パーティショニングの DDL
-- 親テーブルの作成
=#CREATE TABLE parent (c1 int, c2 int) PARTITION BY RANGE;
-- 子テーブルの作成
=# CREATE TABLE child1 PARTITION OF parent FOR VALUES FROM (0) TO (100);
=# CREATE TABLE child2 PARTITION OF parent FOR VALUES FROM (100) TO (200);
-- 子テーブルの取り外し
=# ALTER TABLE parent DETACH PARTITION child2;
-- 子テーブルの取り付け
=# ALTER TABLE parent ATTACH PARTITION child2 FOR VALUES (100) TO (500);
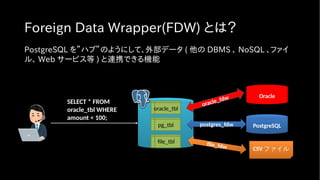
Foreign Data Wrapper(FDW)とは?
OracleOracle
PostgreSQLPostgreSQL
CSV ファイルCSV ファイル
SELECT * FROM
oracle_tbl WHERE
amount < 100;
PostgreSQL を”ハブ”のようにして、外部データ ( 他の DBMS 、 NoSQL 、ファイ
ル、 Web サービス等 ) と連携できる機能
oracle_tbl
pg_tbl
file_tbl
oracle_fdw
postgres_fdwpostgres_fdw
fle_fdw
fle_fdw
21.
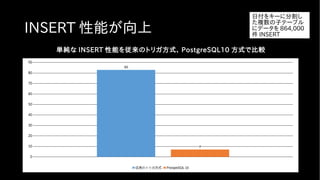
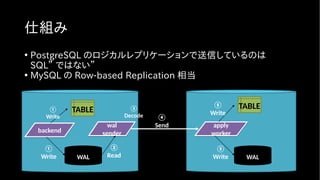
FDW 、 postgres_fdwの機能が強化された
• Join 、 Sort に加え Aggregation (集約)が push down 対応した
• より外部サーバのリソースを使って処理できるようになった
QUERY PLAN
------------------------------------------------------------
Aggregate
Output: sum(col)
-> Foreign Scan on public.s1
Output: col
Remote SQL: SELECT col FROM public.s1
QUERY PLAN
------------------------------------------------------------
Aggregate
Output: sum(col)
-> Foreign Scan on public.s1
Output: col
Remote SQL: SELECT col FROM public.s1
QUERY PLAN
----------------------------------------------------------------
Foreign Scan
Output: (sum(col))
Relations: Aggregate on (public.s1)
Remote SQL: SELECT sum(col) FROM public.s1
QUERY PLAN
----------------------------------------------------------------
Foreign Scan
Output: (sum(col))
Relations: Aggregate on (public.s1)
Remote SQL: SELECT sum(col) FROM public.s1
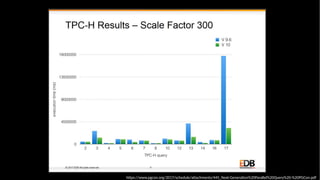
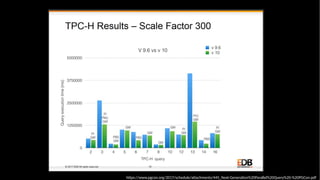
■ 9.6 以前 ■ 10 以降
② ローカルでスキャン結果を
集計
① リモートのデータをスキャン
① リモートでスキャン・集計
を両方実行
SELECT sum(col)
FROM s1; ?
22.
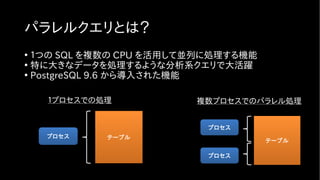
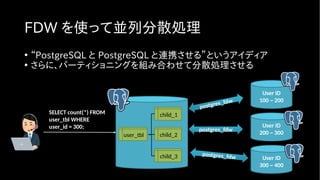
FDW を使って並列分散処理
• “PostgreSQLと PostgreSQL と連携させる”というアイディア
• さらに、パーティショニングを組み合わせて分散処理させる
User ID
100 ~ 200
User ID
200 ~ 300
User ID
300 ~ 400
postgres_fdw
postgres_fdw
postgres_fdwpostgres_fdw
postgres_fdw
postgres_fdw
user_tbl
child_1
child_2
child_3
SELECT count(*) FROM
user_tbl WHERE
user_id = 300;
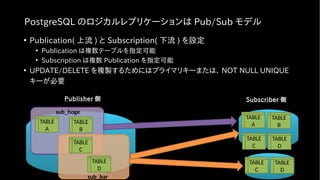
PostgreSQL のロジカルレプリケーションは Pub/Subモデル
• Publication( 上流 ) と Subscription( 下流 ) を設定
• Publication は複数テーブルを指定可能
• Subscription は複数 Publication を指定可能
• UPDATE/DELETE を複製するためにはプライマリキーまたは、 NOT NULL UNIQUE
キーが必要
TABLE
A
TABLE
B
TABLE
C
TABLE
D
sub_hoge
sub_bar
TABLE
A
TABLE
B
TABLE
C
TABLE
D
TABLE
C
TABLE
D
Publisher 側 Subscriber 側
27.
設定例( Publication の作成)
--Publication 作成
=# CREATE PUBLICATION test_pub FOR TABLE t1, t2 WITH (publish = ‘insert, delete’);
-- Publication 確認
=# dRp+
Publication hoge_pub
All tables | Inserts | Updates | Deletes
-------------+----------+-------------+---------
f | t | f | t
Tables:
"public.t1“
"public.t2"
• 複数テーブル、または DB 全体を複製対象として設定可能
• Subscription 毎に複製する操作を指定可能
•




















![モニタリング
-- Publisher 側
=# SELECT application_name, state,
write_lag, flush_lag, replay_lag, sync_state
FROM pg_stat_replication ;
-[ RECORD 1 ]-----+----------------
application_name | hoge_sub
state | streaming
write_lag | 00:00:00.003926
flush_lag | 00:00:00.003926
replay_lag | 00:00:00.003926
sync_state | sync
-- Subscriber 側
=# SELECT * FROM pg_stat_subscription ;
-[ RECORD 1 ]------------+------------------------------
subid | 16388
subname | hoge_sub
pid | 15796
relid |
received_lsn | 0/1693EC8
last_msg_send_time | 2017-07-10 12:30:17.383905-07
last_msg_receipt_time | 2017-07-10 12:30:17.383994-07
latest_end_lsn | 0/1693EC8
latest_end_time | 2017-07-10 12:30:17.383905-07
-- Subscriber 側
=# SELECT * FROM pg_stat_subscription ;
-[ RECORD 1 ]------------+------------------------------
subid | 16388
subname | hoge_sub
pid | 15796
relid |
received_lsn | 0/1693EC8
last_msg_send_time | 2017-07-10 12:30:17.383905-07
last_msg_receipt_time | 2017-07-10 12:30:17.383994-07
latest_end_lsn | 0/1693EC8
latest_end_time | 2017-07-10 12:30:17.383905-07](https://image.slidesharecdn.com/postgresql10-170716013444/85/PostgreSQL10-29-320.jpg)


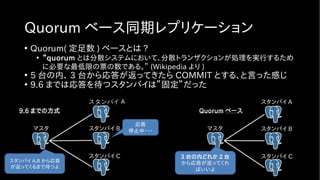
![設定方法
• FIRST 、 ANY で同期方法を選択
• N で台数を指定
• 例
• FIRST 2 (node1, node2, node3)
• node1, node2 の 2 台からの返答を待つ
• ANY 2 (node1, node2, node3)
• node1, node2, node3 の内 2 台からの返答を待つ
synchronous_standby_names = [ ANY | FIRST ] N (node1, node2, ... )synchronous_standby_names = [ ANY | FIRST ] N (node1, node2, ... )](https://image.slidesharecdn.com/postgresql10-170716013444/85/PostgreSQL10-34-320.jpg)





























![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)





























![[db tech showcase Tokyo 2014] C31: PostgreSQLをエンタープライズシステムで利用しよう by PostgreS...](https://cdn.slidesharecdn.com/ss_thumbnails/dbtstokyo2014c31pgeconspostgresql-141120011520-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)



















