Downloaded 33 times









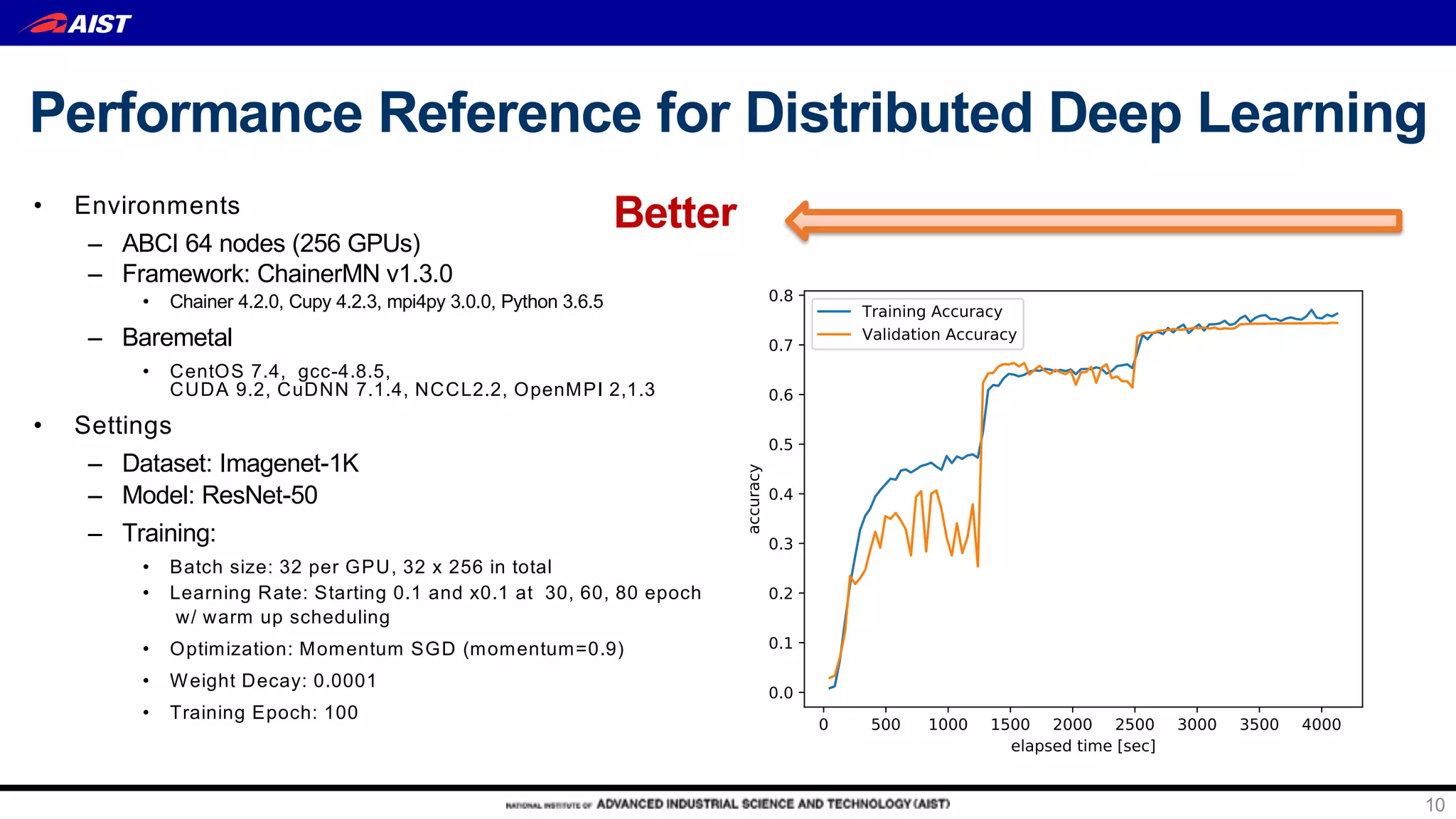

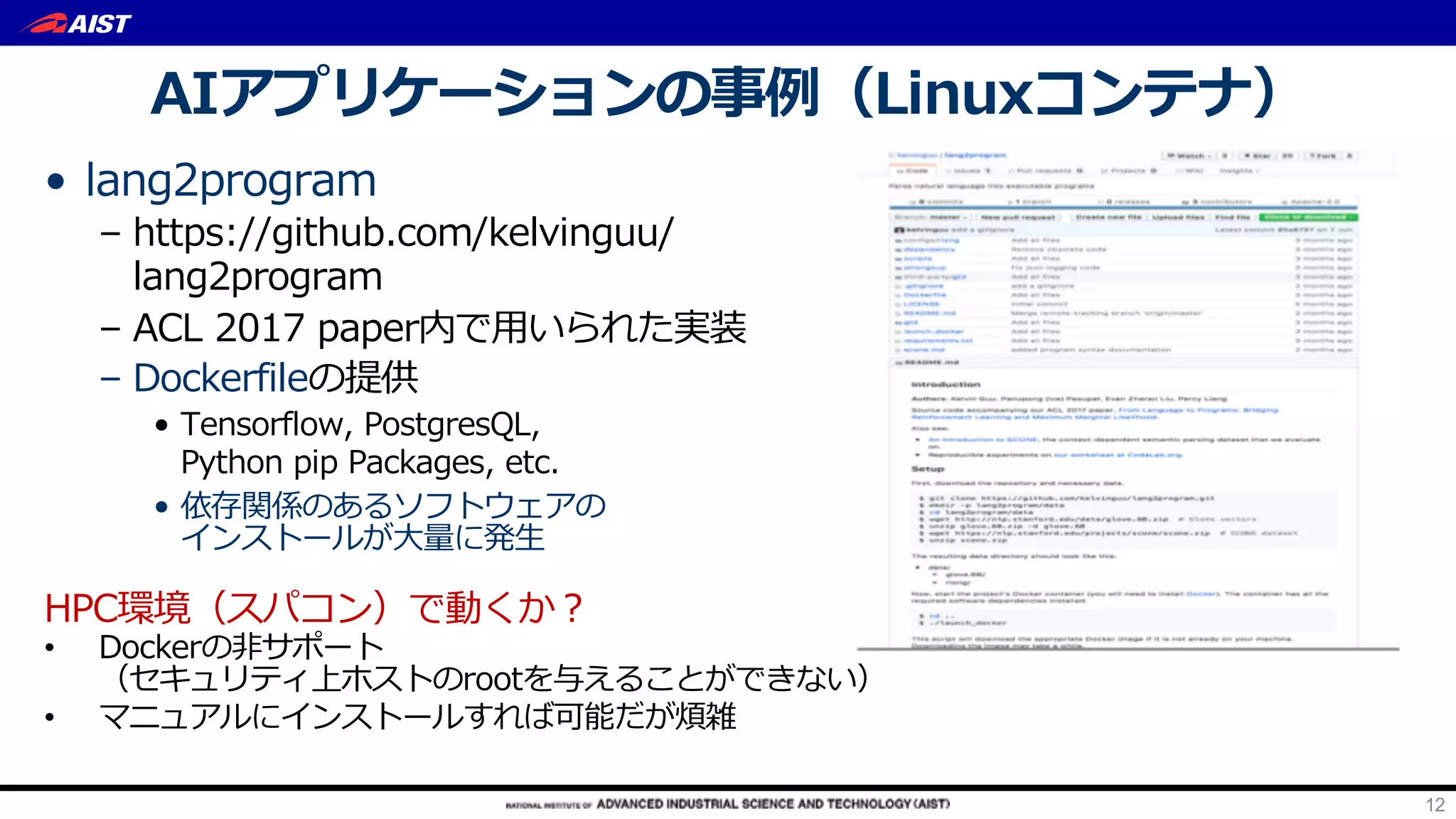

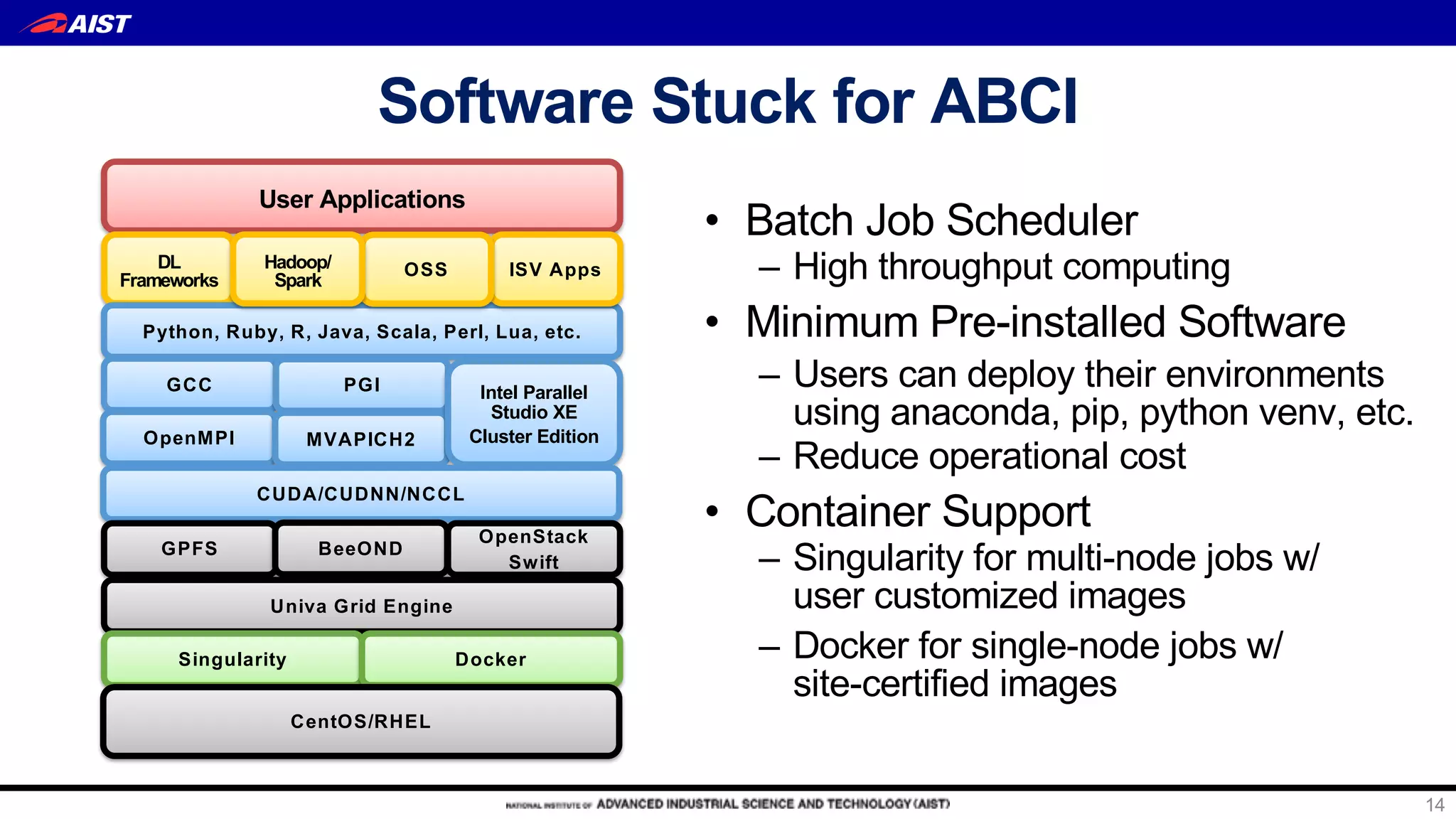
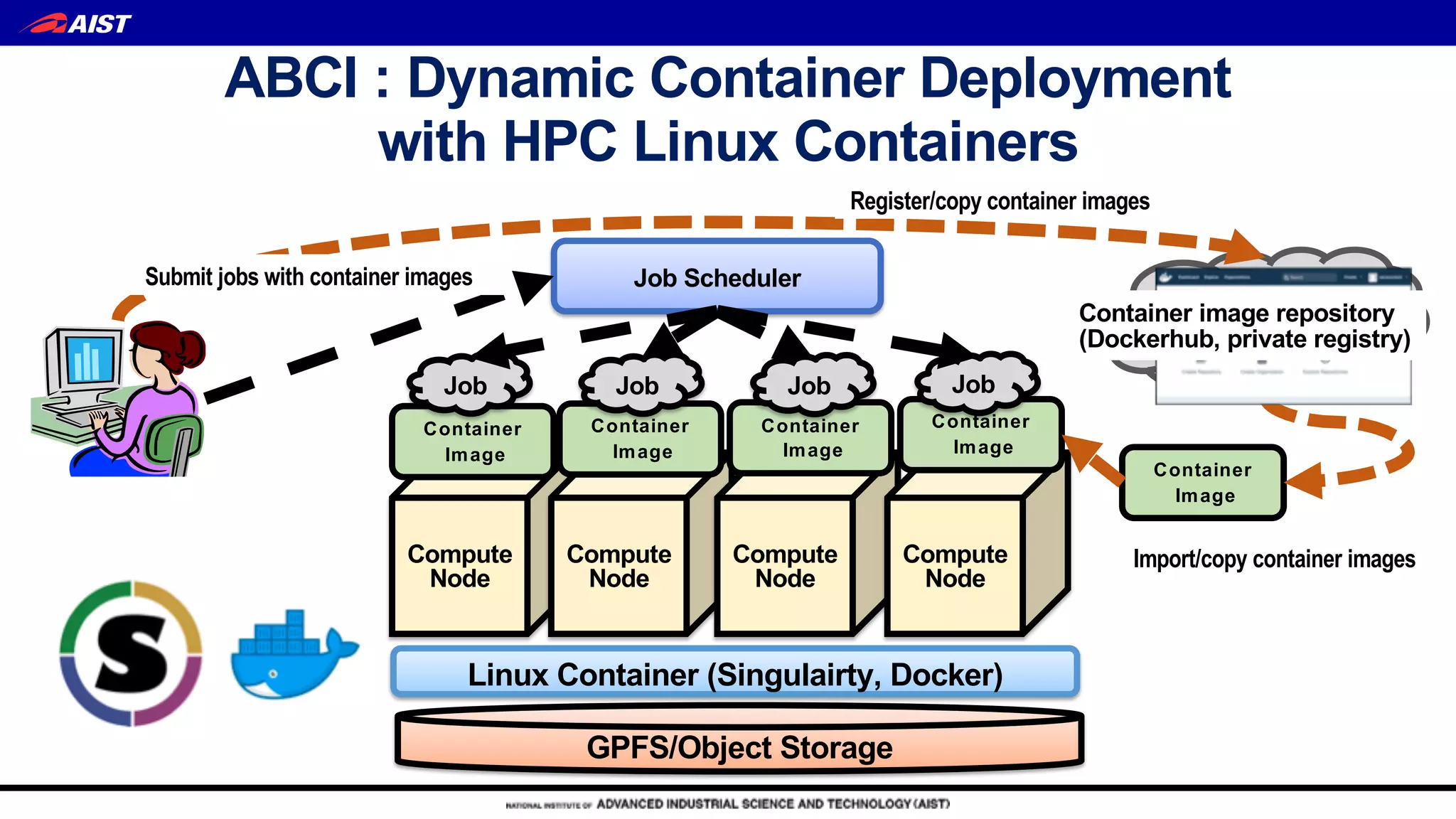










AI Bridging Cloud Infrastructure (ABCI) is a large-scale open AI infrastructure in Japan operated by the University of Tokyo. It provides: 1) Over 0.55 exaflops of computing power with 1088 nodes equipped with 4352 NVIDIA GPUs and 43520 CPU cores for AI and data science research. 2) Dense rack design optimized for thermal management with ambient warm water cooling to achieve high density computing. 3) Hierarchical storage including 1.6PB of local NVMe SSDs, 22PB of parallel file storage, and object storage for burst buffers and campaign storage. 4) Open access platform to accelerate joint academic-industry R&D for AI through distributed



































![[DSC Europe 24] Thomas Kitzler - Building the Future – Unpacking the Essentia...](https://cdn.slidesharecdn.com/ss_thumbnails/thomaskitzler-241220214738-670777be-thumbnail.jpg?width=640&height=640&fit=bounds)




















![ANPARA THERMAL POWER STATION[1] sangam.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/anparathermalpowerstation1sangam-251121115219-9261cde4-thumbnail.jpg?width=640&height=640&fit=bounds)
















