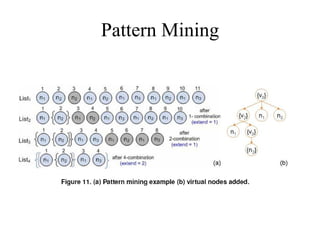
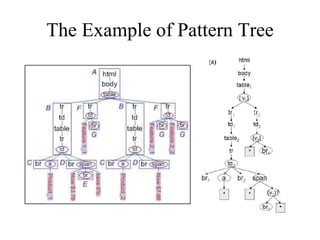
FivaTech is a system that deduces data schemas and templates from input pages generated by a CGI program. It contains two modules: tree merging and schema detection. The tree merging module recognizes similar nodes using a 2-tree matching algorithm and computes a normalized score to merge trees. The schema detection module mines patterns from the merged trees to identify tuple types, element orders, and optional data. It then defines templates by segmenting the pattern tree at reference nodes.

















![[Queue , linked list , tree]](https://cdn.slidesharecdn.com/ss_thumbnails/queuelinkedlisttree-200819083233-thumbnail.jpg?width=640&height=640&fit=bounds)




































































