Download as PDF, PPTX















![17
Semi-structured Data (3/6)
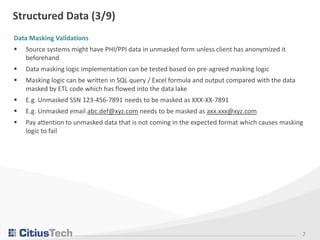
JSON Message Validation
▪ Data lake can be integrated with Kafka Messaging System that produces JSON messages in semi-
structured format
▪ As a part of JSON message validation, QA team can cover the following pointers:
• Compare the JSON Message with the JSON schema provided as part of requirement
• Data Type Check
• Null / Not Null constraints Check
▪ For instance:
JSON Schema JSON Message
{
"ServiceLevel":
{
"type": ["string", "null" ]
},
"ServiceType":
{
"type": ["string"]
}
}
{
"ServiceLevel": "One",
"ServiceType": "Skilled Nurse"
}](https://image.slidesharecdn.com/testingstrategiesfordatalakehostedonhadoop-190830113612/85/Testing-Strategies-for-Data-Lake-Hosted-on-Hadoop-17-320.jpg)






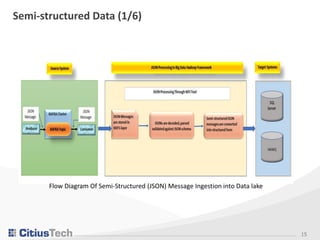
This document discusses testing strategies for structured data in a data lake hosted on Hadoop. It covers validating the schema, data masking, data reconciliation during loads, testing the extract-load-transform framework, handling on-premise versus cloud environments, data quality checks, partitioning and compacting the data for storage. Challenges include special characters in the data, varying data formats, masking logic failures, and limitations of cloud data types and sizes.























































































