Downloaded 19 times

















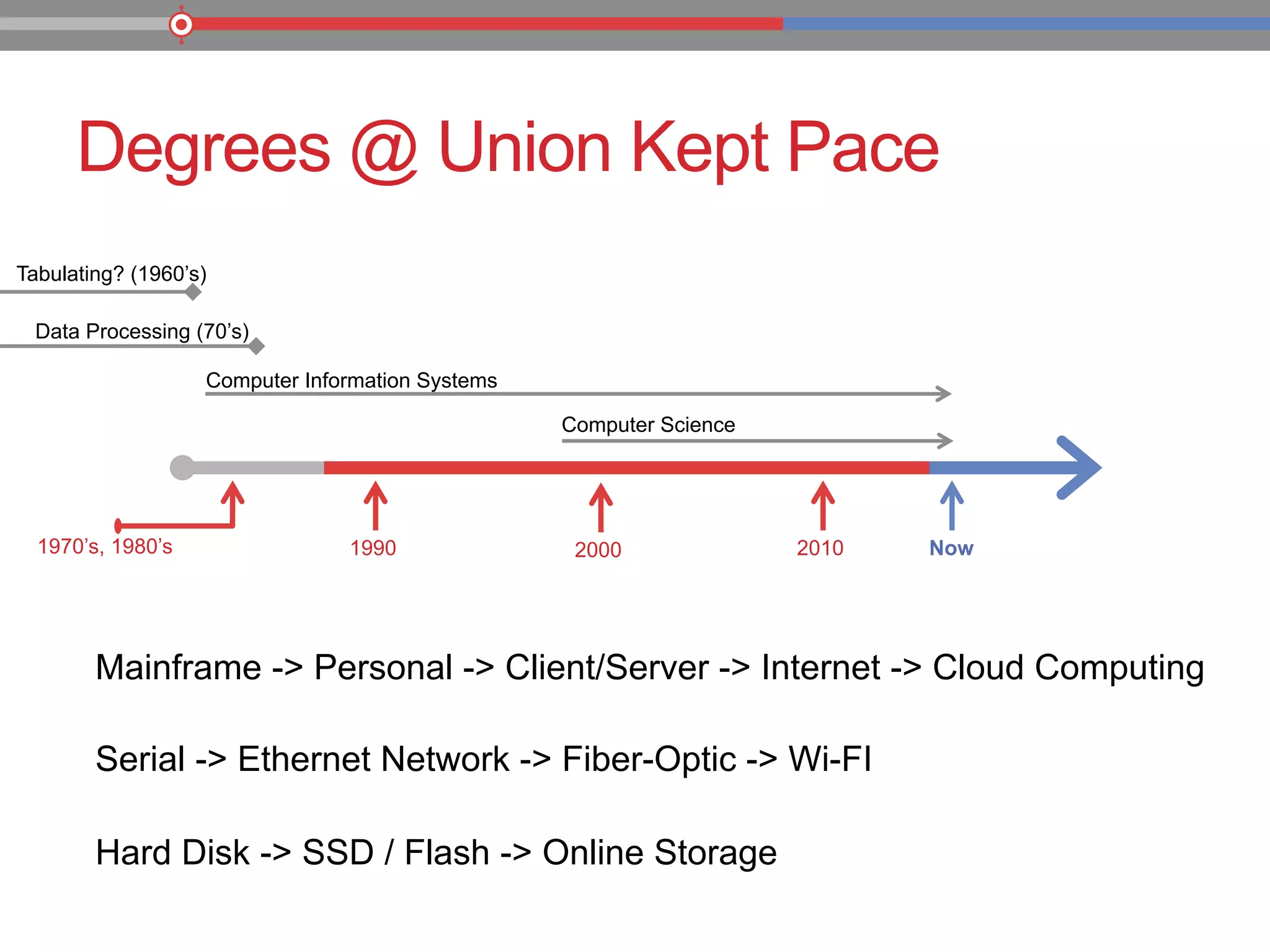
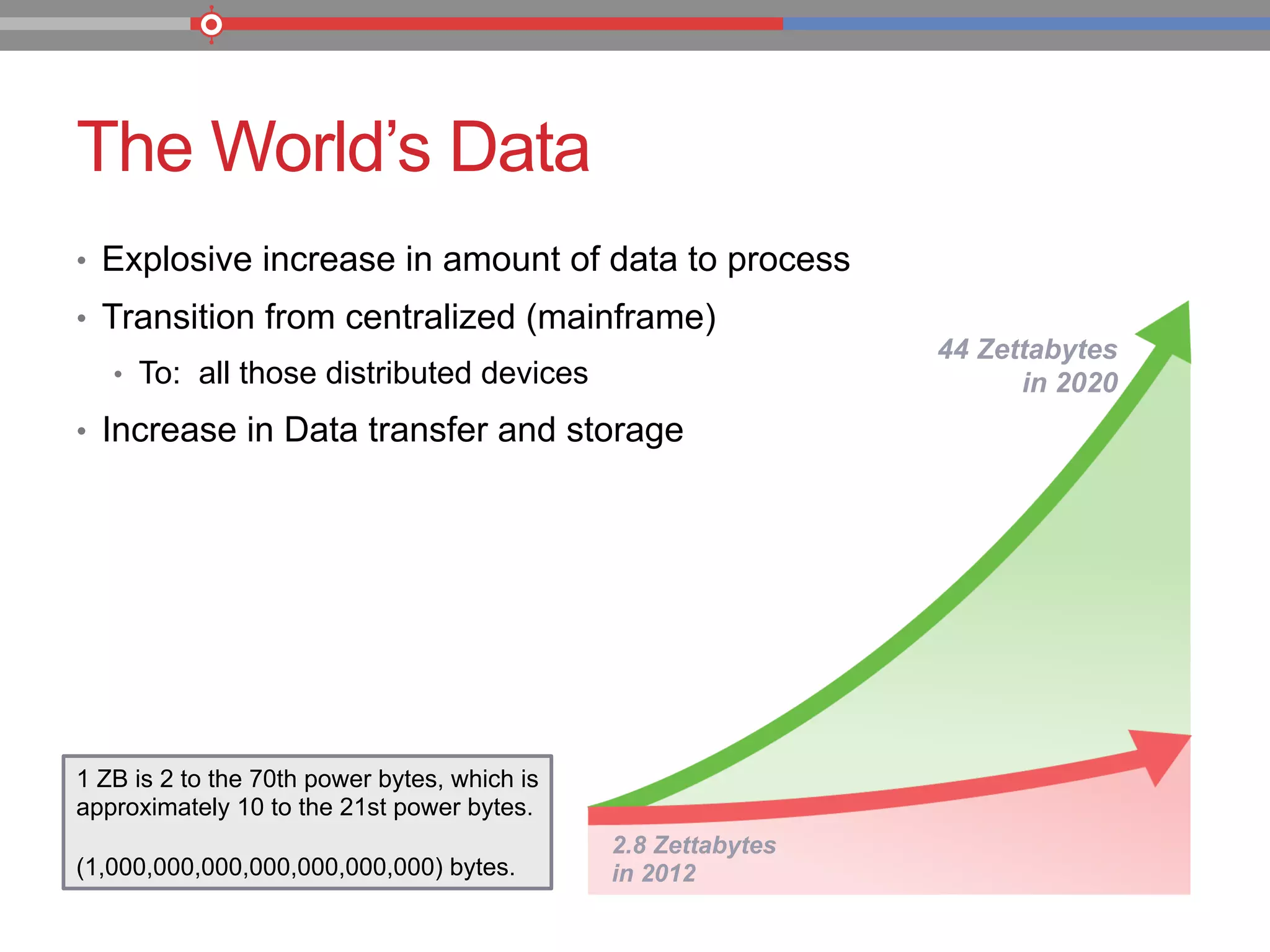




















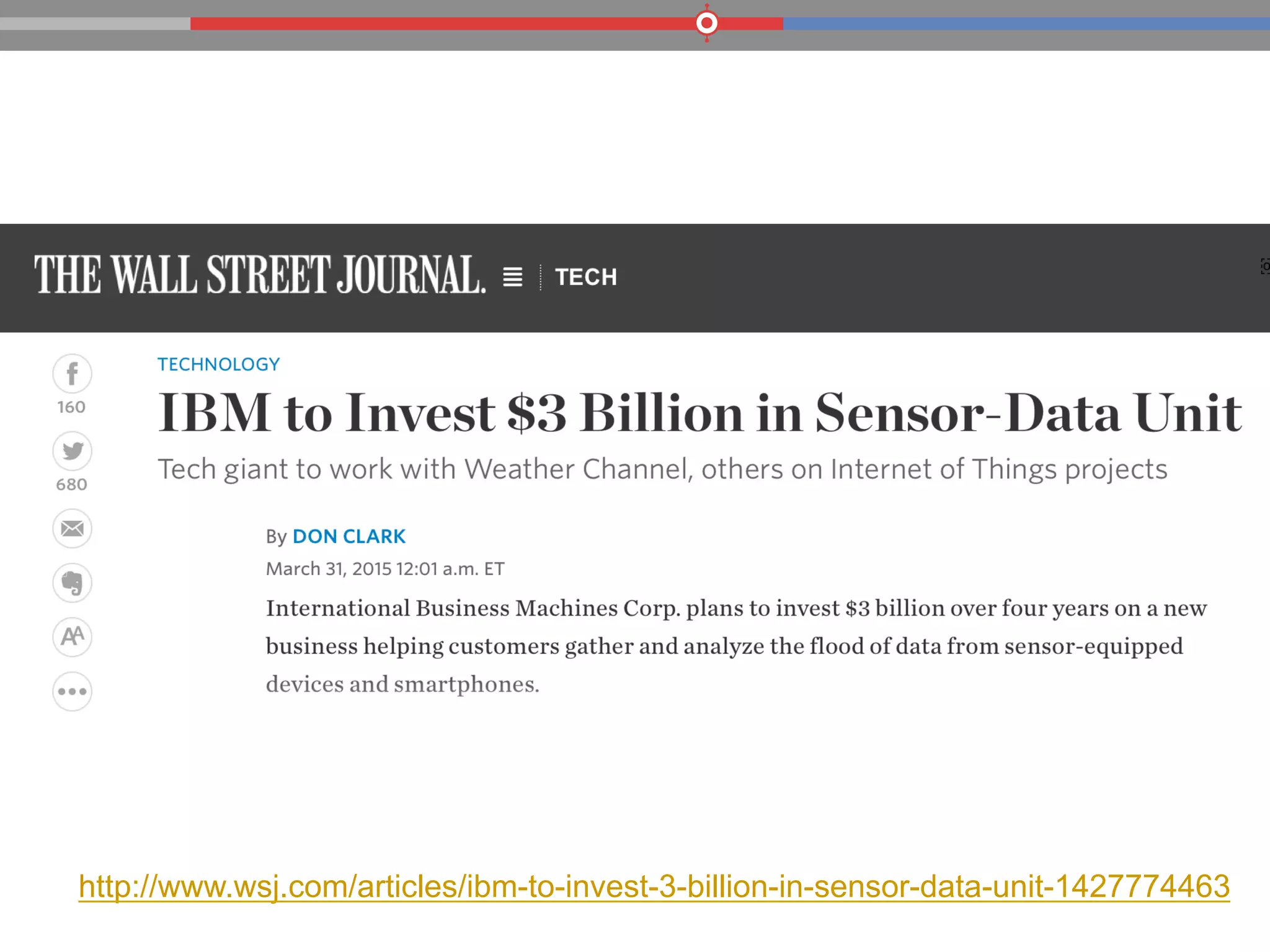
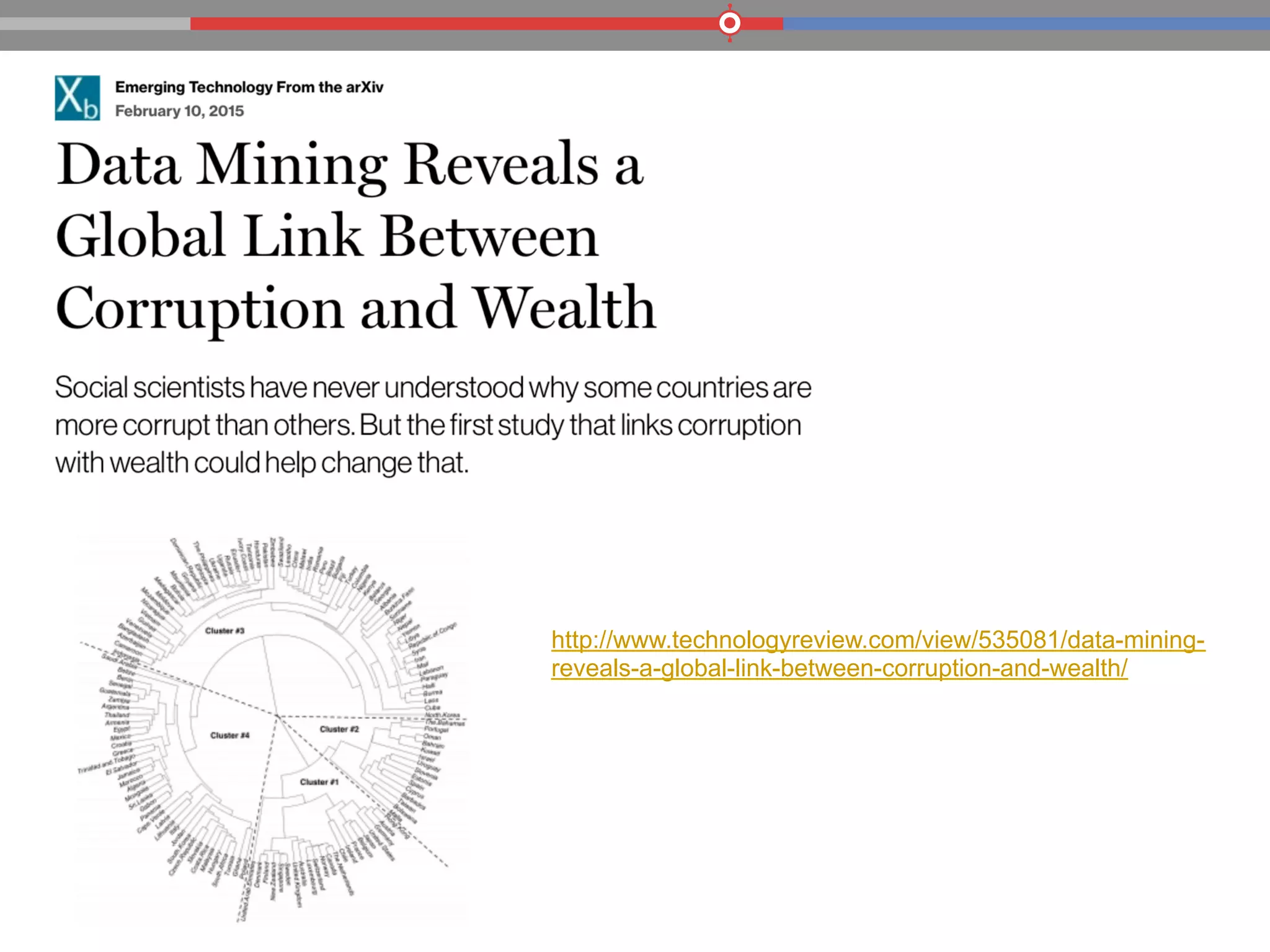


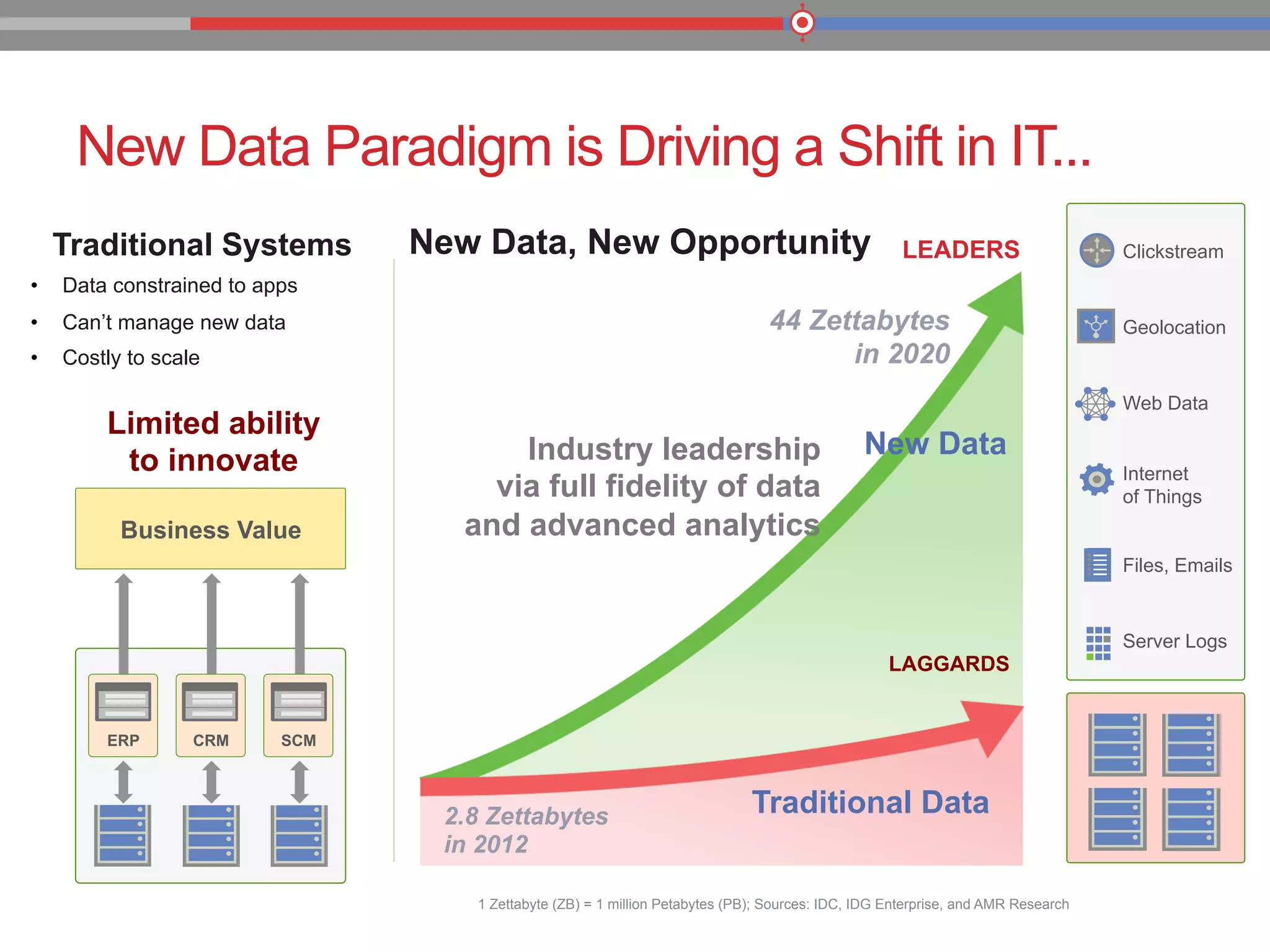


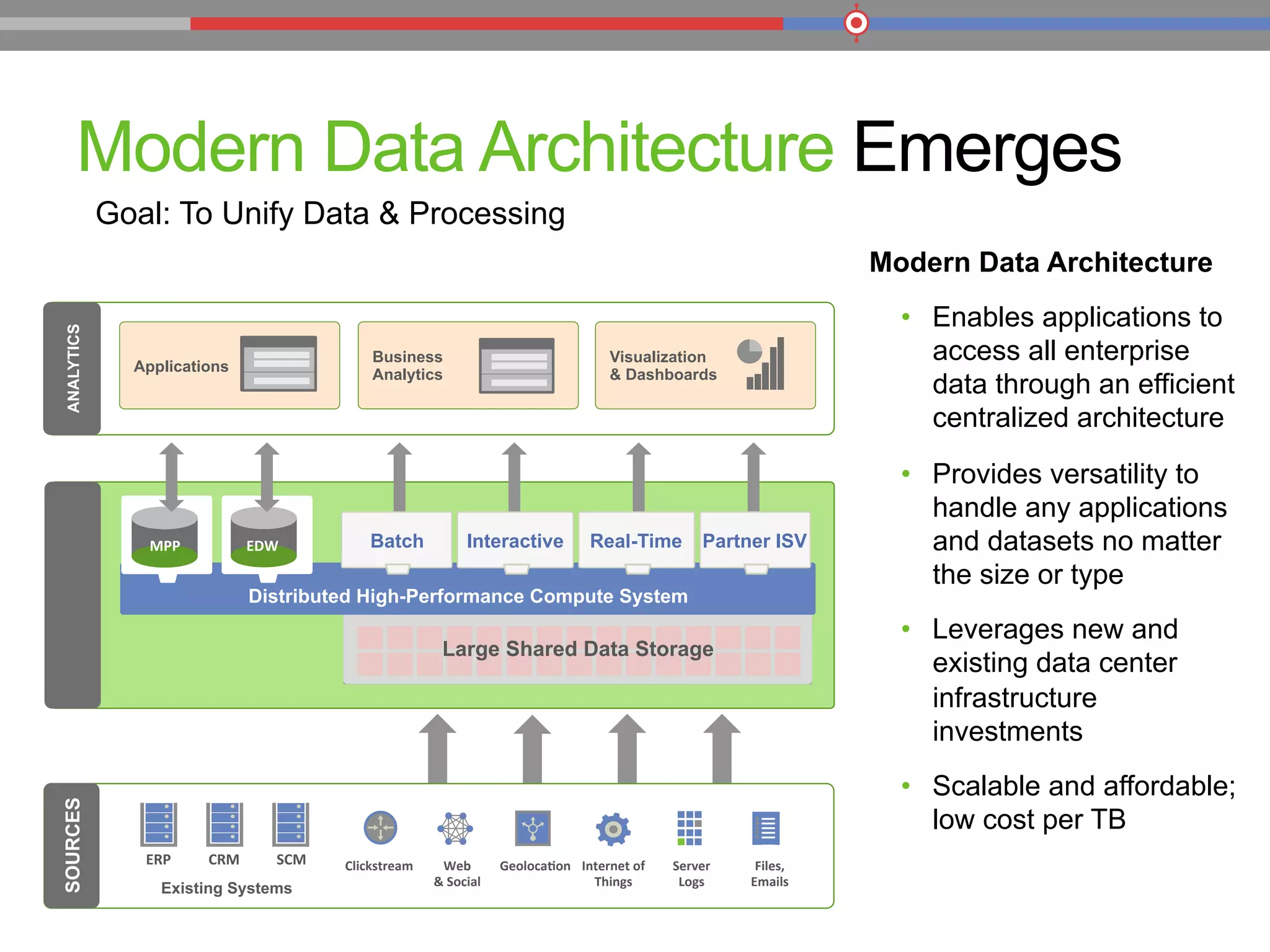





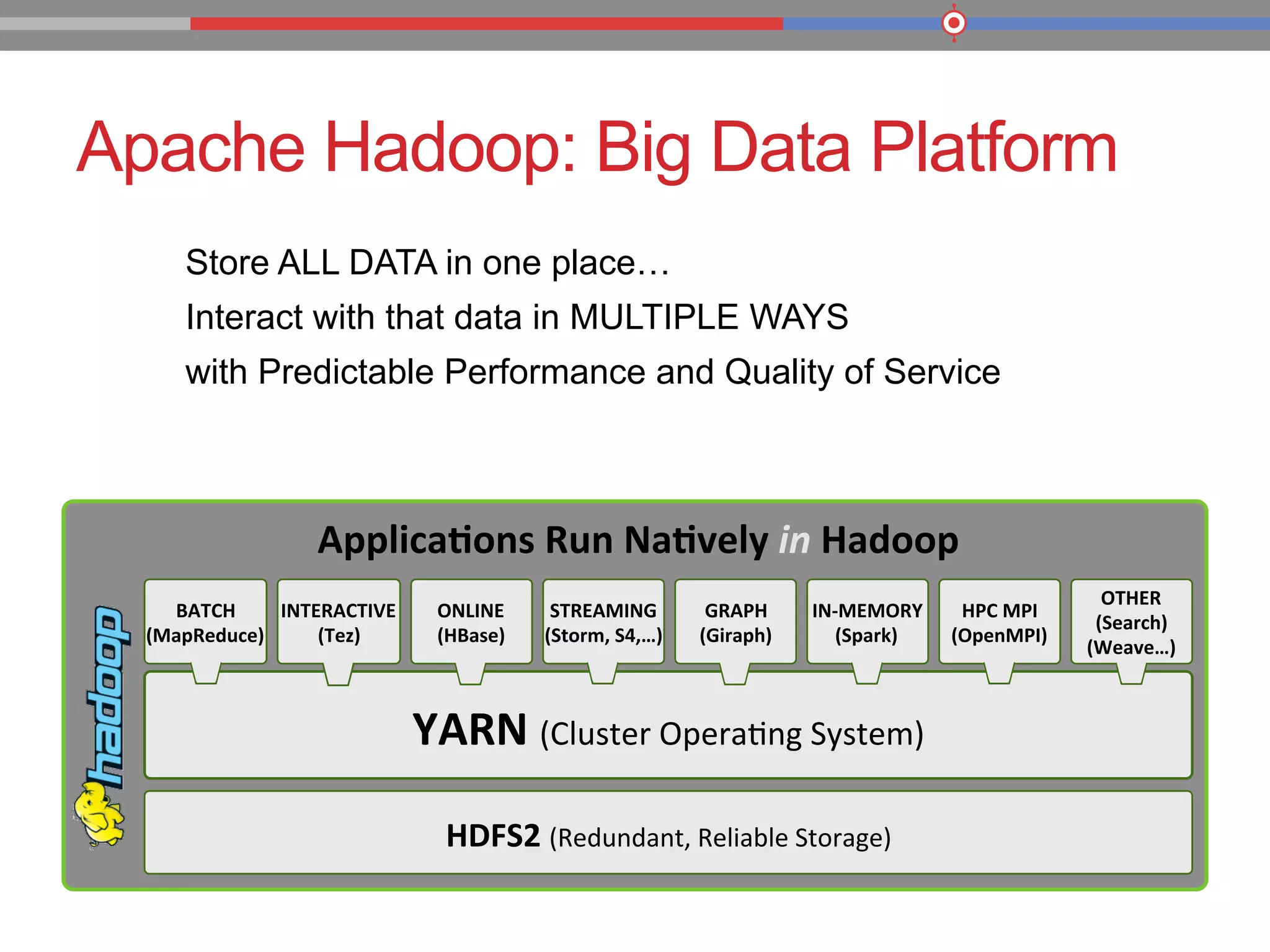

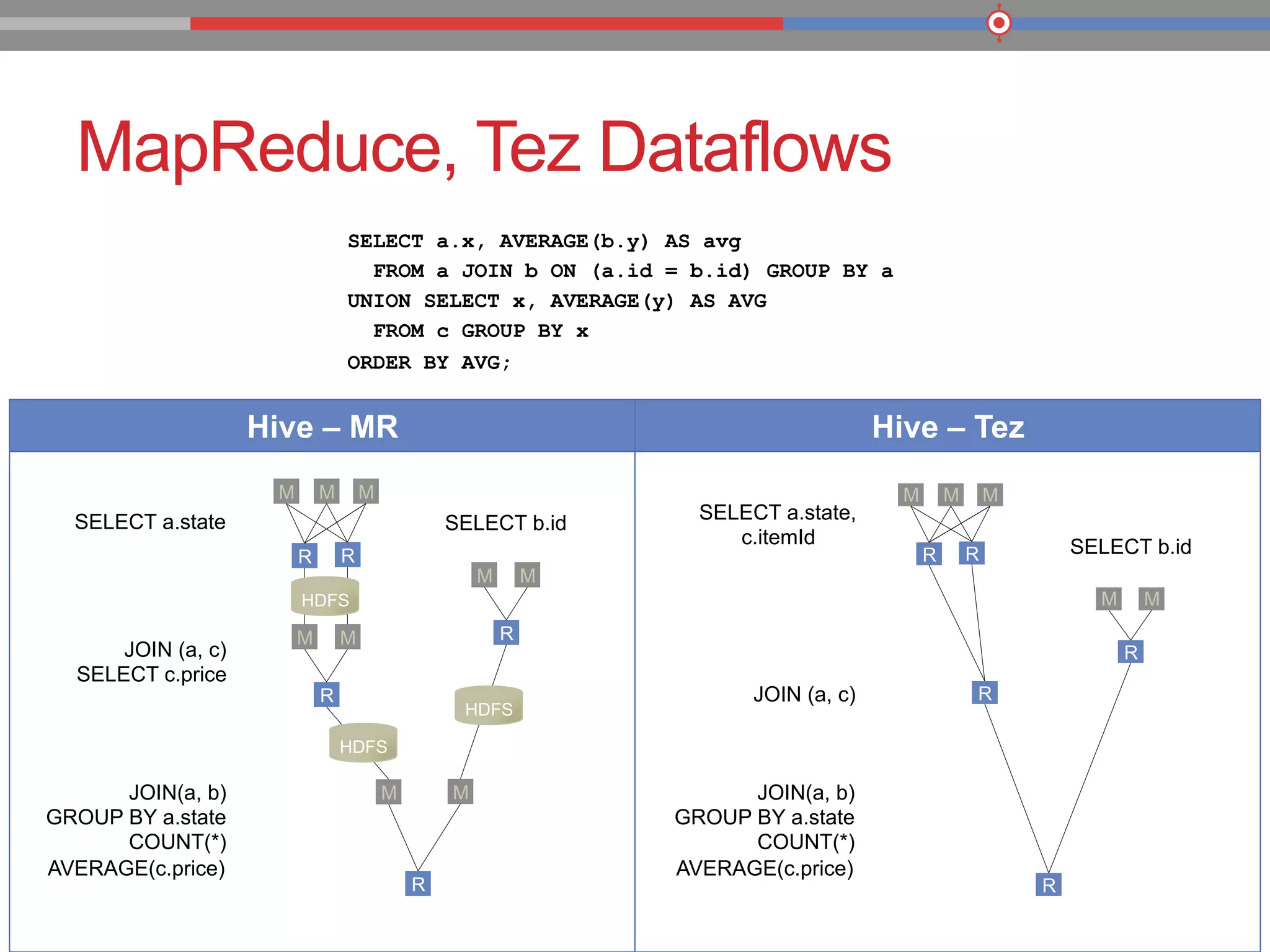








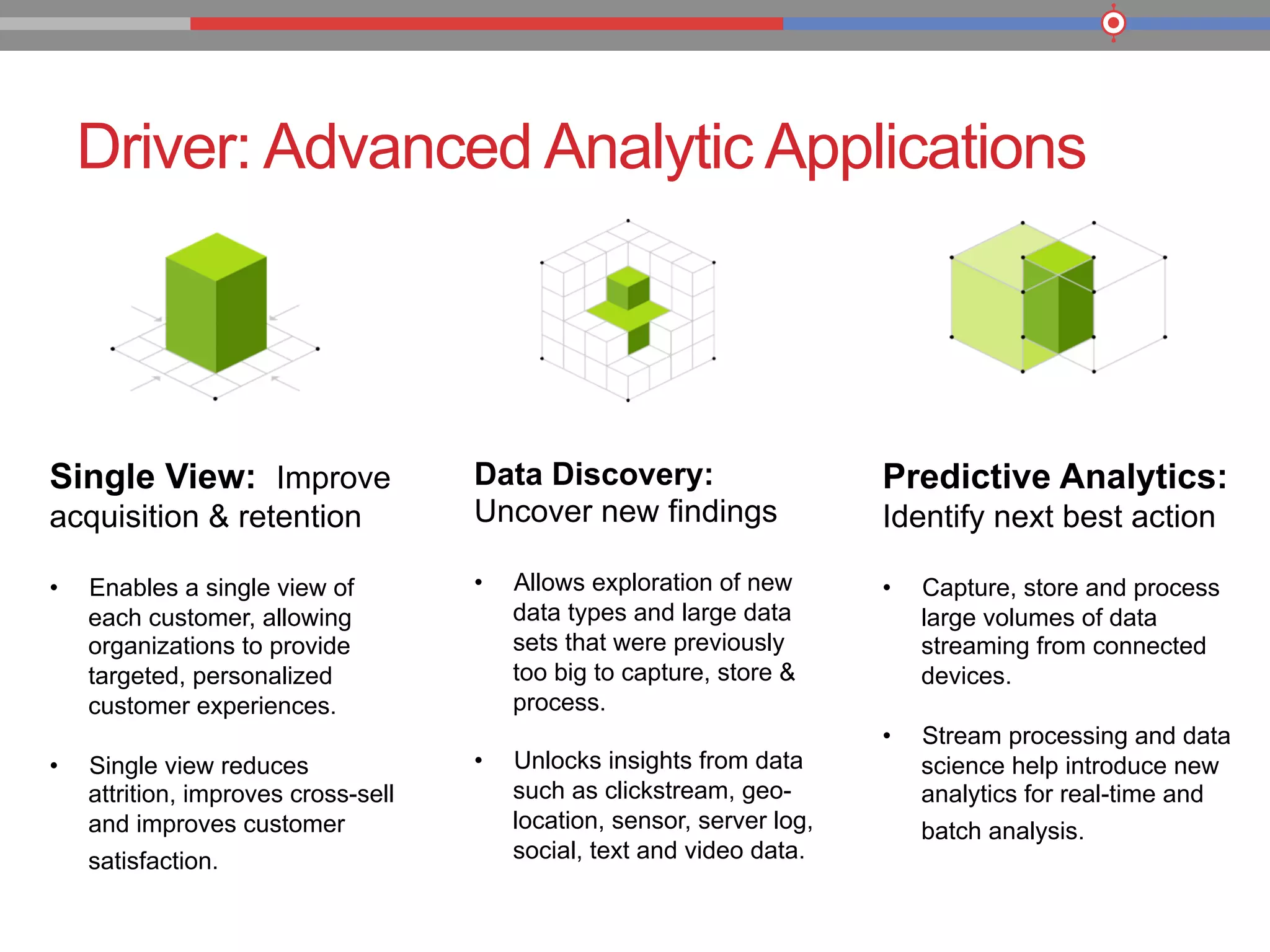



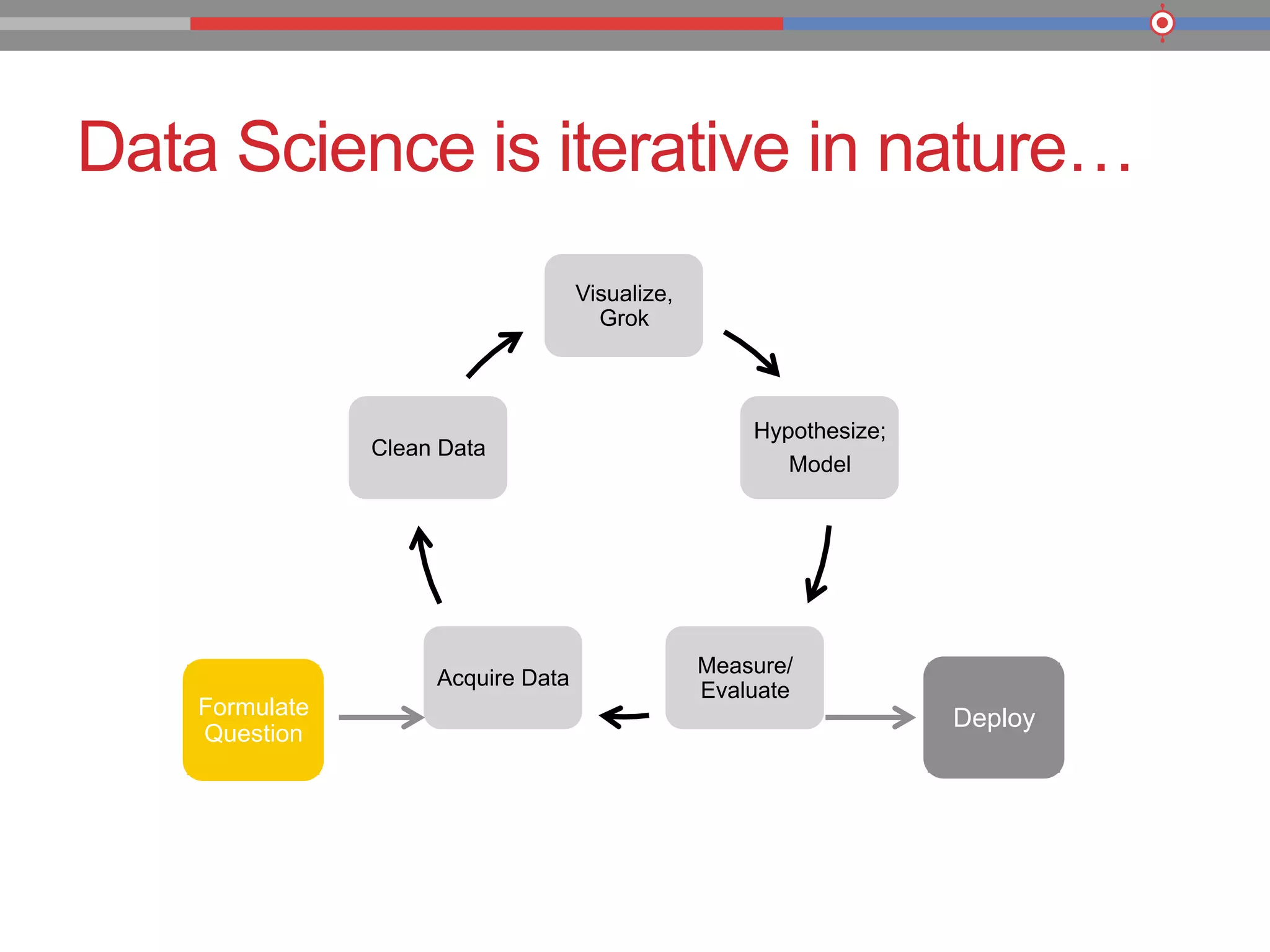


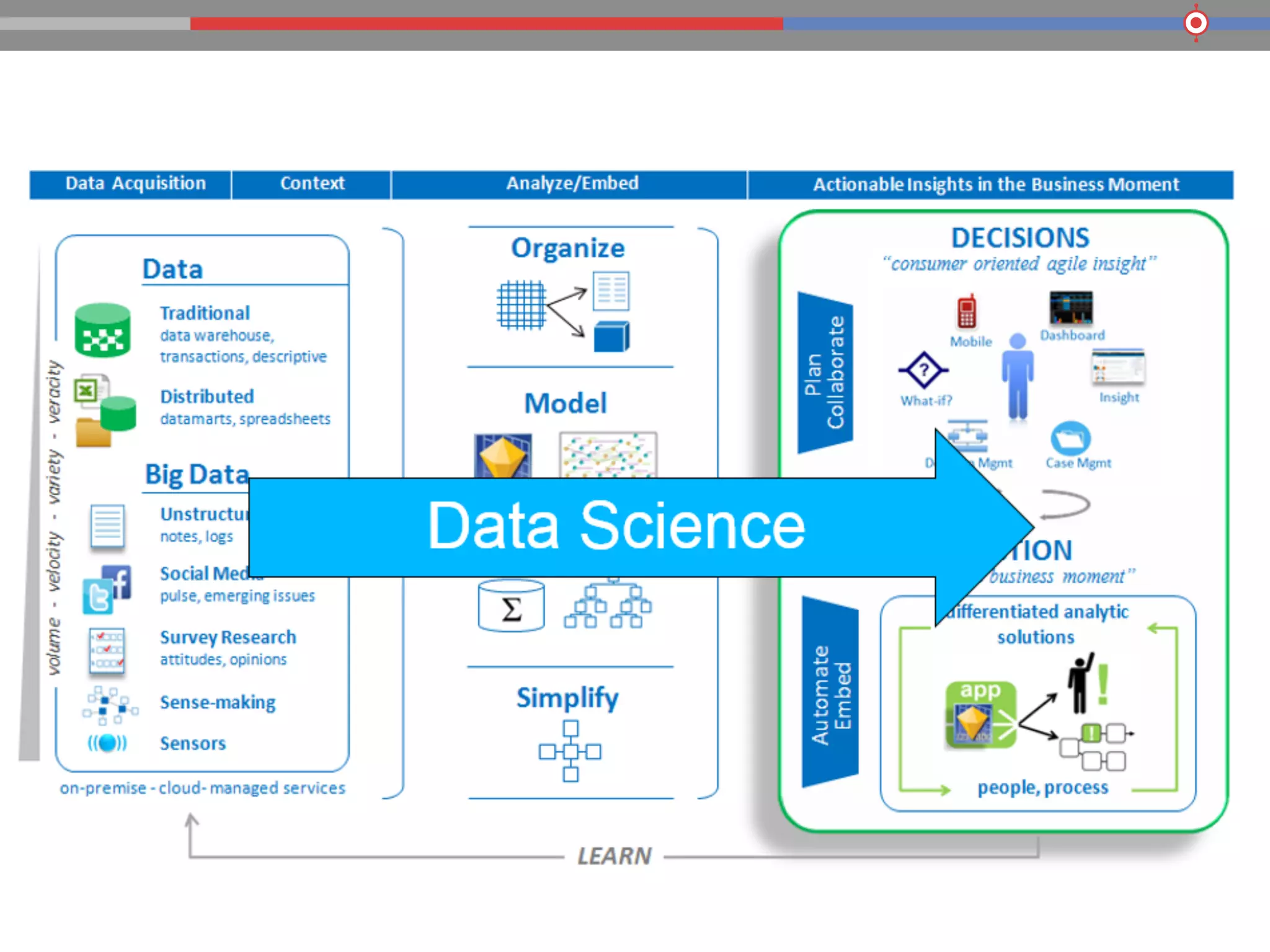



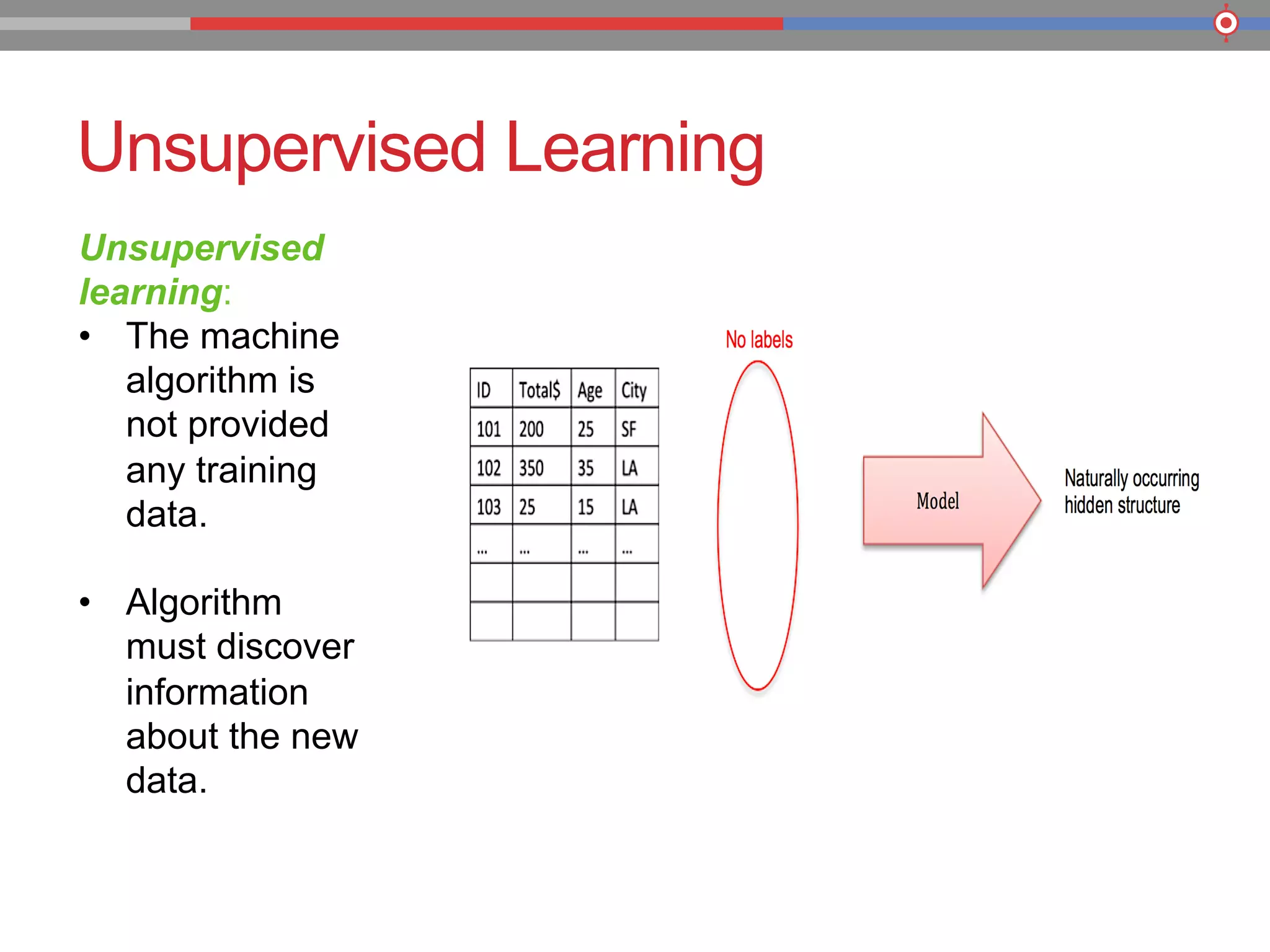

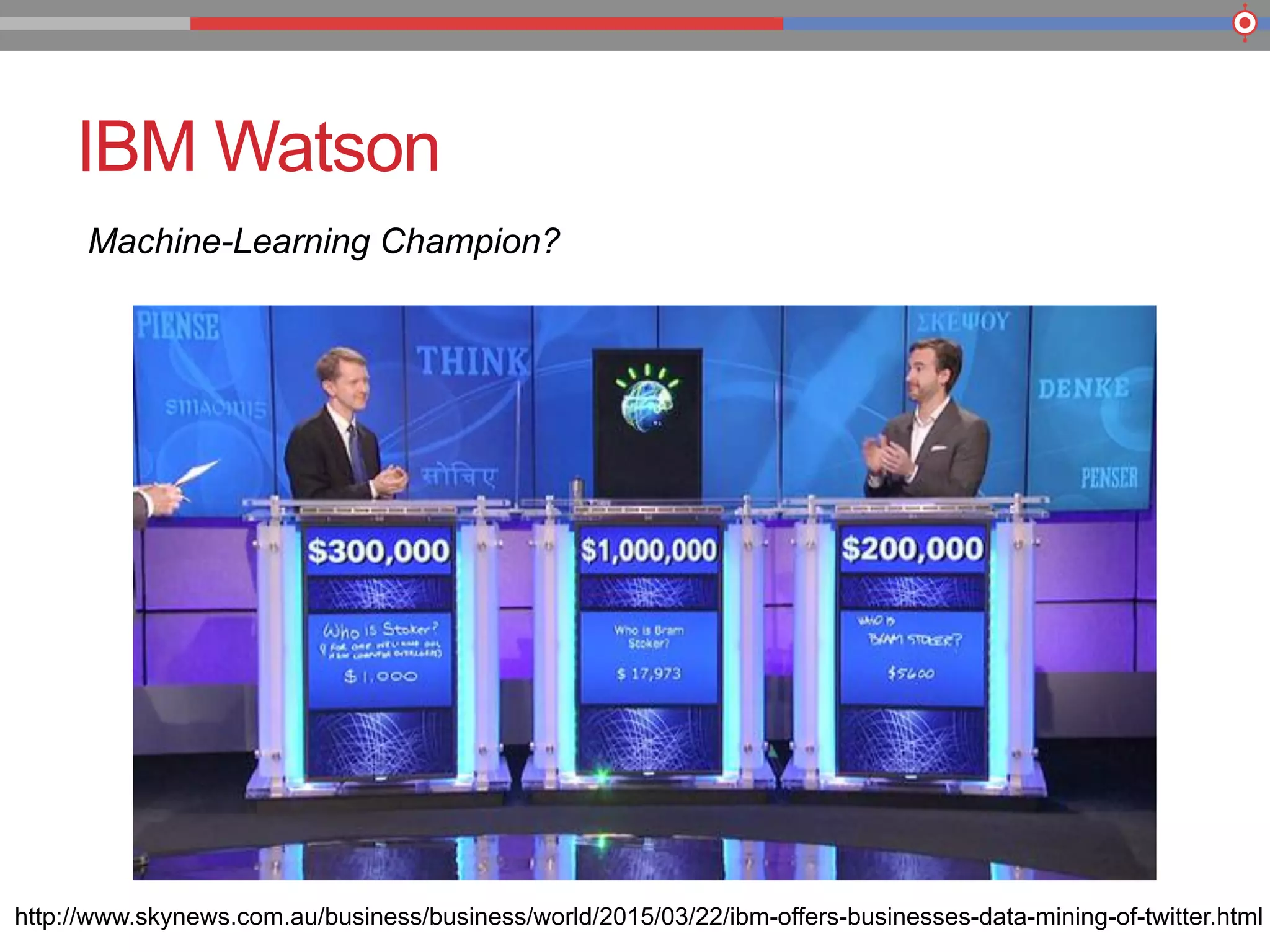




The document discusses the evolution of data processing technologies, emphasizing the capabilities of Apache Hadoop and modern data architecture for enterprises. It outlines the transformative power of big data, highlighting its impact on various industries and the need for scalable, cost-effective solutions. Various use cases demonstrate how data science can enhance decision-making, customer insights, and operational efficiency across sectors such as utilities, insurance, and retail.























































![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Francisco Prado Moreno - Model Validation in the Age of AI: T...](https://cdn.slidesharecdn.com/ss_thumbnails/2igqvkir1yd2yzlhoylg-3-251215095918-6676c4e6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Behzad Hosseini - AI Agents in the Wild: Deploying Models tha...](https://cdn.slidesharecdn.com/ss_thumbnails/3qtejajvsjqrzwfept2c-10-251212103250-7f2b1068-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Djordje Hirs - Revolutionizing Telco Customer Experience with...](https://cdn.slidesharecdn.com/ss_thumbnails/zif75aur3qscnckv6tnc-djordje-hirs-cc-dsc2025-1-251219145617-679178aa-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Maria Kokiasmenos - AI Governance US Perspective.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/eszqnbzlsqa2vch6dmci-6-251215095918-6fcdf45f-thumbnail.jpg?width=640&height=640&fit=bounds)
