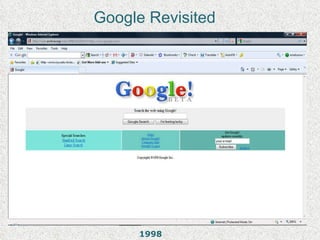
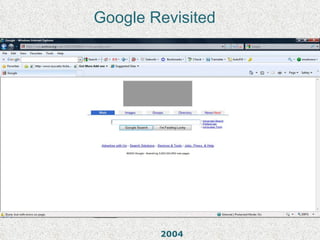
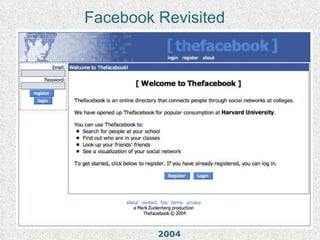
The Internet Archive is a nonprofit organization founded in 1996 by Brewster Kahle to archive the internet and provide universal access to knowledge. It operates the Wayback Machine, which has archived over 150 billion web pages dating back to 1996. The Internet Archive collects and stores digital content including text, videos, audio, software and live concerts, totaling over 3 petabytes of data. However, its practice of archiving copyrighted material without permission has led to legal challenges around its status as a library and claims of copyright infringement.