Download as PDF, PPTX



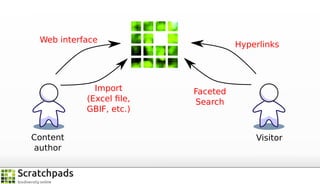
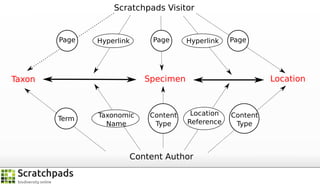
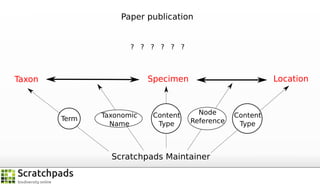
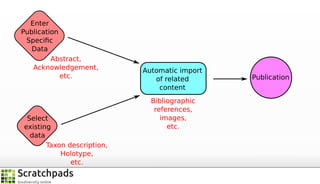
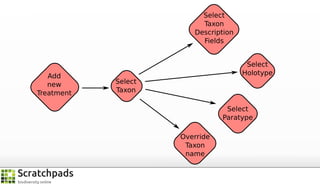
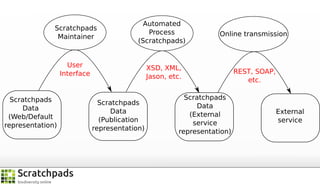
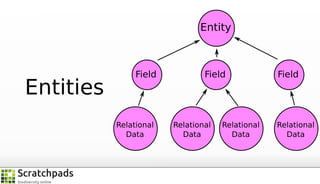
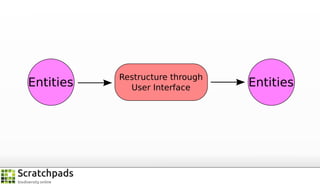
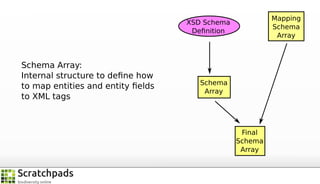
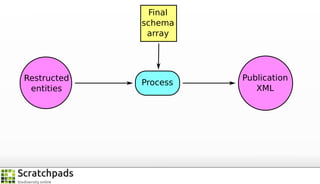
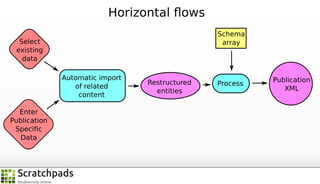
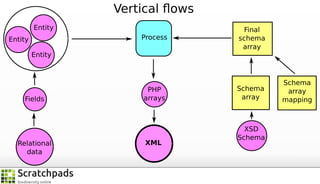



The document discusses the process of converting web content into paper-based publications, focusing on data restructuring, workflows, and implications for data storage and processing. It highlights the importance of user interfaces and the dynamic nature of data flows, emphasizing that model abstraction and modularity are more crucial than data storage. The presentation is part of the Vibrant Virtual Biodiversity project funded by the Seventh Framework Programme.













































































