Download as PDF, PPTX





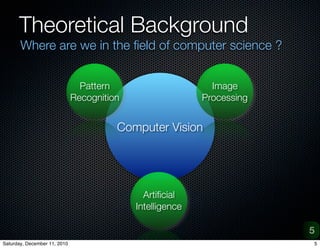



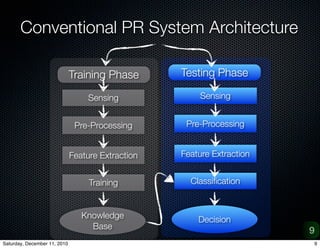






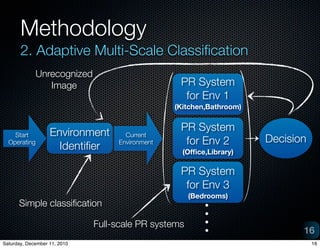




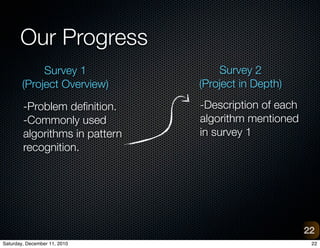
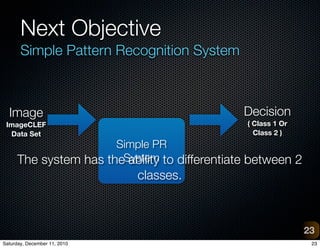


The document provides an overview of a project on vision-based place recognition for autonomous robots. It outlines the objective to localize a robot within an environment using visual cues. The methodology will improve on previous work by combining successful aspects and avoiding limitations. It will use adaptive multi-scale classification to differentiate environments based on discriminative features. Challenges include variations in object appearance and limited robot resources. Testing will use datasets from Bielefeld University and ImageCLEF, as well as a custom data acquisition tool.























![2008 brokerage 04 smart vision system [compatibility mode]](https://cdn.slidesharecdn.com/ss_thumbnails/2008brokerage04-smartvisionsystemcompatibilitymode-100413034051-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![2008 brokerage 04 smart vision system [compatibility mode]](https://cdn.slidesharecdn.com/ss_thumbnails/2008brokerage04-smartvisionsystemcompatibilitymode-100413033730-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



























