Downloaded 11 times


































![Questions [email_address] Or @stephendann www.digiworldhanoi.vn](https://image.slidesharecdn.com/twitteranalytics-111116045037-phpapp02/85/Twitter-analytics-52-320.jpg)




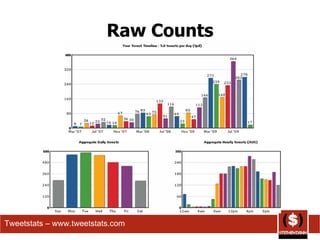
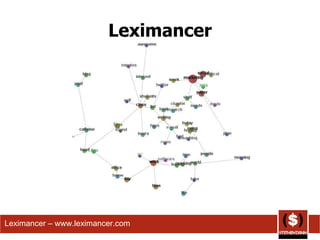
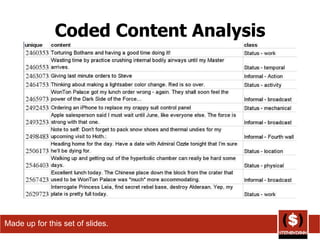
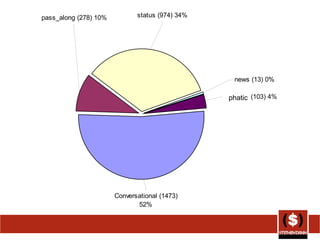
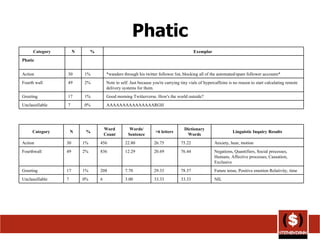
The document summarizes different ways that Twitter data and usage has been analyzed in prior studies. It discusses 6 prior analyses that took different approaches such as removing user information, categorizing tweet content, analyzing brand sentiment, and classifying messages. The document then describes its own coding approach to analyze a sample of the author's Twitter history based on major categories of conversational, status, pass along, news, and spam messages. Results of this analysis on percentages of tweets in each category and subcategory are also presented.





















































































