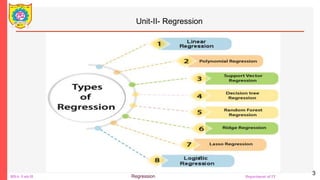
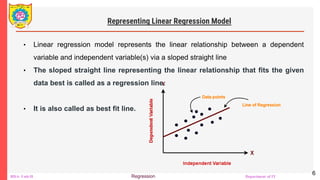
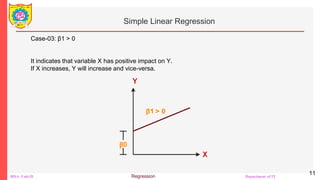
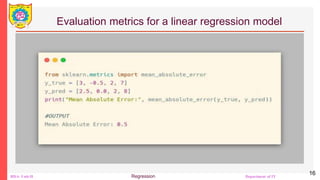
The document outlines a course on Big Data Analytics focusing on Advanced Analytical Theory and Methods using Python, specifically regression techniques. It covers concepts such as linear and multiple linear regression, evaluates models using metrics like mean squared error and R-squared, and details the implementation using libraries like scikit-learn. Additionally, it explains the significance of regression in data analysis for predicting continuous values based on independent variables.




















![BDA- Unit-II Regression Department of IT
Simple Linear Regression With scikit-learn
25
• Step 2: Provide data
• The second step is defining data to work with. The inputs (regressors, 𝑥)
and output (response, 𝑦) should be arrays or similar objects. This is the
simplest way of providing data for regression:
• >>> x = np.array([5, 15, 25, 35, 45, 55]).reshape((-1, 1))
• >>> y = np.array([5, 20, 14, 32, 22, 38])
• Now, you have two arrays: the input, x, and the output, y. You should call
.reshape() on x because this array must be two-dimensional, or more
precisely, it must have one column and as many rows as necessary. That’s
exactly what the argument (-1, 1) of .reshape() specifies.](https://image.slidesharecdn.com/unit2regression-240517095730-f75e77d2/85/Unit2_Regression-ADVANCED-ANALYTICAL-THEORY-AND-METHODS-USING-PYTHON-25-320.jpg)
![BDA- Unit-II Regression Department of IT
Simple Linear Regression With scikit-learn
26
• This is how x and y look now:
• >>> x
• array([[ 5],
• [15],
• [25],
• [35],
• [45],
• [55]])
• >>> y
• array([ 5, 20, 14, 32, 22, 38])
• As you can see, x has two dimensions, and x.shape is (6, 1), while y has a
single dimension, and y.shape is (6,).](https://image.slidesharecdn.com/unit2regression-240517095730-f75e77d2/85/Unit2_Regression-ADVANCED-ANALYTICAL-THEORY-AND-METHODS-USING-PYTHON-26-320.jpg)




![BDA- Unit-II Regression Department of IT
Simple Linear Regression With scikit-learn
31
• When you’re applying .score(), the arguments are also the predictor x and
response y, and the return value is 𝑅².
• The attributes of model are .intercept_, which represents the coefficient 𝑏₀,
and .coef_, which represents 𝑏₁:
• >>> print(f"intercept: {model.intercept_}")
• intercept: 5.633333333333329
• >>> print(f"slope: {model.coef_}")
• slope: [0.54]
• The code above illustrates how to get 𝑏₀ and 𝑏₁. You can notice that
.intercept_ is a scalar, while .coef_ is an array.](https://image.slidesharecdn.com/unit2regression-240517095730-f75e77d2/85/Unit2_Regression-ADVANCED-ANALYTICAL-THEORY-AND-METHODS-USING-PYTHON-31-320.jpg)












































































