Download to read offline













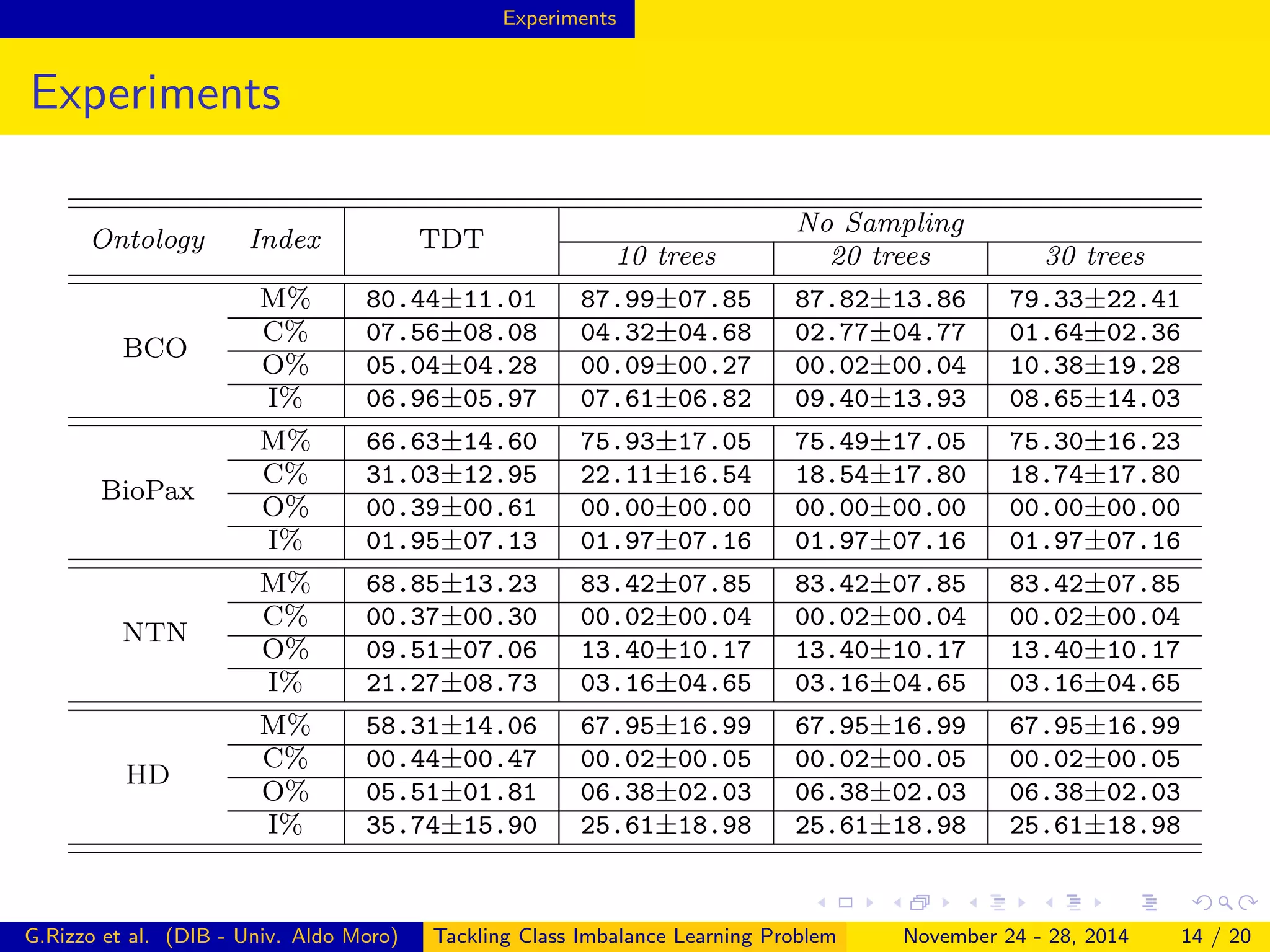
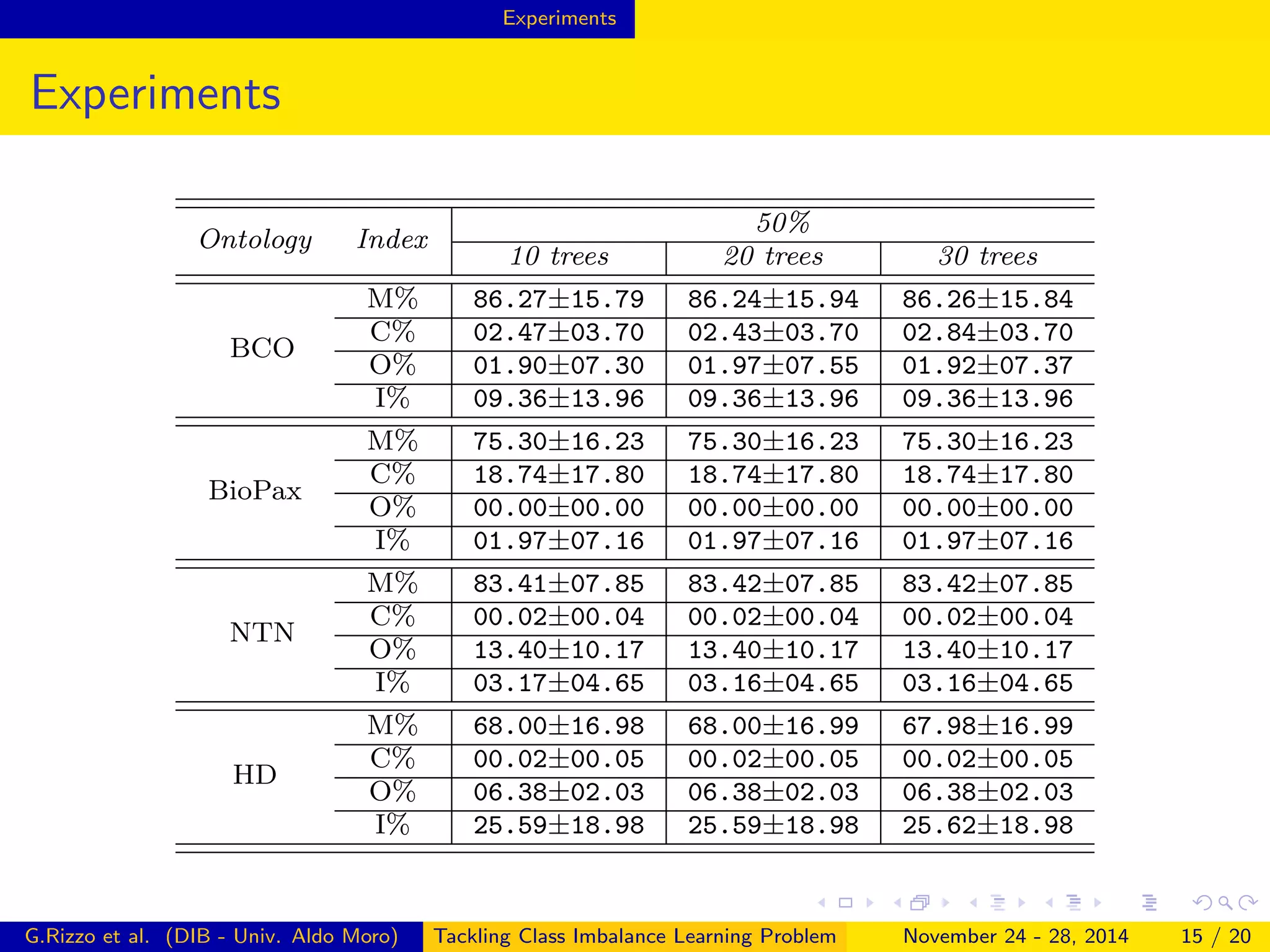
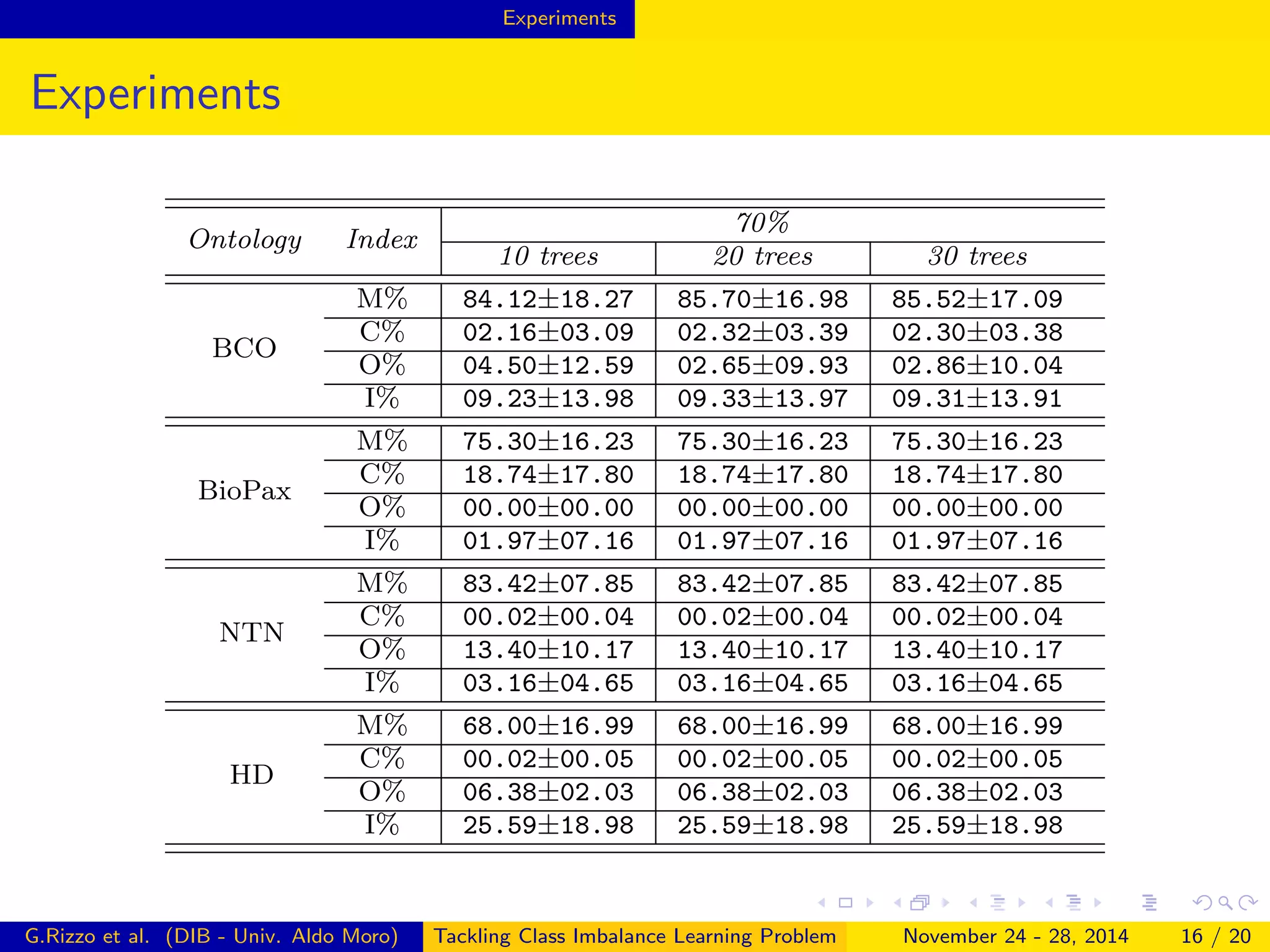
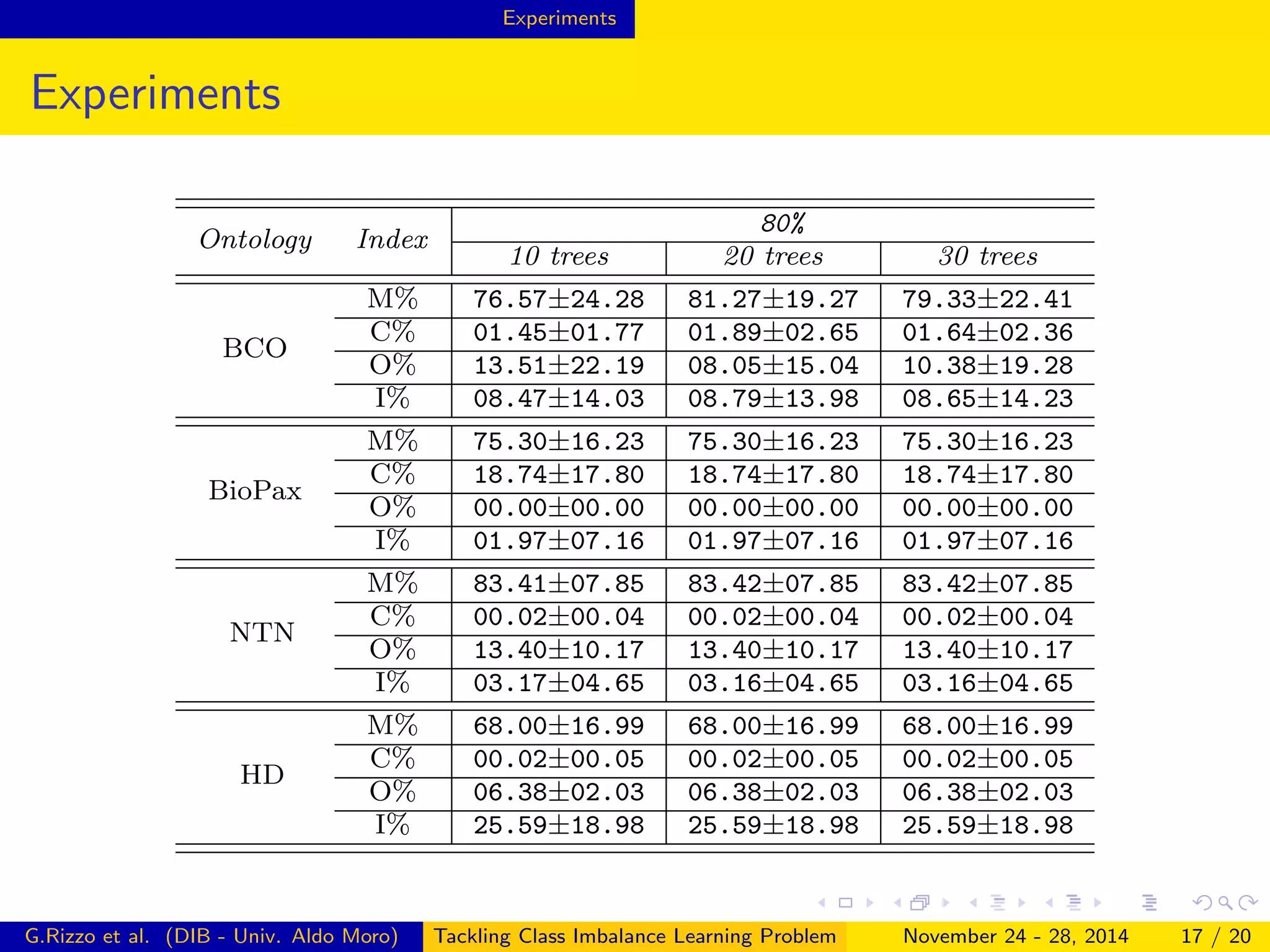




The document describes a framework for tackling class imbalance problems in machine learning on semantic web knowledge bases. It proposes combining sampling strategies with ensemble learning methods like bagging to generate multiple balanced training subsets. A technique called Terminological Random Forest is presented which uses terminological decision trees as weak learners. Experiments on several ontologies show the framework improves performance over single classifiers, with matching rates to a reasoner of up to 87% and low commission rates.




























![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jim Sterne - Adopting Generative AI Capabilities Into the Ent...](https://cdn.slidesharecdn.com/ss_thumbnails/sxhpofuorcagxsaulkmt-3-251204082258-7e66bc48-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)
