Row vs. columnarrelational databases
• All relational databases deal with tables, rows, and columns
• But there are sub-types:
• row-oriented: they are internally organized around the handling of rows
• columnar / column-oriented: these mainly work with columns
• Both types usually offer SQL interfaces and produce tables (with rows
and columns) as their result sets
• Both types can generally solve the same queries
• Both types have specific use cases that they're good for (and use
cases that they're not good for)
3.
Row vs. columnarrelational databases
• In practice, row-oriented databases are often optimized and
particularly good for OLTP workloads
• whereas column-oriented databases are often well-suited for OLAP
workloads
• This is due to the different internal designs of row- and column-
oriented databases
Row-oriented storage
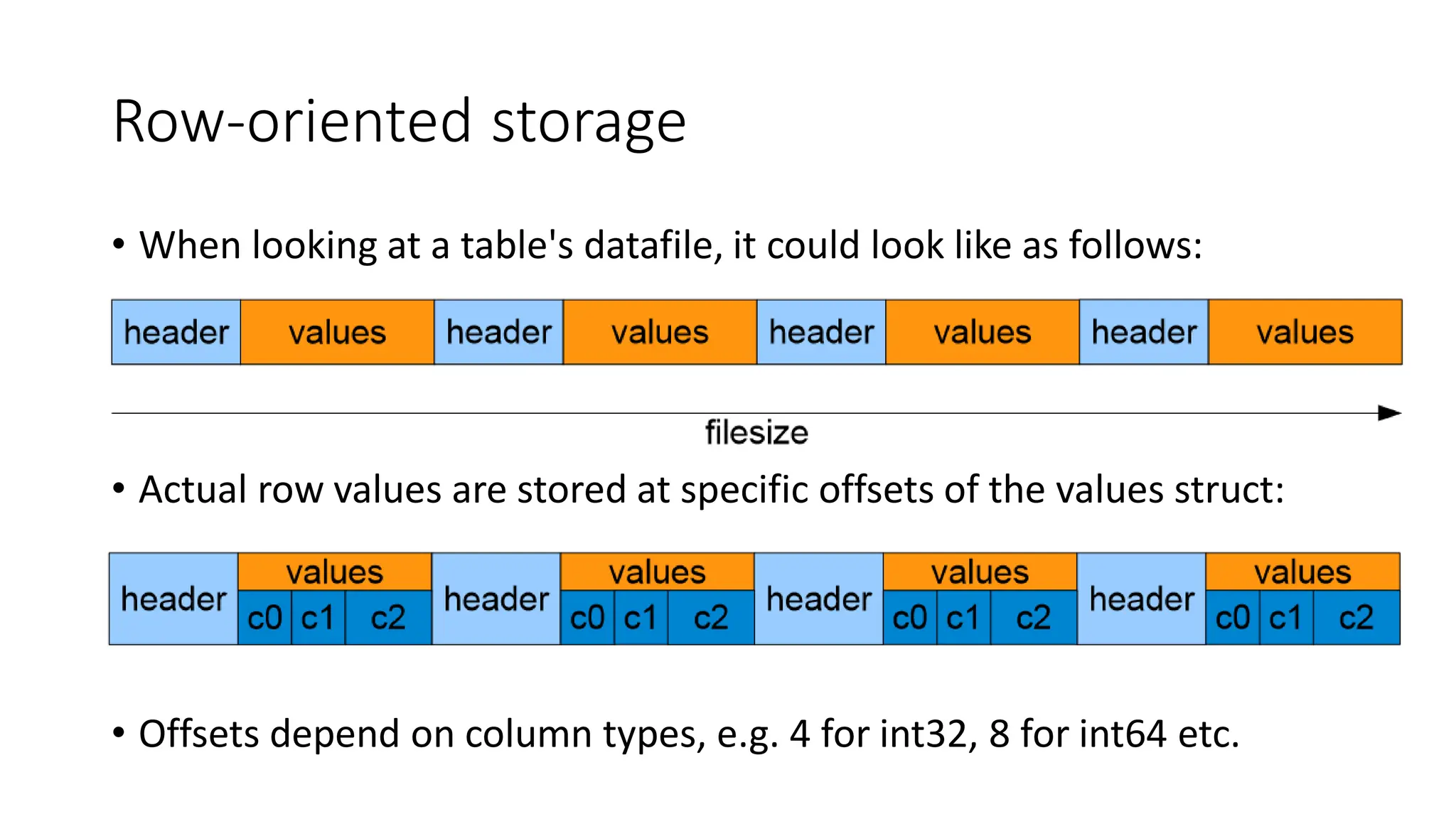
• Whenlooking at a table's datafile, it could look like as follows:
• Actual row values are stored at specific offsets of the values struct:
• Offsets depend on column types, e.g. 4 for int32, 8 for int64 etc.
6.
Row-oriented storage
• Row-orientedstorage is good if we need to touch one row. This
normally requires reading/writing a single page
• Row-oriented storage is beneficial if all or most columns of a row
need to be read or written. This can be done with a single read/write.
• Row-oriented storage is very inefficient if not all columns are needed
but a lot of rows need to be read:
• Full rows are read, including columns not used by a query
• Reads are done page-wise. Not many rows may fit on a page when rows are
big
• Pages are normally not fully filled, which leads to reading lots of unused areas
• Record (and sometimes page) headers need to be read, too but do not
contain actual row data
7.
Column-oriented storage
• Column-orienteddatabases primarily work on columns
• All columns are treated individually
• Values of a single column are stored contiguously
• This allows array-processing the values of a column
• Rows may be constructed from column values later if required
• This means column stores can still produce row output (tables)
• Values from multiple columns need to be retrieved and assembled for
that, making implementation of bit more complex
• Query processors in columnar databases work on columns, too
8.
Column-oriented storage
• Columnstores store data in column-specific files
• Simplest case: one datafile per column
• Row values for each column are stored contiguously
9.
Column-oriented storage
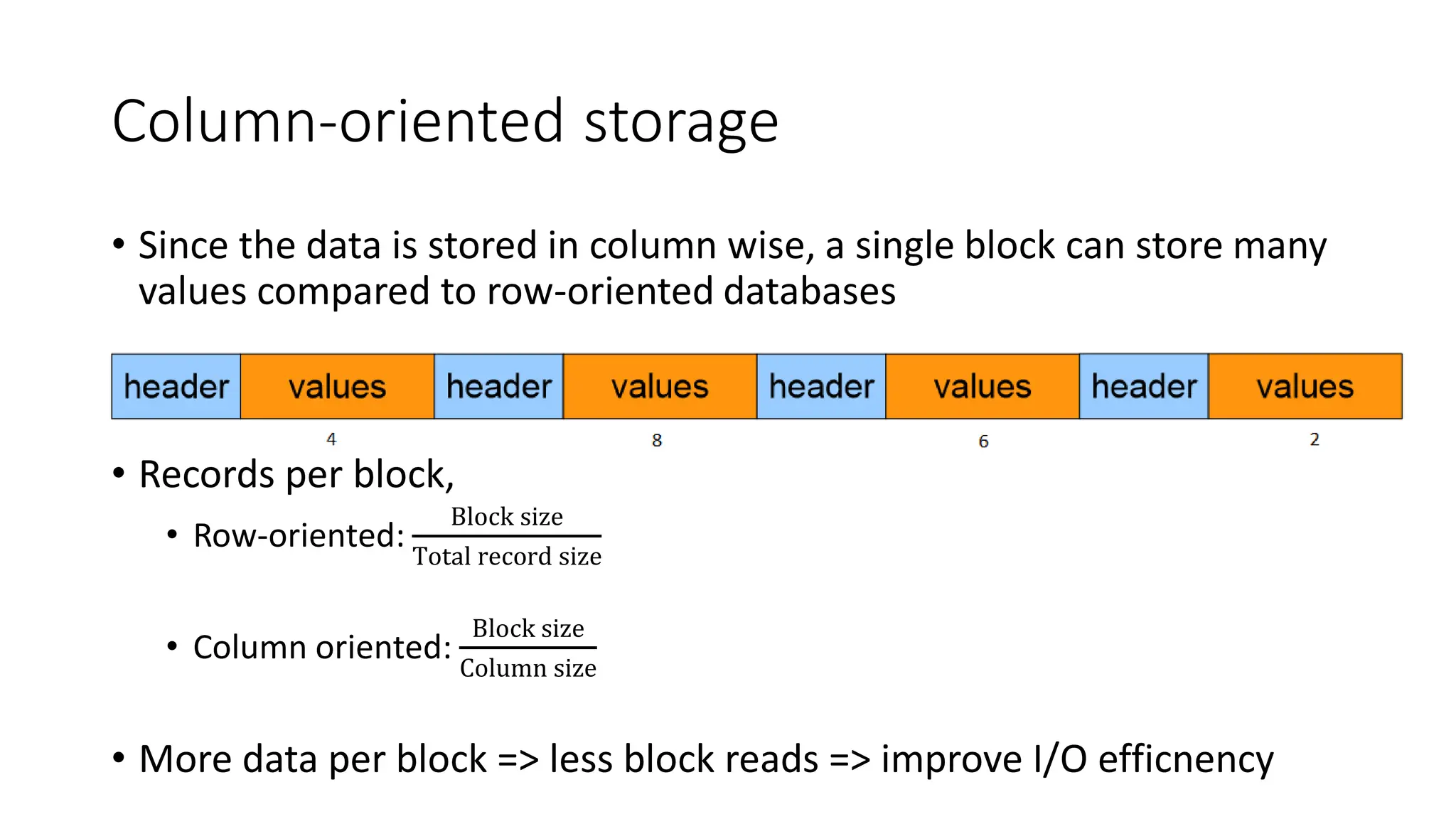
• Sincethe data is stored in column wise, a single block can store many
values compared to row-oriented databases
• Records per block,
• Row-oriented:
Block size
Total record size
• Column oriented:
Block size
Column size
• More data per block => less block reads => improve I/O efficnency
10.
Column-oriented storage –Compression
• Almost all column stores perform compression
– Compression further reduces the storage footprint of each column
– Column data type tailored compression
• RLE (Run-length encoding)
• Integer packing
• Dictionary and lookup string compression
• Other (depends on column store)
• Effective compression reduces storage cost
• IO reduction yields decreased response times during queries as well
- Queries may execute an order of magnitude faster compared to queries over
the same data set on a row store
• 10:1 to 30:1 compression rations may be seen
11.
Column-oriented storage –Compression
• All data within each column datafile have the same type, making it
ideal for compression
• Usually a much better compression factor can be achieved for single
columns than for entire rows
• Compression allows reducing disk I/O when reading/writing column
data but has some CPU cost
• For data sets bigger than the memory size compression is often
beneficial because disk access is slower than decompression
12.
Column-oriented storage –Compression
• A good use case for compression in column stores is dictionary
compression for variable length string values
• Each unique string is assigned an integer number
• The dictionary, consisting of integer number and string value, is saved
as column meta data
• Column values are then integers only, making them small and fixed
width
• This can save much space if string values are non-unique
• With dictionaries sorted by column value, this will also allow range
queries
13.
Column-oriented storage –IO saving
• Column stores can greatly improve the performance of queries that only
touch a small amount of columns
• This is because they will only access these columns’ content
• Simple math: table t has a total of 10 GB data, with
• column a: 4 GB
• column b: 2 GB
• column c: 3 GB
• column d: 1 GB
• If a query only uses column d, at most 1 GB of data will be processed by a
column store
• Could read even less with compression
• In a row store, the full 10 GB will be processed
14.
Column-oriented storage –segments
• Column data in column stores is often grouped into segments/packets of a
specific size (e.g. 64 K values)
• Meta data is calculated and stored separately per segment, e.g.:
• Segment meta data can be checked during query processing when no indexes are
available
• Min value in segment
• Max value in segment
• Number of NOT NULL values in segment
• Histograms
• Compression meta data
• Segment meta data may provide information about whether the segment can be
skipped entirely, allowing to reduce the number of values that need to be
processed in the query
• Calculating segment meta data is a relatively cheap operation (only needs to
traverse column values in segment) but still should occur infrequently
• In a read-only or read-mostly workload, this is tolerable
15.
Column-oriented storage –processing
• Column values are not processed row-at-a-time, but block-at-a-time
• This reduces the number of function calls (function call per block of
values, but not per row)
• Operating in blocks allows compiler optimizations, e.g. loop unrolling,
parallelization, pipelining
• Column values are normally positioned in contiguous memory
locations, also allowing SIMD operations (vectorization)
• Working on many subsequent memory positions also improves cache
usage (multiple values are in the same cache line) and reduces
pipeline stalls
• All these make column stores ideal for batch processing
16.
Column-oriented storage –processing
• Reading all columns of a row is an expensive operation in a column
store, so full row tuple construction is avoided or delayed as much as
possible internally
• Updating/deleting or inserting rows may also be very expensive and
may cost much more time than in a row store
• Some column stores are hybrids, with read-optimized (column)
storage and write-optimized OLTP storage
• Still, column stores are not really made for OLTP workloads, and if you
need to work with many columns at once, you'll pay a price in a
column store
17.
OLTP
• Transactional processing
•Retrieve or modify individual records (mostly few records)
• Use indexes to quickly find relevant records
• Queries often triggered by end user actions and should complete
instantly
• ACID properties may be important
• Mixed read/write workload working set should fit in RAM
18.
OLAP
• Analytical processing/ reporting
• Derive new information from existing data (aggregates,
transformations, calculations)
• Queries often run on many records or complete data set data set
may exceed size of RAM easily
• Mainly read or even read-only workload
• ACID properties often not important, data can often be regenerated
• Queries often run interactively
• Common: not known in advance which aspects are interesting so pre-
indexing „relevant“ columns is difficult
HBase VsRDBMS
Hbase RDBMS
Column-orientedRow-oriented (Mostly)
Flexible schema, add columns on the fly Fixed schema
Good with sparse tables Not optimized for sparse tables
Not optimized for joins – still possible with map reduce Optimized for joins
Tight integration with MR Not really
Horizontal scalability – just add hardware Hard to shared and scale
Good for semi-structured data as well as structured data Good for structured data
When not touseHBase?
•When you have only few thousands/millions rows
• Lacks of RDBMS commands
• When you have hardware less than 5 data nodes when replica
factor is 3
Note: HBase can run quite well in stand-alone mode on a laptop, but,
this should be considers a development configuration only
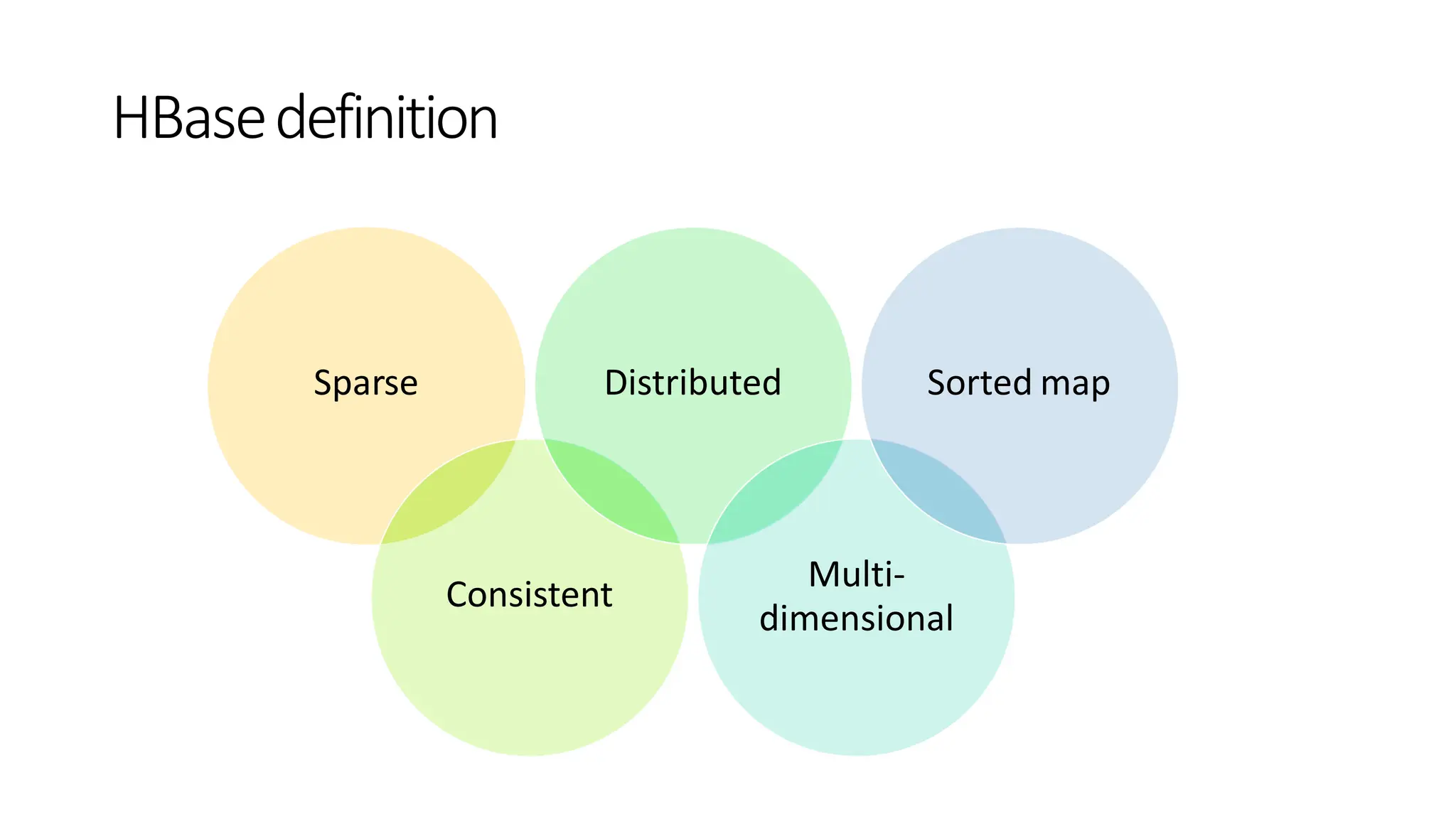
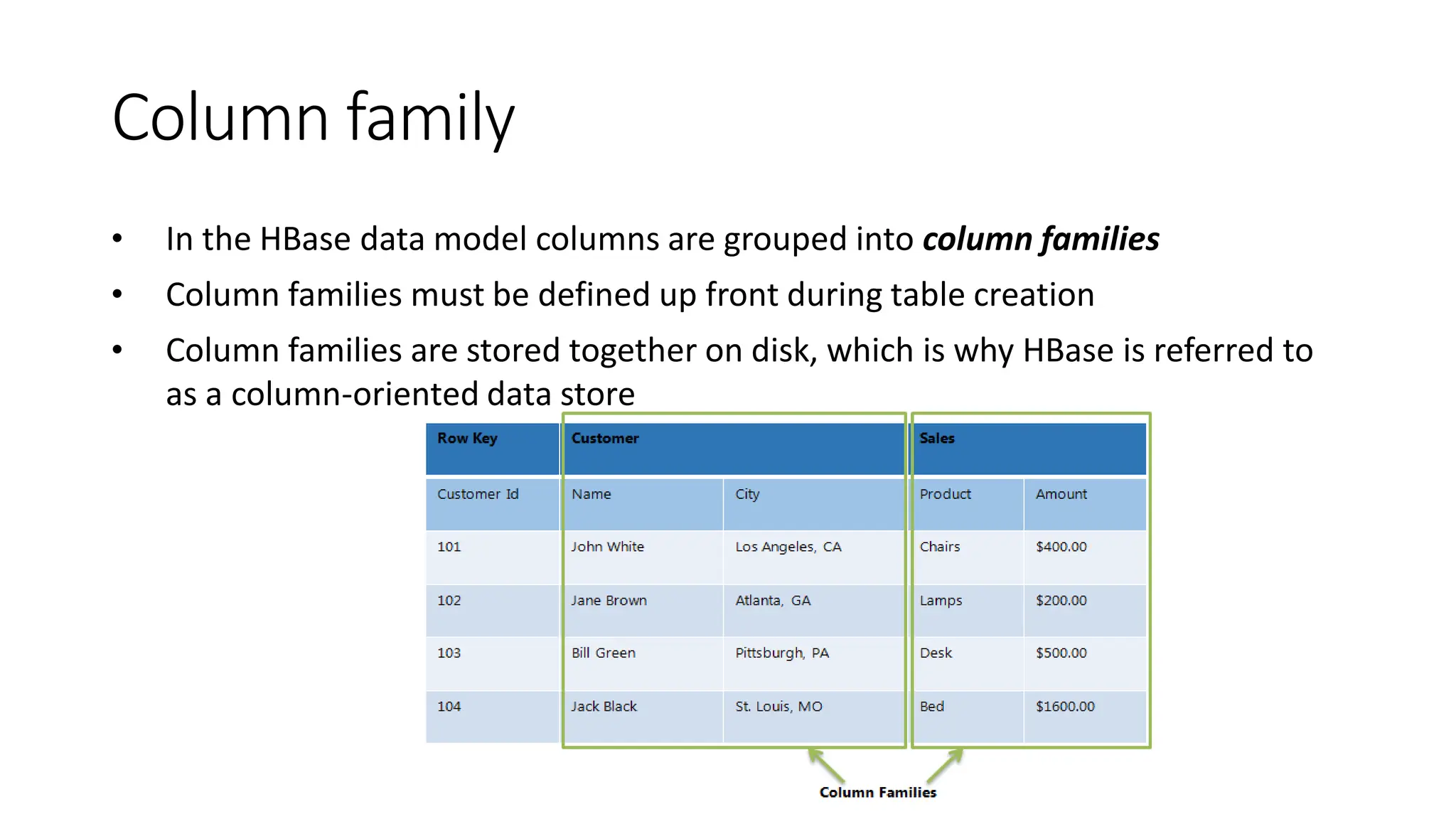
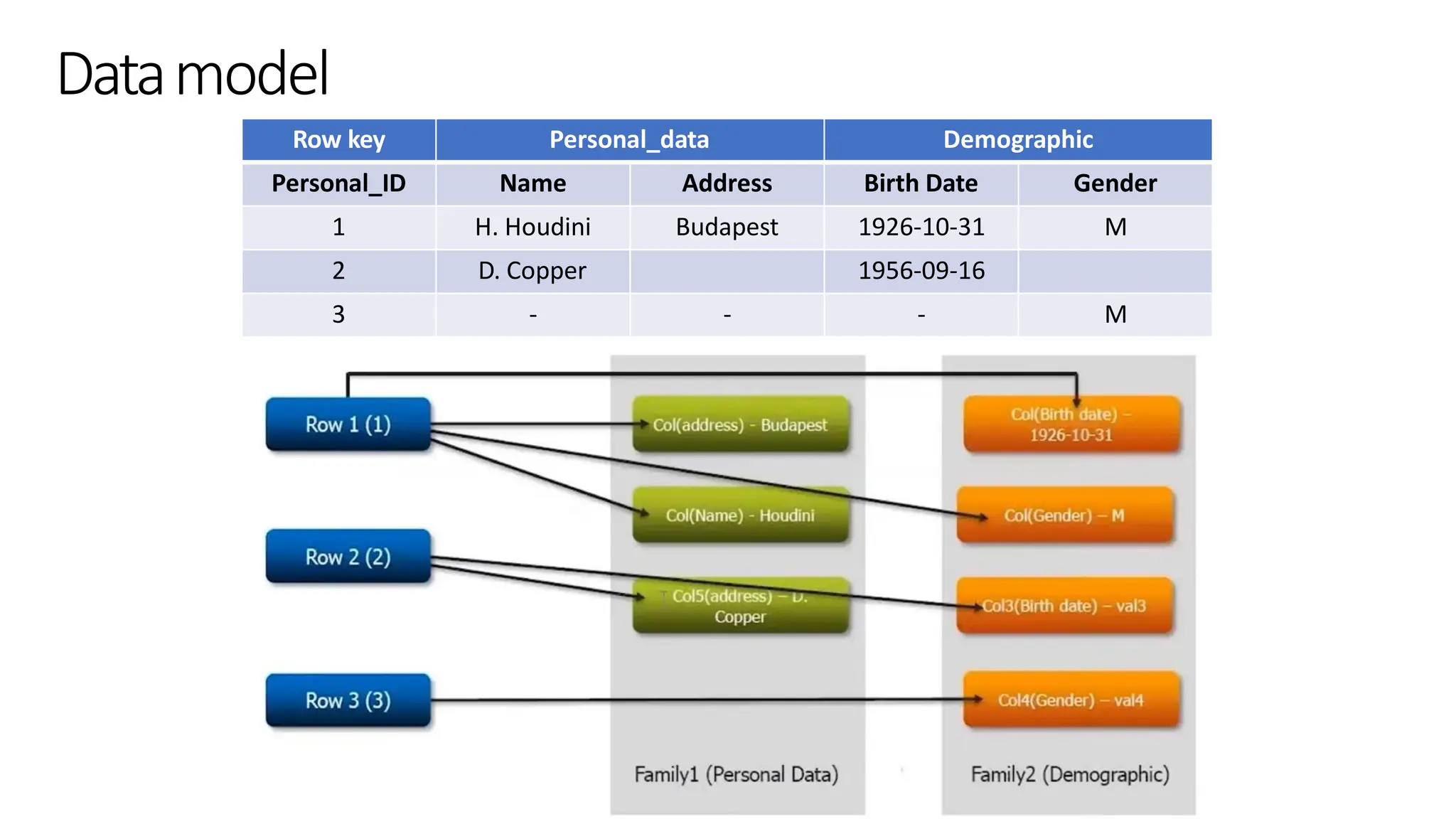
Column family
• Inthe HBase data model columns are grouped into column families
• Column families must be defined up front during table creation
• Column families are stored together on disk, which is why HBase is referred to
as a column-oriented data store
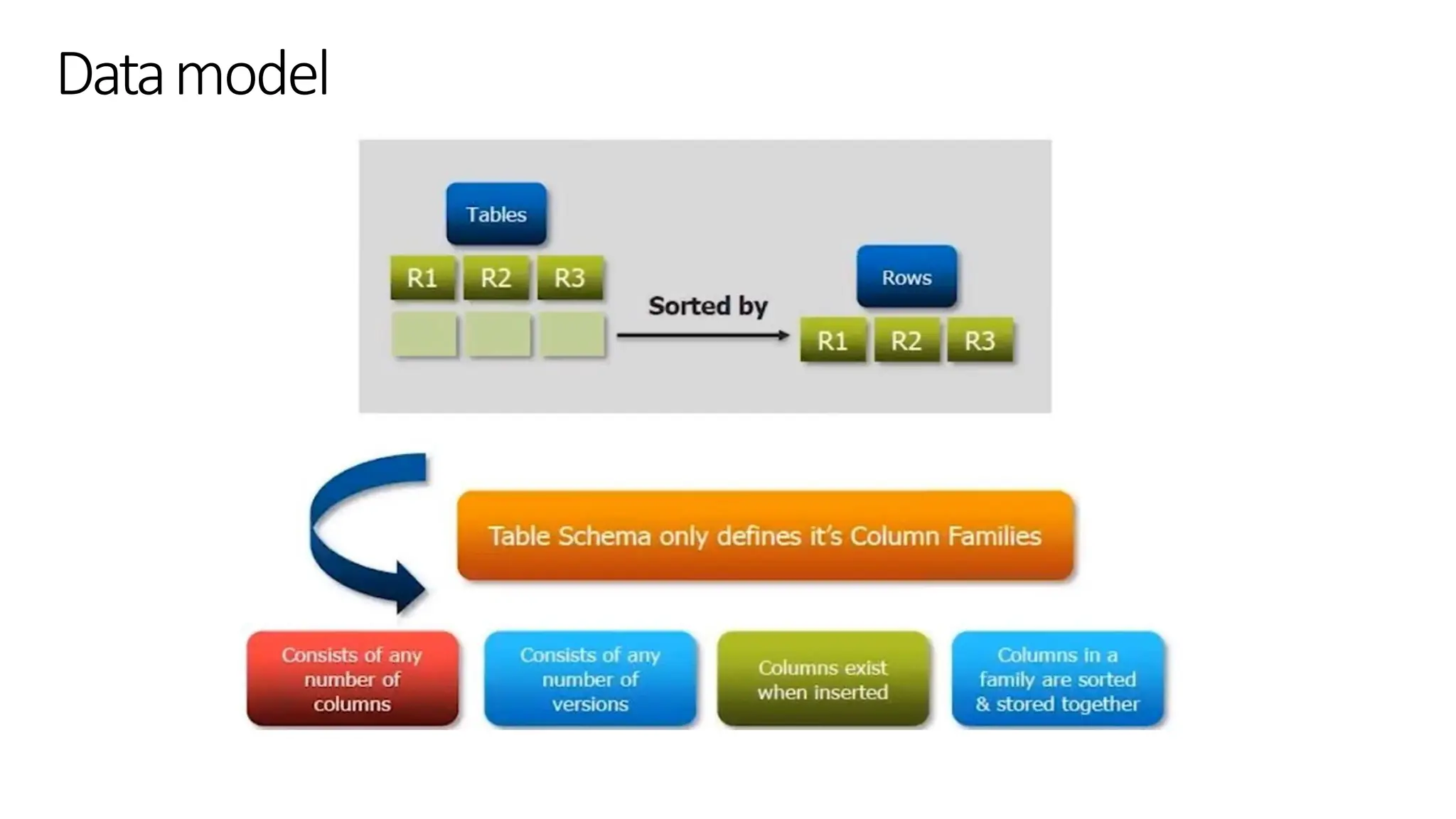
Datamodel
Row key Personal_dataDemographic
Personal_ID Name Address Birth Date Gender
1 H. Houdini Budapest 1926-10-31 M
2 D. Copper 1956-09-16
3 - - - M
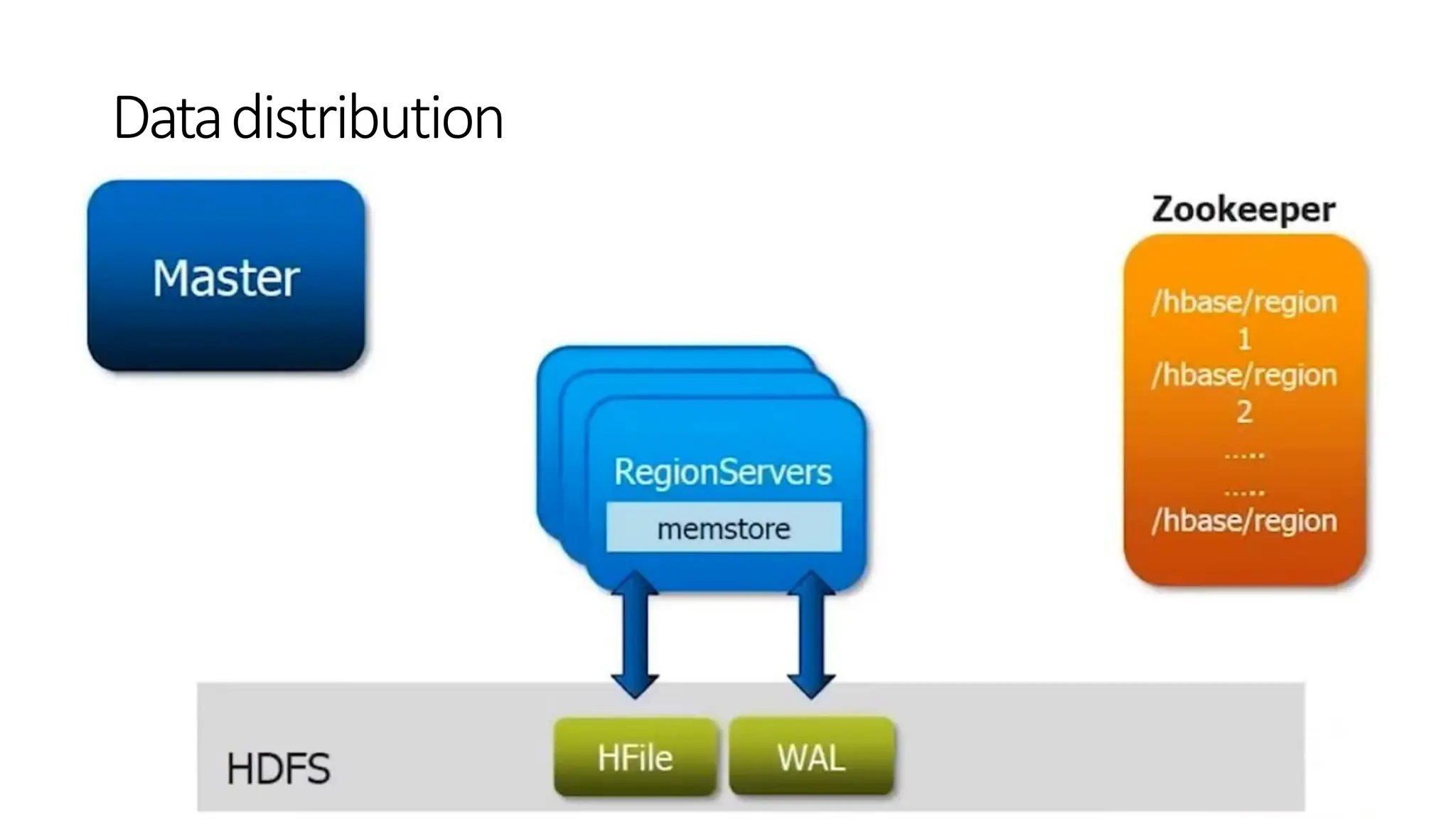
• HBase HMasteris a lightweight process that assigns regions to region servers in
the Hadoop cluster for load balancing.
• Manages and Monitors the Hadoop Cluster
• Performs Administration (Interface for creating, updating and deleting tables.)
• Controlling the failover
• DDL operations are handled by the HMaster
• Whenever a client wants to change the schema and change any of the
metadata operations, HMaster is responsible for all these operation
Architecture-HMaster
33.
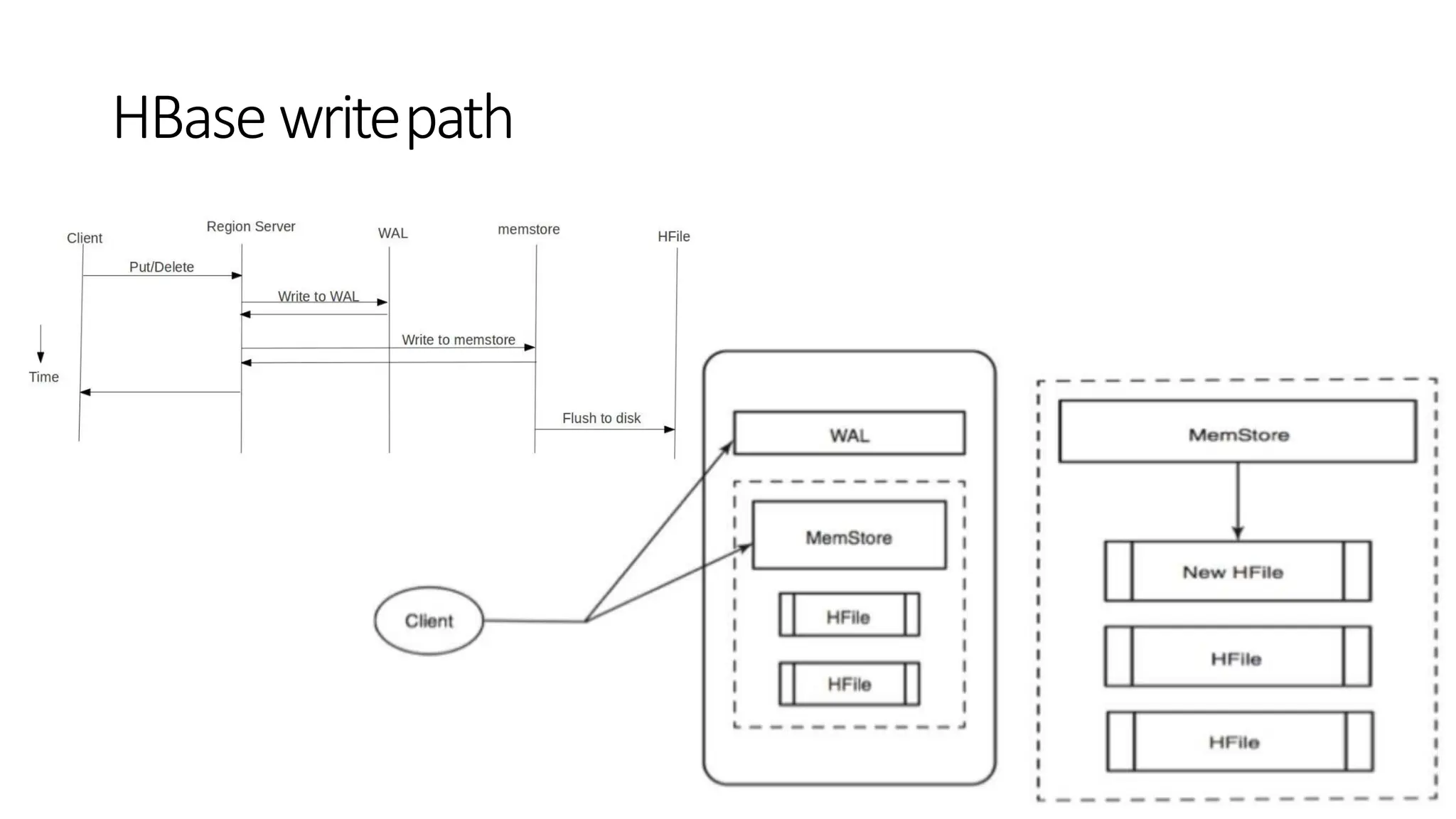
• These arethe worker nodes which handle read, write, update, and delete
requests from clients
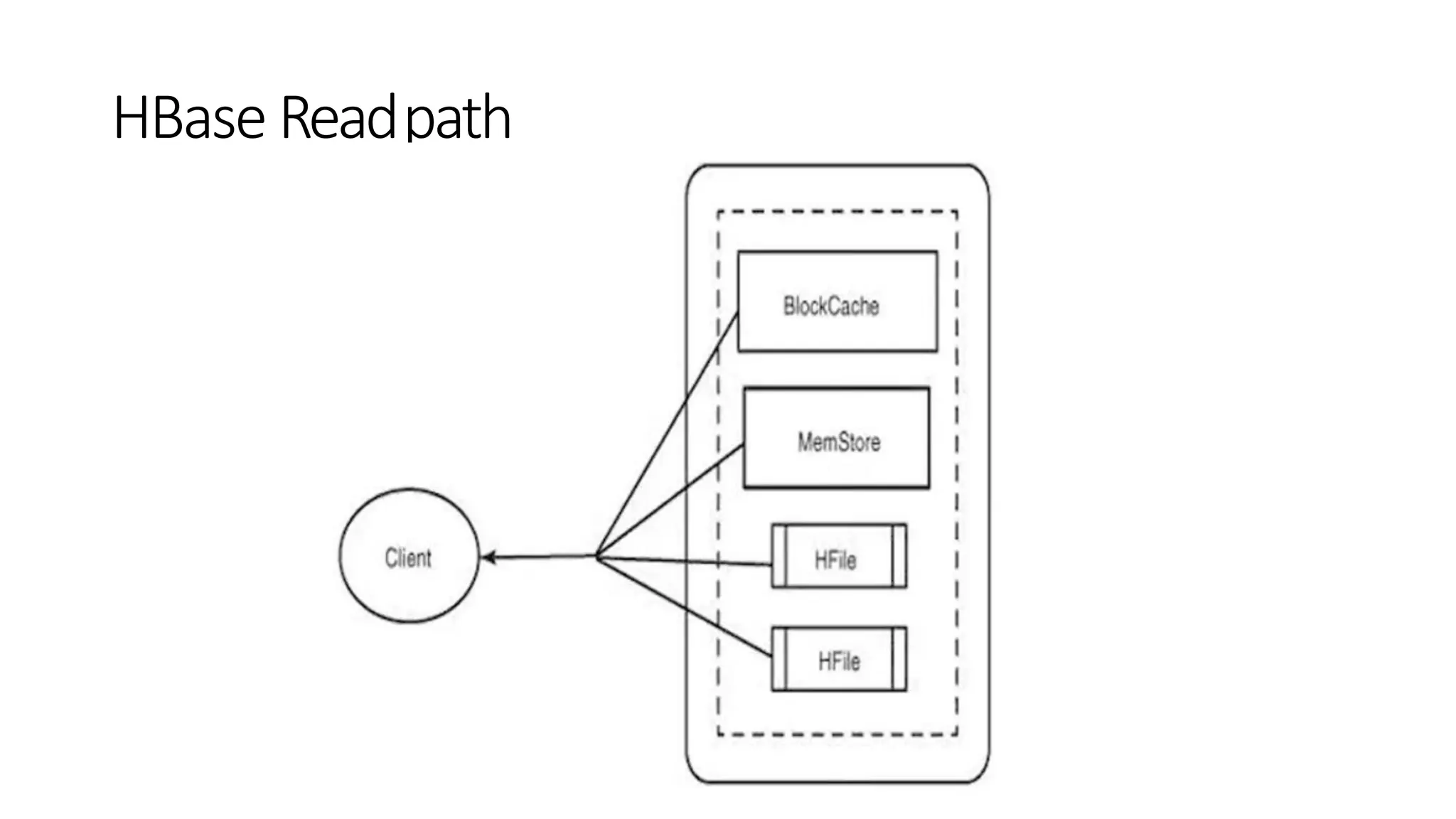
• Region Server process, runs on every node in the Hadoop cluster
• Block Cache – This is the read cache. Most frequently read data is stored in the
read cache and whenever the block cache is full, recently used data is evicted.
• MemStore- This is the write cache and stores new data that is not yet written to
the disk. Every column family in a region has a MemStore.
• Write Ahead Log (WAL) is a file that stores new data that is not persisted to
permanent storage.
• HFile is the actual storage file that stores the rows as sorted key values on a disk
Architecture–Regionserver
CAPtheory inHBase
• HBasesupports Consistency and Partition tolerance.
• IT compromises the Availability factor
• Partition tolerance
• HBase runs on top of Hadoop distribution
• All the HBase data are stored in HFDS
• Hadoop is designed to have fault tolerance and therefore, HBase inherit the
partition tolerance capability.
40.
CAPtheory inHBasecontd.
• Consistency
•Access to row data is atomic and includes any number of columns being read
or written to
• The atomic access is a factor to this architecture being strictly consistent, as
each concurrent reader and writer can make safe assumptions about the state
of a row
• When data is updated it is first written to a commit log, called a write-ahead
log (WAL) in Hbase
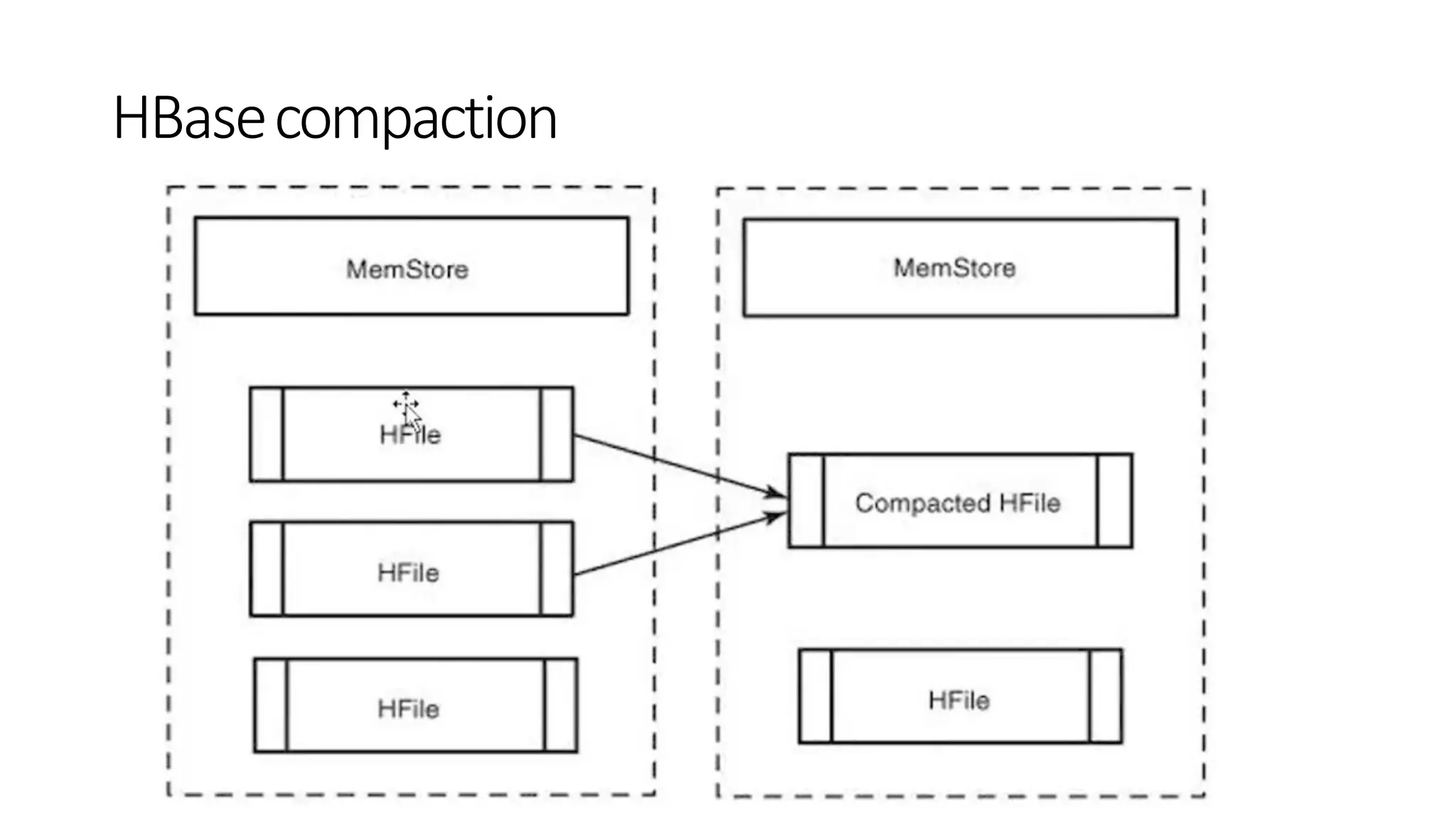
• Then stored in the (sorted by RowId) in-memory memstore
• Once the data in memory has exceeded a given maximum value, it is flushed
as an HFile to disk
• After the flush, the commit logs can be discarded up to the last unflushed
modification
41.
CAPtheory inHBasecontd.
• Availability
•HBase compromises the availability factor
• But, Cloudera Enterprise 5.9.x and Hortonworks Data Platform 2.2
implements high available feature in HBase
• They provides a feature called region replication to achieve high availability for
reads