Download to read offline


![2WeTOSM ‘14
[Turhan09] Data from
Turkish toasters can
predict defects in
NASA flight systems
Today’s topic:
Transfer Learning](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-2-320.jpg)

![Definitions
5
• find the one
• use it
Note: vastly simpler than other transfer learning
methods [Turhan09, Turhan11, Nam13, etc]
Bellwether effect Bellwether method
• If a community builds
many software projects
• There exists one ∈ many
from which
• quality predictors can
be built …
• … and used for all](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-5-320.jpg)
![Challenges:
Variable Datasets
... “New projects are always emerging,
and old ones are being rewritten…”
… “the quality, representativeness,
and volume of the training data have a
major influence on the usefulness
and stability of model performance…”
— Rahman et al.
[Rah12]
Growing Volume
Of Projects
9](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-9-320.jpg)
![• Unstable conclusions are typical in SE [Menzies12]
• Usefulness of some lesson “X” is contradictory
Challenges:
Conclusion Instability
10](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-10-320.jpg)
![• Unstable conclusions are typical in SE [Menzies12]
• Usefulness of some lesson “X” is contradictory
Challenges:
Conclusion Instability
11
Kitchenham et al. ‘07
• Are data from other
organizations …
• … as useful as local
data?
• Inconclusive
• 3 cases: Just as good.
4 cases: Worse.](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-11-320.jpg)
![• Unstable conclusions are typical in SE [Menzies12]
• Usefulness of some lesson “X” is contradictory
Challenges:
Conclusion Instability
12
Zimmermann et al. ‘09
• 622 pairs of projects
• Only 4% of pairs
were useful
Kitchenham et al. ‘07
• Are data from other
organizations …
• … as useful as local
data?
• Inconclusive
• 3 cases: Just as good.
4 cases: Worse.](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-12-320.jpg)
![• Menzies et al. [Men12] offer several ways
• They ask for better experimental practice.
• Is there a better way?
•Yes! Look for the “Bellwether”
• As long as the bellwether continues to offer good
quality predictions
•Then conclusions from one…
•... are conclusions for all
13
How to Reduce this Instability?](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-13-320.jpg)

![Estimating Quality
Why not Static Analyzers?
• [Rahman14] et al. compared
• Code analysis tools:
FindBugs, JLint, and PMD
• with Static Code defect
Predictors
• Found no difference
(measurement: AUCEC)
15
• And
• Using lightweight parsers...
• … Defect predictors can
quickly jump to new
languages
• Same is not true for static
code analysis tools
• Lesser Bugs Better Software](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-15-320.jpg)
![Estimating Quality
Why not Static Analyzers?
16
• And
• They work surprisingly well!
• [Ostrand04]: ~80% of the bugs localized
in 20% of the code](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-16-320.jpg)
![Estimating Quality:
Static code Defect Prediction
1. Ubiquitous
• Researchers and Industrial practitioners frequently use
them. Eg. Companies like Google [Lew14], V&V books
[Raktin01]
2. A lot of (ongoing) research
• Tremendous Attention [Nam13]
• Better approaches are constantly being proposed
3. They are easy to use
• Software Metrics can be collected fast
• Wide variety of tools, open source data miners
[sklearn][weka]
17](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-17-320.jpg)
![Transfer Learning:
Introduction
• Extract knowledge from source (S) and apply to
target (T)
• Data needs to be massaged before use[Zhang15]
• Careful sub-sampling
• Transformation
• Based on data source, TL is categorized as:
• Homogeneous vs. Heterogeneous
• Based on transformation[Nam13, Nam15, Jing15]
• Similarity vs. Dimensionality
19](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-19-320.jpg)

![Homogeneous TL:
Burak Filter
22
• Burak[Tur09] used relevancy filtering
• Filter using kNN
• Gather two sets of data
• Validation set (S) Test Data
• Candidate set (T) Train Data
• Use kNN
• Pick “similar” instances from T
• Filter T using S](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-22-320.jpg)

![Homogeneous TL:
Mixed Model Learner
• Turhan et al.[Tur11] proposed a mixed-model learner
• Combine local data with curated non-local data
• Gather two sets of data
• Validation set (S): Pick a random 10% of local data
• Candidate set (T): Remaining 90% and non-local data
• For non-local data, they use Burak filter[Tur09]
• Experiment with various 90%-10% splits
• 400 experiments were conducted to pick the best model
24](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-24-320.jpg)

![Homogeneous TL:
Addressing the challenges
• Researchers have offered a bleak view of TL
• Zimmerman et al.[Zimm09]
•Transfer is not always consistent
•IE could learn from Firefox but not vice versa
•Rahman et al.[Rahman12]
•The “imprecision” of learning across projects
• Recent research has resorted to more complex
approaches
26](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-26-320.jpg)


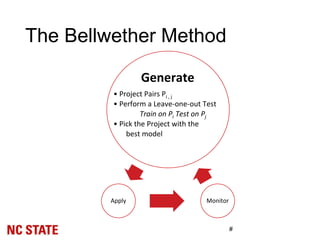
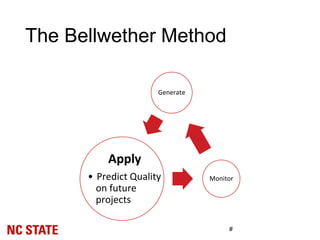
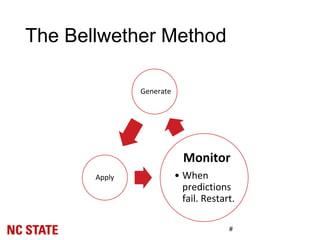
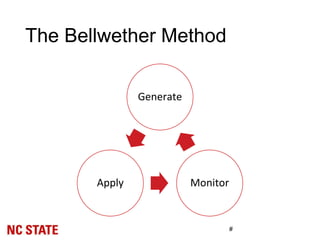

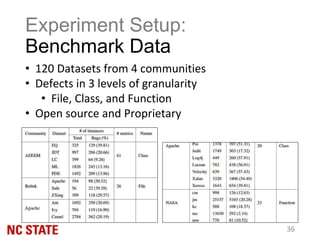
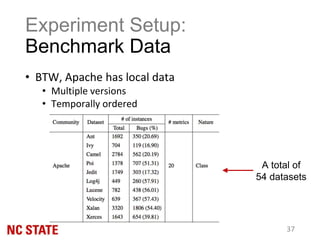
![Experiment Setup:
Prediction Model
• We use Random Forests[Zimmerman08]
• Build several decision trees from random subsamples
• Use ensemble learning
• Samples are imbalanced[Pelayo07]
• More “clean” examples
• Use SMOTE [Chawla01] to rebalance data*
• Randomly down sample “clean” instances
• Up-sample “buggy” instances
*Apply only to training data
38](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-39-320.jpg)

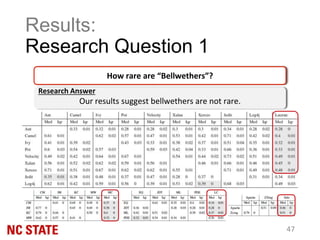
![Experiment Setup:
Statistical Measures
41
• Prediction is usually measured using ROC
• ROC is a plot of Recall vs. False Alarm
• Plot requires several treatments
• Obtained by cross validation.
• We refrain from Cross-Validation
• It tends to mix the test data with the bellwether
• Instead,
• We use Balance [Ma07]](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-41-320.jpg)

![Experiment Setup:
Statistical Measures
• Prediction Model is inherently random
• Rerun model 40 times with different seeds
• Collect Balance measure in every run
• Use Scott-Knott Test to compare Balance values
• Scott-Knott ranks Balance values (best to worst)
• Rank -> Effect Size Test + Hypothesis Test
• Why SK?
•It’s been used by recent high profile papers at TSE
[Mittas13] and ICSE [Ghotra15]
43](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-43-320.jpg)












![Future Work
• Bellwethers in heterogeneous learners
• Promising heterogeneous transfer learners [Nam15][Jing15]
• Perform complex dimensionality mapping transforms
• Can Bellwethers assist in finding the best mapping?
• Study and quantify bellwether
• what makes a bellwether, a bellwether?
•Bellwethers beyond defect prediction
•Are there bellwethers in other data?
62](https://image.slidesharecdn.com/bellwether-ase-160905034609/85/The-Bellwether-Effect-and-Its-Implications-to-Transfer-Learning-62-320.jpg)


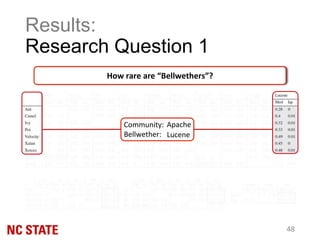
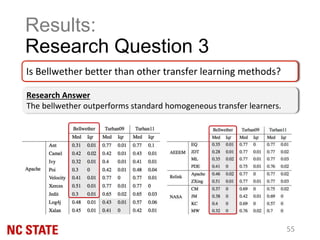
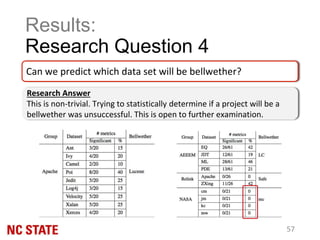
The document discusses the 'bellwether' effect in the context of transfer learning, where one software project within a community can act as a predictor for the quality of others. It outlines the methodology of identifying and using a bellwether to improve the reliability of quality predictions for emerging projects, while addressing challenges such as the 'cold-start' problem and conclusion instability. The findings suggest that bellwethers are not rare and can outperform local models, indicating their potential as a stable basis for transfer learning in software engineering.


































































