Download to read offline







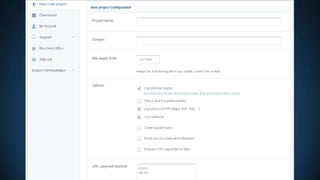
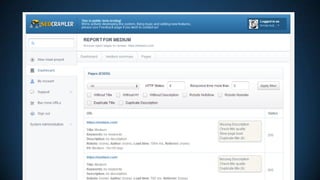
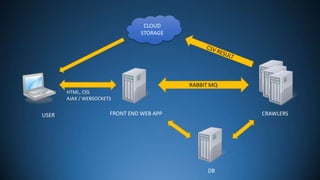

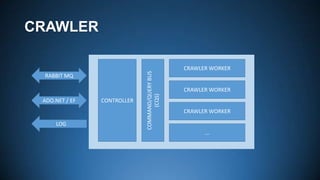

![CRAWLER WORKER PROCESS
Start or Resume
Resume: load state (SQL, serialized)
Get next page from queue (RabbitMQ, durable store)
Download HTML (200ms – 5sec delay), HEAD req for external
Check statuses, canonical, redirects
Run page analysers, extract data for report, prepare for bulk insert
Find links
Check duplicated, blacklisted
Check Robots.txt
Check if visited – cache & db
Normalize & store to queue (RabbitMQ)
Save state every N pages (Serialize with Protobuf, store byte[] to Db)](https://image.slidesharecdn.com/webcamp-seocrawler-131028162714-phpapp02/85/My-weekend-startup-seocrawler-co-14-320.jpg)








This document outlines plans for a web crawling startup called SEOCRAWLER.CO. The startup aims to build a crawler that downloads pages from websites and stores metadata in reports. This will allow marketers and site owners to analyze competitor websites and find broken pages. The founders have already crawled over 2.5 million pages and plan to improve the crawler, reports, and user interface. They are hosting the application on their own servers but may move components to cloud services like Azure or Redis for scaling.




![[Mas 500] Web Basics](https://cdn.slidesharecdn.com/ss_thumbnails/mas-500-3-web-basics-131115130917-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)




































































