Download as PDF, PPTX



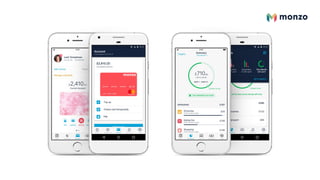
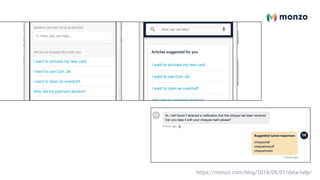
![The main problems that we aim to solve with
machine learning include helping customers
find the right answers to their queries (in the
help screen of the app) and helping agents to
diagnose and respond to customer queries
swiftly (in the internal tooling).
Our most impactful model is an encoder based
on [1] that we train on chat data.
[1] Attention is all you need
https://arxiv.org/abs/1706.03762
Customer Operations](https://image.slidesharecdn.com/2019-xcededatascience-190407211805/85/Machine-Learning-Faster-7-320.jpg)

























Monzo uses machine learning to improve customer service by helping both customers and agents find answers swiftly through an encoder model trained on chat data. Key challenges include quick deployment, validation of models in production, and the reuse of existing models to tackle new problems. The document outlines their approach to overcoming these issues through creating deployment tools, validation testing, and template generation for machine learning processes.



































































