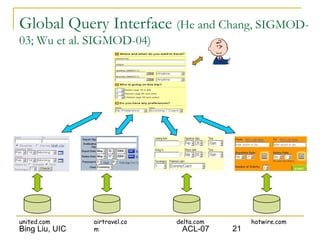
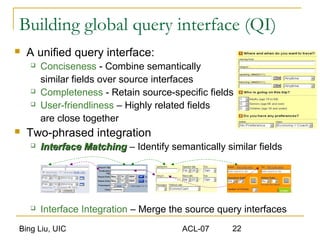
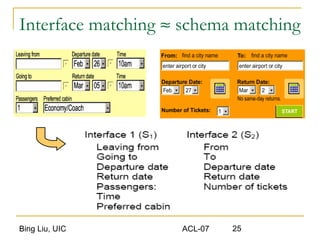
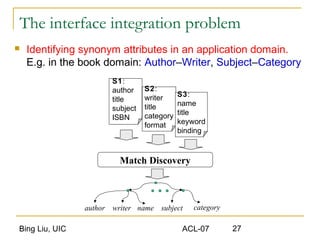
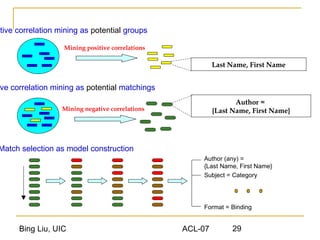
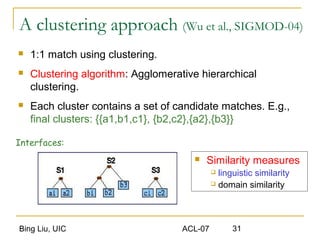
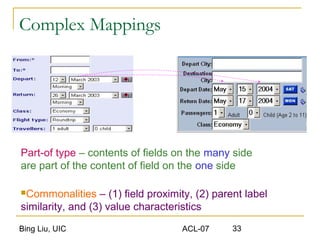
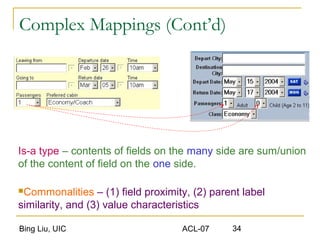
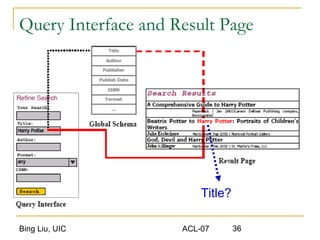
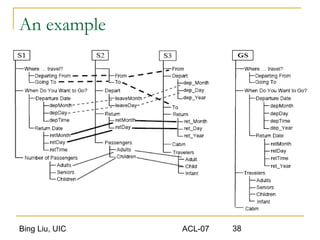
This document discusses techniques for integrating extracted data and schemas. It begins by introducing the problems of column and instance value matching during data integration. It then describes common database integration techniques like schema matching. It also discusses linguistic, constraint-based, domain-level, and instance-level matching approaches. Finally, it covers issues specific to integrating web query interfaces, such as building a global query interface and matching interfaces through correlation mining and clustering algorithms.




















































![[Evaldas Taroza - Master thesis] Schema Matching and Automatic Web Data Extra...](https://cdn.slidesharecdn.com/ss_thumbnails/5c1568bc-753d-44dc-88ac-dcf114742b88-150313043325-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)










































