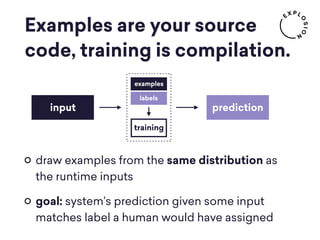
Explosion AI is a digital studio specializing in AI and natural language processing, emphasizing the importance of high-quality training data for effective machine learning. The document discusses the challenges in data collection, especially in terms of human annotators' experiences and incentives, and proposes solutions like active learning to improve data quality. It concludes that AI systems are not just complex algorithms but rely heavily on well-annotated data and require both read and write access for optimal performance.




![How machines “learn”
def train_tagger(examples):
W = defaultdict(lambda: zeros(n_tags))
for (word, prev, next), human_tag in examples:
scores = W[word] + W[prev] + W[next]
guess = scores.argmax()
if guess != human_tag:
for feat in (word, prev, next):
W[feat][guess] -= 1
W[feat][human_tag] += 1
the weights we'll train
if the guess was wrong, adjust weights
get the best-scoring tag
score each tag given weights & context
examples = words, tags, contexts
decrease score for bad tag in this context
increase score for good tag in this context
Example: training a simple part-of-speech tagger with the perceptron algorithm
(teach the model to recognise verbs, nouns, etc.)](https://image.slidesharecdn.com/inesmontani-teachingaiabouthumanknowledge-170120085404/85/Teaching-AI-about-human-knowledge-5-320.jpg)