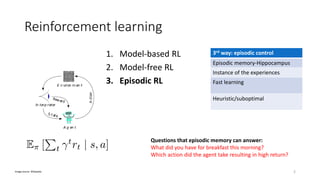
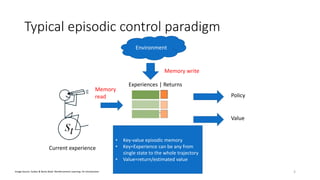
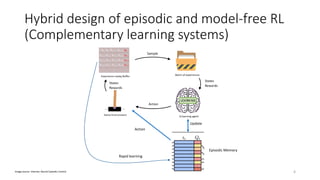
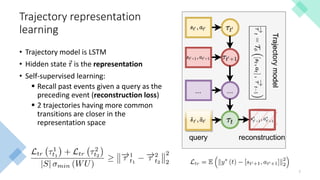
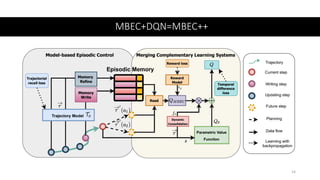
This document presents a new approach called Model-Based Episodic Control (MBEC) that combines model-free reinforcement learning with episodic memory. MBEC uses an episodic memory to store trajectory representations along with their estimated returns. It can estimate values for new trajectories by querying similar past trajectories in memory. The memory is updated to propagate returns across trajectories. A neural network then dynamically combines the episodic value with the model-free value. This hybrid approach allows for rapid learning from episodes while also generalizing through the model-free component. It performs well in noisy environments and challenging domains like Atari games and partially observable problems compared to model-free and episodic approaches alone.




















![[1808.00177] Learning Dexterous In-Hand Manipulation](https://cdn.slidesharecdn.com/ss_thumbnails/learningdextrousinhandmanipulation-180814000608-thumbnail.jpg?width=640&height=640&fit=bounds)



























































