












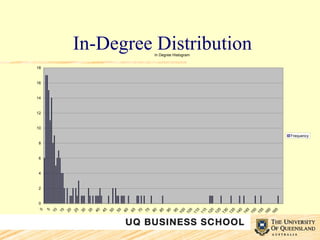











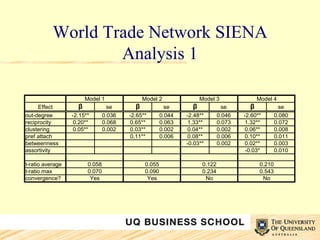
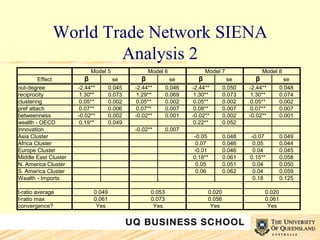
![Interpretation Wealth effect: Although this is a very restricted version of the wealth effect demonstrated in [8], it is still both relatively large and statistically significant. This suggests that at least at the OECD level, the wealth of the countries involved has a strong impact on the formation of new ties. Innovation effect: While the overall fit of Model 6 is good, it is not significantly better than that of the baseline Model 2. Furthermore, the relative size of β for the innovation variable is small. This shows that adding the innovation variable to the model does not improve it sufficiently to justify its inclusion.](https://image.slidesharecdn.com/uqbs-seminar-innovation-networks-steen-kastelle-1227601627493118-9/85/UQBS-Seminar-Innovation-Networks-33-320.jpg)








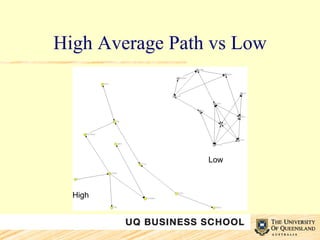
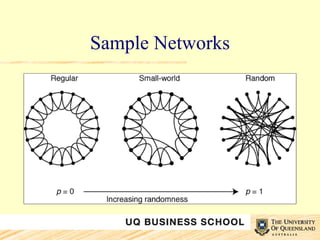
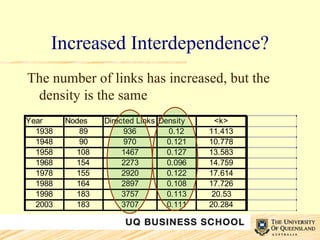
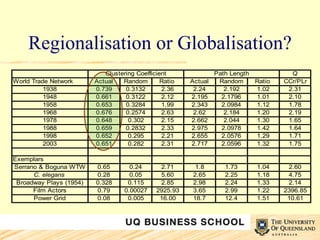
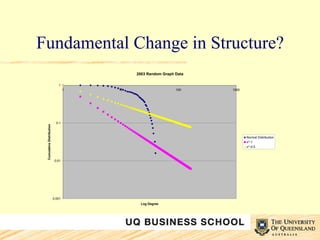
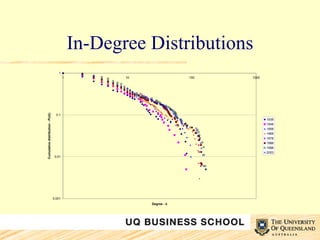
This document discusses network analysis and its use in mapping and analyzing innovation networks. It provides examples of using network analysis to study the international trade network from 1938 to 2003 and a collaborative R&D network. Key network metrics discussed include degree distribution, density, clustering, and average path length. The analysis of the trade network found its overall structure has remained stable over time but countries' interconnectivity has increased. Analysis of an R&D network found those with a small world structure were more innovative.



































































