Downloaded 57 times












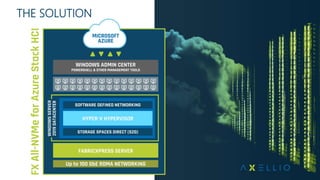






The document discusses simplifying enterprise hybrid cloud environments using Azure Stack HCI, emphasizing challenges like data migration and workload management. It proposes solutions like hyper-converged infrastructure (HCI) to consolidate on-premises resources and integrate cloud services, allowing for scalable and efficient workload handling. The approach includes utilizing advanced hardware, optimized solutions from Axellio, and validated Azure integrations for better management and performance across various workloads.















































![[OpenInfra Days Vietnam 2019] Innovation with open sources and app modernizat...](https://cdn.slidesharecdn.com/ss_thumbnails/innovationwithopensourcesandappmodernizationfordevelopers-dist-190824044544-thumbnail.jpg?width=640&height=640&fit=bounds)







































