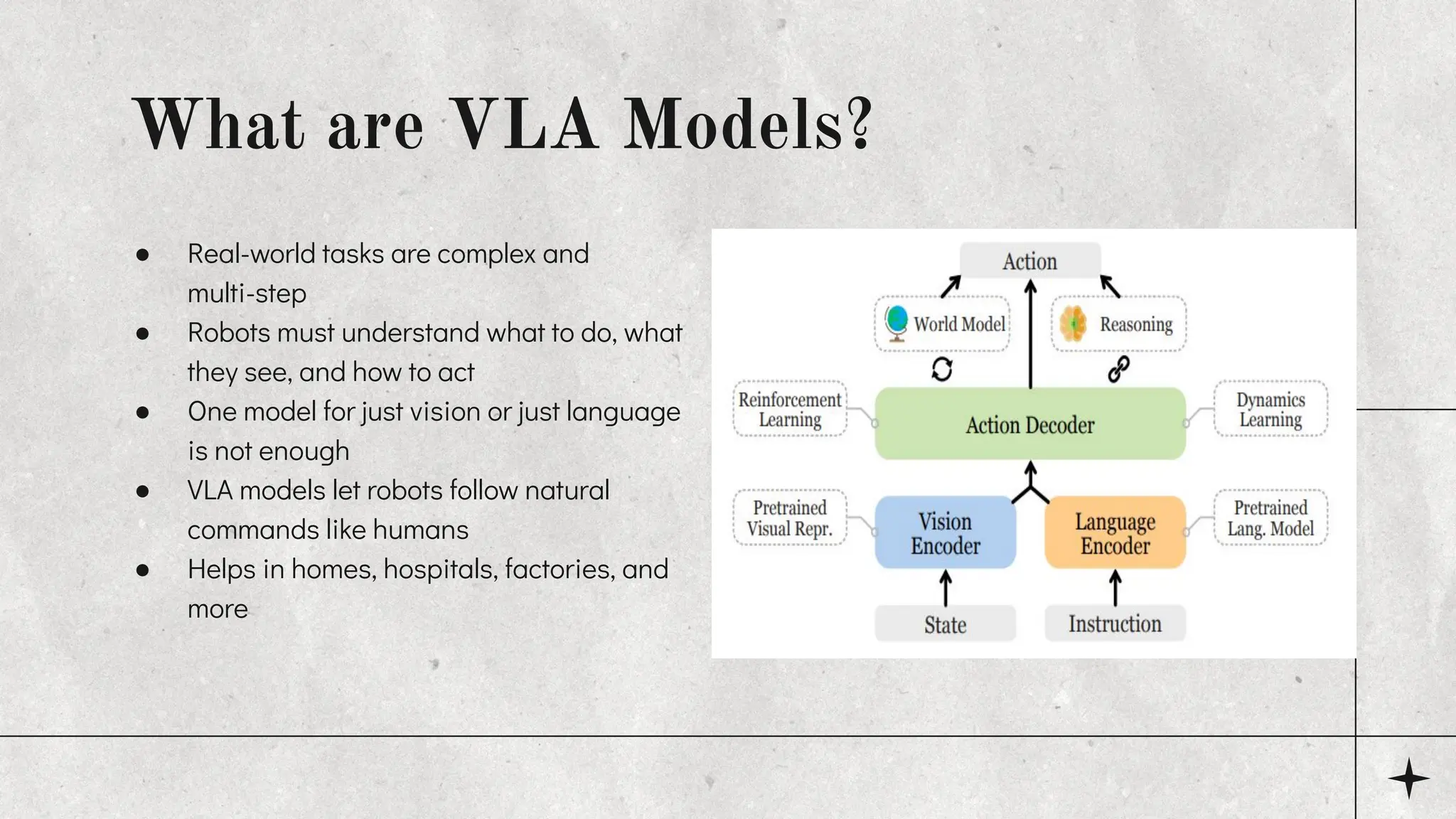
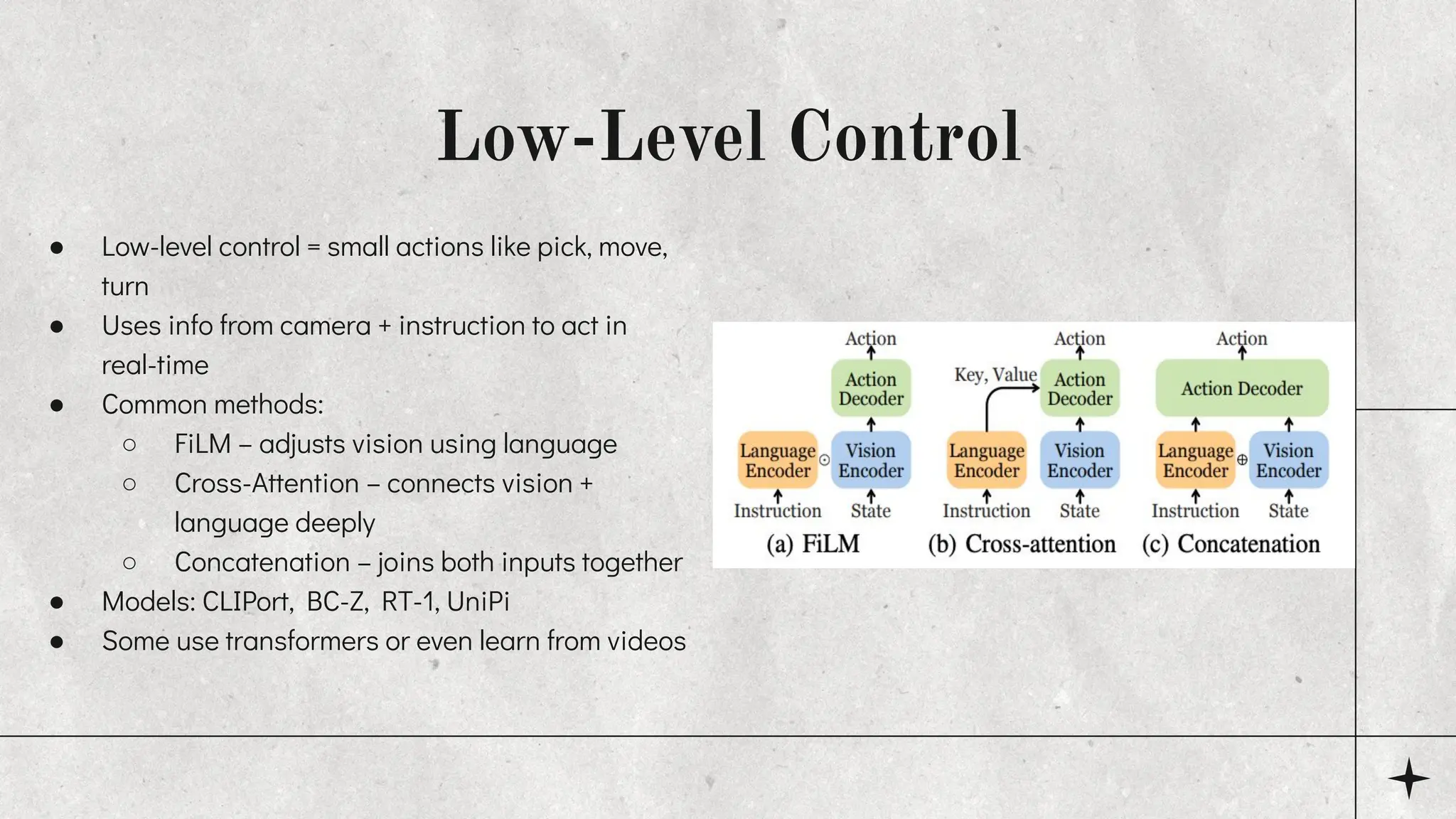
This presentation explains Vision-Language-Action (VLA) models, a new type of AI that combines vision, language, and action to help robots understand and complete real-world tasks. Based on the 2024 survey by Ma et al., it covers the structure, components, training data, challenges, and future of VLA models in Embodied AI. Ideal for students and researchers in deep learning, robotics, and multimodal AI.