Download as PDF, PPTX











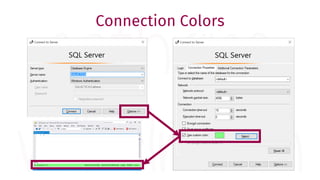
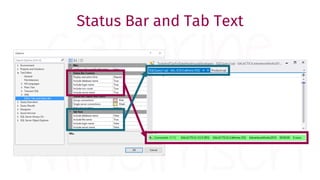
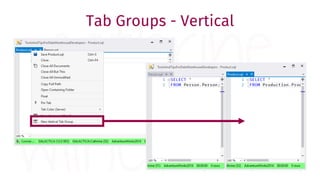
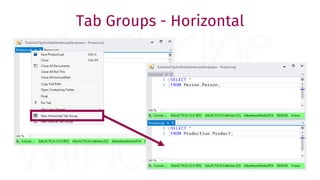
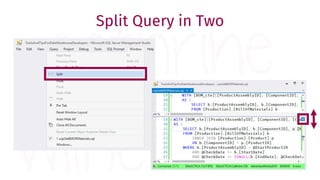
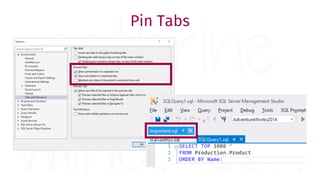

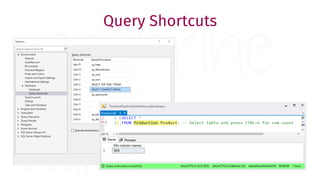

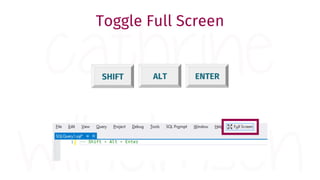
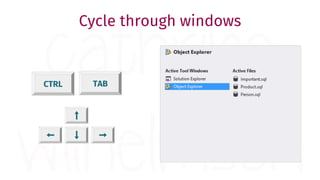

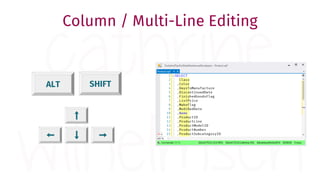
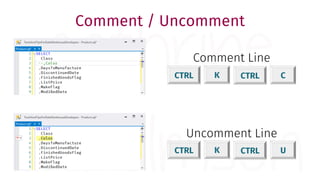
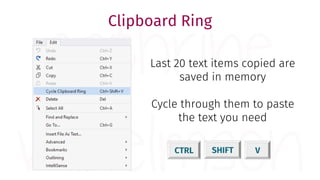
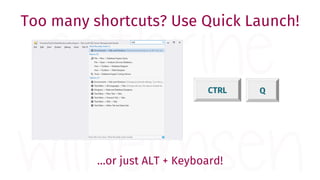



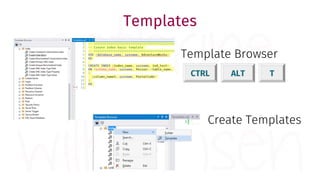
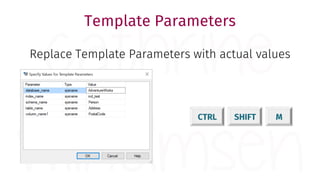
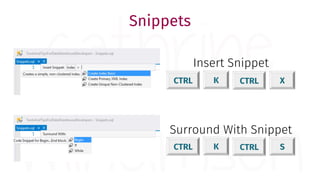



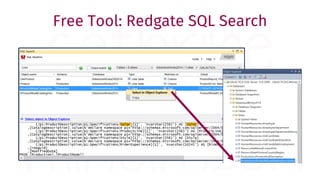


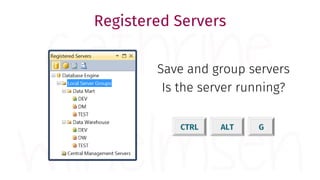


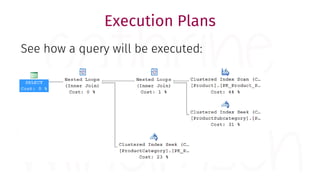
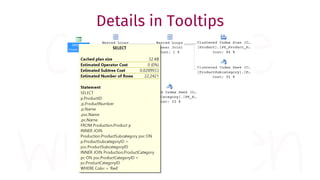
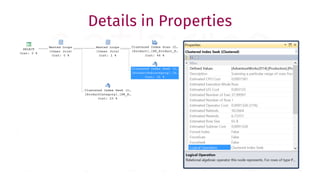
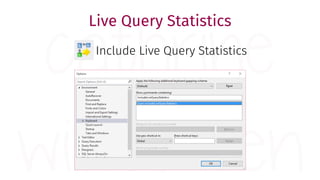
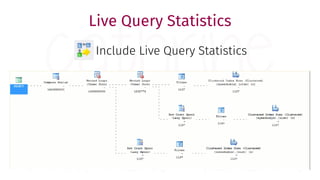
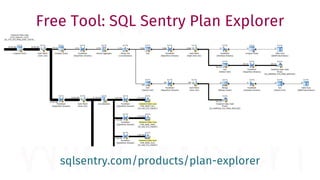
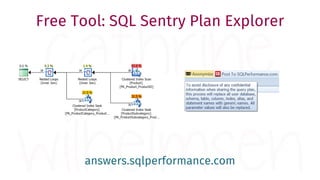





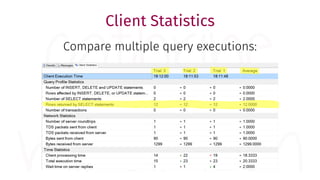

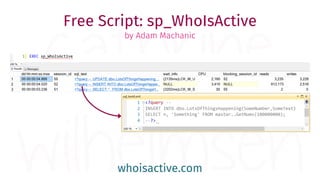
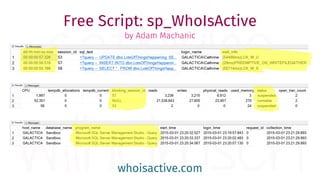

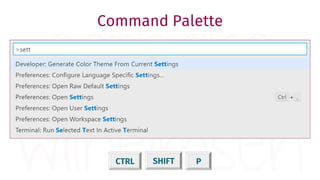


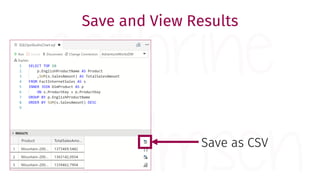
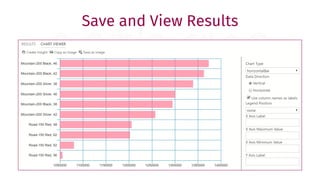
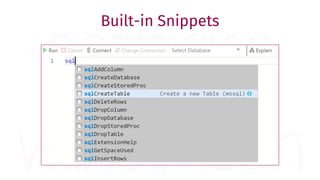




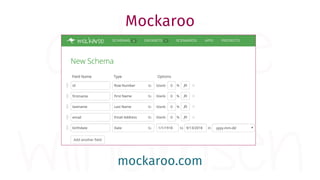











The document provides a comprehensive guide for data warehouse developers, focusing on tools, tips, and shortcuts for SQL Server Management Studio (SSMS) and Business Intelligence Markup Language (BIML) for SSIS development. It includes information on useful features, keyboard shortcuts, templates, snippets, and external tools for query analysis and execution plans. Additionally, it offers links to resources for further learning and development in data warehousing.























































































