Download as PDF, PPTX




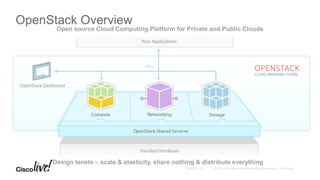
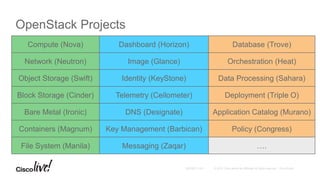


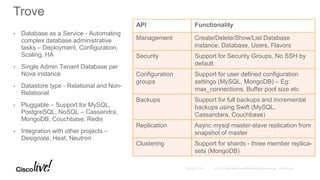



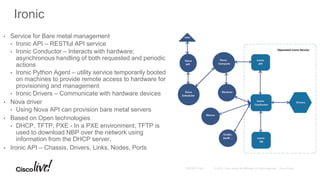








The document provides an overview of upcoming services in OpenStack, including key projects like Trove, Sahara, Ironic, Magnum, and Kolla, highlighting their features and functionalities. It discusses the history and evolution of OpenStack, detailing major releases and contributions over the years. The document emphasizes the ecosystem's expansion and the potential for community involvement.

































































































