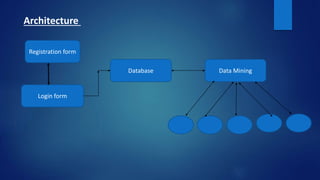
This document discusses a proposed system for segmenting tweets and applying that segmentation to name entity recognition. The proposed system uses k-means clustering to segment tweets into categories like Bollywood, business, education, politics, and sports. This segmentation aims to preserve the semantic meaning of tweets and improve downstream applications like named entity recognition, achieving better accuracy than word-based approaches. The proposed system also adds security features like blocking users and is intended to be more efficient and flexible than prior algorithms.
































![[IJET-V2I2P3] Authors:Vijay Choure, Kavita Mahajan ,Nikhil Patil, Aishwarya N...](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v2i2p3-160427183859-thumbnail.jpg?width=640&height=640&fit=bounds)












![[System design] Design a tweeter-like system](https://cdn.slidesharecdn.com/ss_thumbnails/sys-design-design-twitter-220208072933-thumbnail.jpg?width=640&height=640&fit=bounds)























