Download as PDF, PPTX















![Basics of ETL Job Programming
1. Initialize
2. Read
3. Transform data
4. Write
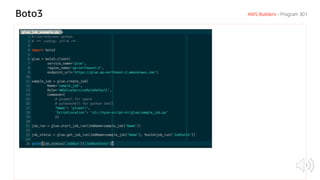
## Initialize
glueContext = GlueContext(SparkContext.getOrCreate())
## Create DynamicFrame and retrieve data from source
ds0 = glueContext.create_dynamic_frame.from_catalog (
database = "mysql", table_name = "customer",
transformation_ctx = "ds0")
## Implement data transformation here
ds1 = ds0 ...
## Write DynamicFrame from Catalog
ds2 = glueContext.write_dynamic_frame.from_catalog (
frame = ds1, database = "redshift",
table_name = "customer_dim",
redshift_tmp_dir = args["TempDir"],
transformation_ctx = "ds2")](https://image.slidesharecdn.com/awsbuildersaws301effectiveawsgluetaehyunkim-190306061037/85/AWS-Builders-Effective-AWS-Glue-20-320.jpg)

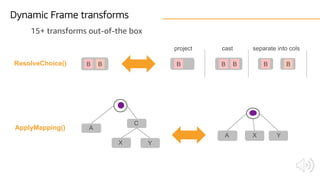
![Semi-structured schema Relational schema
FKA B B C.X C.Y
PK ValueOffset
A C D [ ]
X Y
B B
Transforms and adds new columns, types, and tables on-the-fly
Tracks keys and foreign keys across runs
SQL on the relational schema is orders of magnitude faster than JSON processing
Relationalize() transform](https://image.slidesharecdn.com/awsbuildersaws301effectiveawsgluetaehyunkim-190306061037/85/AWS-Builders-Effective-AWS-Glue-26-320.jpg)


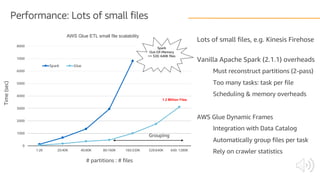
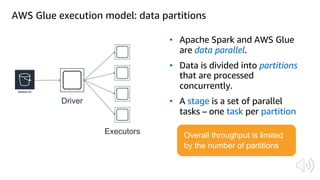



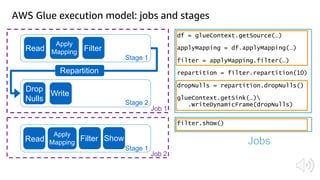



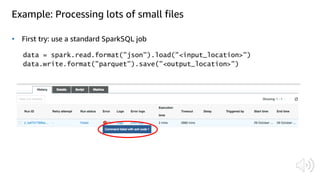
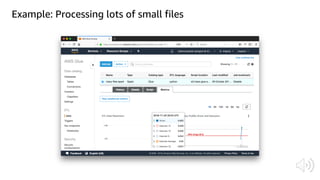
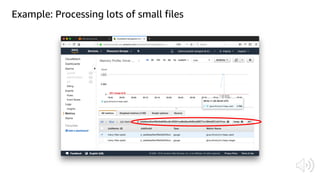


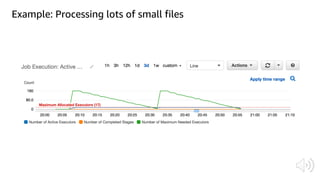




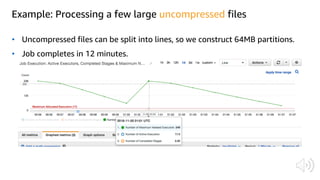


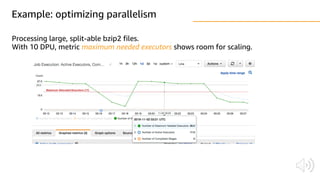

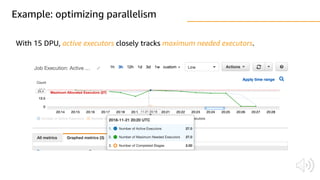


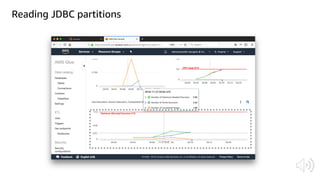
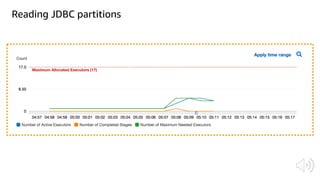
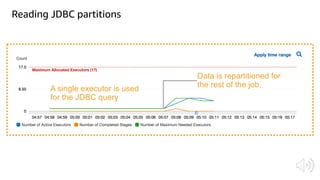


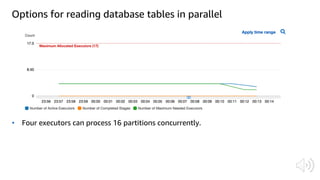
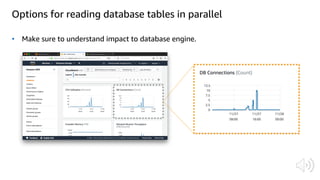


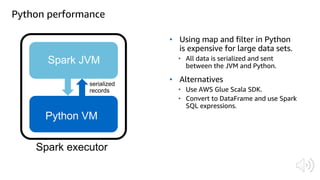

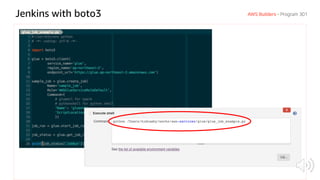
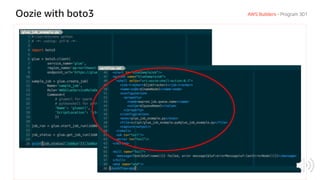
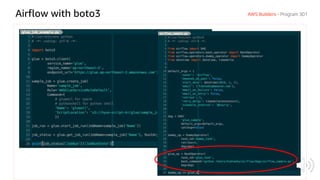

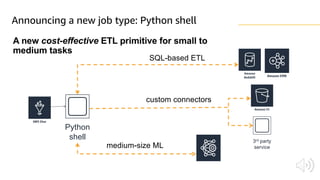




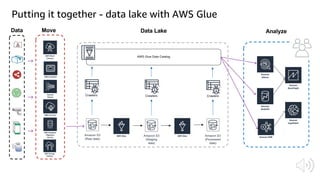
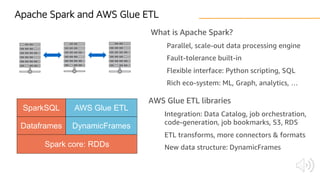
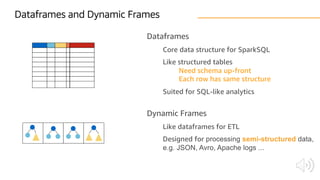
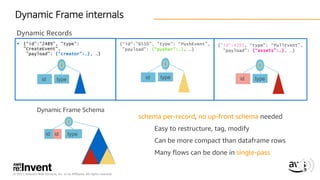
The document discusses AWS Glue, a fully managed ETL service. It provides an overview of Glue's programming environment and data processing model. It then gives several examples of optimizing Glue job performance, including processing many small files, a few large files, optimizing parallelism with JDBC partitions, Python performance, and using the new Python shell job type.












![대용량 데이터레이크 마이그레이션 사례 공유 [카카오게임즈 - 레벨 200] - 조은희, 팀장, 카카오게임즈 ::: Games on AWS ...](https://cdn.slidesharecdn.com/ss_thumbnails/t4s2-221108115925-5b63bf11-thumbnail.jpg?width=640&height=640&fit=bounds)





![[AWS EXpert Online for JAWS-UG 18] 見せてやるよ、Step Functions の本気ってやつをな](https://cdn.slidesharecdn.com/ss_thumbnails/awsxon18howfarstepfunctionsgo-211124111849-thumbnail.jpg?width=640&height=640&fit=bounds)




























![[D3T1S01] Gen AI를 위한 Amazon Aurora 활용 사례 방법](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s01genaiamazonaurora-240702042912-516e67f4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S06] Neptune Analytics with Vector Similarity Search](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s06neptuneanalyticsvectorsilimliaritysearch-240702042912-94c41309-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S03] Amazon DynamoDB design puzzlers](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s03amazondynamodbdesignpuzzlers-240702042912-ad6df881-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S04] Aurora PostgreSQL performance monitoring and troubleshooting by use...](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s04aurorapostgresqlperformancemonitoringandtroubleshooting-240702042912-5df626e3-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S07] AWS S3 - 클라우드 환경에서 데이터베이스 보호하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s07-240702042911-cb134cd6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S05] Aurora 혼합 구성 아키텍처를 사용하여 예상치 못한 트래픽 급증 대응하기](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s05aurora-240702042911-c7f3f22d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T1S02] Aurora Limitless Database Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/d3t1s02auroralimitlessdatabaseintroduction-240702042911-cb5552b7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S01] Amazon Aurora MySQL 메이저 버전 업그레이드 및 Amazon B/G Deployments 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s01amazonaurorabluegreendeployment-240702042226-3ae36566-thumbnail.jpg?width=640&height=640&fit=bounds)
![[D3T2S03] Data&AI Roadshow 2024 - Amazon DocumentDB 실습](https://cdn.slidesharecdn.com/ss_thumbnails/d3t2s03documentdbhandson-240702042224-047bbc2c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[Keynote] 슬기로운 AWS 데이터베이스 선택하기 - 발표자: 강민석, Korea Database SA Manager, WWSO, A...](https://cdn.slidesharecdn.com/ss_thumbnails/d3s01aws-230704014400-3eeae447-thumbnail.jpg?width=640&height=640&fit=bounds)















![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







