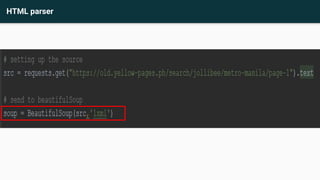
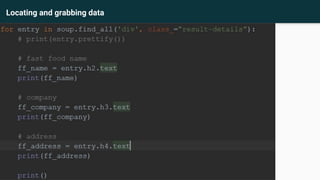
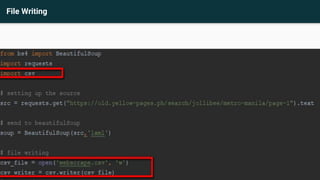
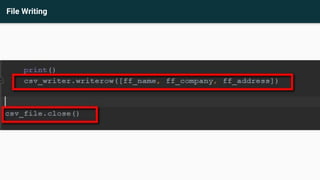
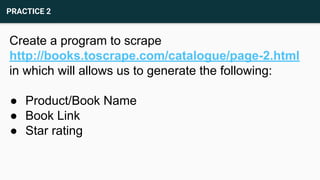
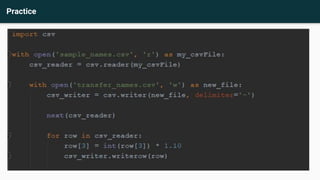
This document provides an agenda and recap for an Advance Python training on web scraping and data analysis. The agenda includes introducing HTML tag familiarization, the data scraping process, and file reading/writing. It also recaps classes, inheritance, and an activity on creating classes. The document then covers introducing web scraping, libraries for scraping (Beautifulsoup4, lxml, requests, html5lib), basic HTML tags, inspecting elements, scraping rules, and practices scraping data from websites and writing to files.

















































![[DSC Europe 24] Domagoj Maric - Modern Web Data Extraction: Techniques, Tools...](https://cdn.slidesharecdn.com/ss_thumbnails/domagojmaric-modernwebdataextractionfinal-250218225444-c7bcad20-thumbnail.jpg?width=640&height=640&fit=bounds)






































