Download as PDF, PPTX







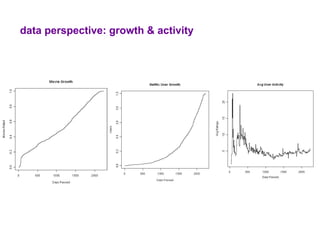









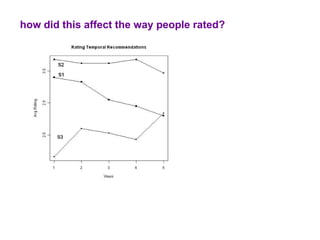
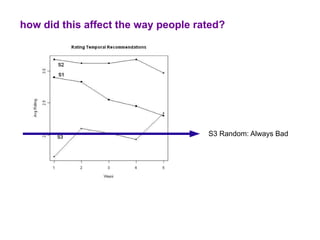
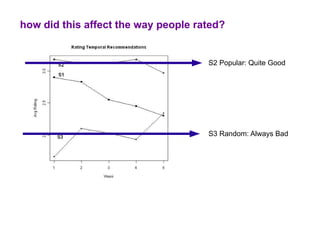
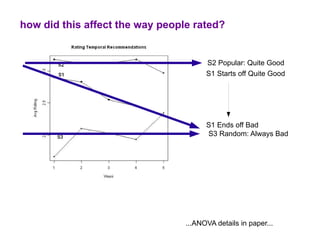






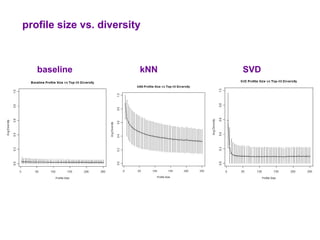
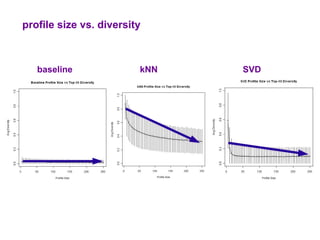


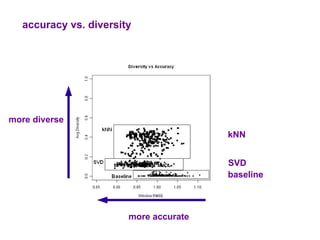


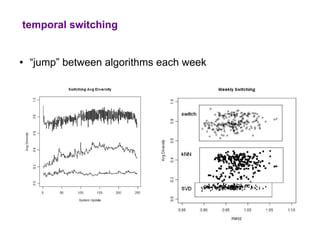
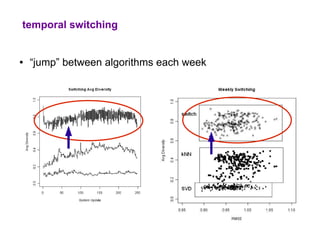
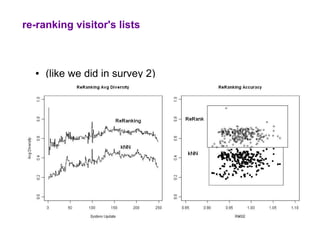
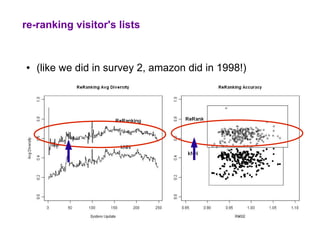



The document examines the importance of temporal diversity in recommender systems. It defines a metric to measure temporal diversity and analyzes how factors like profile size, ratings added, and time between sessions influence diversity levels. The most accurate collaborative filtering algorithms were not the most diverse over time. The authors propose methods like temporal switching between algorithms and re-ranking recommendations to improve temporal diversity and prevent users from seeing the same recommendations repeatedly.


































































