Download as PDF, PPTX


![2nd JTC 1 SGBD Meeting - Workshop
BIG
Big Data Public Private Forum
4
BIG DATA PRIVATE PUBLIC PARTNERSHIP
• Objectives: „The goal […] is to increase the amount
of productive European economic activities and the
number of European jobs that depend on the
availability of high quality data assets and the
technologies needed to derive value from them.”
(Source. Strategic Research and Innovation Agenda, SRIA)
• Neelie Kroes, EU Commissioner for the Digital
Agenda: „This is a revolution and I want the EU
to be right at the front of it“
• 29 European organisations from
industry and research
• Results of public consultattion to
be presented at NESSI Summit
Brussels, 27th May](https://image.slidesharecdn.com/n0047towardsabigdataroadmapforeurope-140626050008-phpapp01/85/Towards-a-big-data-roadmap-for-europe-4-320.jpg)

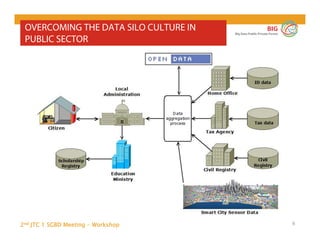


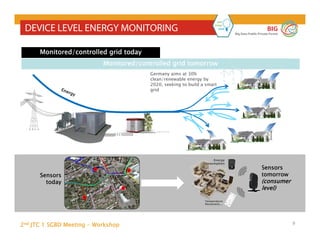
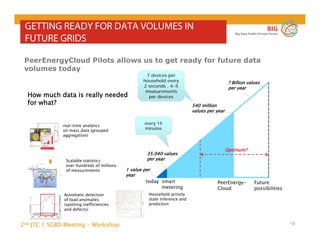

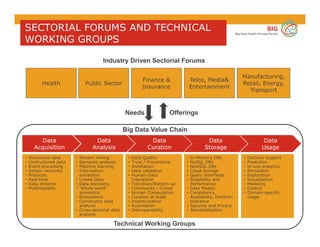
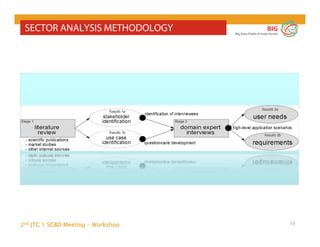
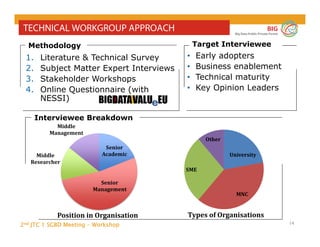


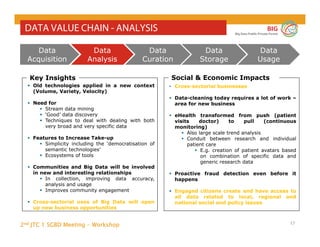


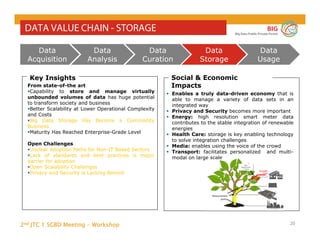
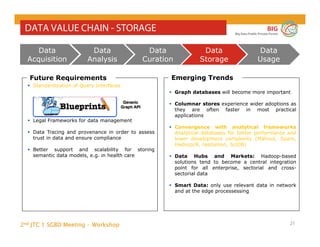
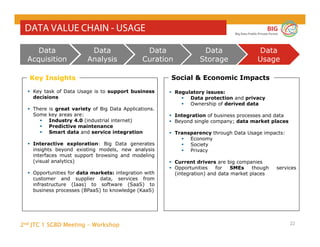





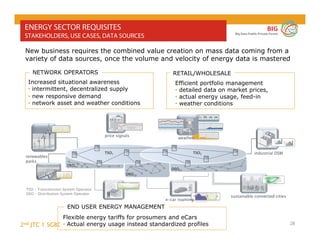




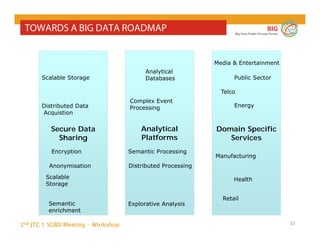



The document outlines the objectives and findings from the 2nd JTC 1 SGBD meeting focused on creating a big data roadmap for Europe through public-private partnerships and stakeholder collaboration. Key insights emphasize the need for strategies to leverage high-quality data assets and technologies to enhance European economic activities and job creation. The document highlights various use cases across sectors, including healthcare and energy, and discusses challenges related to data silos, privacy, and the standardization of data practices.




















































































