Download as PDF, PPTX





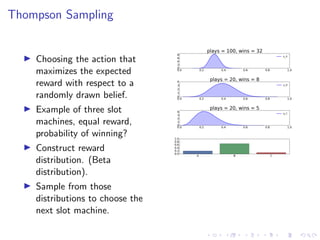
![Thompson sampling using numpy
1 import numpy as np
2
3 plays = np.array([100, 20, 20])
4 wins = np.array([32, 8, 5])
5 num_samples = 1000000
6
7 p_A_sample = np.random.beta(wins[0], plays[0] - wins[0], num_samples)
8 p_B_sample = np.random.beta(wins[1], plays[1] - wins[1], num_samples)
9 p_C_sample = np.random.beta(wins[2], plays[2] - wins[2], num_samples)
10
11 mab_wins = np.array([0.0, 0.0, 0.0])
12
13 for i in range(num_samples):
14 winner = np.argmax([p_A_sample[i], p_B_sample[i], p_C_sample[i]])
15 mab_wins[winner] += 1
16
17 mab_wins = mab_wins / num_samples
18
19 print(mab_wins)](https://image.slidesharecdn.com/thompsonsamplingformachinelearning-180625213048/85/Thompson-Sampling-for-Machine-Learning-Ruben-Mak-8-320.jpg)




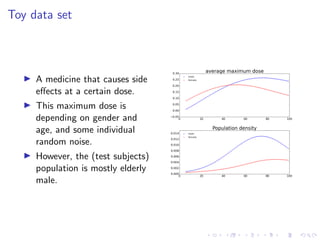
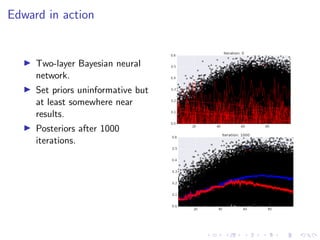
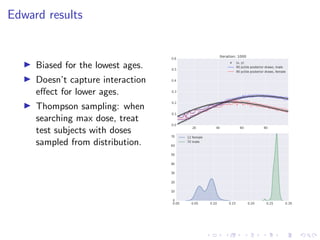
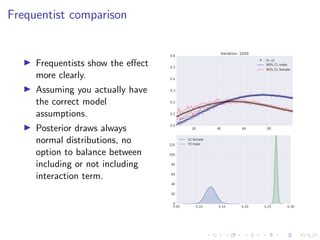
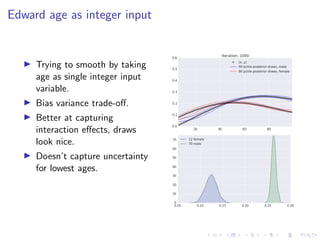





The document discusses Thompson Sampling, a strategy for addressing the multi-armed bandit problem, particularly in data science and marketing contexts. It highlights the historical development and applications of Thompson Sampling, including its use in clinical trials and Bayesian modeling. The conclusion emphasizes the importance of data acquisition costs and advocates for the integration of Thompson Sampling in strategic data collection and modeling efforts.























































































