

















![Triple pattern fragment servers
enable clients to be intelligent.
<http://fragments.dbpedia.org/2014/en#dataset> hydra:search [
hydra:template "http://fragments.dbpedia.org/2014/en
controls
{?subject,predicate,object}";
hydra:mapping
[ hydra:variable "subject"; hydra:property rdf:subject ],
[ hydra:variable "predicate"; hydra:property rdf:predicate ],
[ hydra:variable "object"; hydra:property rdf:object ]
].
The RDF representation explains:
“you can query by triple pattern”.](https://image.slidesharecdn.com/queryingdatasetsonthewebwithhighavailability-141022084340-conversion-gate01/85/Querying-datasets-on-the-Web-with-high-availability-22-320.jpg)




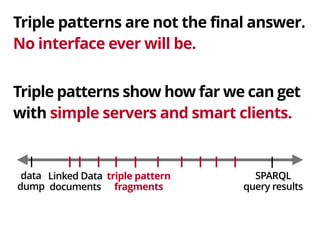
![The client looks inside the fragment
to see how to access the dataset.
Fragment: http://fragments.dbpedia.org/2014/en
<http://fragments.dbpedia.org/2014/en#dataset> hydra:search [
hydra:template "http://fragments.dbpedia.org/2014/en
{?subject,predicate,object}";
hydra:mapping
[ hydra:variable "subject"; hydra:property rdf:subject ],
[ hydra:variable "predicate"; hydra:property rdf:predicate ],
[ hydra:variable "object"; hydra:property rdf:object ]
].
“I can query the dataset by triple pattern.”](https://image.slidesharecdn.com/queryingdatasetsonthewebwithhighavailability-141022084340-conversion-gate01/85/Querying-datasets-on-the-Web-with-high-availability-27-320.jpg)







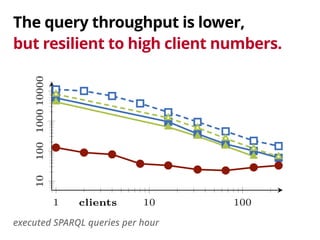
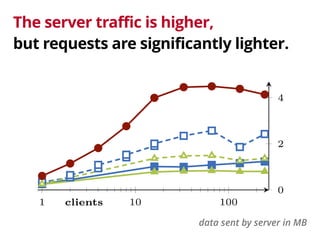
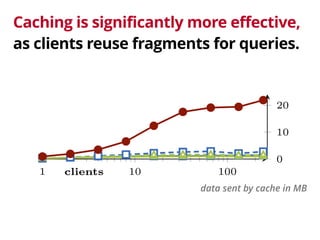
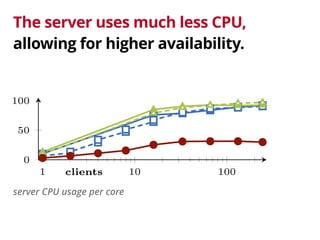
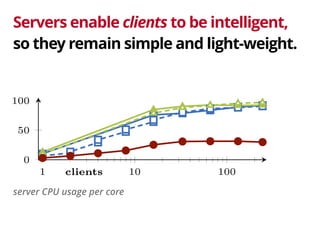

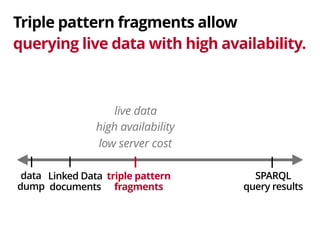



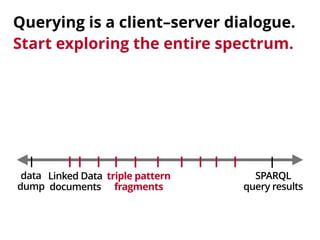


The document discusses the trade-offs involved in querying linked open data on the web, highlighting the need for affordable high-availability solutions. It introduces a triple pattern fragments interface that enables simpler servers and intelligent clients to perform live data queries at lower costs while managing bandwidth and query speed. The authors evaluate the performance and availability of this approach compared to traditional methods like SPARQL endpoints and data dumps.





















































