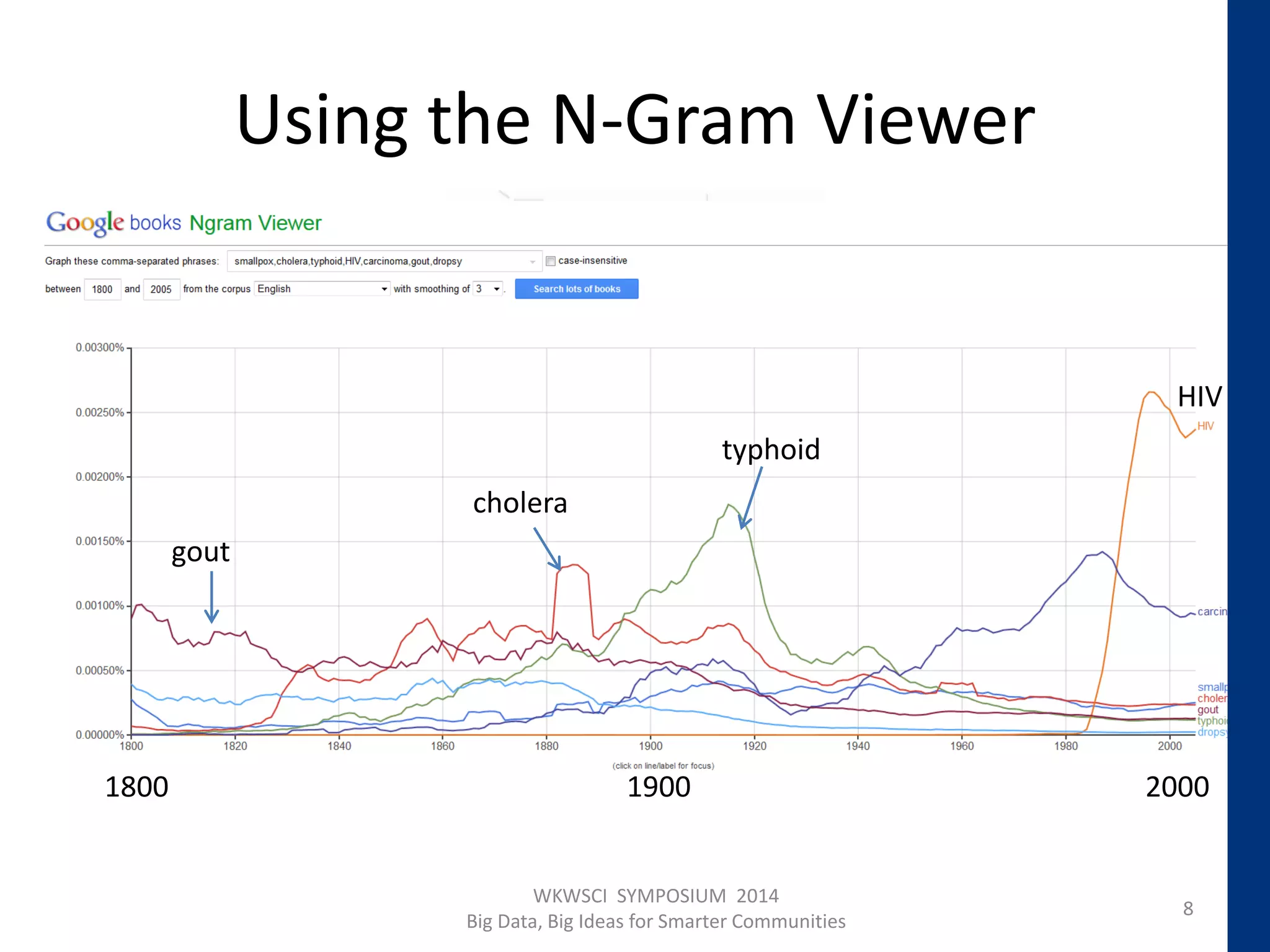
The document discusses the challenges and opportunities presented by big text data, highlighting its rise from large bibliographic databases to contemporary sources like digitized books and social media. It emphasizes issues such as quality, reliability, and processing complexities, while also introducing the concept of culturomics, which analyzes cultural trends through large datasets of digitized texts. Additionally, it explores various text processing techniques and applications, including sentiment analysis and trend prediction, along with critiques of their limitations.