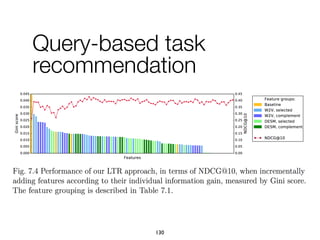
Download as PDF, PPTX




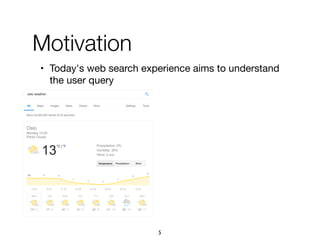







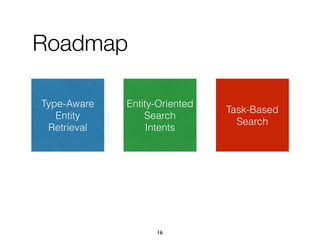



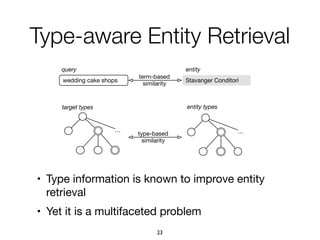






























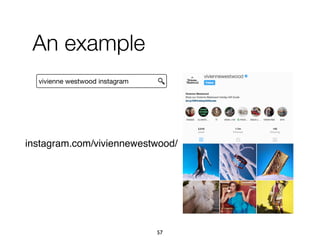












![1. Intents searched for a type of entities
paris map, sydney map => [city] map
2. Categories assigned to refiners
vivienne westwood instagram => Website
vivienne westwood age => Property
vivienne westwood customer care => Service
3. Multiple refiners expressing an intent
"booking", "book", "make a reservation", "rooms"
75
A knowledge base of entity-
oriented search intents](https://image.slidesharecdn.com/20191204-defense-201031110153/85/Task-Based-Support-in-Search-Engines-75-320.jpg)
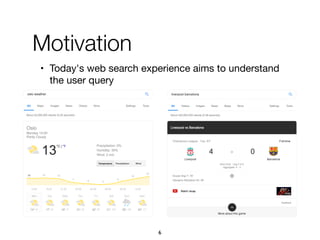
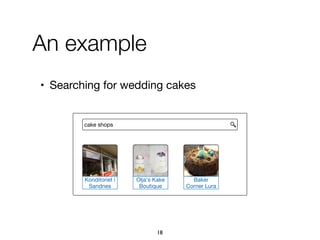
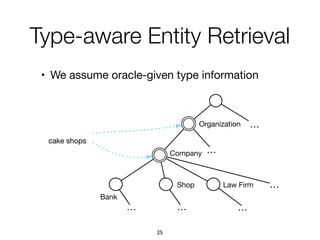
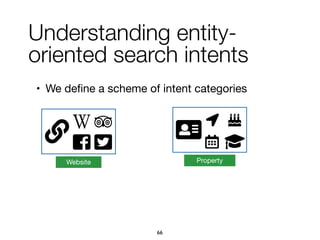
![1. Intents searched for a type of entities
paris map, sydney map => [city] map
• (intent ID, searchedForType, entity type, confidence)
2. Categories assigned to refiners
vivienne westwood instagram => Website
vivienne westwood age => Property
vivienne westwood customer care => Service
3. Multiple refiners expressing an intent
"booking", "book", "make a reservation", "rooms"
76
A knowledge base of entity-
oriented search intents](https://image.slidesharecdn.com/20191204-defense-201031110153/85/Task-Based-Support-in-Search-Engines-76-320.jpg)
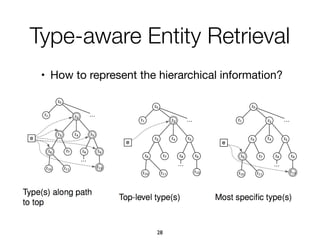
![1. Intents searched for a type of entities
paris map, sydney map => [city] map
• (intent ID, searchedForType, entity type, confidence)
2. Categories assigned to refiners
vivienne westwood instagram => Website
vivienne westwood age => Property
vivienne westwood customer care => Service
• (intent ID, ofCategory, intent category, confidence)
3. Multiple refiners expressing an intent
"booking", "book", "make a reservation", "rooms"
77
A knowledge base of entity-
oriented search intents](https://image.slidesharecdn.com/20191204-defense-201031110153/85/Task-Based-Support-in-Search-Engines-77-320.jpg)
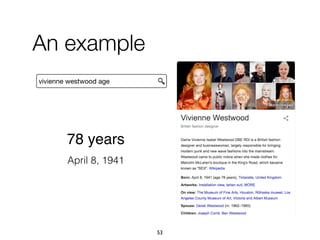
![1. Intents searched for a type of entities
paris map, sydney map => [city] map
• (intent ID, searchedForType, entity type, confidence)
2. Categories assigned to refiners
vivienne westwood instagram => Website
vivienne westwood age => Property
vivienne westwood customer care => Service
• (intent ID, ofCategory, intent category, confidence)
3. Multiple refiners expressing an intent
"booking", "book", "make a reservation", "rooms"
• (intent ID, expressedBy, refiner, confidence)
A knowledge base of entity-
oriented search intents
78](https://image.slidesharecdn.com/20191204-defense-201031110153/85/Task-Based-Support-in-Search-Engines-78-320.jpg)
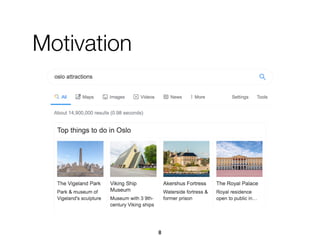
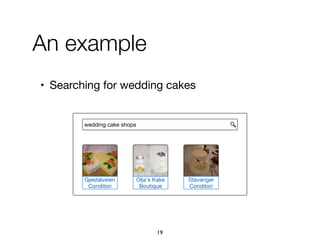
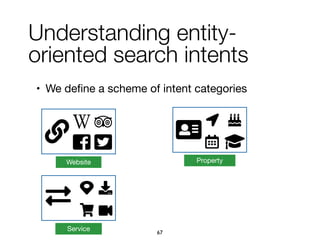
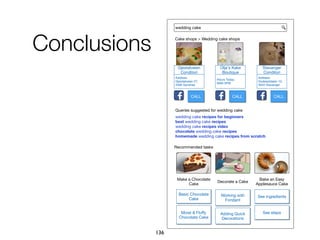
![Approach
Refiners
acquisition
Refiners
categorization
Intents
discovery
[hotel] airport
[hotel] spa
[hotel] booking
...
[hotel] airport: Service
[hotel] address: Property
[hotel] expedia: Website
...
taxi
arrive
Hotel_Arrivingbooking
make a reservation
Hotel_Booking
address
Hotel_Address
KB
construction
Intent ID Predicate Object Confidence
Hotel_Booking searchedForType [hotel] c1
Hotel_Booking ofCategory Service c2
Hotel_Booking expressedBy "booking" c3
Hotel_Booking expressedBy "make a reservation" c4
Hotel_Booking expressedBy "rooms" c5
79](https://image.slidesharecdn.com/20191204-defense-201031110153/85/Task-Based-Support-in-Search-Engines-79-320.jpg)
![Approach
Refiners
acquisition
Refiners
categorization
Intents
discovery
[hotel] airport
[hotel] spa
[hotel] booking
...
[hotel] airport: Service
[hotel] address: Property
[hotel] expedia: Website
...
taxi
arrive
Hotel_Arrivingbooking
make a reservation
Hotel_Booking
address
Hotel_Address
Intent
profile
{ KB
construction
Intent ID Predicate Object Confidence
Hotel_Booking searchedForType [hotel] c1
Hotel_Booking ofCategory Service c2
Hotel_Booking expressedBy "booking" c3
Hotel_Booking expressedBy "make a reservation" c4
Hotel_Booking expressedBy "rooms" c5
80](https://image.slidesharecdn.com/20191204-defense-201031110153/85/Task-Based-Support-in-Search-Engines-80-320.jpg)

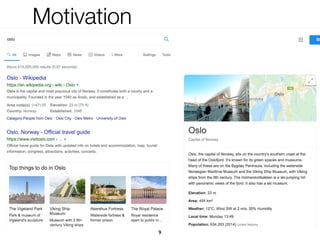
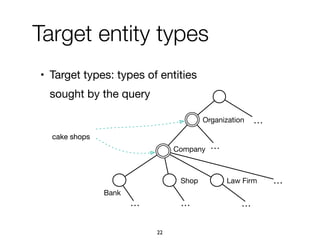
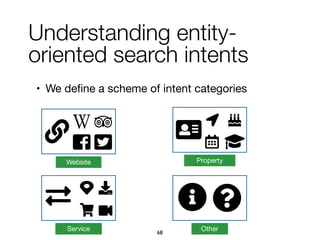
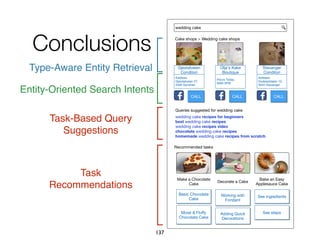
![Experimental evaluation
• Experts judge correctness, ignoring
confidence, of around 1.29% of IntentsKB
82
[0, 0.87) [0.87, 0.88) [0.88, 0.9) [0.9, 0.93) [0.93, 1]
Confidence intervals according to the splitting percentiles
0%
20%
40%
60%
80%
100%
Proportionoftriples
6,337 6,370 6,335 6,368 6,314
Correct
Incorrect, OFCATEGORY
Incorrect, EXPRESSEDBY](https://image.slidesharecdn.com/20191204-defense-201031110153/85/Task-Based-Support-in-Search-Engines-82-320.jpg)









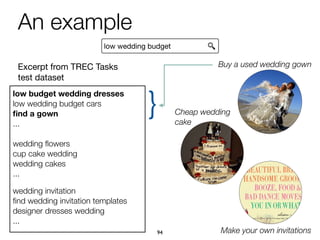
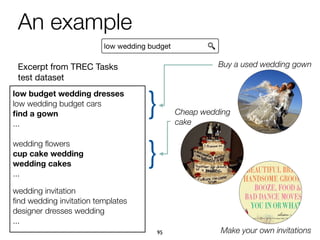
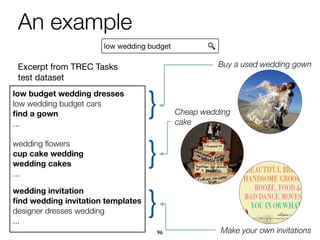





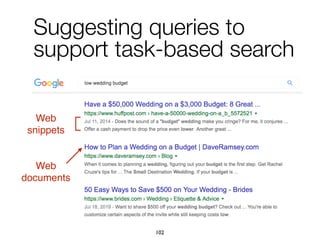




























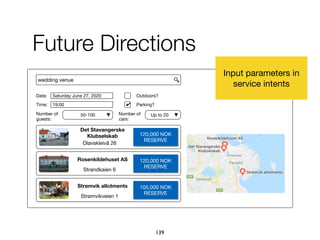



The document explores task-based support in search engines, focusing on entity retrieval and user intent identification. It discusses the importance of structured knowledge, type-aware entity retrieval, and methods for identifying target entity types to improve search efficiency. Additionally, it presents approaches for generating query suggestions and building a knowledge base to enhance user experience during complex search tasks.


































































