words, the residuals are I(1). Therefore, we should estimate a model containing only first differences. 2 Johansen Example 1: Long-run PPP This is a PcGive implementation of the long-run purchasing power parity example presented in Verbeek (2004, p.331). We begin by loading the data file ppp.xls from duo, which contains monthly observations from 1981:1 to 1996:6 on price indices and exchange rates from France and Italy. The variables contained in the file are as follows: This example investigates the concept of PPP, where exchange rate equals the ratio of price levels. In logarithms, we represent PPP as: *
- 79. ttt (1) where t s is the log of the spot exchange rate, t p is the log of domestic prices and * t p is the log of foreign prices. 1. Following Verbeek's reasoning we will first run a test with p = 3, excluding a time trend (Model > Category: Models for time-series data; Model class: Multiple-equation dynamic Modelling using PcGive). Note that PcGive automatically restricts the Constant term (shown by the U to its left. We remove this to restrict the constant following Verbeek's example. Select U Constant in
- 80. Selection > Change Use default status to Clear status and click Set, then the U is removed. Note that this now corresponds to Model 2 in the Pantula Principle). Click OK and choose Unrestricted system. 2. Press Test > Test Menu: Dynamic Analysis and Cointegration Tests... > Dynamic Analysis: I(1) cointegration analysis > OK. You are presented with results, the firrst part of which are the eigenvalues: We can see from the results that there are two small eigenvalues that are significant at the 1 percent level. In this case we reject H0 : r = 0 and also H0 : r = 1, but we cannot reject H0 : r = 2 against the alternative of H1 : r = 3. Therefore using Johansen we conclude that there are two cointegrating relationships. P-values are based on Doornik (1998) (reprinted in McAleer and Oxley (1999)). Verbeek (2004, p.332) reminds us that in this particular example, Engle-Granger finds that the null
- 81. of no cointegration could not be rejected. (Note: you can follow the E-G procedure that was used above to verify this). One possible explanation is that the number of lags is too small. Therefore we formulate a model with p = 12, supported by the use of monthly data: These results are clearly weaker than with p = 3. We do, however, have a rejection of H0 : r = 1. We can now move on to build a cointegrated VAR model. We will assume r = 1. 3. Formulate the model used for estimating the cointegration test for p = 12. Remember that we have a restricted constant (Model > Category: Models for time-series data; Model class: Multiple-equation dynamic Modelling using PcGive). 4. Click OK and then select Cointegrated VAR and press OK once more.
- 82. 5. In the Cointegrated VAR Settings dialog box make sure the Cointegrating rank is set to 1. Click OK and OK to estimate a Reduced Rank Regression You should be presented with the following output in the Results: The most interesting part of these results, relating to estimating the cointegrating vector, β, are shown under Reduced form beta. The normalized cointegrating therefore corresponds to: * 756.14346.6 ttt As Verbeek, p.332 points out, this “does not seem to correspond to an economically interpretable long-run relationship.”
- 83. 3 The Pantula Principle Following Johansen (1992) we can use the so-called Pantula Principle to determine the choice for deterministic components in the cointegration space and/or the short-run, and also establish the order of the cointegration rank r. Recall that we estimate all three models and present the results from the r = 0 (model 2, the most restrictive) to r = n-1 (model 4, the least restrictive). Moving through these models and examining them in turn, we look to the trace statistic and stop once the null hypothesis cannot be rejected. In the case of the example we are concerned with identifying the deterministic components. One further point to consider are the correct critical values for models 1 to 4. Exercice 2: The Pantula Principle In the above worked example we estimated a long-run PPP model and tested for
- 84. cointegration. Effectively, what we did corresponds with Model 2 in the Pantula Principle. timating Models 2, 3 and 4 in sequence. You should examine your results and establish which specification is preferred. To assist you, Table 1 contains pointers on setting up each model in PcGive. It is helpful to construct a table similar to Table 5.5 in Harris and Sollis (2003). You should come to your own conclusion about this by first looking at appropriate graphic analysis. Specifically you can go to Test > Graphic Analysis and look at Actual and fitted values, Cross plot of actual and fitted, Residuals (scaled), Residual density and histogram (kernel estimate) and Residual correlogram (ACF). preferred model. You should
- 85. examine F-tests on the retained regression to see if it is possible to delete all the lags of the same length (i.e. those that are not significant) whilst keeping the sample period unchanged. You can use Test > Exclusion Restrictions... to evaluate. Summary for equation-by-equation and system-wide tests, which you should examine. 3.1 Imposing Restrictions We can test for restrictions on α and β with PcGive. For example, to test the restriction We would go to Model > Category: Models for time-series data; Model class: Multiple-equation dynamic Modelling using PcGive and select Cointegrated VAR.
- 86. Press OK and enter a Cointegrating rank of 1. We then select General restrictions and press OK. The General Restrictions dialog box opens, where we specify the restriction in the form &1=0;&2=0;&3=0 - see Figure 2 for a screenshot. We are testing a null of weakly exogenous - you may wish to try this for the PPP model estimated above. We can also use PcGive's ability to impose general restrictions to test for unique cointegrating vectors and in addition jointly test restrictions on α and β. See Harris and Sollis (2003, p.135-163) for full details, examples and references to imposing restrictions in PcGive. 4 Points to note
- 87. - G and Johansen approaches to cointegration. whether the smallest k - r0 eigenvalues significantly differ from 0. However, we can also use the maximum eigenvalue test. This tests H0 : r ≤ r0 against H1 : r = r0 + 1. PcGive gives the eigenvalues so it is possible to calculate these. For example, in the PPP example the first eigenvalue is 0.30091 so the ax m as 183*LN(1-0.30091), i.e. 65.509 which can be set against the correct critical value, in this case 22.04. References J. A. Doornik. Approximations to the asymptotic distribution of cointegration tests.
- 88. Journal of Economic Surveys, 12:573{593, 1998. R. Harris and R. Sollis. Apple Time Series Modelling and Forecasting. John Wiley & Sons Ltd., Chichester, 2003. D. F. Hendry and J. A. Doornik. Empirical Econometric Modelling Using Pc-Give, volume 1. Timberlake Consultants Ltd., 3 edition, 2001. S. Johansen. Cointegration in partial systems and the effciency of single equation analysis. Journal of Econometrics, 52:389{402, 1992. M. McAleer and L. Oxley. Practical Issues in Cointegration Analysis. Blackwell Publishers, Oxford, 1999. M. Verbeek. A Guide to Modern Econometrics. John Wiley & Sons, Inc., 2004. Johansen Test by PcGive(computer lab2).pdf — Appendix ————-— Cointegration Analysis Using the Johansen Technique: A Practitioner's __ Guide to PcGive 10.1
- 89. This appendix provides a basic introduction on how to implement the Johan- sen technique using the PcGive 10.1 econometric program (see Doornik and Hendry, 2001 for full details). Using the same data set as underlies much of the analysis in Chapters 5 and 6, we show the user how to work through Chapter 5 up to the point of undertaking joint tests involving restrictions on a and p. This latest version of PcGive brings together the old PcGive (single equa- tion) and PcFiml (multivariate) stand-alone routines into a single integrated software program (that in fact is much more than the sum of the previous versions, since it is built on the Ox programming language and allows various bolt-on Ox programs to be added—such as dynamic panel data analysis (DPD), time series models and generalized autoregressive conditional heteroscedastic (GARCH) models—see Chapter 8). It is very flexible to operate, providing drop-down menus and (for the present analysis) an extensive range of modelling features for 7(1) and 7(0) systems (and limited analysis of the 7(2) system).1 Cointegration facilities are embedded in an overall modelling strategy leading through to structural vector autoregression (VAR) modelling.
- 90. After the data have been read-in to GiveWin2 (the data management and graphing platform that underpins PcGive and the other programs that can operate in what has been termed the Oxmetrics suite of programs), it is first necessary to (i) start the PcGive module, (ii) select 'Multiple- equation Dynamic Modelling' and then (iii) 'Formulate' a model. This allows the user to define the model in (log) levels, fix which deterministic variables should enter the co- integration space, determine the lag length of the VAR and decide whether 1 PcGive also allows users to run batch jobs where previous jobs can be edited and rerun. 2 The program accepts data files based on spreadsheets and unformatted files. 260 APPENDIX Figure A.I. Formulating a model in PcGive 10.1: Step (1) choosing the correct model option. 7(0) variables, particularly dummies, need to be specified to enter the model in the short-run dynamics but not in the cointegration spaces (see Figures A. 1 and A.2). When the 'Formulate' option is chosen, the right-hand area under 'Data-
- 91. base' shows the variables available for modelling. Introducing dummies and transformations of existing variables can be undertaken using the 'Calculator' or 'Algebra Editor' under Tools' in GiveWin, and these new variables when created will also appear in the 'Database'. In this instance, we will model the demand for real money (rm) as a function of real output (y), inflation (dp) and the interest rate (rstar), with all the variables already transformed into log levels. The lag length (k) is set equal to 4 (see lower right-hand option in Figure A.2); if we want to use an information criterion (1C) to set the lag length, then k can be set at different values, and when the model is estimated it will produce the Akaike, Hannan—Quinn and Schwarz 1C for use in deter- mining which model is appropriate.3 (However, it is also necessary to ensure that the model passes diagnostic tests with regard to the properties of the residuals of the equations in the model—see below—and therefore use of an 1C needs to be done carefully.) Each variable to be included is highlighted in the 'Database' (either one at a time, allowing the user to determine the order in which these variables enter, or all variables can be simultaneously highlighted). This will bring up an '<<Add' option, and, once this is clicked on, then the model selected appears
- 92. on the left-hand side under 'Model'. The 'Y' next to each variable indicates 3 Make sure you have this option turned on as it is not the default. To do this in PcGive. choose 'Model', then 'Options', 'Additional output' and put a cross in the information criterion box. APPENDIX , 261 Figure A.2. Formulating a model in PcGive 10.1: Step (2) choosing the 'Formulate' option. that it is endogenous and therefore will be modelled, a 'IT indicates the vari- able (e.g., the Constant, which enters automatically) is unrestricted and will only enter the short-run part of the vector error correction model (VECM), and the variables with '_k' next to them denote the lags of the variable (e.g., rmt – 1). We also need to enter some dummies into the short-run model to take account of'outliers' in the data (of course we identify these only after estimating the model, checking its adequacy, and then creating deterministic dummies to try to overcome problems; however, we shall assume we have already done this,4
- 93. 4 In practice, if the model diagnostics—see Figure A.3— indicates, say, a problem of non-normality in the equation determining a variable, plot the residuals using the graphing procedures (select, in PcGive, 'Test' and 'Graphic analysis' and then choose 'Residuals' by putting a cross in the relevant box). Visually locate outliers in terms of when they occur, then again under 'Test' choose 'Store residuals in database', click on residuals and accept the default names (or choose others) and store these residuals in the spreadsheet. Then go to the 'Window' drop-down option in Give Win and select the database, locate the residuals just stored, locate the outlier residuals by scrolling down the spreadsheet (using the information gleaned from the graphical analysis) and then decide how you will 'dummy out' the outlier (probably just by creating a dummy variable using the 'Calculator' option in Give Win, with the dummy being 0 before and after the outlier date and 1 for the actual date of the outlier). 262 APPENDIX or that ex ante we know such impacts have occurred and need to be included). Hence, highlight these (dumrst, dumdp, dumdpl), set the lag length option at the bottom right-hand side of the window to 0 and then click on '<Add'. Scroll down the 'Model' window, and you will see that these dummies have 'Y' next to
- 94. them, which indicates they will be modelled as additional variables. Since we only want them to enter unrestrictedly in the short-run model, select/highlight the dummies and then in the 'Status' options on the left-hand side (the buttons under 'Status' become available once a variable in the model is highlighted) click on 'Unrestricted', so that each dummy now has a 'U' next to it in the model. Finally, on the right-hand side of the 'Data selection' window is a box headed 'Special'. These are the deterministic components that can be selected and added to the model. In this instance, we select 'CSeasonal (centred seasonal dummies), as the data are seasonally unadjusted, and add the seasonal dummies to the model. They automatically enter as unrest- ricted. Note that if the time 'Trend' is added, it will not have a 'U' next to it in the model, indicating it is restricted to enter the cointegration space (Model 4 in Chapter 5—see equation (5.6)). If we wanted to select Model 2 then we would not enter the time trend (delete it from the model if it is already included), but would instead click on 'Constant' in the 'Model' box and click on 'Clear' under the 'Status' options. Removing the unrest- ricted status of the constant will restrict it to enter the cointegration space.
- 95. Thus, we can select Models 2–4, one at a time, and then decide which deterministic components should enter II, following the Pantula principle (see Chapter 5). Having entered the model required, click OK, bringing up the 'Model settings' window, accept the default of 'Unrestricted system' (by clicking OK again) and accept ordinary least squares (OLS) as the estimation method (again by clicking OK). The results of estimating the model will be available in Give Win (the 'Results' window—accessed by clicking on the Give Win toolbar on your Windows status bar). Return to the PcGive window (click on its toolbar), choose the 'Test' option to activate the drop- down options, and click on 'Test summary'. This produces the output in GiveWin as shown in Figure A.3. The model passes the various tests equation by equation and by using system-wide tests. Several iterations of the above steps are likely to be needed in practice to obtain the lag length (k) for the VAR, which deterministic components should enter the model (i.e., any dummies or other 7(0) variables that are needed in the short-run part of the VECM to ensure the model passes the diagnostic tests on the residuals) and which deterministic components should enter the
- 96. cointegration space (i.e., should the constant or trend be restricted to be included in II). To carry out the last part presumes you have already tested for the rank of II, so we turn to this next. To undertake cointegration analysis of the I(1) system in PcGive, choose Test', then 'Dynamic Analysis and Cointegration tests' and check the "7(1) APPENDIX rm Y dp rstar rm Y dp rstar rm Y dp rstar rm y dp rstar rm y dp rstar
- 97. 263 Portmanteau(11): Portmanteau(11) : Portmanteau(11): Portmanteau(11) : AR 1-5 test: AR 1-5 test: AR 1-5 test: AR 1-5 test: Normality test: Normality test: Normality test: Normality test: ARCH 1-4 test: ARCH 1-4 test: ARCH 1-4 test: ARCH 1-4 test: hetero test: hetero test: hetero test: hetero test: 11.2164 6.76376 3.66633 11.6639 F(5, F(5, F(5, F(5, Chi' Chi- Chi' Chi' F(4,
- 99. = 1 -I - 0. = 0. = 0. = 0. - 0. .4131 .8569 .0269 .8359 .8297 .0521 .6973 .7019 .5882 .1669 .1133 68023 38980 72070 67314 88183
- 100. [0. [0. [0. [0. [0. [0. [0. [0. [0. [0. [0. [0. [0. [0. [0. [0. 2297] 1125] 4083] 1164] 2430] 0800] 0955] 2590] 1871] 3329] 3573] 6080] 9974] 8385] 8838] 6463] Vector Portmanteau(ll): 148.108 Vector AR 1-5 test: F(80,219)= 1.0155 [0.4555]
- 101. Vector Normality test: Chi'2(8) = 15.358 [0.0525] Vector hetero test: F(350,346)= 0.47850 [1.0000] Not enough observations for hetero-X test Figure A.3. Estimating the unrestricted VAR in PcGive 10.1; model diagnostics. cointegration analysis' box.5 The results are produced in Figure A.4,6 provid- ing the eigenvalues of the system (and log-likelihoods for each cointegration rank), standard reduced rank test statistics and those adjusted for degrees of freedom (plus the significance levels for rejecting the various null hypotheses) and full-rank estimates of a, p and IT (the P are automatically normalized along the principal diagonal). Graphical analysis of the (J-vectors (unadjusted and adjusted for short-run dynamics) are available to provide a visual test of which vectors are stationary,7 and graphs of the recursive eigenvalues associated with each eigenvector can be plotted to consider the stability of the cointegration vectors.8 5 Note that the default output only produces the trace test. To obtain the A-max test as well as the default (and tests adjusted for degrees of freedom), in PcGive choose 'Model', then 'Options', 'Further options' and put a cross in the box for cointegration test with Max test. 6 Note that these differ from Box 5.5 and Table 5.5, since the latter are based on a model
- 102. without the outlier dummies included in the unrestricted short- run model. 7 The companion matrix that helps to verify the number of unit roots at or close to unity, corresponding to the 7(1) common trends, is available when choosing the 'Dynamic analysis' option in the 'Test' model menu in PcGive. 8 Note that, to obtain recursive options, the 'recursive estimation' option needs to be selected when choosing OLS at the 'Estimation Model' window when formulating the model for estimation. 264 APPENDIX 1(1) cointegration analysis, 1964 (2) to 1989 (2) eigenvalue 0.57076 0.11102 0.063096 0.0020654 loglik for rank 1235.302 0 1278.012 1 1283.955 2 1287.246 3 1287.350 4 rank Trace test [ Prob] Max test [ Prob] Trace test [T-nm] Max test [T-nm] 0 104.10 [0.000]** 85.42 [0.000]** 87.61 [0.000]** 71.89 [0.000]'
- 103. 1 18.68 [0.527] 11.89 [0.571] 15.72 [0.737] 10.00 [0.747] 2 6.79 [0.608] 6.58 [0.547] 5.72 [0.731] 5.54 [0.676] 3 0.21 [0.648] 0.21 [0.648] 0.18 [0.675] 0.18 [0.675] Asymptotic p-values based on: Unrestricted constant Unrestricted variables: [0] = Constant [1] = CSeasonal [2] = CSeasonal_l [3] = CSeasonal_2 [4] = dumrst [5] = dumdp [6] = dumdp1 Number of lags used in the analysis: 4 beta (scaled on diagonal; cointegrating vectors in columns) rm y dp rstar 1.0000 -1.0337 6.4188 6.7976 15.719 1.0000 -207.49 131.02 -0.046843 0.064882 1.0000 -0.039555
- 104. 1.6502 -0.13051 8.6574 1.0000 alpha rm -0.18373 y -0.0081691 dp 0.022631 rstar 0.0046324 0.00073499 -0.0010447 0.00023031 -0.0011461 0.0012372 -0.16551 -0.042258 -0.0022919 -0.0010530 -0.00080063 0.0010822 0.0018533 long-run matrix, rank 4 rm y rm -0.17397 0.19088 y -0.018159 -0.0032342 dp 0.030017 -0.026047 rstar -0.010218 -0.0063252
- 105. dp -1.3397 -0.0081182 0.064590 0.28129 rstar -1.1537 -0.18666 0.18677 -0.11673 Figure A.4. 7(1) cointegration analysis in PcGive 10.1. After deciding on the value of r < n, it is necessary to select a reduced rank system. In PcGive, under 'Model', choose 'Model settings' (not 'Formulate'), select the option 'Cointegrated VAR' and in the window that appears set the cointegration rank (here we change '3' to '1', as the test statistics indicate that r — 1). Leave the 'No additional restrictions' option unchanged as the default, click OK in this window and the next, and the output (an estimate of the new value of II together with the reduced-form cointegration vectors) will be written to the results window in GiveWin. Finally, we test for restrictions on a and p (recall that these should usually be conducted together). To illustrate the issue, the model estimated in Chapter 6
- 106. APPENDIX , , 265 Figure A.5. Testing restrictions on a and B using 'General Restrictions' in PcGive 10.1. is chosen (instead of the one above) with a time trend restricted into the cointegration space and r — 2. Thus, we test the following restrictions: , r-i i * * o [ 0 — 1 * * * ,_ r* o * o ~~ L* o * o using the option 'General restrictions'. To do this in PcGive, under 'Model', choose 'Model settings', select the option 'Cointegrated VAR' and in the window that appears set the cointegration rank (here we change '3' to '2', since we have chosen r = 2). Click the 'General restrictions' option, type the relevant restrictions into the window (note that in the 'Model' the parameters are identified by '&' and a number—see Figure A.5), click OK in this window (and the next) and the results will be written into Give Win (Figure A.6—see also the top half of Box 6.1). CONCLUSION
- 107. For the applied economist wishing to estimate cointegration relations and then to test for linear restrictions, PcGive 10.1 is a flexible option. But there are others. Harris (1995) compared three of the most popular options available in the 1990s (Microfit 3.0, Cats (in Rats) and PcFiml—the latter the predecessor to the current PcGive). The Cats program9 has seen little development since its 9 Cointegration Analysis of Times Series (Cats in Rats), version 1.0, by Henrik Hansen and Katrina Juselius, distributed by Estima. 266 APPENDIX Cointegrated VAR (4) in: [0] - rm tl] = y [2] = dp [3] = rstar Unrestricted variables: [0] = dumrst [1] = dumdp [2] = dumdp 1 [3] = Constant [4] = CSeasonal [5] = CSeasonal_l [6] = CSeasonal_2 Restricted variables: [0] = Trend Number of lags used in the analysis: 4 General cointegration restrictions:
- 108. &8=-l;&9=l;&12=0; &13=0;&14=-1; &2=0;&3=0;&6=0;&7=0; beta rm y dp rstar Trend -1.0000 1.0000 -6.5414 -6.6572 0.00000 0.00000 -1.0000 2.8091 -1.1360 0.0066731 Standard errors of beta rm y dp rstar Trend alpha rm y dp rstar
- 109. 0.00000 0.00000 0.88785 0.33893 0.00000 0.17900 0.00000 -0.011637 0.00000 0.00000 0.00000 0.46671 0.19346 0.00020557 0.083003 0.00000 -0.15246 0.00000 Standard errors of alpha rm 0.018588 0.074038 y 0.00000 0.00000 dp 0.0078017 0.031076 rstar 0.00000 0.00000 log—likelihood 1290.6274 -T/2log|Omega| 1863.87857 no. of observations 101 rank of long-run matrix 2 beta is identified AIC -35.2253